Apache HBaseに保存されているデータをバックアップするために利用できるメカニズムの概要と、さまざまなデータリカバリ/フェイルオーバーシナリオが発生した場合にそのデータを復元する方法を入手してください
HBaseの採用と重要なビジネスシステムへの統合が進むにつれ、多くの企業は、HBaseクラスターの堅牢なバックアップおよびディザスタリカバリ(BDR)戦略を構築することにより、この重要なビジネス資産を保護する必要があります。潜在的にペタバイトのデータをすばやく簡単にバックアップおよび復元するのは大変なことのように聞こえるかもしれませんが、HBaseとApache Hadoopエコシステムは、まさにそれを実現するための多くの組み込みメカニズムを提供します。
この投稿では、HBaseに格納されているデータをバックアップするために使用できるメカニズムの概要と、さまざまなデータ回復/フェイルオーバーシナリオが発生した場合にそのデータを復元する方法について説明します。この投稿を読んだ後、ビジネスニーズに最適なBDR戦略について知識に基づいた決定を下せるようになるはずです。また、各メカニズムの長所、短所、およびパフォーマンスへの影響を理解する必要があります。 (ここでの詳細は、CDH 4.3.0 / HBase 0.94.6以降に適用されます。)
注:この記事の執筆時点では、Cloudera Enterprise 4は、個別にライセンスされた機能として、ClouderaBDR1.0を介してHDFSおよびHiveMetastoreの本番環境に対応したバックアップおよび障害復旧機能を提供しています。 HBaseはそのGAリリースには含まれていません。したがって、このブログで説明されているさまざまなメカニズムが必要です。 (Cloudera Enterprise 5は現在ベータ版であり、Cloudera BDRを介してHBaseスナップショット管理を提供します。)
バックアップ
HBaseは、データの正確性、一貫性、バージョン管理などを保証する複雑な内部メカニズムを備えたログ構造のマージツリー分散データストアです。では、HDFSのHFilesとログ先行書き込み(WAL)の組み合わせ、および数十のリージョンサーバーのメモリに存在するこのデータの一貫したバックアップコピーをどのように取得できるでしょうか。
中断が最も少なく、データフットプリントが最小で、パフォーマンスへの影響が最も少ないメカニズムから始めて、最も中断の少ないフォークリフトスタイルのツールに進みましょう。
- スナップショット
- レプリケーション
- エクスポート
- CopyTable
- HTable API
- HDFSデータのオフラインバックアップ
次の表は、これらのアプローチをすばやく比較するための概要を示しています。これについては、以下で詳しく説明します。
| パフォーマンスへの影響 | データフットプリント | ダウンタイム | 増分バックアップ | 実装のしやすさ | 平均修復時間(MTTR) | |
| スナップショット | 最小限 | 小さな | 簡単な説明(復元時のみ) | いいえ | 簡単 | 秒 |
| レプリケーション | 最小限 | 大 | なし | 固有 | 中 | 秒 |
| エクスポート | 高 | 大 | なし | はい | 簡単 | 高 |
| CopyTable | 高 | 大 | なし | はい | 簡単 | 高 |
| API | 中 | 大 | なし | はい | 難しい | あなた次第 |
| 手動 | 該当なし | 大 | 長い | いいえ | 中 | 高 |
スナップショット
CDH 4.3.0以降、HBaseスナップショットは完全に機能し、機能が豊富で、作成中にクラスターのダウンタイムを必要としません。私の同僚のMatteoBertozziは、彼のブログエントリとその後の詳細でスナップショットを非常によく取り上げました。ここでは、概要のみを説明します。
スナップショットは、HDFS上のテーブルのストレージファイルへのUNIXハードリンクに相当するものを作成することにより、テーブルの瞬間をキャプチャするだけです(図1)。これらのスナップショットは数秒で完了し、クラスターにパフォーマンスのオーバーヘッドをほとんどかけず、わずかなデータフットプリントを作成します。データはまったく複製されませんが、小さなメタデータファイルにカタログ化されるだけです。これにより、スナップショットを復元する必要がある場合に、システムをその時点にロールバックできます。
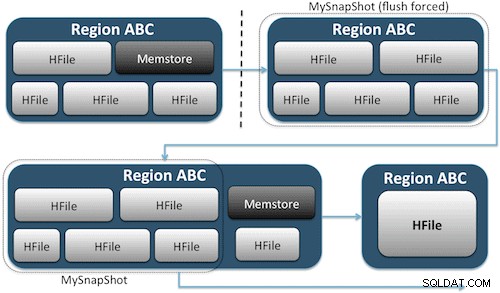
テーブルのスナップショットの作成は、HBaseシェルから次のコマンドを実行するのと同じくらい簡単です。
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
このコマンドを発行すると、HDFSの/hbase/.snapshot/myTable(CDH4)または/hbase/.hbase-snapshots(Apache 0.94.6.1)に、スナップショットを復元するために必要な情報を含む小さなデータファイルがいくつか見つかります。 。復元は、シェルから次のコマンドを発行するのと同じくらい簡単です。
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
注:ご覧のとおり、テーブルはオフラインである必要があるため、スナップショットを復元するには短時間の停止が必要です。復元されたスナップショットの作成後に追加/更新されたデータはすべて失われます。
データのオフサイトバックアップが必要なビジネス要件がある場合は、exportSnapshotコマンドを使用して、テーブルのデータをローカルHDFSクラスターまたは選択したリモートHDFSクラスターに複製できます。
スナップショットは、毎回テーブルの完全なイメージです。現在、インクリメンタルスナップショット機能は利用できません。
HBaseレプリケーション
HBaseレプリケーションは、もう1つの非常にオーバーヘッドの少ないバックアップツールです。 (私の同僚のHimanshu Vashishthaは、このブログ投稿で複製について詳しく説明しています。)要約すると、複製は列ファミリーレベルで定義でき、バックグラウンドで機能し、複製チェーン内のクラスター間ですべての編集の同期を維持します。
>レプリケーションには、マスター->スレーブ、マスター<->マスター、およびサイクリックの3つのモードがあります。このアプローチにより、任意のデータセンターからデータを取り込む柔軟性が得られ、他のデータセンターのそのテーブルのすべてのコピーにデータが確実に複製されます。 1つのデータセンターで壊滅的な停止が発生した場合、DNSツールを使用してクライアントアプリケーションをデータの別の場所にリダイレクトできます。
レプリケーションは堅牢でフォールトトレラントなプロセスであり、「結果整合性」を提供します。つまり、テーブルに対する最近の編集は、そのテーブルのすべてのレプリカで利用できるとは限りませんが、最終的にはそこに到達することが保証されます。
>注:既存のテーブルの場合、最初に、この投稿で説明されている他の方法のいずれかを使用して、ソーステーブルを宛先テーブルに手動でコピーする必要があります。レプリケーションは、有効にした後の新しい書き込み/編集に対してのみ機能します。

(Apacheのレプリケーションページから)
エクスポート
HBaseのエクスポートツールは組み込みのHBaseユーティリティであり、HBaseテーブルからHDFSディレクトリ内のプレーンなSequenceFilesにデータを簡単にエクスポートできます。クラスターに対して一連のHBaseAPI呼び出しを行うMapReduceジョブを作成し、1つずつ、指定されたテーブルからデータの各行を取得し、そのデータを指定されたHDFSディレクトリに書き込みます。このツールは、MapReduceとHBaseクライアントAPIを利用するため、クラスターのパフォーマンスをより重視しますが、機能が豊富で、バージョンまたは日付範囲によるデータのフィルタリングをサポートしているため、増分バックアップが可能です。
最も単純な形式のコマンドのサンプルを次に示します。
hbase org.apache.hadoop.hbase.mapreduce.Export
テーブルがエクスポートされると、結果のデータファイルを好きな場所(オフサイト/オフクラスターストレージなど)にコピーできます。コマンドの出力場所としてリモートHDFSクラスター/ディレクトリを指定することもできます。エクスポートすると、コンテンツがリモートクラスターに直接書き込まれます。このアプローチでは、エクスポートの書き込みパスにネットワーク要素が導入されるため、リモートクラスターへのネットワーク接続が信頼性が高く高速であることを確認する必要があることに注意してください。
CopyTable
CopyTableユーティリティについては、Jon Hsiehのブログエントリで詳しく説明されていますが、ここで基本を要約します。エクスポートと同様に、CopyTableはHBaseAPIを利用してソーステーブルから読み取るMapReduceジョブを作成します。主な違いは、CopyTableが出力をHBaseの宛先テーブルに直接書き込むことです。宛先テーブルは、ソースクラスターまたはリモートクラスターのローカルにあります。
コマンドの最も単純な形式の例は次のとおりです。
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
このコマンドは、「test」という名前のテーブルの内容を「testCopy」という名前の同じクラスター内のテーブルにコピーします。
CopyTableには、個々の「プット」を使用してデータを行ごとに宛先テーブルに書き込むという点で、パフォーマンスに大きなオーバーヘッドがあることに注意してください。テーブルが非常に大きい場合、CopyTableによって宛先リージョンサーバーのmemstoreがいっぱいになり、memstoreのフラッシュが必要になり、最終的には圧縮やガベージコレクションなどが発生する可能性があります。
さらに、HBase上でMapReduceを実行することによるパフォーマンスへの影響を考慮する必要があります。データセットが大きい場合、そのアプローチは理想的ではない可能性があります。
HTable API(カスタムJavaアプリケーションなど)
Hadoopの場合は常にそうであるように、パブリックAPIを利用し、テーブルを直接クエリする独自のカスタムアプリケーションをいつでも作成できます。これは、そのフレームワークの分散バッチ処理の利点を利用するためにMapReduceジョブを介して、または独自の設計の他の手段を介して行うことができます。ただし、このアプローチでは、Hadoop開発と、本番クラスターでそれらを使用することによるすべてのAPIとパフォーマンスへの影響を深く理解する必要があります。
生のHDFSデータのオフラインバックアップ
最もブルートフォースのバックアップメカニズム(これも最も破壊的なメカニズム)には、最大のデータフットプリントが含まれます。 HBaseクラスターをクリーンにシャットダウンし、HDFSクラスターの/hbaseにあるすべてのデータとディレクトリ構造を手動でコピーできます。 HBaseがダウンしているため、すべてのデータがHDFSのHFilesに永続化され、データの正確なコピーが取得されます。ただし、将来のバックアップを試みるときに、どのデータが変更または追加されたかを確認できないため、増分バックアップを取得することはほぼ不可能です。
.METAがあるため、データを復元するにはオフラインのメタ修復が必要になることに注意することも重要です。テーブルには、復元時に無効になる可能性のある情報が含まれます。このアプローチでは、データをオフサイトに転送し、必要に応じて後で復元するための高速で信頼性の高いネットワークも必要です。
これらの理由から、ClouderaはHBaseバックアップへのこのアプローチを強く推奨していません。
災害復旧
HBaseは、ハードウェアが頻繁に故障することを前提として、ネイティブの冗長性を備えた非常にフォールトトレラントな分散システムとして設計されています。 HBaseでのディザスタリカバリには、通常、いくつかの形式があります。
- データセンターレベルでの致命的な障害。バックアップ場所へのフェイルオーバーが必要です
- ユーザーエラーまたは誤った削除のために、データの以前のコピーを復元する必要がある
- 監査目的でデータの特定の時点のコピーを復元する機能
他の災害復旧計画と同様に、ビジネス要件によって、計画の設計方法とそれに投資する金額が決まります。選択したバックアップを確立すると、必要なリカバリのタイプに応じて、復元の形式が異なります。
- バックアップクラスターへのフェイルオーバー
- テーブルのインポート/スナップショットの復元
- HBaseルートディレクトリをバックアップ場所にポイントします
バックアップ戦略が、HBaseデータを別のデータセンターのバックアップクラスターに複製するようなものである場合、フェイルオーバーは、エンドユーザーアプリケーションをDNS技術を使用してバックアップクラスターにポイントするのと同じくらい簡単です。
ただし、停止期間中にバックアップクラスターへのデータの書き込みを許可する場合は、停止が終了したときにデータがプライマリクラスターに戻されることを確認する必要があることに注意してください。マスター間レプリケーションまたはサイクリックレプリケーションはこのプロセスを自動的に処理しますが、マスタースレーブレプリケーションスキームではマスタークラスターが同期しなくなり、停止後に手動で介入する必要があります。
前述のエクスポート機能に加えて、以前にエクスポートによってバックアップされたデータを取得してHBaseテーブルに復元できる対応するインポートツールがあります。エクスポートに適用されたのと同じパフォーマンスへの影響は、インポートにも関係しています。バックアップスキームにスナップショットの作成が含まれる場合、データの以前のコピーに戻すのは、そのスナップショットを復元するのと同じくらい簡単です。
HDFSデータ構造のブルートフォースオフラインコピーを実行した場合は、hbase-site.xmlのhbase.root.dirプロパティを変更し、/ hbaseディレクトリのバックアップコピーを指定するだけで、災害から回復することもできます。 。ただし、これは、データ構造全体を本番クラスターにコピーして戻す際に長時間の停止が必要になるため、復元オプションの中で最も望ましくありません。前述のように、.METAです。同期していない可能性があります。
結論
要約すると、何らかの形の損失または停止後にデータを回復するには、適切に設計されたBDR計画が必要です。稼働時間、データの正確性/可用性、および障害復旧に関するビジネス要件を完全に理解することを強くお勧めします。ビジネス要件に関する詳細な知識があれば、それらのニーズに最適なツールを慎重に選択できます。
ただし、ツールの選択はほんの始まりに過ぎません。 BDR戦略の大規模なテストを実行して、インフラストラクチャで機能的に機能し、ビジネスニーズを満たしていること、および運用チームが停止が発生する前に必要な手順に精通していること、およびその困難な方法を見つけていることを確認する必要があります。 BDRプランは機能しません。
このトピックについてさらにコメントまたは議論したい場合は、HBaseのコミュニティフォーラムを使用してください。
参考資料:
- JonHsiehのStrata+HadoopWorld2012プレゼンテーション
- HBase:決定的なガイド (ラーズジョージ)
- HBaseの動作 (ニック・ディミドゥク/アマンディープ・フラーナ)