主要な母集団クエリをさらに分析する
ODBCトレースシリーズのパート3では、ODBCリンクテーブルのAccess管理キーと、SELECTクエリを並べ替えてグループ化する方法についてさらに詳しく説明します。前回の記事では、ダイナセットタイプのレコードセットが実際には2つの個別のクエリであり、最初のクエリがODBCリンクテーブルのキーのみをフェッチし、その後データの入力に使用されることを学びました。この記事では、Accessがキーを管理する方法と、ODBCリンクテーブルに使用するキーとその影響を推測する方法についてもう少し詳しく説明します。並べ替えから始めます。
クエリに並べ替えを追加する
前回の記事で、単純なSELECTから始めたことがわかりました。 特別な注文なし。また、Accessが最初にCityIDを取得した方法も確認しました。 そして、最初のクエリの結果を使用して後続のクエリにデータを入力し、大きなレコードセットを開いたときにユーザーに高速であるように見せます。クエリに並べ替えやグループ化を追加する状況を経験したことがある場合は、突然遅くなります。これが理由を説明します。
StateProvinceIDに並べ替えを追加しましょう アクセスクエリの場合:
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;ここで、ODBC SQLをトレースすると、次の出力が表示されます。
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)前の記事のトレースと比較すると、最初のクエリを除いて同じであることがわかります。 Accessは、キーを取得するために使用する最初のクエリに並べ替えを配置します。これは、レコードをウォークスルーするために使用するキーに並べ替えを適用することで、Accessがレコードの順序位置と並べ替え方法を1対1で対応することが保証されるため、理にかなっています。次に、まったく同じ方法でレコードにデータを入力します。唯一の違いは、他のクエリに入力するために使用するキーのシーケンスです。
GROUP BYを追加するとどうなるか考えてみましょう 州ごとの都市をカウントすることによって:
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;トレースは次のように出力されます:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" また、クエリがゆっくり開くようになり、ダイナセットタイプのレコードセットとして設定されている場合でも、Accessはこれを無視し、基本的にスナップショットタイプのレコードセットとして扱うことに気付いたかもしれません。これは、クエリが更新不可能であり、このようなクエリ内の任意の位置に実際に移動できないため、理にかなっています。したがって、自由に参照できるようになる前に、すべての行がフェッチされるまで待つ必要があります。 StateProvinceID Citiesには複数のレコードがあるため、レコードの検索には使用できません テーブル。 GROUP BYを使用しましたが この例では、Accessが代わりにスナップショットタイプのレコードセットを使用するようにするグループ化である必要はありません。 DISTINCTを使用する たとえば、同じ効果があります。 Accessがdynasetタイプのレコードセットを使用するかどうかを予測するための便利な経験則は、結果のレコードセットの特定の行がODBCデータソースの正確に1つの行にマップされるかどうかを確認することです。そうでない場合、クエリがdynasetを使用することになっている場合でも、Accessはスナップショットの動作を使用します。 したがって、デフォルトがダイナセットタイプのレコードセットであるという理由だけで、それが実際にダイナセットタイプのレコードセットになることを保証するものではありません。単なるリクエストです 、需要ではありません。
選択に使用するキーの決定
この記事と以前の記事の両方で、以前のトレースされたSQLで、AccessがCityIDを使用していることに気付いたかもしれません。 キーとして。その列は最初のクエリでフェッチされ、その後の準備されたクエリで使用されました。しかし、Accessは、リンクされたテーブルのどの列を使用する必要があるかをどのように知るのでしょうか。最初の傾向は、主キーをチェックしてそれを使用すると言うことです。ただし、それは正しくありません。実際、AccessデータベースエンジンはODBCのSQLStatisticsを利用します テーブルのリンクまたは再リンク中に機能して、使用可能なインデックスを調べます。この関数は、すべてのインデックスのインデックスに参加している列ごとに1行の結果セットを返します。この結果セットは常に並べ替えられ、慣例により、クラスター化されたインデックス、ハッシュされたインデックス、その他のインデックスタイプが常に並べ替えられます。各インデックスタイプ内で、インデックスは名前のアルファベット順に並べ替えられます。 Accessデータベースエンジンは、実際の主キーでなくても、最初に見つかった一意のインデックスを選択します。これを証明するために、いくつかの奇妙なインデックスを持つばかげたテーブルを作成します:
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );次に、テーブルにデータを入力し、Accessでそのテーブルにリンクして、リンクされたテーブルのデータシートビューを開くと、トレースされたODBCSQLにこれが表示されます。簡潔にするために、最初の2つのコマンドのみが含まれています。
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?
OtherStuff クラスタ化インデックスに参加し、実際の主キーの前にあるため、Accessデータベースエンジンによって選択され、個々の行を選択するためのダイナセットタイプのレコードセットで使用されます。これは、一意のクラスター化インデックスの名前がプライマリインデックスの名前の後に来るという事実にも関わらずです。 Accessデータベースエンジンにテーブルの特定のインデックスを選択させるための戦術は、そのタイプを変更するか、名前の名前を変更して、インデックスタイプのグループ内でアルファベット順に並べ替えることです。 SQL Serverの場合、主キーは通常クラスター化されており、クラスター化インデックスは1つしか存在できないため、Accessデータベースエンジンが使用するのに通常正しいインデックスであるのは幸いなことです。ただし、SQL Serverデータベースにクラスター化されていない主キーを持つテーブルが含まれていて、クラスター化された一意のインデックスがある場合は、最適な選択ではない可能性があります。クラスタ化されたインデックスがまったくない場合は、他のインデックスの前にソートされるようにインデックスに名前を付けることで、どの一意のインデックスが使用されるかに影響を与えることができます。これは、主キーのクラスター化インデックスを作成することが実用的または不可能な他のRDBMSソフトウェアで役立つ可能性があります。 インデックスのないリンクされたSQLビューまたはテーブルのアクセス側インデックス
インデックスまたは主キーが定義されていないSQLビューまたはSQLテーブルにリンクする場合、Accessデータベースエンジンで使用できるインデックスはありません。リンクテーブルマネージャーを使用して、インデックスのないテーブルまたはSQLビューをリンクした場合は、次のようなダイアログが表示されることがあります。

IDを選択した場合 、リンクを完了し、リンクされたテーブルをデザインビューで開き、インデックスダイアログを開くと、次のように表示されます。
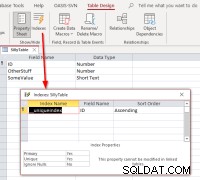 これは、テーブルに
これは、テーブルに__uniqueindexという名前のインデックスがあることを示しています。 ただし、元のデータソースには存在しません。どうしたの?答えは、Accessがアクセス側を作成したということです。 そのようなテーブルまたはビューのレコード識別子として使用できるものを識別するのに役立つインデックス。 Linked Table Managerを使用するのではなく、プログラムでテーブルを再リンクする場合は、そのようなリンクされたテーブルを更新可能にするために、動作を複製する必要があります。これは、AccessSQLコマンドを実行することで実行できます。
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);たとえば、
CurrentDb.Executeを使用できます Access SQLを実行して、リンクテーブルにインデックスを作成します。ただし、インデックスは実際にはサーバー上に作成されないため、パススルークエリとして実行しないでください。リンクされたテーブルの更新を許可するのは、Accessのメリットのためだけです。 Accessは、そのようなリンクされたテーブルに対して1つのインデックスのみを許可し、インデックスがまだない場合にのみ許可されることに注意してください。それでも、データベース設計でクラスター化されたインデックスを使用できない場合や、Accessデータベースエンジンにこのインデックスを使用するように説得するためにインデックスの名前をいじりたくない場合は、SQLビューを使用することが望ましいオプションであることがわかります。そのインデックスではありません。 SQLビューをリンクするときに、インデックスとそれに含める必要のある列を明示的に制御できます。
結論
前回の記事から、ダイナセットタイプのレコードセットは通常2つのクエリを発行することがわかりました。最初のクエリは通常、入力を処理します。Accessがダイナセットタイプのレコードセットに使用するキーの入力をどのように処理するかを詳しく調べました。 Accessが実際に元のAccessクエリから並べ替えを変換し、それをキーポピュレーションクエリで使用する方法を確認しました。キーポピュレーションクエリの順序は、レコードセット内のデータが並べ替えられてユーザーに表示される方法に直接影響することがわかりました。これにより、ユーザーはリストの序数の位置に基づいて、abritraryレコードにジャンプするなどのことができます。
次に、返された行と元の行の間の1対1のマッピングを妨げるグループ化およびその他のSQL操作により、Accessは、ダイナセットタイプのレコードセットを要求しているにもかかわらず、Accessクエリをスナップショットタイプのレコードセットであるかのように処理することがわかりました。
次に、AccessがODBCリンクテーブルを使用して更新を管理するために使用するキーを決定する方法を確認しました。予想に反して、インデックスのタイプとインデックスの名前に応じて、テーブルの主キーを選択する必要はなく、最初に見つかった一意のインデックスを選択します。 Accessが正しい一意のインデックスを選択するようにするための戦略について説明しました。通常はインデックスを持たないSQLビューを確認し、SQLビューまたは主キーを持たないテーブルにキーを設定する方法をAccessに通知する方法について説明しました。これにより、Accessが次の更新を処理する方法をより細かく制御できます。それらのODBCリンクテーブル。
次の記事では、ユーザーがAccessクエリまたはレコードソースを介して変更を加えたときに、Accessが実際にデータの更新を実行する方法について説明します。
アクセスエキスパートがお手伝いします。 773-809-5456までお電話いただくか、[email protected]までメールでお問い合わせください。