インデックス作成とは何ですか?
インデックス作成は、データベースの世界では重要な概念です。任意のフィールドにインデックスを作成する主な利点は、データへのアクセスが高速になることです。データベースの検索とアクセスのプロセスを最適化します。これを理解するために、この例を検討してください。
ユーザーがデータベースから特定の行を要求した場合、DBシステムは何をしますか?最初の行から開始し、これがユーザーが必要とする行であるかどうかを確認しますか?はいの場合はその行を返し、そうでない場合は最後まで行の検索を続けます。
通常、特定のフィールドにインデックスを定義すると、DBシステムはそのフィールドの値の順序付きリストを作成し、それを別のテーブルに格納します。このテーブルの各エントリは、元のテーブルの対応する値を指します。したがって、ユーザーが任意の行を検索しようとすると、最初にバイナリ検索アルゴリズムを使用してインデックステーブルの値を検索し、元のテーブルから対応する値を返します。線形検索の代わりに二分探索を使用しているため、このプロセスにかかる時間は短くなります。
この記事では、MongoDBインデックス作成に焦点を当て、MongoDBでインデックスを作成して使用する方法を理解します。
MongoDBコレクションでインデックスを作成するには?
Mongoシェルを使用してインデックスを作成するには、次の構文を使用できます:
db.collection.createIndex( <key and index type specification>, <options> )例:
myCollコレクションの名前フィールドにインデックスを作成するには:
db.myColl.createIndex( { name: -1 } )MongoDBインデックスの種類
-
デフォルトの_idインデックス
これは、新しいコレクションを作成するときにMongoDBによって作成されるデフォルトのインデックスです。このフィールドに値を指定しない場合、ユーザーが同じ_idフィールド値を持つ2つのドキュメントを挿入できないように、デフォルトで_idがコレクションの主キーになります。このインデックスを_idフィールドから削除することはできません。
-
単一フィールドインデックス
このインデックスタイプは、_idフィールド以外のフィールドに新しいインデックスを作成する場合に使用できます。
例:
db.myColl.createIndex( { name: 1 } )これにより、myCollコレクションの名前フィールドに単一のキー昇順インデックスが作成されます
-
複合インデックス
複合インデックスを使用して、複数のフィールドにインデックスを作成することもできます。このインデックスでは、インデックスで定義されているフィールドの順序が重要です。この例を考えてみましょう:
db.myColl.createIndex({ name: 1, score: -1 })このインデックスは、最初にコレクションを名前で昇順で並べ替え、次に名前の値ごとにスコア値で降順で並べ替えます。
-
マルチキーインデックス
このインデックスは、配列データのインデックスを作成するために使用できます。コレクション内のいずれかのフィールドに値として配列がある場合は、このインデックスを使用して、配列内の要素ごとに個別のインデックスエントリを作成できます。インデックス付きフィールドが配列の場合、MongoDBはそのフィールドにマルチキーインデックスを自動的に作成します。
この例を考えてみましょう:
{ ‘userid’: 1, ‘name’: ‘mongo’, ‘addr’: [ {zip: 12345, ...}, {zip: 34567, ...} ] }Mongoシェルでこのコマンドを発行することにより、addrフィールドにマルチキーインデックスを作成できます。
db.myColl.createIndex({ addr.zip: 1 }) -
地理空間インデックス
MongoDBコレクションにいくつかの座標を保存したとします。このタイプのフィールド(地理空間データがある)にインデックスを作成するには、地理空間インデックスを使用できます。 MongoDBは、2種類の地理空間インデックスをサポートしています。
-
2Dインデックス:このインデックスは、2D平面上にポイントとして保存されるデータに使用できます。
db.collection.createIndex( { <location field> : "2d" } ) -
2dsphereインデックス:データがGeoJson形式または座標ペア(経度、緯度)として保存される場合にこのインデックスを使用します
db.collection.createIndex( { <location field> : "2dsphere" } ) -
-
テキストインデックス
コレクション内のテキストの検索を含むクエリをサポートするには、テキストインデックスを使用できます。
例:
db.myColl.createIndex( { address: "text" } ) -
ハッシュインデックス
MongoDBは、ハッシュベースのシャーディングをサポートしています。ハッシュインデックスは、インデックス付きフィールドの値のハッシュを計算します。ハッシュ化インデックスは、ハッシュ化されたシャーディングキーを使用したシャーディングをサポートします。ハッシュシャーディングは、このインデックスをシャードキーとして使用して、クラスター全体でデータを分割します。
例:
db.myColl.createIndex( { _id: "hashed" } )
-
一意のインデックス
このプロパティにより、インデックス付きフィールドに重複する値がないことが保証されます。インデックスの作成中に重複が見つかった場合、それらのエントリは破棄されます。
-
スパースインデックス
このプロパティにより、すべてのクエリでインデックス付きフィールドのあるドキュメントが検索されます。インデックス付きフィールドがないドキュメントがある場合は、結果セットから破棄されます。
-
TTLインデックス
このインデックスは、特定の時間間隔(TTL)の後にコレクションからドキュメントを自動的に削除するために使用されます。これは、イベントログまたはユーザーセッションのドキュメントを削除するのに理想的です。
パフォーマンス分析
学生のスコアのコレクションを考えてみましょう。正確に3000000のドキュメントが含まれています。このコレクションにはインデックスを作成していません。スキーマを理解するには、以下の画像を参照してください。
 スコアコレクションのサンプルドキュメント
スコアコレクションのサンプルドキュメント ここで、インデックスなしのこのクエリについて考えてみましょう。
db.scores.find({ student: 585534 }).explain("executionStats")このクエリの実行には1155ミリ秒かかります。これが出力です。結果のexecutionTimeMillisフィールドを検索します。
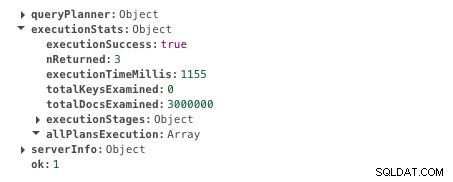 インデックス作成なしの実行時間
インデックス作成なしの実行時間 それでは、学生フィールドにインデックスを作成しましょう。インデックスを作成するには、このクエリを実行します。
db.scores.createIndex({ student: 1 })これで、同じクエリに0ミリ秒かかります。
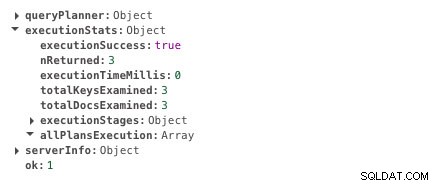 インデックス作成の実行時間
インデックス作成の実行時間 実行時間の違いがはっきりとわかります。ほぼ瞬時です。それがインデックス作成の力です。
結論
明らかなポイントの1つは、インデックスを作成することです。クエリに基づいて、コレクションにさまざまな種類のインデックスを定義できます。インデックスを作成しない場合、各クエリはコレクション全体をスキャンするため、アプリケーションの速度が非常に遅くなり、サーバーの多くのリソースが使用されます。一方、不要なインデックスを作成すると、すべての挿入、削除、更新に余分な時間のオーバーヘッドが発生するため、あまり多くのインデックスを作成しないでください。インデックス付きフィールドでこれらの操作のいずれかを実行する場合は、インデックスツリーでも同じ操作を実行する必要があり、時間がかかります。インデックスはRAMに保存されるため、無関係なインデックスを作成するとRAMスペースが消費され、サーバーの速度が低下する可能性があります。