どのストリーミングアーキテクチャパターンがユースケースに最適であるかを評価することは、本番環境への導入を成功させるための前提条件です。
Apache Hadoopエコシステムは、大規模なデータをリアルタイムで処理および理解しようとしている企業にとって好ましいプラットフォームになっています。 Apache Kafka、Apache Flume、Apache Spark、Apache Storm、Apache Samzaなどのテクノロジーは、可能なことの限界をますます押し広げています。大規模なストリーミングのユースケースをまとめたくなることがよくありますが、実際には、エコシステムのさまざまなコンポーネントがさまざまな問題に適しているため、いくつかの異なるアーキテクチャパターンに分解される傾向があります。
この投稿では、本番環境でエンタープライズデータハブを実行しているお客様と遭遇した4つの主要なストリーミングパターンの概要を説明し、それらのパターンをHadoopにアーキテクチャ的に実装する方法を説明します。
ストリーミングパターン
4つの基本的なストリーミングパターン(多くの場合、タンデムで使用されます)は次のとおりです。
- ストリームの取り込み: HDFS、Apache HBase、およびApacheSolrへのイベントの低レイテンシーの永続化が含まれます。
- 外部コンテキストを使用したほぼリアルタイム(NRT)のイベント処理: イベントが到着すると、アラート、フラグ付け、変換、フィルタリングなどのアクションを実行します。異常検出モデルなどの高度な基準に基づいてアクションが実行される場合があります。 NRT不正の検出や推奨などの一般的な使用例では、100ミリ秒未満の低遅延が要求されることがよくあります。
- NRTイベントパーティション処理: NRTイベント処理に似ていますが、より関連性の高い外部情報をメモリに格納するなど、データを分割することでメリットが得られます。このパターンでは、100ミリ秒未満の処理レイテンシも必要です。
- アグリゲーションまたはMLの複雑なトポロジ: ストリーム処理の聖杯:複雑で柔軟な一連の操作を使用して、データからリアルタイムの回答を取得します。ここでは、結果がウィンドウ化された計算に依存することが多く、よりアクティブなデータを必要とするため、焦点は超低遅延から機能性と精度に移ります。
次のセクションでは、このようなパターンをテスト済みで実証済みの保守可能な方法で実装するための推奨される方法について説明します。
ストリーミングインジェスト
従来、Flumeはストリーミング取り込みに推奨されるシステムでした。ソースとシンクの大規模なライブラリは、何を消費し、どこに書き込むかについてのすべての基盤をカバーしています。 (Flumeの構成および管理方法の詳細については、Flumeの使用 、Cloudera Software Engineer / FlumePMCのメンバーであるHariShreedharanによるO’Reilly Mediaの本は、すばらしいリソースです。)
昨年、再生や複製などの強力な機能により、Kafkaも人気を博しました。 FlumeとKafkaの目標は重複しているため、両者の関係はしばしば混乱を招きます。それらはどのように組み合わされますか?答えは簡単です。KafkaはFlumeのチャネル抽象化に似たパイプですが、上記の機能をサポートしているため、より優れたパイプです。一般的なアプローチの1つは、ソースとシンクにFlumeを使用し、それらの間のパイプにKafkaを使用することです。
次の図は、KafkaがFlumeへのデータのアップストリームソース、Flumeのダウンストリーム宛先、またはFlumeチャネルとしてどのように機能するかを示しています。
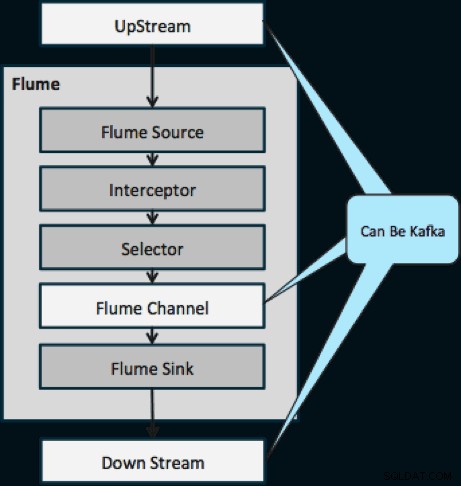
以下に示す設計は、非常にスケーラブルで、戦闘が強化され、Cloudera Managerを介して一元的に監視され、フォールトトレラントであり、再生をサポートします。
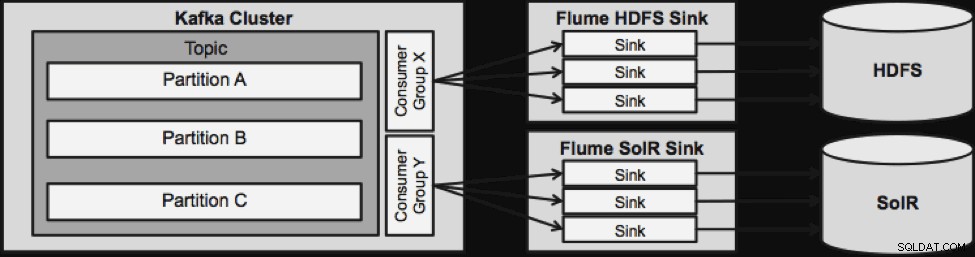
次のストリーミングアーキテクチャに進む前に注意すべきことの1つは、この設計が障害を適切に処理する方法です。 Flume Sinksは、KafkaConsumerGroupから取得しています。コンシューマーグループは、Apache ZooKeeperの助けを借りて、トピックのオフセットを追跡します。 Flumeシンクが失われた場合、Kafkaコンシューマーは残りのシンクに負荷を再配分します。 Flume Sinkが復旧すると、Consumerグループは再配布します。
外部コンテキストを使用したNRTイベント処理
繰り返しになりますが、このパターンの一般的な使用例は、データを変換するか、何らかの外部アクションを実行するために、ストリーミングされるイベントを確認し、即座に決定を下すことです。決定ロジックは、多くの場合、外部プロファイルまたはメタデータに依存します。このアプローチを実装する簡単でスケーラブルな方法は、Kafka/FlumeアーキテクチャにSourceまたはSinkFlumeインターセプターを追加することです。適度な調整により、低ミリ秒でレイテンシーを達成することは難しくありません。
Flume Interceptorsは、イベントまたはイベントのバッチを取得し、ユーザーコードがそれらに基づいてアクションを変更または実行できるようにします。ユーザーコードは、ローカルメモリまたはHBaseなどの外部ストレージシステムと対話して、意思決定に必要なプロファイル情報を取得できます。 HBaseは通常、ネットワーク、スキーマの設計、および構成に応じて、約4〜25ミリ秒で情報を提供できます。また、障害が発生した場合でも、HBaseがダウンしたり中断されたりしないようにHBaseを設定することもできます。
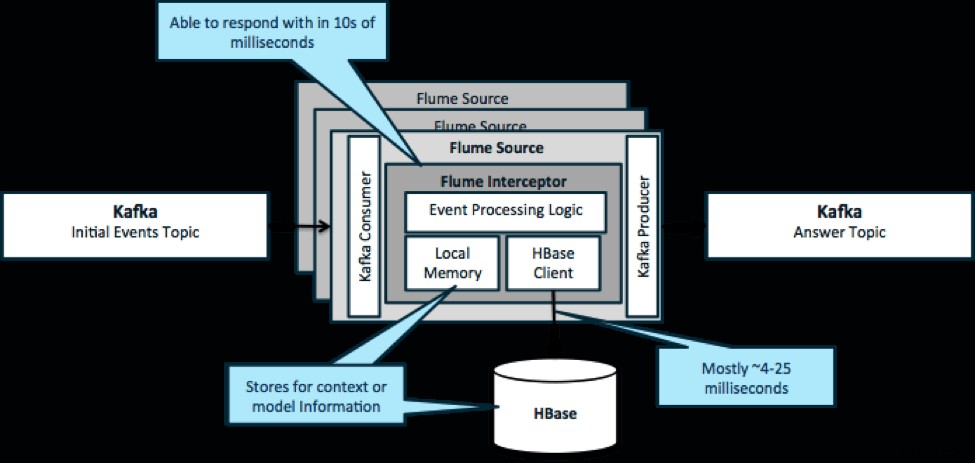
実装には、インターセプターのアプリケーション固有のロジック以外のコーディングはほとんど必要ありません。 Cloudera Managerは、パーセルを介してこのロジックを展開し、サービスを接続、構成、および監視するための直感的なUIを提供します。
外部コンテキストを使用したNRTパーティション化イベント処理
以下に示すアーキテクチャ(パーティション化されていないソリューション)では、特定のイベントに関連する外部コンテキストがFlumeインターセプターのローカルメモリに収まらないため、HBaseに頻繁に呼び出す必要があります。
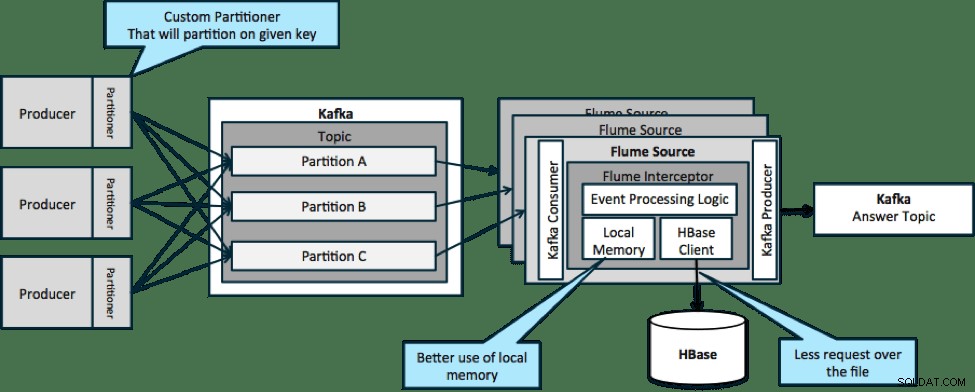
ただし、データを分割するためのキーを定義すると、受信データをそれに関連するコンテキストデータのサブセットと照合できます。データを10回分割する場合、メモリに保持する必要があるのはプロファイルの1/10だけです。 HBaseは高速ですが、ローカルメモリは高速です。 Kafkaを使用すると、データを分割するために使用するカスタムパーティショナーを定義できます。
ここではFlumeは厳密には必要ないことに注意してください。ここでの根本的な解決策は、Kafkaの消費者だけです。したがって、YARNまたはMapのみのMapReduceアプリケーションでコンシューマーのみを使用できます。
アグリゲーションまたはMLの複雑なトポロジ
これまで、イベントレベルの操作を検討してきました。ただし、カウント、平均、セッション化、データのバッチを操作する機械学習モデルの構築など、より複雑な操作が必要になる場合があります。この場合、SparkStreamingはいくつかの理由で理想的なツールです。
- 他のツールに比べて開発が簡単です。 Sparkの豊富で簡潔なAPIにより、複雑なトポロジを簡単に構築できます。
- ストリーミングとバッチ処理用の同様のコード。 いくつかの変更を加えるだけで、リアルタイムの小さなバッチのコードをオフラインで大量のバッチに使用できます。このアプローチは、コードサイズを削減するだけでなく、テストと統合に必要な時間を短縮します。
- 知っておくべきエンジンが1つあります。 分散処理エンジンの癖や内部に関するスタッフのトレーニングにはコストがかかります。 Sparkで標準化すると、ストリーミングとバッチの両方でこのコストが統合されます。
- マイクロバッチ処理は、確実にスケーリングするのに役立ちます。 バッチレベルで確認することにより、スループットが向上し、二重送信を恐れることなくソリューションが可能になります。マイクロバッチ処理は、大規模なパフォーマンスの観点から、HDFSまたはHBaseに変更を送信するのにも役立ちます。
- Hadoopエコシステムの統合が組み込まれています。 Sparkは、HDFS、HBase、およびKafkaと緊密に統合されています。
- データ損失のリスクはありません。 WALとKafkaのおかげで、SparkStreamingは障害が発生した場合のデータ損失を回避します。
- デバッグと実行は簡単です。 クラスタを使用せずに、ローカルIDEでコードSparkStreamingをデバッグしてステップスルーできます。さらに、コードは通常の関数型プログラミングコードのように見えるため、JavaまたはScalaの開発者がジャンプするのにそれほど時間はかかりません。 (Pythonもサポートされています。)
- ストリーミングはネイティブにステートフルです。 Spark Streamingでは、州は第一級市民です。つまり、ノードの障害に強いステートフルストリーミングアプリケーションを簡単に作成できます。
- デファクトスタンダードとして、Sparkはエコシステム全体から長期的な投資を受けています。
この記事の執筆時点では、過去30日間でSparkへのコミットは全体で約700でした。これは、Stormなどの他のストリーミングフレームワークと比較して、同時に15のコミットがありました。 - MLライブラリにアクセスできます。
SparkのMLlibは非常に人気があり、その機能は向上するだけです。 - 必要に応じてSQLを使用できます。
Spark SQLを使用すると、ストリーミングアプリケーションにSQLロジックを追加して、コードの複雑さを軽減できます。
結論
ストリーミングには多くの力があり、いくつかの可能なパターンがありますが、この投稿で学んだように、どのパターンがユースケースに最もよく一致するかを知っていれば、最小限のコーディングで本当に強力なことを行うことができます。
Ted Malaskaは、Clouderaのソリューションアーキテクトであり、Spark、Flume、HBaseの寄稿者であり、O’Reillyの本の共著者です。 Hadoopアプリケーションアーキテクチャ。