MongoDBは、10年以上前から存在しているドキュメントデータストアです。ここ数年で、MongoDBは、スケーラビリティ、セキュリティ、復元力などのエンタープライズグレードのオプションを備えた成熟した製品に進化しました。ただし、要求の厳しいクラウドムーブメントでは、十分ではありませんでした。
仮想マシン、コンテナ、サーバーレスコンピューティングリソース、データベースなどのクラウドリソースは、現在高い需要があります。最近では、多くのソフトウェアソリューションを、自分のハードウェアに展開するのにかかっていた時間の何分の1かでスピンアップすることができます。それはトレンドを開始し、同時に市場の期待を変えました。
しかし、オンラインサービスの品質は、展開だけに限定されません。多くの場合、ユーザーは、作業を行うのに役立つ追加のサービス、統合、または追加の機能を必要とします。クラウドサービスは依然として非常に制限されている可能性があり、自動化とリモートインフラストラクチャから得られるものよりも多くの問題を引き起こす可能性があります。
では、MongoDB Inc.のこの一般的な問題へのアプローチは何ですか?
- MongoDBチャート
- MongoDB Stich
- MongoDBKubernetesとOpsManagerの統合
- MongoDBクラウドの移行
- 全文検索
- MongoDBデータレイク(ベータ版)
MongoDBチャート
MongoDB Chartsは、MongoDBAtlasプラットフォームからアクセスできるサービスの1つです。これは、MongoDB内にあるデータを視覚化する簡単な方法を提供するだけです。 MongoDB Chartsはデータドキュメントを処理し、データを簡単に視覚化できるように設計されているため、データを別のリポジトリに移動したり、独自のコードを記述したりする必要はありません。
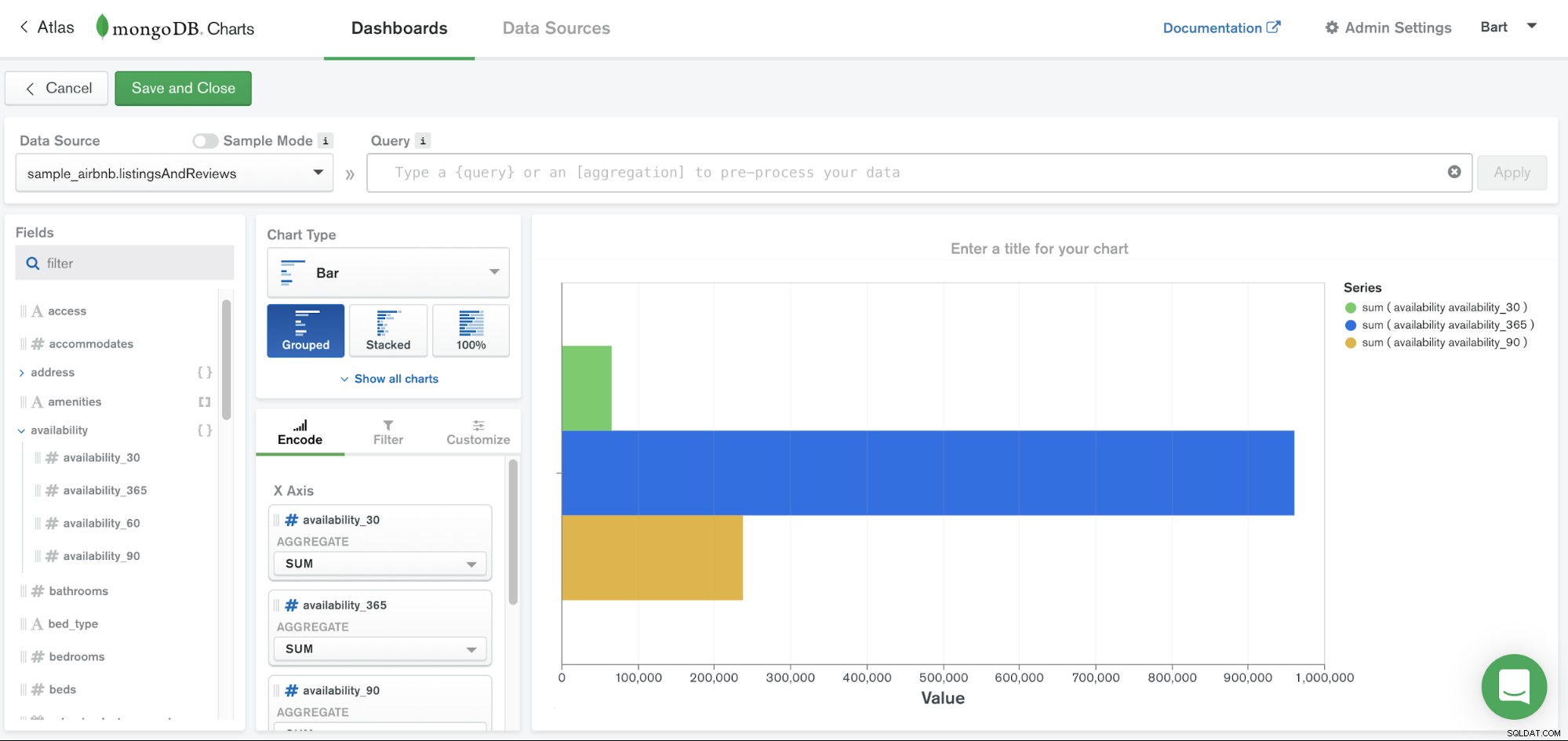
MongoDBチャートは、組み込みツールを提供することにより、データの伝達を簡単なプロセスにします。視覚化を簡単に共有および共同作業できます。データの視覚化は、データを明確に理解し、変数間の相関関係を強調し、データセット内のパターンと傾向を簡単に識別できるようにするための重要なコンポーネントです。
集約フレームワークは、さまざまな段階でドキュメントを操作し、提供された基準に従ってドキュメントを処理してから、計算結果を返す運用プロセスです。複数のドキュメントの値がグループ化され、一致する結果を返すためにさらに多くの操作を実行できます。
MongoDBチャートは、組み込みの集計機能を提供します。集計を使用すると、さまざまな指標で収集データを処理し、平均や標準偏差などの計算を実行できます。
チャートは、MongoDBAtlasとのシームレスな統合を提供します。 MongoDBチャートをAtlasプロジェクトにリンクして、Atlasクラスターデータの視覚化をすぐに開始できます。
MongoDBチャートは、ドキュメントデータモデルの利点をネイティブに理解しています。固定オブジェクトや配列など、ドキュメントベースのデータを管理します。ネストされたデータ構造を使用すると、視覚化機能を維持しながら、アプリケーションに合わせてデータを構造化する柔軟性が得られます。
MongoDBチャートには、さまざまな指標を使用してコレクションデータを処理できる組み込みの集計機能があります。開発者以外でも十分直感的に使用できるため、セルフサービスのデータ分析が可能であり、データ分析チームにとって優れたツールになります。
MongoDBステッチ
サーバーレスアーキテクチャについて聞いたことがありますか?
サーバーレスを使用すると、アプリケーションを個別の自律機能に構成できます。各関数はサーバーレスプロバイダーによってホストされ、関数呼び出しの頻度が増減するときに自動的にスケーリングできます。これは、コンピューティングリソースの支払いに非常に費用対効果の高い方法であることがわかりました。アプリケーションを常にオンにして、非常に多くの異なるインスタンスでリクエストを待つのではなく、関数が呼び出された時間に対してのみ料金を支払います。
MongoDB Stitchは、最も有用なものだけを使用する別の種類のMongoDBサービスです。クラウドインフラストラクチャ環境。これは、開発者がサーバーインフラストラクチャをセットアップせずにアプリケーションを構築できるようにするサーバーレスプラットフォームです。ステッチはMongoDBAtlas上で行われ、データベースへの接続を自動的に統合します。開発するプラットフォームの多くで利用できるStitchClientSDKを介してStitchに接続できます。
MongoDBKubernetesとOpsManagerの統合
Ops Managerは、独自のインフラストラクチャで実行するMongoDBクラスターの管理プラットフォームです。 Ops Managerの機能には、レプリカセットとシャードクラスター、およびその他のMongoDB製品の監視、アラート、ディザスタリカバリ、スケーリング、デプロイ、アップグレードが含まれます。 2018年、MongoDBはKubernetesとのベータ統合を導入しました。
MongoDB Enterprise Operatorは、Kubernetesv1.11以降と互換性があります。 Openshift3.11に対してテストされています。このオペレーターには、OpsManagerまたはCloudManagerが必要です。このドキュメントでは、「Ops Manager」を指す場合、「CloudManager」に置き換えることができます。機能は同じです。
インストールは非常に簡単で、必要です
- MongoDBEnterpriseOperatorのインストール。これは、helmまたはYAMLファイルを介して実行できます。
- OpsManagerのプロパティを収集します。
- KubernetesConfigMapファイルを作成して適用する
- OpsManagerAPIキーを保存するKubernetesシークレットオブジェクトを作成します
この基本的な例では、YAMLファイルを使用します:
kubectl apply -f crds.yaml
kubectl apply -f https://raw.githubusercontent.com/mongodb/mongodb-enterprise-kubernetes/master/mongodb-enterprise.yaml次のステップは、ConfigMapファイルで使用する次の情報を取得することです。これらはすべて、運用マネージャーにあります。
- ベースURL。 Base Urlは、OpsManagerまたはCloudManagerのURLです。
- プロジェクトID。 KubernetesオペレーターがデプロイするOpsManagerプロジェクトのID。
- ユーザー。既存のOpsManagerユーザー名
- パブリックAPIキー。 KubernetesOperatorがOpsManagerRESTAPIエンドポイントに接続するために使用します
必要なOpsManager構成情報を取得したので、Kubernetes用のKubernetesConfigMapファイルを作成する必要があります。演習の目的で、このファイルをproject.yamlと呼ぶことができます。
apiVersion: v1
kind: ConfigMap
metadata:
name:<<Name>>
namespace: mongodb
data:
projectId:<<Project ID>>
baseUrl: <<OpsManager URL>>次のステップは、KubernetesとシークレットファイルへのConfigMapを作成することです
kubectl apply -f my-project.yaml
kubectl -n mongodb create secret generic <<Name of credentials>> --from-literal="user=<<User>>" --from-literal="publicApiKey=<<public-api-key>>"取得したら、最初のクラスターをデプロイできます
apiVersion: mongodb.com/v1
kind: MongoDbReplicaSet
metadata:
name: <<Replica set name>>
namespace: mongodb
spec:
members: 3
version: 4.2.0
persistent: false
project: <<Name value specified in metadata.name of ConfigMap file>>
credentials: <<Name of credentials secret>>詳細な手順については、MongoDBのドキュメントをご覧ください。
MongoDBクラウドの移行
Atlas Live Migration Serviceは、AWS、Azure、GCP、オンプレミスのいずれであっても、既存の環境からMongoDBのグローバルクラウドデータベースであるMongoDBAtlasにデータを移行できます。
ライブマイグレーションは、MongoDBAtlasのクラスターをソースデータベースと同期させることで機能します。このプロセスの間、アプリケーションはソースデータベースからの読み取りと書き込みを続行できます。プロセスは今後の変更を監視するため、すべてが複製され、移行はオンラインで実行できます。アプリケーションの接続設定をいつ変更するかを決定し、カットオーバーを実行します。プロセスを実行しにくいAtlasは、ホワイトリストIPアクセス、SSL構成、CAなどをチェックする検証オプションを提供します。
全文検索は、MongoDBが提供するもう1つのサービスクラウドサービスであり、MongoDBAtlasでのみ利用できます。 Atlas以外のMongoDBデプロイメントでは、テキストのインデックス作成を使用できます。 Atlas全文検索は、オープンソースのApacheLuceneに基づいて構築されています。 Luceneは強力なテキスト検索ライブラリです。 Luceneには、インデックスをクエリするためのカスタムクエリ構文があります。これは、ElasticsearchやApacheSolrなどの一般的なシステムの基盤です。全文検索用のインデックスを作成できます。検索、保存、読み取りが可能です。 Atlas MongoDBに完全に統合されているため、プロビジョニングや管理を行うための追加のシステムやインフラストラクチャはありません。
MongoDBデータレイク(ベータ版)
MongoDBDataLakeで言及したい最後のMongoDBクラウド機能。これは、データレイクの一般的な概念に対応するかなり新しいサービスです。データレイクは生データの膨大なプールであり、その目的はまだ定義されていません。データを専用のデータストアに配置する代わりに、元の形式でデータレイクに移動します。これにより、変換などのデータ取り込みの初期コストが排除されます。データがに配置されると。
Atlas Data Lakeを使用してS3データをAtlasクラスターに取り込むと、Mongo Shell、MongoDB Compass、および任意のMongoDBドライバーを使用してAWSS3バケットに保存されているデータをクエリできます。