
Resqueキュー、ワーカー、およびジョブがどのように実行されているかを視覚化したいと思ったことはありませんか?この記事では、Resqueコンポーネントの周りにいくつかの簡単なグラフを作成する方法を学びます。
バックグラウンドキューへのジョブの委任
実行時間が長く、計算コストが高く、待ち時間の長いジョブをバックグラウンドワーカーキューに委任することは、スケーラブルなWebアプリケーションを作成するために使用される一般的なパターンです。目標は、すべての高額なジョブがリクエスト/レスポンスサイクルの外で処理されるようにすることで、エンドユーザーのリクエストに可能な限り迅速に対応することです。
レスク
Resqueは、バックグラウンドジョブを作成し、それらを複数のキューに配置し、後で処理するためのRedisがサポートするRubyライブラリです。 Resqueは、ウェブダッシュボードを介して統計情報を中継しながら、行動の可視性と信頼性を確保するメカニズムを提供するため、大量のジョブエントリを必要とするシナリオで使用するように設計されています。
Redis
Redisは、オープンソース(BSDライセンス)のメモリ内データ構造ストアであり、データベース、キャッシュ、およびメッセージブローカーとして使用されます。文字列、ハッシュ、リスト、セット、範囲クエリを使用した並べ替えられたセット、ビットマップ、ハイパーログログ、半径クエリを使用した地理空間インデックスなどのデータ構造をサポートします。
Node.js
Node.jsは、ChromeのJavaScriptランタイム上に構築されたプラットフォームであり、高速でスケーラブルなネットワークアプリケーションを簡単に構築できます。 Node.jsは、イベント駆動型の非ブロッキングI / Oモデルを使用しており、軽量で効率的であるため、分散デバイス間で実行されるデータ集約型のリアルタイムアプリケーションに最適です。
Express.js
Express.jsはNode.jsフレームワークです。 Node.jsは、Webおよびネットワークアプリケーションを作成するために、JavaScriptをWebブラウザーの外部で使用できるようにするプラットフォームです。これは、他のほとんどのWeb言語と同様に、JavaScriptを使用して、アプリケーションのサーバーおよびサーバー側のコードを作成できることを意味します。
Socket.IO
Socket.IOは、リアルタイムウェブアプリケーション用のJavaScriptライブラリです。これにより、Webクライアントとサーバー間のリアルタイムの双方向通信が可能になります。これには、ブラウザーで実行されるクライアント側ライブラリとNode.js用のサーバー側ライブラリの2つの部分があります。どちらのコンポーネントにもほぼ同じAPIがあります。
Heroku
Herokuは、企業がアプリを構築、配信、監視、スケーリングできるようにするクラウドプラットフォームです。これは、インフラストラクチャの問題をすべて回避して、アイデアからURLに移行するための最速の方法です。
この記事は、Redis、Node.js、およびHerokuToolbeltがマシンにすでにインストールされていることを前提としています。
セットアップ:
- ScaleGridのリポジトリからコードをダウンロードします。
- npm installを実行して、必要なコンポーネントをインストールします。
- 最後に、「nodeindex.js」を実行してノードサーバーを起動できます。ファイルの変更を監視する「nodemon」を実行することもできます。
ここから、このアプリのホストバージョンにアクセスすることもできます。
このアプリケーションは、node-resqueと呼ばれるResqueのポートを使用して、Redisクラスターで実行されているキュー、ワーカー、ジョブを監視できるようにします。
基本を理解する
アプリを起動するとすぐに、Redisクラスターの資格情報を入力する必要があります。これを正しく機能させるには、クラスターにResqueをインストールして実行する必要があることに注意してください。
幸い、フルマネージドのScaleGrid forRedis™*は、Redis™に高性能のワンクリックホスティングソリューションを提供します。まだメンバーでない場合は、ここで30日間の無料トライアルに登録して開始できます。
それ以外の場合は、ダッシュボードにログインして、Redis™セクションの下に新しいRedis™クラスターを作成します。クラスタが起動して実行されると、[クラスタの詳細]ページから必要な詳細を取得できます。次の情報が必要になります:
- ホスト
- ポート
- パスワード

接続が成功すると、次のようなグラフが表示されます。

これらの各グラフについて詳しく説明しましょう。すべてのグラフは自己更新されるため、ワーカーがクラスターでジョブを処理している場合、グラフは自動的に更新されることに注意してください。
すべてのキューの合計タスク
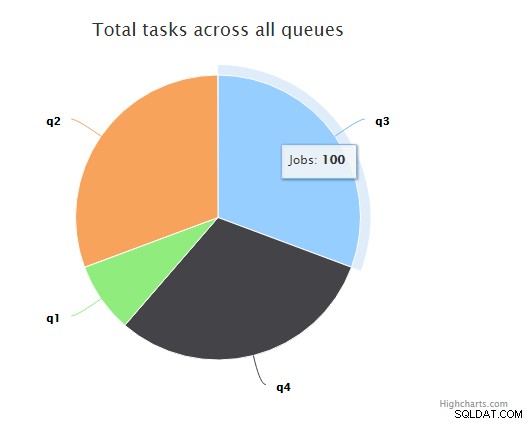

上記のグラフは、クラスター上のResqueキューの総数と、各キューに含まれるジョブの数を示しています。 Resqueは、「resque:queue:name」という名前のRedisリストにジョブキューを格納します。リスト内の各要素は、JSON文字列としてシリアル化されたハッシュです。 Redisには、「失敗した」ジョブリストを含む独自の管理構造もあります。 Resqueは、Redis内のデータに「resque:」プレフィックスを付けて名前を付け、他のユーザーと共有できるようにします。
労働者/仕事のヒストグラム
Resqueワーカーがジョブを処理します。 fork(2)をサポートするプラットフォームでは、ワーカーは子をフォークして各ジョブを処理します。これにより、次のジョブを開始するときにクリーンな状態が保証され、メモリの段階的な増加と低レベルの障害が削減されます。
また、ワーカーがマスターであるあなたからの信号を常に聞き取り、それに応じて対応できるようにします。

上のグラフは、Redisクラスター上のすべてのワーカーを示しています。状態1は、ジョブがワーカーに割り当てられて進行中であることを示し、状態0は、ワーカーがフリー/アイドルであることを示します。
ジョブステータス
Resqueジョブは、作業の単位を表します。各ジョブは単一のキューに存在し、ペイロードオブジェクトが関連付けられています。ペイロードは、`class`と`args`の2つの属性を持つハッシュです。 `class`は、ジョブの実行に使用する必要があるRubyクラスの名前です。 `args`は、Rubyクラスの`perform`クラスレベルのメソッドに渡す必要のある引数の配列です。

上のグラフは、処理済みまたは失敗したジョブのステータスを示しています。ワーカーがジョブの実行に失敗した場合、ジョブは失敗状態に追加されます。簡単なジョブオブジェクトの例を次に示します。
var jobs = {
"add": {
plugins: [ 'jobLock', 'retry' ],
pluginOptions: {
jobLock: {},
retry: {
retryLimit: 3,
retryDelay: (1000 * 5),
}
},
perform: function(a,b,callback){
var answer = a + b;
callback(null, answer);
},
},
"subtract": {
perform: function(a,b,callback){
var answer = a - b;
callback(null, answer);
},
},
};
- ホストされているバージョンはこちらから入手できます。
- このアプリケーションをHerokuにデプロイするには、ドキュメントを確認してください。
- ソースコード全体はGitHubでも入手でき、ここでフォークして作業できます。
いつものように、素晴らしいものを作成する場合は、@scalegridioでツイートしてください。