特にコンピュータ構造のシステムパフォーマンスを向上させるには、パフォーマンスの概要を把握するプロセスが必要です。このプロセスは一般に監視と呼ばれます。監視はデータベース管理の重要な部分であり、MongoDBの詳細なパフォーマンス情報は、その機能状態を測定するのに役立つだけではありません。しかし、異常についての手がかりも与えてください。これは、メンテナンスを行うときに役立ちます。より深刻な障害にエスカレートする前に、異常な動作を特定して修正することが不可欠です。
発生する可能性のある障害の種類には、次のようなものがあります...
- 遅れまたは減速
- リソースの不足
- システムの一時的な中断
多くの場合、監視はメトリックの分析に集中しています。監視する必要のある主要な指標には、次のものがあります...
- データベースのパフォーマンス
- リソースの使用率(CPU使用率、使用可能なメモリ、ネットワーク使用量)
- 新たな挫折
- リソースの飽和と制限
- スループット操作
このブログでは、これらのメトリックについて詳しく説明し、MongoDBで使用可能なツール(ユーティリティやコマンドなど)について説明します。また、Pandora、FMS Open Source、Robo3Tなどの他のソフトウェアツールについても説明します。わかりやすくするために、この記事ではRobo3Tソフトウェアを使用してメトリックを示します。
データベースのパフォーマンス
データベースで最初にチェックすることは、サーバーがアクティブであるかどうかなど、データベースの一般的なパフォーマンスです。 Robo 3Tのデータベースでこのコマンドdb.serverStatus()を実行すると、サーバーの状態を示すこの情報が表示されます。
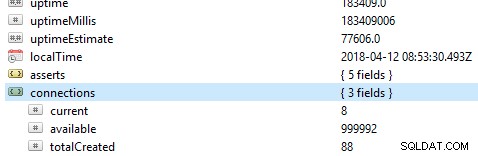

レプリカセット
レプリカセットは、同じデータセットを維持するmongodプロセスのグループです。特に実稼働モードでレプリカセットを使用している場合、操作ログはレプリケーションプロセスの基盤を提供します。すべての書き込み操作は、ノード、つまり、制限されたサイズのコレクションを格納するプライマリノードとセカンダリノードを使用して追跡されます。プライマリノードでは、書き込み操作が適用および処理されます。ただし、プライマリノードが操作ログにコピーされる前に障害が発生した場合、セカンダリ書き込みが行われますが、この場合、データは複製されない可能性があります。
監視する重要な指標...
レプリケーションラグ
これは、セカンダリノードがプライマリノードの背後にある距離を定義します。最適な状態では、ギャップをできるだけ小さくする必要があります。通常のオペレーティングシステムでは、このラグは0と推定されます。ギャップが広すぎると、セカンダリノードがプライマリに昇格するとデータの整合性が損なわれます。この場合、たとえば1分のしきい値を設定でき、それを超えるとアラートが設定されます。レプリケーションラグが大きくなる一般的な原因は次のとおりです...
- 書き込み容量が不十分である可能性があり、リソースの飽和に関連することが多いシャード。
- セカンダリノードは、プライマリノードよりも遅い速度でデータを提供しています。
- ネットワークが貧弱なために、ノードの通信が何らかの形で妨げられる可能性もあります。
- プライマリノードでの操作も遅くなり、レプリケーションがブロックされる可能性があります。これが発生した場合は、次のコマンドを実行できます。
- db.getProfilingLevel():値が0の場合、db操作が最適です。
値が1の場合、遅い操作に対応します。これは、結果としてクエリが遅いことが原因である可能性があります。 - db.getProfilingStatus():この場合、slowmsの値をチェックします。デフォルトでは100msです。値がこれよりも大きい場合は、プライマリで大量の書き込み操作が行われているか、セカンダリでリソースが不十分である可能性があります。これを解決するために、セカンダリをスケーリングして、プライマリと同じ量のリソースを確保することができます。
- db.getProfilingLevel():値が0の場合、db操作が最適です。
カーソル
たとえばfindなどの読み取り要求を行うと、結果のデータセットへのポインタであるカーソルが提供されます。このコマンドdb.serverStatus()を実行し、メトリックオブジェクトに移動してからカーソルを移動すると、次のように表示されます…

この場合、カーソルを閉じずに停止した接続が9つあったため、cursor.timeOutプロパティは9に段階的に更新されました。その結果、デフォルトのMongoDB設定で取得されない限り、サーバー上で開いたままになり、メモリを消費します。メモリを節約するために、非アクティブなカーソルを識別してそれらを刈り取る必要があります。また、タイムアウトでないカーソルはリソースを保持することが多く、それによって内部システムのパフォーマンスが低下するため、回避することもできます。これは、cursor.open.noTimeoutプロパティの値を値0に設定することで実現できます。
ジャーナル
WiredTiger Storage Engineを考慮すると、データが記録される前に、最初にディスクファイルに書き込まれます。これはジャーナリングと呼ばれます。ジャーナル処理により、障害が発生した場合のデータの可用性と耐久性が保証され、そこからリカバリを実行できます。
リカバリの目的で、最後のチェックポイントからリカバリするためにチェックポイント(特にWiredTigerストレージシステムの場合)を使用することがよくあります。ただし、MongoDBが予期せずシャットダウンした場合は、ジャーナリング手法を使用して、最後のチェックポイントの後に処理または提供されたデータを回復します。
新しいチェックポイントを作成するのに60秒ほどしかかからないため、最初のケースではジャーナル処理をオフにしないでください。したがって、障害が発生した場合、MongoDBはジャーナルを再生して、これらの数秒以内に失われたデータを回復できます。
ジャーナリングは通常、データがメモリに適用されてからディスク上で耐久性があるまでの時間間隔を狭めます。 storage.journalオブジェクトには、コミット頻度を記述するプロパティがあります。つまり、WiredTigerの場合は100msの値に設定されることが多いcommitIntervalMsです。低い値に調整すると、書き込みの頻繁な記録が強化され、データ損失のインスタンスが減少します。
ロックパフォーマンス
これは、多くのクライアントからの複数の読み取りおよび書き込み要求が原因で発生する可能性があります。これが発生した場合、一貫性を維持し、書き込みの競合を回避する必要があります。これを実現するために、MongoDBは複数粒度ロックを使用して、グローバル、データベース、コレクションレベルなどのさまざまなレベルでロック操作を実行できるようにします。
スキーマデザインパターンが不十分な場合、ロックが長期間保持される可能性があります。これは、同じコレクション内の1つのドキュメントに対して2つ以上の異なる書き込み操作を行うときによく発生し、結果として相互にブロックされます。 WiredTigerストレージエンジンの場合、キューやスレッドなどから読み取りまたは書き込み要求が送信されるチケットシステムを使用できます。
デフォルトでは、読み取り操作と書き込み操作の同時数は、パラメーターwiredTigerConcurrentWriteTransactionsとwiredTigerConcurrentReadTransactionsによって定義され、どちらも値128に設定されています。
この値を大きくしすぎると、CPUリソースによって制限されることになります。スループット操作を向上させるには、より多くのシャードを提供して水平方向にスケーリングすることをお勧めします。
SomeninesがMongoDBDBAになる-MongoDBを本番環境に導入MongoDBDownloadを無料でデプロイ、監視、管理、スケーリングするために知っておくべきことを学びましょうリソースの利用
これは通常、CPU容量/処理速度やRAMなどの利用可能なリソースの使用状況を表します。特にCPUのパフォーマンスは、異常なトラフィック負荷に応じて大幅に変化する可能性があります。チェックするものは次のとおりです...
- 接続数
- ストレージ
- キャッシュ
接続数
接続数がデータベースシステムで処理できる数よりも多い場合は、多くのキューが発生します。その結果、これはデータベースのパフォーマンスを圧倒し、セットアップの実行を遅くします。この数は、ドライバーの問題やアプリケーションの複雑化につながる可能性があります。
特定の数の接続を一定期間監視し、その値がピークに達したことに気付いた場合、接続がこの数を超えた場合にアラートを設定することをお勧めします。
数が多くなりすぎている場合は、この増加に対応するためにスケールアップできます。これを行うには、特定の期間内に利用可能な接続の数を知る必要があります。そうしないと、利用可能な接続が十分でない場合、リクエストがタイムリーに処理されません。
デフォルトでは、MongoDBは最大100万の接続をサポートします。監視では、現在の接続がこの値に近づきすぎないように常に注意してください。接続オブジェクトで値を確認できます。

ストレージ
MongoDBのすべての行とデータレコードはドキュメントと呼ばれます。ドキュメントデータはBSON形式です。特定のデータベースで、コマンドdb.stats()を実行すると、このデータが表示されます。
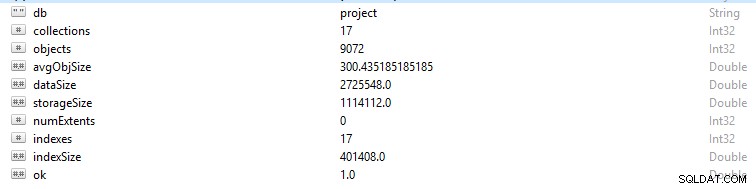
- StorageSizeは、データベース内のすべてのデータエクステントのサイズを定義します。
- IndexSizeは、そのデータベース内に作成されたすべてのインデックスのサイズの概要を示します。
- dataSizeは、データベース内のドキュメントが占める合計スペースの尺度です。
特に大量のデータが削除された場合は、メモリの変化が見られることがあります。この場合、悪意のあるアクティビティによるものではないことを確認するために、アラートを設定する必要があります。
データベーストラフィックグラフが一定であるときに全体的なストレージサイズが急増する場合があります。この場合、アプリケーションまたはデータベース構造をチェックして、不要な場合は重複しないようにする必要があります。
コンピュータの一般的なメモリと同様に、MongoDBにもアクティブデータが一時的に保存されるキャッシュがあります。ただし、操作によって、このアクティブなメモリにないデータが要求される場合があります。そのため、メインディスクストレージから要求が行われます。この要求または状況は、ページフォールトと呼ばれます。ページフォールト要求には、実行に時間がかかるという制限があり、頻繁に発生すると有害になる可能性があります。このシナリオを回避するには、RAMのサイズが、使用しているデータセットに対応するのに常に十分であることを確認してください。また、スキーマの冗長性や不要なインデックスがないことを確認する必要があります。
キャッシュ
キャッシュは、頻繁にアクセスされるデータの一時的なデータストレージアイテムです。 WiredTigerでは、ファイルシステムキャッシュとストレージエンジンキャッシュがよく使用されます。ワーキングセットが使用可能なキャッシュを超えて膨らんでいないことを常に確認してください。膨らんでいないと、ページフォールトの数が増え、パフォーマンスの問題が発生します。
ある時点で、頻繁な操作を変更することを決定する場合がありますが、変更がキャッシュに反映されない場合があります。この変更されていないデータは「ダーティデータ」と呼ばれます。まだディスクにフラッシュされていないために存在します。 「ダーティデータ」の量が、ディスクへの書き込みが遅いことで定義される平均値に達すると、ボトルネックが発生します。シャードを追加すると、この数を減らすのに役立ちます。
CPU使用率
不適切なインデックス作成、不十分なスキーマ構造、および不適切に設計されたクエリは、より多くのCPUの注意を必要とするため、明らかにその使用率が増加します。
スループット操作
これらの操作に関する十分な情報を大部分取得することで、エラー、リソースの飽和、機能の複雑化などの結果的な挫折を回避できます。
データベースへの読み取りおよび書き込み操作の数、つまりクラスターのアクティビティの高レベルのビューに常に注意する必要があります。リクエストに対して生成された操作の数を知ることで、データベースが処理すると予想される負荷を計算できます。その後、負荷はデータベースのスケールアップまたはスケールアウトのいずれかで処理できます。あなたが持っているリソースの種類に応じて。これにより、リクエストが処理されている速度に対して、リクエストが蓄積されている商の比率を簡単に測定できます。さらに、パフォーマンスを向上させるためにクエリを適切に最適化できます。
読み取りおよび書き込み操作の数を確認するには、このコマンドdb.serverStatus()を実行してから、locks.globalオブジェクトに移動します。プロパティrの値は、読み取り要求の数とw書き込みの数を表します。
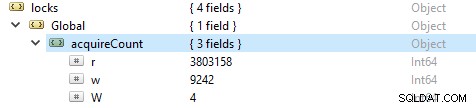
多くの場合、読み取り操作は書き込み操作以上のものです。アクティブなクライアントメトリックは、globalLockで報告されます。
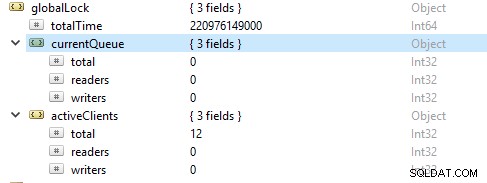
リソースの飽和と制限
キューに入れられたリクエストの数が増えることで示されるように、データベースが書き込みと読み取りの速度に追いつかない場合があります。この場合、MongoDBがリクエストに十分な速さで対応できるように、より多くのシャードを提供してデータベースをスケールアップする必要があります。
新たな挫折
MongoDBログファイルは、返されるアサート例外に関する一般的な概要を常に提供します。この結果により、エラーの考えられる原因についての手がかりが得られます。コマンドdb.serverStatus()を実行すると、次のようなエラーアラートが表示されます。

- 通常のアサート:これらは操作の失敗の結果です。たとえば、スキーマで文字列値が整数フィールドに指定されているため、BSONドキュメントの読み取りに失敗した場合。
- 警告の主張:これらは多くの場合、何らかの問題に関するアラートですが、その動作にはあまり影響を与えていません。たとえば、MongoDBをアップグレードすると、非推奨の関数を使用してアラートが表示される場合があります。
- Msgの主張:これらは、低速ネットワークなどの内部サーバー例外の結果であるか、サーバーがアクティブでない場合に発生します。
- ユーザーアサーション:通常のアサーションと同様に、これらのエラーはコマンドの実行時に発生しますが、多くの場合、クライアントに返されます。たとえば、キーが重複している場合、ディスクスペースが不十分である場合、またはデータベースに書き込むためのアクセス権がない場合です。これらのエラーを修正するには、アプリケーションを確認することを選択します。