このHadoopチュートリアル MapReduceのシャッフルと並べ替えがすべてです。ここでは、Hadoopのシャッフルと並べ替えのフェーズについて詳しく説明します。
最初にMapReduceシャッフリングとは何かについて説明し、次にMapReduceソートについて説明します。次に、MapReduceの2次ソートフェーズについて詳しく説明します。
MapReduceのシャッフルと並べ替えとは何ですか?
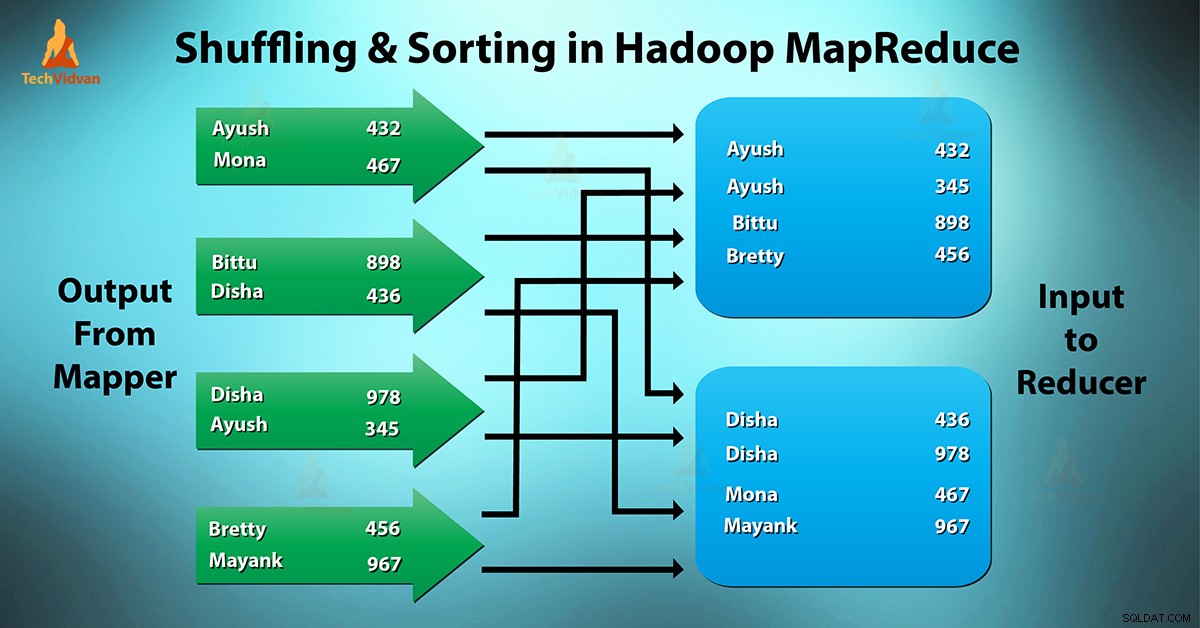
シャッフル マッパーを転送するプロセスです レデューサーへの中間出力。 レデューサーは、レデューサーに基づいて1つ以上のキーと関連する値を取得します。
中間キー–マッパーによって生成された値はキーによって自動的にソートされます。並べ替えフェーズでは、マップ出力のマージと並べ替えが行われます。
Hadoopでのシャッフルと並べ替えは同時に発生します。
MapReduceでのシャッフル
マッパーからレデューサーにデータを転送するプロセスはシャッフルです。これは、システムがソートを実行するプロセスでもあります。次に、マップ出力を入力としてレデューサーに転送します。これが、レデューサーにシャッフルフェーズが必要な理由です。
そうしないと、入力(またはすべてのマッパーからの入力)がありません。マップフェーズが終了する前でもシャッフルを開始できるため。したがって、これにより時間を節約し、タスクをより短い時間で完了できます。
MapReduceでの並べ替え
MapReduce Frameworkは、マッパーによって生成されたキーを自動的に並べ替えます。したがって、レデューサーを開始する前に、すべての中間キーと値のペアは、値ではなくキーでソートされます。各レデューサーに渡された値はソートされません。順序は任意です。
MapReduceジョブで並べ替えると、reducerは新しいreduceタスクをいつ開始するかを簡単に区別できます。
これにより、レデューサーの時間を節約できます。 MapReduceのReducerは、ソートされた入力データの次のキーが前のキーと異なる場合に、新しいreduceタスクを開始します。各reduceタスクは、キーと値のペアを入力として受け取り、キーと値のペアを出力として生成します。
注意すべき重要な点は、ゼロレデューサー(setNumReduceTasks(0))を指定した場合、HadoopMapReduceでのシャッフルと並べ替えはまったく行われないということです。
レデューサーがゼロの場合、MapReduceジョブはマップフェーズで停止します。また、マップフェーズには、どのような種類の並べ替えも含まれていません(マップフェーズの方が高速です)。
MapReduceでのセカンダリソート
レデューサー値を並べ替える場合は、2次並べ替え手法を使用します。この手法により、各レデューサーに渡された値を(昇順または降順で)並べ替えることができます。
結論
結論として、MapReduceのシャッフルと並べ替えが同時に行われ、Mapperの中間出力が要約されます。 Hadoopシャッフル-ゼロレデューサー(setNumReduceTasks(0))を指定した場合、ソートは行われません。
フレームワークは、すべての中間キーと値のペアを、値ではなくキーでソートします。値による並べ替えに2次並べ替えを使用します。 MapReduceのシャッフルと並べ替えのフェーズに関連する提案やクエリがある場合は、コメントボックスにコメントを残してください。
喜んで解決させていただきます。