MongoDBゾーン
MongoDBゾーンを理解するには、まずゾーンとは何か、つまり特定のタグのセットに基づくシャードのグループを理解する必要があります。
MongoDBゾーンは、シャード間でのタグに基づくチャンクの分散に役立ちます。ゾーン内のドキュメントに関連するすべての作業(読み取りと書き込み)は、そのゾーンに一致するシャードで実行されます。
シャーディングされたクラスター(ゾーンベース)が非常に有用であることが証明されるさまざまなシナリオが存在する可能性があります。例:
- 地理的に分散しているアプリケーションには、データストアだけでなくフロントエンドも必要になる場合があります
- アプリケーションにはn層アーキテクチャがあり、一部のレコードは高層(低遅延)ハードウェアからフェッチされ、他のレコードは低層(高遅延誘導)ハードウェアからフェッチされる可能性があります
MongoDBゾーンを使用する利点
DBAは、MongoDBゾーンの助けを借りて、データのライフサイクルをサポートする階層型ストレージソリューションを作成できます。使用頻度の高いデータはメモリに保存され、使用頻度の低いデータはサーバーに保存され、適切なタイミングでアーカイブされたデータはオフラインになります。
ゾーンの設定方法
シャードクラスターでは、シャードのグループを表すゾーンを作成し、1つ以上の範囲のシャードキー値をそのゾーンに関連付けることができます。 MongoDBは、ゾーン範囲に入るすべての読み取りとすべての書き込みを、ゾーン内のシャードにのみルーティングします。各ゾーンをクラスター内の1つ以上のシャードに関連付けることができ、シャードは任意の数のゾーンに関連付けることができます。
ゾーンが適用される可能性のある最も一般的な展開パターンのいくつかは次のとおりです。
- 特定のシャードセットでデータの特定のサブセットを分離します。
- 最も関連性の高いデータが、アプリケーションサーバーに地理的に最も近いシャードに存在するようにすることによって。
- シャードハードウェアのパフォーマンスに基づいて、データをシャードにルーティングします。
次の画像は、3つのシャードと2つのゾーンを持つシャードクラスターを示しています。 Aゾーンは、下限が0、上限が10の範囲を表します。Bゾーンは、下限が10、上限が20の範囲を示します。シャードREDとBLUEにはAゾーンがあります。シャードブルーにもBゾーンがあります。 ShardGREENにはゾーンが関連付けられていません。クラスターは定常状態にあり、どのチャンクもどのゾーンにも違反していません
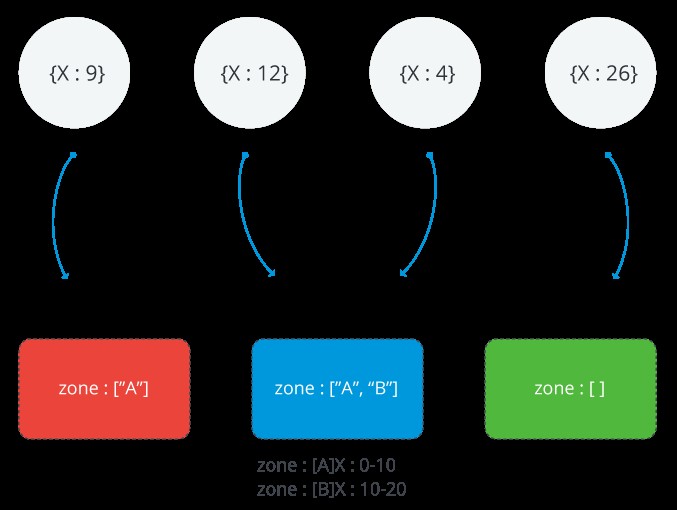
MongoDBゾーンの範囲
すべてのゾーンは、1つ以上の範囲のシャードキー値をカバーします。ゾーンがカバーする各範囲には、常に下限が含まれ、上限は含まれません。
覚えておいてください: ゾーンは範囲を共有できず、範囲が重複することもできません。
ゾーンへのシャードの追加
sh.addShardTag()メソッドは、シャードにゾーンを追加するために使用されます。 1つのシャードに複数のゾーンがあり、複数のシャードにも同じゾーンがある場合があります。次の例では、ゾーンAを1つのシャードに追加します。
sh.addShardTag("shard0000", "A")シャードをゾーンに削除する
シャードからゾーンを削除するには、sh.removeShardTag()メソッドを使用します。次の例では、ゾーンAをシャードから削除します。
sh.removeShardTag("shard0002", "A")MongoDBゾーンのヒント
ドキュメントをシンプルに保つ
MongoDBは、スキーマフリーのデータベースです。これは、デフォルトで事前定義されたスキーマがないことを意味します。新しいバージョンで事前定義されたスキーマを追加できますが、必須ではありません。アプリケーション側/ETLプロセスでデータを解析することが非常に困難になる可能性があるため、ドキュメントや配列を操作するときに発生する問題を過小評価しないでください。さらに、配列は複製のパフォーマンスを低下させる可能性があります。配列が変更されるたびに、すべての配列値が複製されます。
最良のハードウェアが常に最良の選択肢であるとは限りません
優れたハードウェアを使用すると、確実に優れたパフォーマンスが得られます。しかし、大きなマシンの1つのインスタンスが停止すると、環境で何が起こる可能性がありますか?答えは「フェイルオーバー」です。
分散環境に(1つまたは2つではなく)複数の小さなマシンを配置すると、アプリケーションによる認識がほとんどまたはまったくなく、停止がシャードのごく一部にのみ影響を与えることが保証されます。しかし同時に、マシンが増えると、障害が発生する可能性が高くなります。環境を設計するときは、このトレードオフを考慮してください。正しい選択はパフォーマンスに影響します。
ワーキングセット
ワーキングセットの大きさはどれくらいですか?通常、アプリケーションはすべてのデータを使用するわけではありません。一部のデータは頻繁に更新されますが、他のデータは更新されません。作業データセットはRAMに収まりますか?最適なパフォーマンスは、すべての作業データセットがRAMにあるときに発生します。