このHadoopチュートリアルでは 、Hadoopコンバイナーの詳細な説明を提供します。まず、MapReduce Combinerとは何か、MapReduceにおけるCombinerの重要な役割は何かを見ていきます。
次に、Hadoopでコンバイナーを使用する場合と使用しない場合のMapReduceプログラムの例について説明します。最後に、MapReduceのCombinerのいくつかの長所と短所もわかります。
Hadoopコンバイナーとは何ですか?
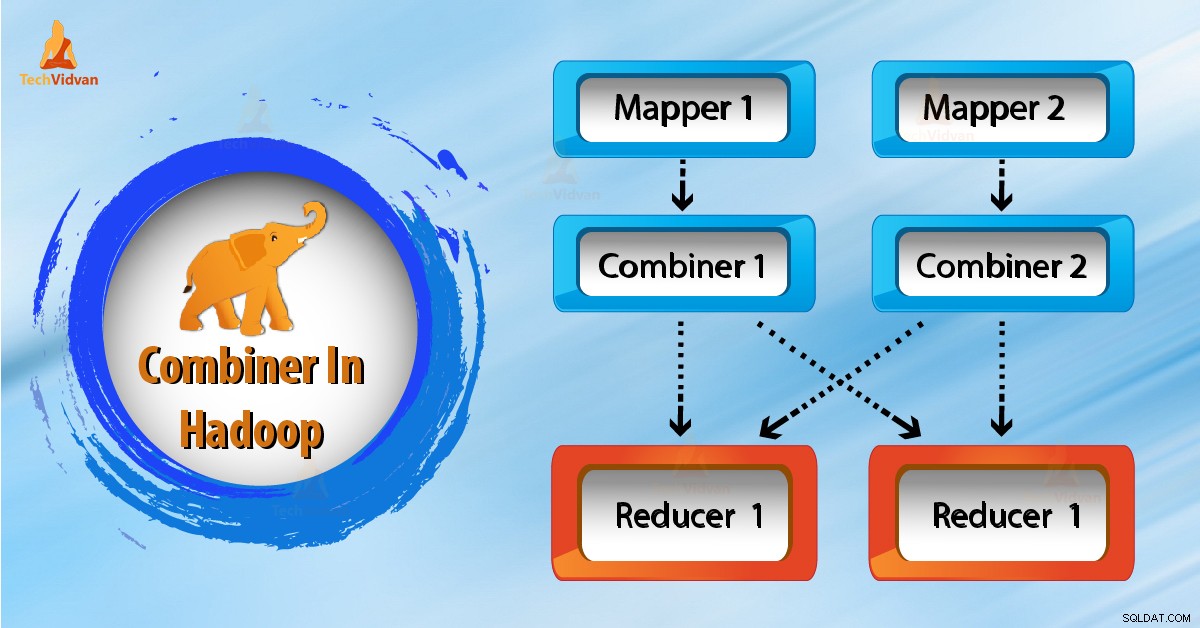
コンバイナー 「ミニリデューサー」とも呼ばれます 」は、マッパーをまとめたものです。 レデューサーに渡す前に、同じキーでレコードを出力します 。
MapReduceジョブを実行するときの大きなデータセット。そのため、マッパーは中間データの大きなチャンクを生成します。次に、フレームワークはこの中間データをレデューサーに渡してさらに処理します。
これにより、ネットワークが非常に混雑します。 Hadoopフレームワークは、コンバイナーと呼ばれる機能を提供します これは、ネットワークの輻輳を減らす上で重要な役割を果たします。
コンバイナーの主な仕事は、「ミニリデューサー」は、マッパーからの出力データを処理してから、レデューサーに渡すことです。マッパーの後、レデューサーの前で実行されます。その使用法はオプションです。
コンバイナーはHadoopでどのように機能しますか?
では、MapReduceでコンバイナーを使用すると状況がどのように変化するかを学びましょう。

上の図にあるように、コンバイナーはありません。入力は2つのマッパーに分割されます。フレームワークはマッパーから9つのキーを生成します。
これで、(9つのキー/値)中間データができました。さらにマッパーはこのキー値を送信します レデューサーに直接。レデューサーにデータを送信する際、ネットワーク帯域幅を消費します。データのサイズが大きい場合、レデューサーにデータを転送するのに時間がかかります。

上の図から、マッパーとレデューサーの間にコンバイナーを使用するとします。次に、コンバイナーは9つのキー/値をシャッフルしてから、レデューサーに送信します。次に、4つのキーと値のペアを出力として生成します。
これで、Reducerは、2つのコンバイナーから生成された4つのキー/値ペアデータのみを処理する必要があります。したがって、レデューサーは4回だけ実行され、最終出力が生成されます。したがって、これにより全体的なパフォーマンスが向上します。
MapReduceのCombinerの利点
MapReduceでのHadoopコンバイナーの利点について説明しましょう。
- コンバイナーを使用すると、マッパーとレデューサー間のデータ転送にかかる時間が短縮されます。
- コンバイナーは、レデューサーの全体的なパフォーマンスを向上させます。
- レデューサーが処理する必要のあるデータの量を減らします。
MapReduceのCombinerのデメリット
Hadoopコンバイナーにはいくつかの欠点もあります。同じことについて話し合いましょう。
- ローカルファイルシステムで、Hadoopがキーと値のペアを保存し、後でコンバイナーを実行すると、ディスクIOが高価になります。
- MapReduceジョブは、実行に保証がないため、コンバイナーの実行に依存することはできません。
結論
したがって、Hadoop Combinerは、ネットワークの輻輳を軽減する上で重要な役割を果たします。 Mapperの出力を要約することにより、レデューサーの全体的なパフォーマンスが向上します。
これで、Hadoopコンバイナーについて明確に理解できたと思います。それでも質問がある場合は、下のセクションにコメントを残してください。