このビッグデータHadoopチュートリアル 、HadoopHDFSデータブロックの詳細な説明を提供します。まず、Hadoopのデータブロックとは何か、それらの重要性、HDFSデータブロックのサイズが128MBである理由について説明します。
また、Hadoopのデータブロックの例とHadoopのHDFSのさまざまな利点についても説明します。
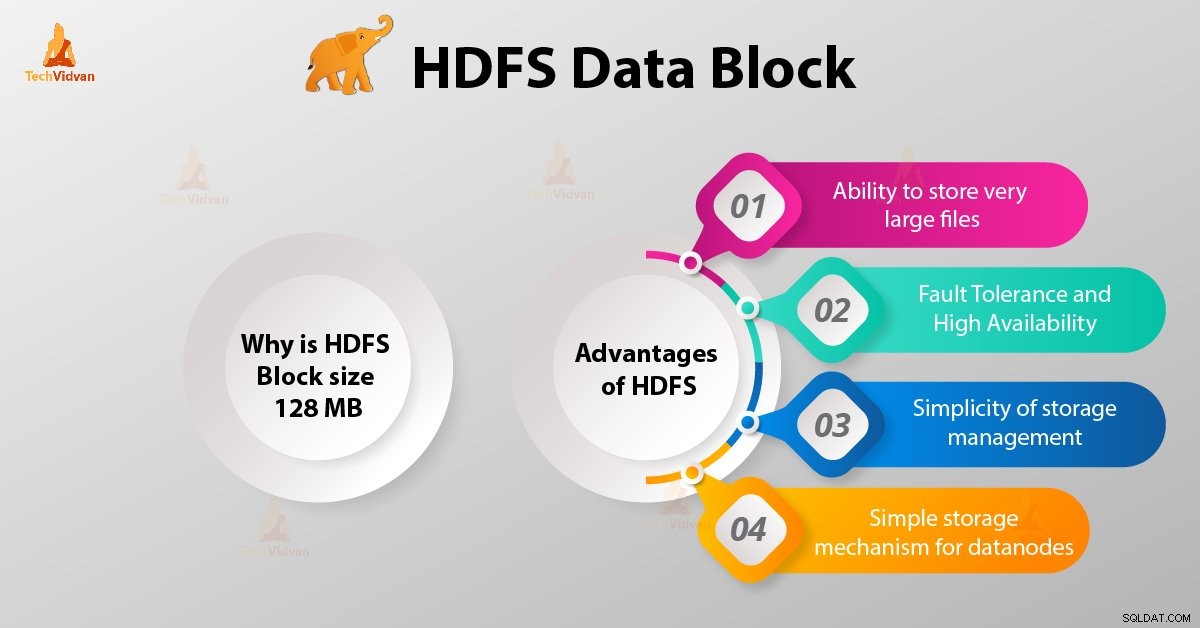
HDFSデータブロックの概要
Hadoop HDFS 大きなファイルをブロックと呼ばれる小さなチャンクに分割します 。ブロックは、データの物理的表現です。読み取りまたは書き込みが可能な最小量のデータが含まれています。 HDFSは、各ファイルをブロックとして保存します。 HDFSクライアントは、ブロックの場所などのブロックを制御できません。Namenodeがそのようなすべてを決定します。
デフォルトでは、HDFSブロックサイズは 128MB です 要件に応じて変更できます。すべてのHDFSブロックは、同じサイズ以下の最後のブロックを除いて同じサイズです。
Hadoopフレームワークは、ファイルを128 MBのブロックに分割してから、Hadoopファイルシステムに保存します。 Apache Hadoopアプリケーションは、データブロックを複数のノードに分散する役割を果たします。
例-
ファイルサイズが513MBで、ブロックサイズ128MBのデフォルト構成を使用しているとします。次に、Hadoopフレームワークは5つのブロックを作成し、最初の4つのブロックは128MBになりますが、最後のブロックは1MBのみになります。
したがって、この例から、HDFSに保存される各ファイルは、構成されたブロックサイズ128 mb、256 mbなどの正確な倍数である必要はないことが明らかです。したがって、ファイルの最終ブロックは、必要なだけのスペースを使用します。
HDFSブロックサイズが128MBなのはなぜですか?
HDFSは、テラバイトとペタバイトのデータを保存します。 LinuxファイルシステムのようにHDFSブロックサイズが4kbの場合、Hadoop HDFSのデータブロックが多すぎるため、メタデータが多すぎます。
したがって、この膨大な数のブロックとメタデータを維持および管理すると、膨大なオーバーヘッドとトラフィックが発生しますが、これは私たちが望んでいないことです。
ブロックサイズは、システムがデータ処理の最後の1つのユニットが作業を完了するのを非常に長い時間待機するほど大きくすることはできません。
HDFSの利点
HDFSデータブロックとは何かを学んだ後、HadoopHDFSの利点について説明しましょう。
1。非常に大きなファイルを保存する機能
Hadoop HDFSは、Hadoopフレームワークがファイルをブロックに分割し、さまざまなノードに分散するため、単一のディスクのサイズよりもさらに大きい非常に大きなファイルを保存します。
2。フォールトトレランスとHDFSの高可用性
Hadoopフレームワークは、データノード間でブロックを簡単に複製できます。したがって、フォールトトレランスと高可用性を提供します HDFS。
3。ストレージ管理のシンプルさ
HDFSのブロックサイズは固定(128MB)であるため、ディスクに保存できるブロック数の計算は非常に簡単です。
4。データノードのシンプルなストレージメカニズム
HDFSのブロックにより、データノードのストレージが簡素化されます 。 Namenode すべてのブロックのメタデータを維持します。 HDFS Datanodeは、ファイルのアクセス許可などのブロックメタデータについて心配する必要はありません。
結論
したがって、HDFSデータブロックはファイルシステム内のデータの最小単位です。 HDFSブロックのデフォルトサイズは128MBで、要件に応じて構成できます。 HDFSブロックは、データノード間で簡単に複製できます。したがって、フォールトトレランスとHDFSの高可用性を提供します。
Hadoop HDFSデータブロックに関連する質問や提案については、以下のセクションにコメントを残してお知らせください。