ユーザーがシステムにデータを要求するとき、通常、数千行を返している場合でも、特定の順序でデータを表示したいと考えています。多くのDBAや開発者が知っているように、ORDER BYはデータを並べ替える必要があるため、クエリプランに大混乱をもたらす可能性があります。これには、クエリ実行の一部としてSORTオペレーターが必要になる場合があります。これは、特に見積もりがオフでディスクに流出する場合は、コストのかかる操作になる可能性があります。理想的な世界では、データはインデックスのおかげですでに並べ替えられています(インデックスと並べ替えは非常に補完的です)。クエリを満たすためにカバーインデックスを作成することについてよく話します。これにより、オプティマイザが追加の列を取得するためにベーステーブルまたはクラスター化インデックスに戻る必要がなくなります。また、インデックスの列の順序が重要であると人々が言うのを聞いたことがあるかもしれません。 SORTの運用にどのように影響するか考えたことはありますか?
ORDERBYと並べ替えの確認
まず、SQL Server 2014インスタンス(バージョン12.0.2000)上のAdventureWorks2014データベースの新しいコピーから始めます。 ORDER BYを指定せずにSales.SalesOrderHeaderに対して単純なSELECTクエリを実行すると、(SQL Sentryプランエクスプローラーを使用して)単純な古いクラスター化インデックススキャンが表示されます。
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 ORDER BYなしのクエリ、クラスター化インデックススキャン
ORDER BYなしのクエリ、クラスター化インデックススキャン
次に、ORDER BYを追加して、プランがどのように変更されるかを確認しましょう。
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
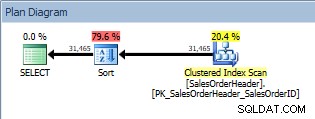 ORDER BY、クラスター化インデックススキャン、および並べ替えを使用したクエリ
ORDER BY、クラスター化インデックススキャン、および並べ替えを使用したクエリ
クラスター化インデックススキャンに加えて、オプティマイザーによって導入されたソートがあり、その推定コストはスキャンのコストよりも大幅に高くなっています。さて、推定コストは推定されたばかりであり、ここでは、Sortがクエリのコストの79.6%を占めたとは絶対に言えません。ソートのコストを実際に理解するには、IO STATISTICSも確認する必要がありますが、これは今日の目標を超えています。
これがご使用の環境で頻繁に実行されるクエリである場合は、それをサポートするためにインデックスを追加することを検討してください。この場合、WHERE句はなく、4つの列を取得し、そのうちの1つで並べ替えるだけです。インデックスでの論理的な最初の試みは次のようになります:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
必要なすべての列を含むインデックスを追加した後、クエリを再実行します。インデックスがデータを並べ替える作業を行ったことを思い出してください。これで、新しい非クラスター化インデックスに対するインデックススキャンが表示されます。
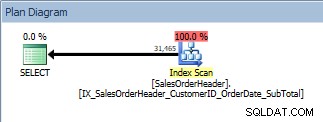 ORDER BYを使用したクエリでは、新しい非クラスター化インデックスがスキャンされます
ORDER BYを使用したクエリでは、新しい非クラスター化インデックスがスキャンされます
これは良い知らせです。しかし、誰かがそのクエリを変更した場合はどうなりますか?ユーザーが並べ替える列を指定できるため、または開発者に変更が要求されたためです。たとえば、ユーザーがCustomerIDとSalesOrderIDを降順で表示したい場合があります。
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
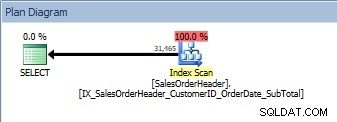 ORDER BYに2つの列があるクエリでは、新しい非クラスター化インデックスがスキャンされます
ORDER BYに2つの列があるクエリでは、新しい非クラスター化インデックスがスキャンされます
同じ計画があります。ソート演算子は追加されませんでした。 Kimberly Trippのsp_helpindex(スペースを節約するために一部の列が折りたたまれている)を使用してインデックスを見ると、計画が変更されなかった理由がわかります。
 sp_helpindexの出力
sp_helpindexの出力
インデックスのキー列はCustomerIDですが、SalesOrderIDはクラスター化インデックスのキー列であるため、インデックスキーの一部でもあり、データはCustomerID、SalesOrderIDの順に並べ替えられます。クエリは、これら2つの列でソートされたデータを降順で要求しました。インデックスは両方の列が昇順で作成されましたが、二重にリンクされたリストであるため、インデックスを逆方向に読み取ることができます。これは、ManagementStudioの非クラスター化インデックススキャンオペレーターの[プロパティ]ペインで確認できます。
 非クラスター化インデックススキャンのプロパティペイン、後方に表示されている
非クラスター化インデックススキャンのプロパティペイン、後方に表示されている
すばらしい、そのクエリに問題はありません…しかし、これはどうですか:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
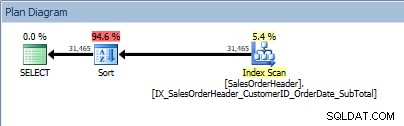 ORDER BYに2つの列があるクエリで、並べ替えが追加されます>
ORDER BYに2つの列があるクエリで、並べ替えが追加されます>
インデックスからのデータが要求された順序でソートされていないため、SORT演算子が再表示されます。含まれている列の1つで並べ替えると、同じ動作が見られます。
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
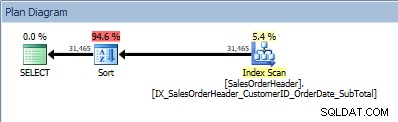 ORDER BYに2つの列があるクエリで、並べ替えが追加されます>
ORDER BYに2つの列があるクエリで、並べ替えが追加されます>
(最後に)述語を追加し、ORDER BYを少し変更するとどうなりますか?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
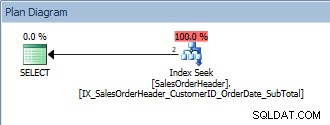 単一の述語とORDERBYを使用したクエリ
単一の述語とORDERBYを使用したクエリ
繰り返しになりますが、SalesOrderIDはインデックスキーの一部であるため、このクエリは問題ありません。この1つのCustomerIDの場合、データはすでにSalesOrderIDによって注文されています。 SalesOrderIDでソートされたCustomerIDの範囲をクエリするとどうなりますか?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
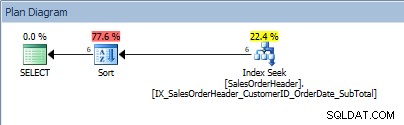 述語の値の範囲とORDERBYを使用したクエリ
述語の値の範囲とORDERBYを使用したクエリ
ラット、私たちのSORTが帰ってきました。データがCustomerIDによって順序付けられているという事実は、その範囲の値を見つけるためにインデックスを探すのに役立つだけです。 ORDER BY SalesOrderIDの場合、オプティマイザーは、要求された順序でデータを配置するために、並べ替えを挿入する必要があります。
この時点で、クエリプランに表示される並べ替え演算子に固執しているのはなぜか疑問に思われるかもしれません。高いからです。リソース(メモリ、IO)や期間の点でコストがかかる可能性があります。
クエリ期間は、ストップアンドゴー操作であるため、並べ替えの影響を受ける可能性があります。計画の次の操作を実行する前に、データのセット全体を並べ替える必要があります。数行のデータのみを注文する必要がある場合、それはそれほど大したことではありません。数千行または数百万行の場合はどうでしょうか。今、待っています。
全体的なクエリ期間に加えて、リソースの使用についても考慮する必要があります。作業中の31,465行を取得し、それらをテーブル変数にプッシュしてから、CustomerIDのORDERBYを使用して最初のクエリを実行します。
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
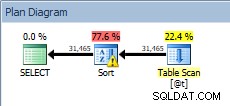 並べ替えを使用したテーブル変数に対するクエリ
並べ替えを使用したテーブル変数に対するクエリ
SORTが戻ってきましたが、今回は警告が表示されます(感嘆符の付いた黄色の三角形に注意してください)。警告は良くありません。この種のプロパティを見ると、「オペレーターがtempdbを使用して、スピルレベル1の実行中にデータをスピルしました」という警告が表示されます。
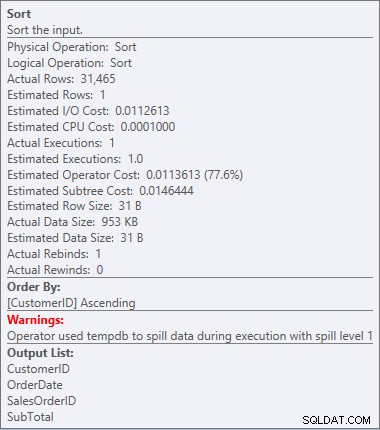
これは私が計画で見たいものではありません。オプティマイザーは、データをソートするためにメモリー内に必要なスペースの量を見積もり、そのメモリーを要求しました。しかし、実際にすべてのデータがあり、それをソートしようとすると、エンジンは十分なメモリがないことに気づき(オプティマイザが要求したのが少なすぎる!)、ソート操作がこぼれました。場合によっては、これがディスクに流出する可能性があります。これは、読み取りと書き込みが遅いことを意味します。データを順番に取得するためだけに待機しているだけでなく、すべてをメモリ内で実行できないため、さらに低速になります。オプティマイザが十分なメモリを要求しなかったのはなぜですか?並べ替えに必要なデータについての見積もりが間違っていました:
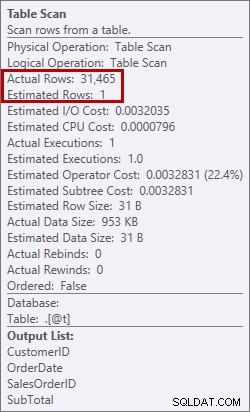 1行の見積もりと実際の31,465行
1行の見積もりと実際の31,465行
この場合、テーブル変数を使用して誤った見積もりを強制しました。統計の推定値とテーブル変数には既知の問題があり(Aaron Bertrandは、これに対処するためのオプションに関する優れた投稿をしています)、ここで、オプティマイザーは、31,465ではなく、1行のみがテーブルスキャンから返されると信じていました。
オプション
では、DBAまたは開発者として、クエリプランでSORTを回避するために何ができるでしょうか。簡単な答えは、「データを注文しないでください」です。しかし、それは必ずしも現実的ではありません。場合によっては、その並べ替えをクライアントまたはアプリケーションレイヤーにオフロードできますが、ユーザーはそれでもでデータを並べ替えるのを待つ必要があります。 層。アプリケーションの動作を変更できない状況では、インデックスを確認することから始めることができます。
ユーザーがアドホッククエリを実行できるアプリケーションをサポートしている場合、または並べ替え順序を変更して、ユーザーが希望どおりに並べ替えられたデータを表示できるようにする場合は、最も苦労します(ただし、原因が失われるわけではありません)。まだ読むのをやめないでください!)。すべてのオプションにインデックスを付けることはできません。それは非効率的であり、あなたが解決するよりも多くの問題を生み出すでしょう。ここでの最善の策は、ユーザーと話すことです(森の隅を離れるのが怖いこともありますが、試してみてください)。ユーザーが最も頻繁に実行するクエリについては、ユーザーが通常どのようにデータを表示するのが好きかを調べます。はい、これはプランキャッシュからも取得できます。クエリとプランを心ゆくまで取得して、それらが何をしているかを確認できます。しかし、ユーザーと話す方が速いです。追加の利点は、なぜあなたが尋ねているのか、そしてなぜ「私ができるのですべての列でソートする」というその考えがそれほど良いものではないのかを説明できることです。知ることは戦いの半分です。パワーユーザーや新しい人々を訓練するユーザーの教育に時間を費やすことができれば、何か良いことができるかもしれません。
ORDER BYオプションが制限されているアプリケーションをサポートしている場合は、実際の分析を行うことができます。存在するORDERBYのバリエーションを確認し、最も頻繁に実行される組み合わせを判別し、それらのクエリをサポートするためにインデックスを作成します。おそらくすべてをヒットすることはありませんが、それでも影響を与えることができます。開発者と話し合い、問題とその対処方法について開発者に教育することで、さらに一歩進めることができます。
最後に、SORT操作を使用したクエリプランを検討しているときは、並べ替えの削除だけに焦点を当てないでください。 どこを見てください ソートはプランで発生します。それが計画の左側で発生し、通常である場合 数行、焦点を当てるべきより大きな改善要因を持つ他の領域があるかもしれません。左側の並べ替えは、今日焦点を当てたパターンですが、ORDER BYのため、並べ替えが常に発生するとは限りません。プランの右端に[並べ替え]が表示されていて、プランのその部分を移動する行がたくさんある場合は、調整を開始するのに適した場所を見つけたことがわかります。