このブログ投稿では、S3に格納され、CDPのData DiscoveryandExplorationクラスターでホストされているApacheSolrサービスによって提供されるデータを取得する方法に関する簡単な「HelloWorld」の例を紹介します。好奇心旺盛な方へ:DDEは、CDPで事前にテンプレート化されたSolrに最適化されたクラスター展開オプションであり、最近技術プレビューでリリースされました。 。このブログでは、AWS環境とS3環境についてのみ説明します。 AzureとADLSの展開オプションは、技術プレビューでも利用できますが、今後のブログ投稿で取り上げられる予定です。
簡単に始められるように、最も単純なシナリオを示します。もちろん、より高度なデータパイプライン設定とより豊富なスキーマが可能ですが、これは初心者にとって良い出発点です。
前提条件:
- すでにCDPアカウントを持っており、このサービスを起動する予定の環境のパワーユーザーまたは管理者権限を持っています。
CDP AWSアカウントをお持ちでない場合は、お気に入りのCloudera担当者に連絡するか、ここでCDPトライアルにサインアップしてください。 - 環境とIDがマッピングおよび構成されています。より明確に言うと、必要なのは、CDPユーザーをAWSロールにマッピングして、読み取り(および書き込み)する特定のs3バケットへのアクセスを許可することだけです。
- ワークロード(FreeIPA)パスワードがすでに設定されています。
- DDEクラスターが実行されています。 CDP Data Hubでのテンプレートの使用に関する詳細については、こちらをご覧ください。
- そのクラスターへのCLIアクセスがあります。
- AWSでは、IPアドレスと同様にSSHポートが開いています。 Datahubクラスターの詳細内のSolrノードの1つのパブリックIPアドレスを取得できます。 AWSクラスターにSSHで接続する方法についてはこちらをご覧ください。
- S3バケットにユーザーがアクセスできるログファイルがあります(この例では
/sample.log)。お持ちでない場合は、こちらから使用したものへのリンクをご覧ください。
ワークフロー
次のセクションでは、DDEに付属しているCrunchIndexerToolを使用してデータのインデックスを作成する手順について説明します。

インデックスを保持するコレクションを作成する
HUEにはインデックスデザイナーがいます。ただし、DDEがTech Previewにある限り、DDEは多少再構築中であるため、現時点ではお勧めしません。ただし、DDEがGAになった後で試してみて、ご意見をお聞かせください。
今のところ、CLIツール「solrctl」を使用してSolrスキーマと構成を作成できます。 「my-own-logs-config」という構成と「my-own-logs」というコレクションを作成します。これには、CLIアクセスが必要です。
1.クラスター内の任意のワーカーノードにSSHで接続します。
2.コレクション構成を作成する権限を持つユーザーとしてのkinit:
キニット
3.SOLR_ZK_ENSEMBLE環境変数が/etc/solr/conf/solr-env.shに設定されていることを確認します。これは以降の手順で必要になるため、その値を保存します。
Enterキーを押して、ワークロード(FreeIPA)パスワードを入力します。
例:
cat /etc/solr/conf/solr-env.sh
期待される出力:
export SOLR_ZK_ENSEMBLE =zk01.example.com:2181、zk02.example.com:2181、zk03.example.com:2181 / solr
これは、ClouderaManagerでSolrサーバーまたはゲートウェイの役割を持つホストに自動的に設定されます。
4.コレクションの構成ファイルを生成するには、次のコマンドを実行します。
solrctl config --create my-own-logs-config schemalessTemplate -p immutable =false
schemalessTemplateは、CDPのSolrに付属しているデフォルトのテンプレートの1つですが、テンプレートであるため、不変です。このワークフローの目的のために、それをコピーして、変更可能な新しいワークフローを作成する必要があります(これはimmutable =falseオプションが行うことです)。これにより、柔軟でスキーマレスな構成が可能になります。適切に設計されたスキーマを作成することは、設計時間を費やす価値のあるものですが、探索的な使用には必要ありません。このため、このブログ投稿の範囲を超えています。ただし、実際の本番環境では、適切に設計されたスキーマを使用することを強くお勧めします。必要に応じて、専門家によるサポートを提供させていただきます。
5.次のコマンドを使用して、新しいコレクションを作成します。
solrctlコレクション--createmy-own-logs-s 1 -c my-own-logs-config
これにより、1つのシャードの「my-own-logs-config」コレクション構成に基づいて「my-own-logs」コレクションが作成されます。
6.コレクションが作成されたことを検証するために、Solr管理UIにナビゲートできます。 「my-own-logs」のコレクションは、左側のナビゲーションのドロップダウンから利用できます。

データのインデックスを作成
ここでは、簡単な例を使用して、組み込みのCrunch Indexer Toolを構成および実行して、S3でデータにすばやくインデックスを付け、DDEでSolrを介して提供する方法について説明します。クラスタのセキュリティ保護にはCMAutoTLS、Knox、Kerberos、およびRangerが利用される可能性があるため、「Sparksubmit」はこの投稿でカバーされていない側面に依存する可能性があります。
S3からのデータのインデックス作成は、HDFSからのインデックス作成とまったく同じです。
これらの手順は、Yarnワーカーノード(管理コンソールwebUIでは「Yarnworker」と呼ばれます)で実行します。
1. Solr管理者ユーザーとしてDDEクラスターの専用YarnワーカーノードにSSHで接続します。
YarnワーカーノードのIPアドレスを確認するには、ハードウェアをクリックします。 クラスタの詳細ページのタブをクリックし、[Yarnworker]ノードまでスクロールします。

2.リソースディレクトリに移動します(または、まだ作成していない場合は作成します:
cd
管理者ユーザーのホームフォルダをリソースディレクトリとして使用します(
3.ユーザーをキニトします:
キニット
Enterキーを押して、ワークロード(FreeIPA)パスワードを入力します。
4.
curl --negotiate -u: "https://: / solr / admin?op =GETDELEGATIONTOKEN "--insecure> tokenFile.txt
5. Crunch Indexer ToolのMorphline構成ファイル(この例ではread-log-morphline.conf)を作成します。
SOLR_LOCATOR:{#solrコレクションコレクションの名前:my-own-logs #zk ensemble zkHost: } morphlines:[{id:loadLogs importCommands:["org.kitesdk。**"、 "org.apache.solr。**"]コマンド:[{readMultiLine {regex: "(^。+ Exception:。+)| (^ \\ s + at。+)|(^ \\ s+\\。\\。\\。\\d+ more)|(^ \\ s *原因:。+) "what:previous charset:UTF -8}}} {logDebug {format: "output record:{}"、args:["@ {}"]}} {loadSolr {}}}
このMorphlineは、指定されたログファイルからスタックトレースを読み取り、デバッグエントリログを書き込んで、指定されたSolrにロードします。
6.ログ構成用のlog4j.propertiesファイルを作成します。
log4j.rootLogger =INFO、A1#A1はConsoleAppender.log4j.appender.A1 =org.apache.log4j.ConsoleAppender#に設定されていますA1はPatternLayout.log4j.appender.A1.layout=org.apache.log4jを使用します.PatternLayoutlog4j.appender.A1.layout.ConversionPattern =%-4r [%t]%-5p%c%x-%m%n
7.読み取りたいファイルがS3に存在するかどうかを確認します(ファイルがない場合は、この簡単な例で使用したファイルへのリンクを次に示します:
aws s3 ls s3:// /sample.log
8.spark-submitコマンドを実行します。
export myDriverJarDir =/ opt / cloudera / parcels / CDH / lib / solr / contrib / crunchexport myDependencyJarDir =/ opt / cloudera / parcels / CDH / lib / search / lib / search-crunchexport myDriverJar =$(find $ myDriverJarDir- maxdepth 1 -name'search-crunch-*。jar'!-name'* -job.jar'!-name'*-sources.jar')export myDependencyJarFiles =$(find $ myDependencyJarDir -name'* .jar' | sort | tr'\ n''、' | head -c -1)export myDependencyJarPaths =$(find $ myDependencyJarDir -name'* .jar' | sort | tr'\ n'':' | head -c -1) export myJVMOptions ="-DmaxConnectionsPerHost =10000 -DmaxConnections =10000 -Djava.io.tmpdir =/ tmp / dir /" export myResourcesDir =" "export HADOOP_CONF_DIR =" / etc / hadoop / conf "spark-submit \ --master yen \ --deploy-mode cluster \ --jars $ myDependencyJarFiles \ --executor-memory 1024M \ --conf" spark.executor.extraJavaOptions =$ myJVMOptions "\ --driver-java-options" $ myJVMOptions "\ --class org.apache.solr.crunch.CrunchIndexerTool \ --files $(ls $ myResourcesDir / log4j.properties)、$(ls $ myResourcesDir / read-log-morphline.conf)、tokenFile.txt \ $ myDriverJar \ -Dhadoop.tmp.dir =/ tmp \ -DtokenFile =tokenFile.txt \ --morphline-file read-log-morphline.conf \ --morphline- id loadLogs \ --pipeline-type spark \ --chatty \ --log4j log4j.properties \ s3a:// /sample.log
同様のメッセージが表示された場合は、無視してかまいません:
警告metadata.Hive:すべてのfunctions.org.apache.hadoop.hive.ql.metadata.HiveException:org.apache.thrift.transport.TTransportExceptionの登録に失敗しました
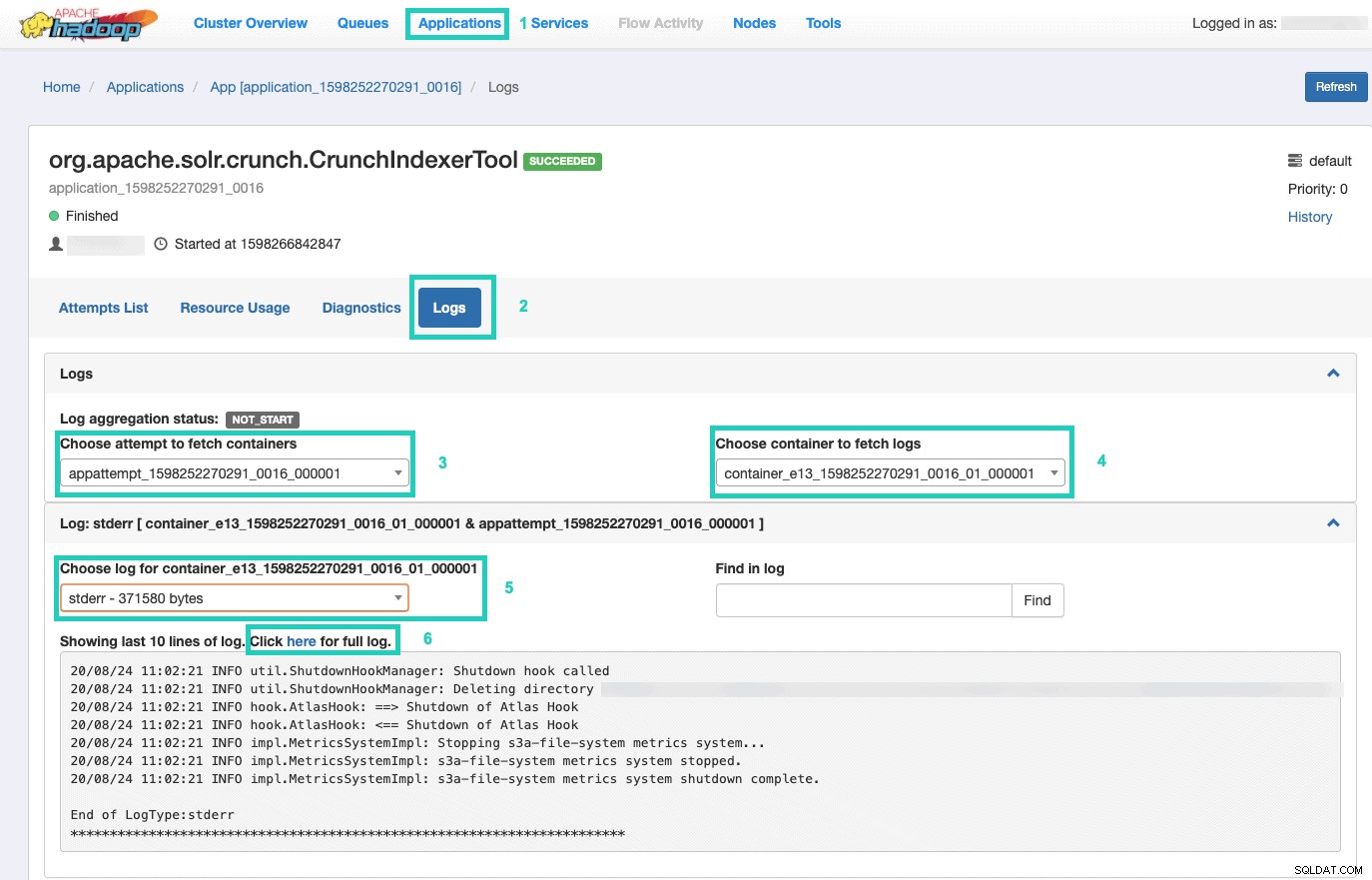
9.コマンドの実行を監視するには、リソースマネージャーに移動します。

そこで、アプリケーションを選択します タブ> アプリケーションIDをクリックします 監視するアプリケーションの試行回数> ログ>コンテナの取得の試行を選択>ログを取得するコンテナを選択>コンテナのログを選択> stderrを選択します ログ>完全なログについてはここをクリックをクリックしてください 。
インデックスを提供する
検索可能なインデックス付きデータをエンドユーザーに提供する方法には、多くのオプションがあります。 SolrのリッチAPI(非常に一般的)に基づいて独自のリッチアプリケーションを構築できます。 Qlik、Tableauなどのお気に入りのサードパーティツールを、認定されたSolr接続を介して接続できます。 Hueのシンプルなsolrダッシュボードを使用して、プロトタイプアプリケーションを構築できます。
後者を行うには:
1.色相に移動します。

2.ダッシュボードビューで、選択したインデックスファイル(作成したばかりのインデックスファイルなど)に移動します。
3.さまざまなダッシュボード要素のドラッグアンドドロップを開始し、インデックスからフィールドを選択して、手元のビジュアルのデータを入力します。
インスピレーションを得るために、過去のダッシュボードチュートリアルビデオをここで簡単に見つけることができます。
今後のブログ投稿のために、さらに深く掘り下げていきます。
概要
Crunch Indexer Toolを使用して、DDEでSolrによってインデックス付けされたS3のデータを取得する方法について、このブログ投稿から多くのことを学んだことを願っています。もちろん、他にも多くの方法があります(データエンジニアリングエクスペリエンスのSpark、データフローエクスペリエンスのNifi、ストリーム管理エクスペリエンスのKafkaなど)が、それらは将来のブログ投稿で取り上げられます。テキストやその他の非構造化データを含む強力なインサイトアプリケーションを構築するための継続的な旅で、あなたが非常に成功することを願っています。 CDPでDDEを試すことにした場合は、すべてがどのように進んだかをお知らせください。