これはこのブログシリーズのパート2です。ここでパート1を読むことができます: デジタルトランスフォーメーションは、エッジからインサイトへのデータジャーニーです
このブログシリーズは、コネクテッドカーメーカーの製造、運用、販売のデータをフォローしています。データは、現在のテクノロジーの最先端にある大手製造会社で通常経験される段階と変換を経ています。最初のブログでは、模擬コネクテッドカー製造会社であるThe Electric Car Company(ECC)を紹介し、データライフサイクル全体の製造データパスを説明しました。これを実現するために、ECCはCloudera Data Platform(CDP)を活用してイベントを予測し、世界中にある工場内の自動車の製造プロセスをトップダウンで表示します。
前のブログのデータ収集ステップを完了した後、データライフサイクルにおけるECCの次のステップはデータエンリッチメントです。 ECCは収集されたデータを充実させ、データライフサイクルの後半で分析とモデル作成に使用できるようにします。以下は、データライフサイクルのすべてのステップです。ライフサイクルの各ステップは、専用のブログ投稿によってサポートされます(図1を参照)。
- データ収集 –エッジでのデータの取り込みと監視(エッジが産業用センサーであるか、車両のショールームにいる人であるかを問わず)
- データの強化 –データパイプラインの処理、集約、および管理により、データをさらに分析できるようにします
- レポート –ビジネスインサイトの提供(販売分析と予測、例としての予算編成)
- サービング –重要なビジネスオペレーション(ディーラーオペレーション、生産監視)の制御と実行
- 予測分析 – AIと機械学習に基づく予測分析(例として、予知保全、需要ベースの在庫最適化)
- セキュリティとガバナンス –データライフサイクル全体にわたるセキュリティ、管理、およびガバナンステクノロジーの統合セット

図1エンタープライズデータのライフサイクル
データエンリッチメントチャレンジ
ECCには、車両の製造、ディーラー業務、および出荷に関連するすべてのデータの包括的なビューと強力な理解が必要です。また、計画外の機械の停止や突然の起動によって引き起こされる誤った温度スパイクを含む可能性のあるデータのスピンオフなど、データに関する問題を迅速に特定する必要があります。たとえば、保守作業員が定期検査中に酸浸漬タンクからセンサーを取り外すプロセスとは関係のないデータは、分析で考慮されるべきではありません。
さらに、ECCは、モーター製造をサプライチェーン全体にうまく移行させるために対処する必要のある次のデータの課題に直面しています。これらのデータの課題には、次のものが含まれます。
- さまざまなソースからさまざまな形式のデータを取得する: データエンジニアリングパイプラインでは、さまざまなソースからさまざまな形式でデータを取り込む必要があります。データが生産ラインにあるセンサーから供給されているか、製造操作をサポートしているか、サプライチェーンを制御するERPデータから供給されているかにかかわらず、さらに分析するためにすべてをまとめる必要があります。
- 冗長または無関係なデータを除外する: 重複または無効なデータを削除し、残りのデータの正確性を確保することは、高度な予測分析でさらに使用するためにデータを準備するための重要なステップです。
- 非効率的なプロセスを特定する機能: ECCには、どのデータプロセスが最も時間とリソースを消費しているかを確認する機能が必要です。これにより、プロセス全体を高速化するために、パイプラインのパフォーマンスの低い部分を簡単にターゲットにできます。
- 単一のペインからすべてのプロセスを監視する機能: ECCには、進行中のすべてのデータプロセスを監視できる一元化されたシステムと、透明性を維持しながら現在のインフラストラクチャを拡張する手段が必要です。
厳選された高品質のデータセットは、高度な分析イニシアチブのバックボーンです。これを実現するには、データエンジニアリングフレームワークを使用して、データライフサイクル内のさまざまな車両部品のデータを移動、操作、および管理するために必要なすべての配管と配管を構築できるようにする必要があります。
Clouderaデータエンジニアリングを使用したパイプラインの構築
データが強化され、最初のブログで説明される前に、工場から収集されたITおよびOTデータストリームは、クリーンアップ、操作、および変更されます。工場ID、マシンID、タイムスタンプ、部品番号、およびシリアル番号は、電気モーターに刻印されたQRコードから取得できます。モーターがコネクテッドカーに組み込まれると、モデルタイプ、VIN、基本車両コストなどのデータが収集されます。
車両の販売後、顧客名、連絡先情報、最終販売価格、顧客の場所などの販売情報が個別に記録されます。このデータは、潜在的なリコールや対象を絞った予防保守についてお客様に連絡するために重要です。地理位置データも保存されます。これは、顧客の位置を緯度と経度にマッピングして、これらのモーターが車両で販売された後の位置をよりよく理解するのに役立ちます。
ECCはClouderaDataEngineering(CDE)を使用して、上記のデータの課題に対処します(図2を参照)。その後、CDEはデータをCloudera Data Warehouse(CDW)で利用できるようにし、高度な分析とビジネスインテリジェンスレポートで利用できるようにします。 CDEの手順の概要を以下に示します。
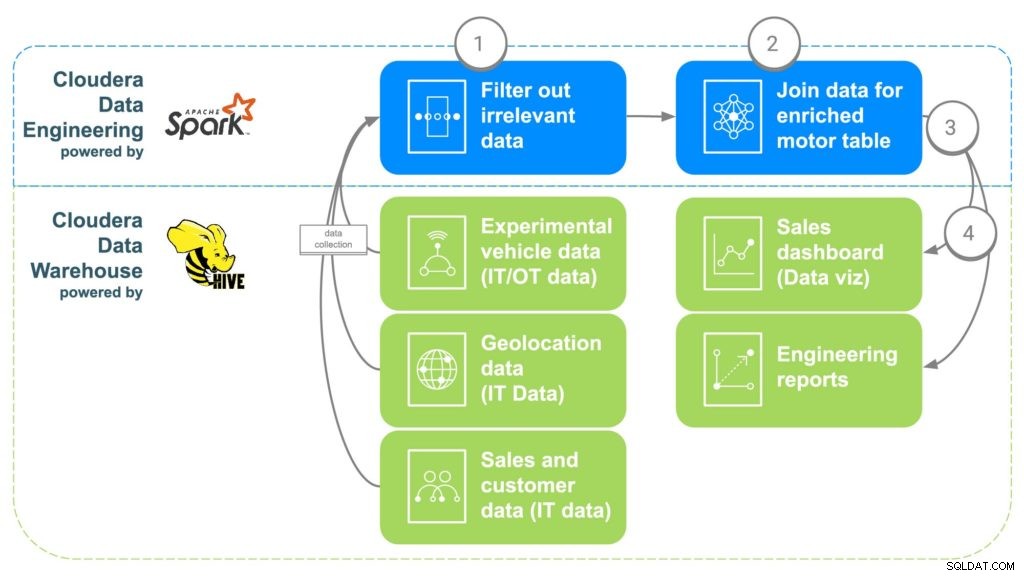
図2ECCデータエンリッチメントパイプライン
ステップ1:データをフィルタリングして分離する
CDEを使用する最初のステップは、ステップ1のこれらのさまざまな「生の」ソースからのデータを取り込むPySparkジョブを作成することです。これは、たとえば、16歳未満の顧客など、無関係なデータをフィルタリングする機会です。通常、最低運転年齢です。重複するデータやその他の無関係なデータもフィルタリングまたは分離できます。
ステップ2:データを組み合わせる
すべてのデータを結合するために、CDEは共通のリンクを相互に関連付けます。まず、自動車販売データを購入した顧客に関連付けて、連絡先情報、年齢、給与などの顧客メタデータを取得します。次に、地理位置データを使用して、顧客のより正確な位置情報を取得します。 、後でモーターをマッピングするのに役立ちます。部品の取り付けデータは、お客様の車に取り付けられた各モーターのシリアル番号を識別するために使用されます。最後に、工場データは、どの工場、機械、および特定の各モーターがいつ作成されたかを識別するモーターのシリアル番号と一致するように調整されます。
ステップ3:Clouderaデータウェアハウスにデータを送信する
すべてのデータが強化されたテーブルにまとめられると、単純なApacheSparkコマンドがデータをClouderaデータウェアハウス内の新しいテーブルに書き込みます。これにより、追加の分析を行うためにデータにアクセスしたいデータサイエンティストがデータにアクセスできるようになります。
ステップ4:データ視覚化ダッシュボードとレポートを生成する
すべてのデータを1か所にまとめることで、レポートを作成できるようになりました。これにより、従業員は十分な情報に基づいた意思決定を行い、存在しなかった機能を利用できるようになります。ヒートマップを作成して、モーターの位置を追跡し、極端な寒さや暑さによる障害など、問題を潜在的な地理的位置と関連付けることができます。このデータを使用して、特定の工場で問題が発生した場合に影響を受ける可能性のある顧客を正確に追跡できるため、リコールや予防保守が必要な顧客を簡単に追跡できます。
結論
Cloudera Data Engineeringを使用すると、ECCは、顧客満足度と車両の信頼性を向上させるために、製造データと部品データ、顧客の使用タイプ、環境条件、販売情報などを相互に関連付けることができるパイプラインを構築できます。 ECCは、モーターの製造に関連するデータを追跡し、次の方法で利益を得ることで、目的を達成し、課題に対処しました。
- ECCは、データパイプラインを調整および自動化して、さまざまなデータソースから厳選された高品質のデータセットを安全かつ透過的に配信することで、価値実現までの時間を短縮しました。
- ECCは、関連するデータを識別し、冗長で重複するデータを除外することができました。
- ECCは、ビジネスに影響が出る前に問題を迅速に解決するための視覚的なトラブルシューティングを通じて問題を早期に発見するように警告される立場にありながら、単一のペインからデータパイプラインの監視を実現できました。
レポーティングについて詳しく説明する次のブログを探してください。このブログでは、ECCエンジニアがこのキュレートされたデータに対してCDWでアドホッククエリを実行し、エンタープライズデータウェアハウス内の他の関連ソースにデータを結合する方法を示します。 CDWは、すべてのデータをまとめることを容易にし、クエリされた結果からダッシュボードに移動するための組み込みのデータ視覚化ツールを提供します。次のイベントにご期待ください!
その他のデータ収集リソース
これらすべての動作を確認するには、以下の関連リンクをクリックして、データの強化について詳しく学んでください。
- ビデオ–これがどのように構築されたかを確認したい場合は、リンクのビデオを参照してください。
- チュートリアル–自分のペースでこれを実行したい場合は、スクリーンショットと、これを設定して実行する方法の行ごとの説明を含む詳細なウォークスルーを参照してください。
- 交流会– Clouderaの専門家と直接話をしたい場合は、仮想交流会に参加してライブストリームのプレゼンテーションをご覧ください。最後に直接Q&Aの時間があります。
- ユーザー–ユーザー固有の技術的なコンテンツを表示するには、リンクをクリックしてください。