これの主な目標の Hadoopのチュートリアルを あなたのHadoopの作業で使用されている各構成要素の詳細な説明を提供することです。このチュートリアルでは、Hadoopの中でパーティショナをカバーしようとしている。
何Hadoopのパーティショナは、Hadoopの中にパーティション分割の必要性が何であるか、MapReduceの中にデフォルトパーティション分割は何ですか、どのように多くのMapReduceパーティショナHadoopのに使用されているのですか?
我々は、このMapReduceのチュートリアルでは、これらすべての質問にお答えします。
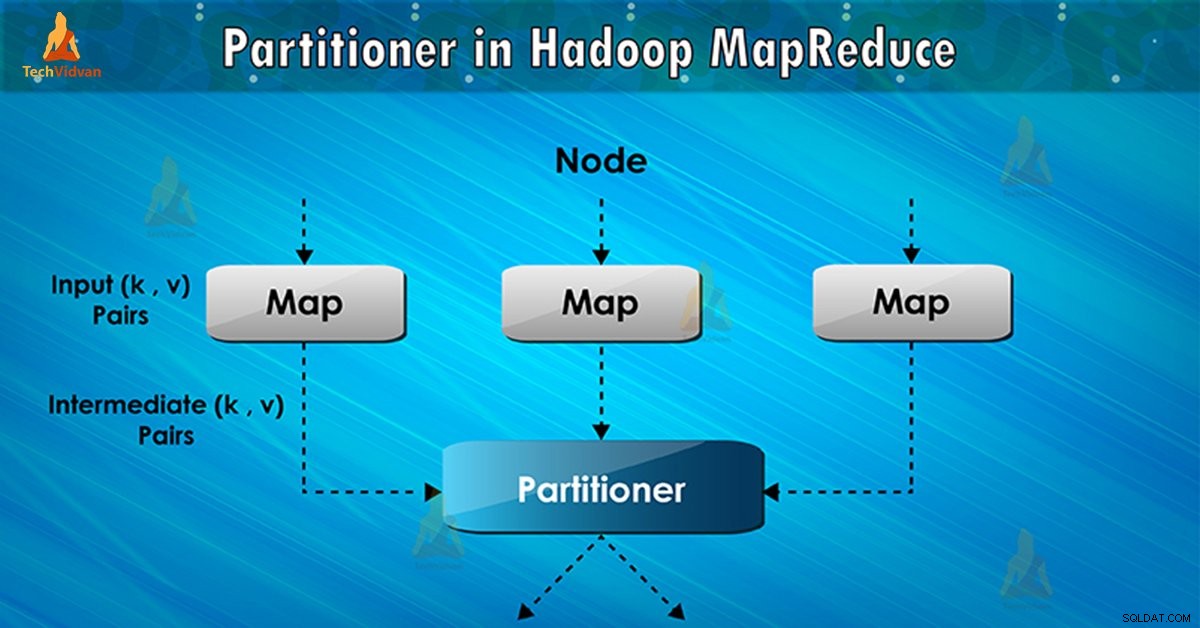
Hadoopのパーティショナは何ですか?
MapReduceのジョブの実行中にパーティショナは中間map出力のキーの分配を制御します。ハッシュ関数の助けを借りて、キー(またはキーのサブセット)は、パーティションを導出します。パーティションの合計数は減らすタスクの数と同じである。
基づいてのキー値を 、フレームワークパーティション、それぞれのマッパーの 出力。同じキー値を持つものとしてレコードは(各マッパー内で)同じパーティションに入ります。その後、各パーティションが送られるの減速の 。
パーティションのクラスは、与えられた(キー、値)のペアが行くどのパーティションを決定します。 MapReduceのデータフローにおけるパーティション相はマップフェーズの後に行われ、前段階を減らすことができます。
のHadoopのMapReduceでのパーティション分割の必要性
MapReduceのジョブの実行では、入力データ・セットを受け取り、キーと値のペアのリストを生成します。これらのキーと値のペアは、mapフェーズの結果です。ここで入力データが分割され、各タスクはキーと値のペアのリストを分割し、各マップを処理出力
その後、フレームワークは、タスクを減らすためにマップの出力を送信します。ユーザ定義がマップ出力に機能を縮小プロセスを減らします。前のキーに基づいてマップ出力テイク場所の区分、位相を削減します。
Hadoopのパーティショニングは、各キーのすべての値が一緒にグループ化されていることを指定します。また、単一のキーのすべての値が同じ減速に行くことを確認します。これは、減速オーバーマップ出力を均一に分布することができます。
MapReduceのジョブにおけるパーティショナは、減速ハンドルを特定のキーを決定することにより減速するマッパー出力をリダイレクトします。
Hadoopのデフォルトパーティショナ
<強い>ハッシュパーティショナを デフォルトパーティショナです。これは、キーのハッシュ値を計算します。また、この結果に基づいてパーティションを割り当てます。
どのように多くのHadoopでのパーティショナ?
パーティショナの総数は、減速の数によって異なります。 Hadoopのパーティション分割は、減速の数に応じてデータを分割します。それは、をJobConf.setNumReduceTasksによって設定されている()を 方法。
したがって、単一の減速機は、単一のパーティからのデータを処理します。通知に重要なことは、フレームワークは、多くのレデューサーがある場合にのみ、パーティを作成することです。
HadoopのMapReduceの中に悪いパーティション
MapReduceのジョブでのデータ入力での場合は一つのキーは、より多くの他のキーよりも表示されます。このような場合には、次のように我々は2つのメカニズムを使用してパーティションにデータを送信する
- 倍のより多くの数を表示されて鍵が一つのパーティションに送信されます。
- すべての他のキーは、彼らののhashCode()をに基づいてパーティションに送信されます 。
<強い>のhashCode()の場合は この方法は、パーティションの範囲に渡って他の鍵データを配布しません。その後、データは減速に送信されません。
他に比べていくつかの減速がより多くのデータ入力を有することがデータ手段の乏しい分割。彼らは、他の減速よりも行うにはより多くの仕事を持っています。したがって、ジョブ全体では、負荷のその特大のシェアを完了するために1つの減速を待つ必要がある。
<強い>のMapReduceの貧しいパーティショニングを克服するには?を
HadoopのMapReduceの中に貧しいパーティショナを克服するために、我々は、カスタムパーティショナを作成することができます。これは、異なる減速間でワークロードを共有することができます。
結論
結論として、パーティショナは、減速オーバーマップ出力の均一な分布を可能にします。 MapReducerパーティショナには、キーと値に基づいてマップ出力テイク場所で区切る。
したがって、我々はこのブログでパーティショナの完全な概要をカバーしています。あなたはそれが好き願っています。何か疑問がHadoopのパーティショナについてのあなたの心に入ってくる場合は、そう、私たちと共有することを忘れないでください。