MySQLレプリケーションを選択する理由
最初にレプリケーションテクノロジに関するいくつかの基本事項。 MySQLレプリケーションは複雑ではありません!活用できるさまざまなリソースがあるため、実装、監視、調整は簡単です。Googleはその1つです。 MySQLレプリケーションには、調整するための多くの構成変数が含まれていません。 SQL_THREADとIO_THREADの論理エラーは、理解して修正するのはそれほど難しくありません。 MySQLレプリケーションは最近非常に人気があり、データベースの高可用性を実装する簡単な方法を提供します。旧式のバイナリログ位置の代わりにGTID(グローバルトランザクション識別子)やロスレス準同期レプリケーションなどの強力な機能により、より堅牢になります。
以前の投稿で見たように、高可用性ソリューションを選択する場合、ネットワーク遅延は大きな課題です。 MySQLレプリケーションを使用すると、レイテンシーにそれほど敏感ではないという利点があります。 Galera Clusterがグループ通信とトランザクション順序付けの手法を使用して同期レプリケーションを実現するのとは異なり、認証ベースのレプリケーションは実装されていません。したがって、すべてのノードが書き込みセットを認証する必要はなく、他のスレーブまたはレプリカでコミットする前に待機する必要もありません。
非同期のプライマリ-セカンダリアプローチを使用する従来のMySQLレプリケーションを選択すると、マスター内からトランザクションを処理する際の速度が向上します。スレーブがトランザクションを同期またはコミットするのを待つ必要はありません。セットアップには通常、プライマリ(マスター)と1つ以上のセカンダリ(スレーブ)があります。したがって、これはシェアードナッシングシステムであり、すべてのサーバーがデフォルトでデータの完全なコピーを持っています。もちろん欠点もあります。 SQLおよびI/Oスレッドエラーが原因でスレーブが複製に失敗した場合、またはクラッシュした場合、データの整合性が問題になる可能性があります。または、データの整合性の問題に対処するために、半同期(またはMySQL 5.7ではロスレス半同期レプリケーションと呼ばれる)であるMySQLレプリケーションを実装することを選択できます。これがどのように機能するかというと、マスターはレプリカがトランザクションのすべてのイベントを確認するまで待機する必要があります。これは、ACK応答でマスターに送り返す前に、リレーログへの書き込みを終了し、ディスクにフラッシュする必要があることを意味します。準同期レプリケーションを有効にすると、マスター内のスレッドまたはセッションはレプリカからの確認応答を待機する必要があります。レプリカからACK応答を取得すると、トランザクションをコミットできます。次の図は、MySQLが準同期レプリケーションを処理する方法を示しています。
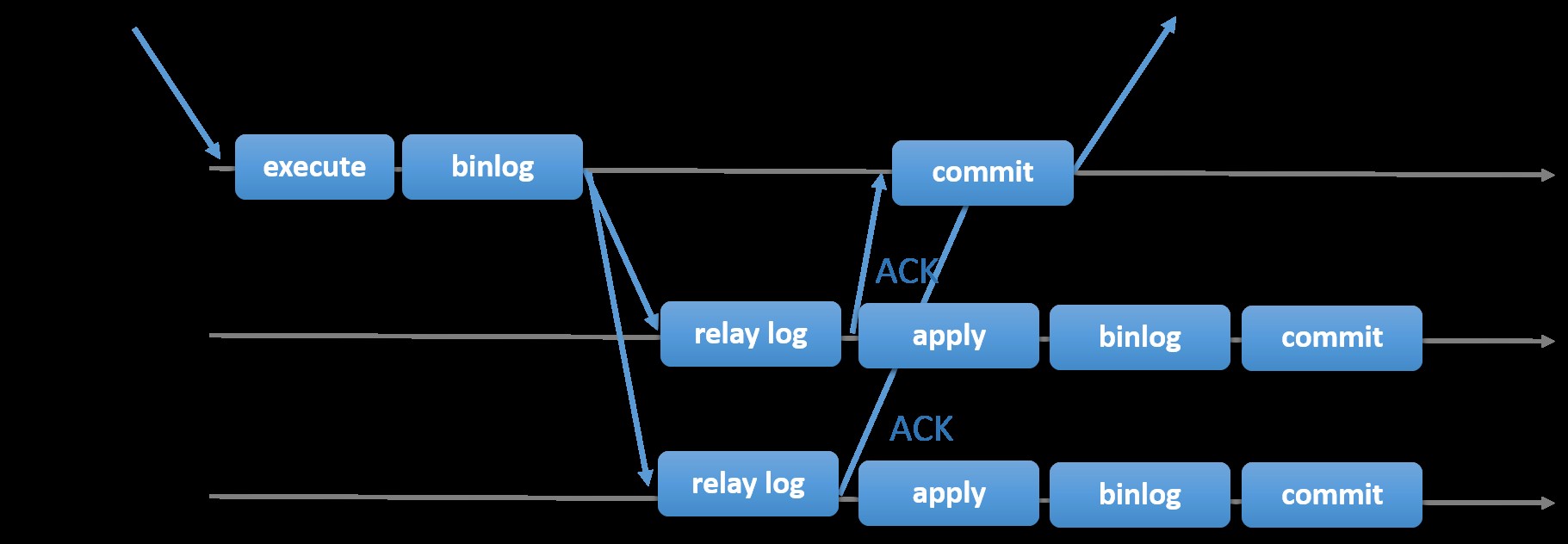 画像提供:MySQLドキュメント
画像提供:MySQLドキュメント この実装では、マスターがクラッシュした場合に、コミットされたすべてのトランザクションが少なくとも1つのスレーブにすでに複製されています。準同期は、それ自体では高可用性ソリューションを表すものではありませんが、ソリューションのコンポーネントです。ニーズを把握し、それに応じて半同期の実装を調整することをお勧めします。したがって、ある程度のデータ損失が許容できる場合は、代わりに従来の非同期レプリケーションを使用できます。
GTIDベースのレプリケーションは、特にスレーブが別のマスターまたは新しいマスターを指している場合に、フェイルオーバーを実行するタスクを簡素化するため、DBAに役立ちます。これは、正しいホストとレプリケーションの資格情報を設定した後、単純なMASTER_AUTO_POSITION =1を使用すると、正しいバイナリログのxとyの位置を見つけて指定しなくても、マスターからのレプリケーションを開始することを意味します。並列レプリケーションのサポートを追加すると、リレーログからのイベントを処理する速度が向上するため、レプリケーションスレッドも向上します。
したがって、MySQLレプリケーションは、ニーズに合っている場合、他のHAソリューションよりも優れた選択コンポーネントです。
MySQLレプリケーションのトポロジ
オンプレミスでレプリケーションする必要がある場合でも、GCP(Google Cloud Platform)とAWSを使用してマルチクラウド環境にMySQLレプリケーションをデプロイすることは同じアプローチです。
セットアップして実装できるさまざまなトポロジがあります。
スレーブレプリケーションを備えたマスター(シングルレプリケーション)
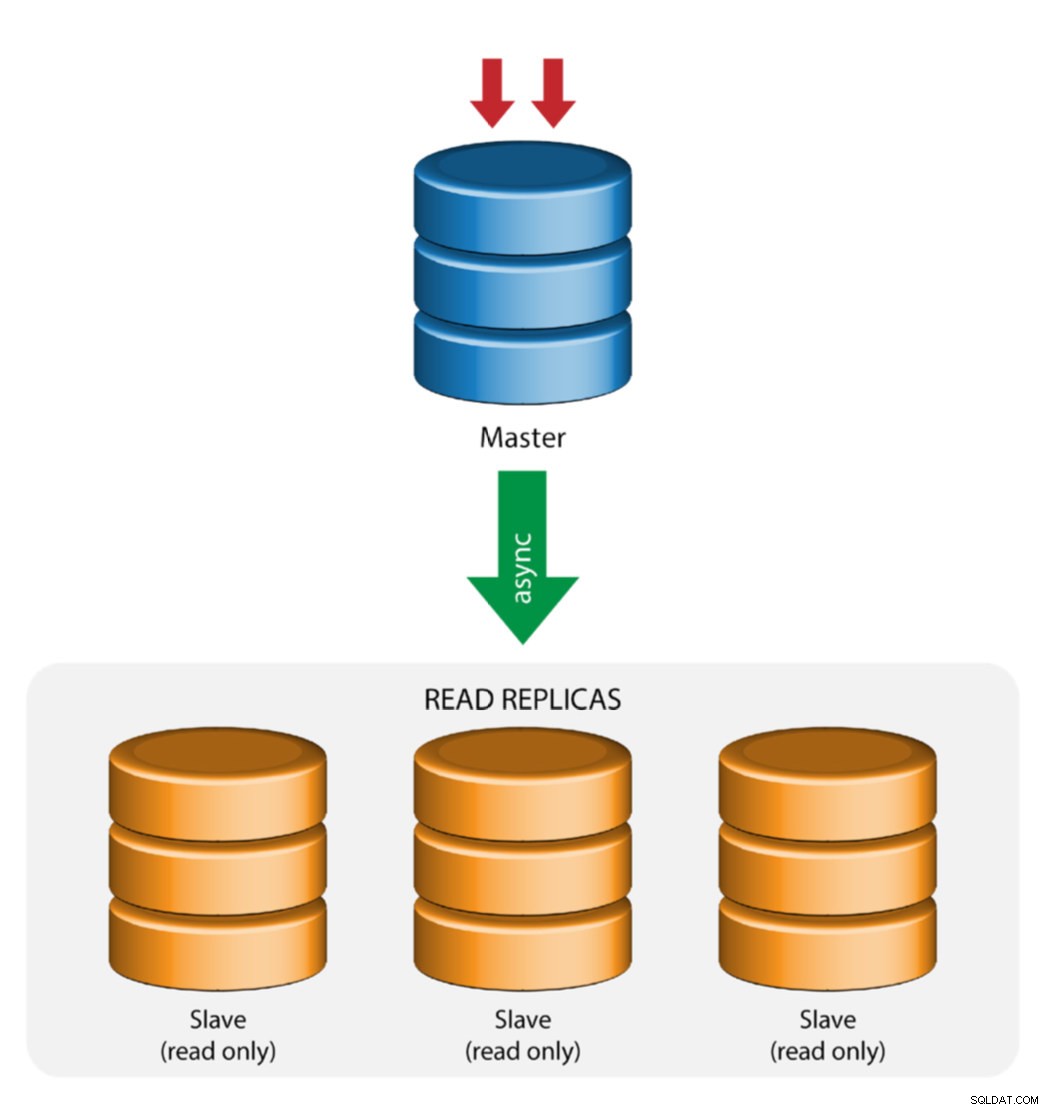
これは最も単純なMySQLレプリケーショントポロジです。 1つのマスターが書き込みを受信し、1つ以上のスレーブが非同期または準同期レプリケーションを介して同じマスターからレプリケートします。指定されたマスターがダウンした場合、最新のスレーブを新しいマスターとして昇格させる必要があります。残りのスレーブは、新しいマスターからのレプリケーションを再開します。
リレースレーブを備えたマスター(チェーンレプリケーション)
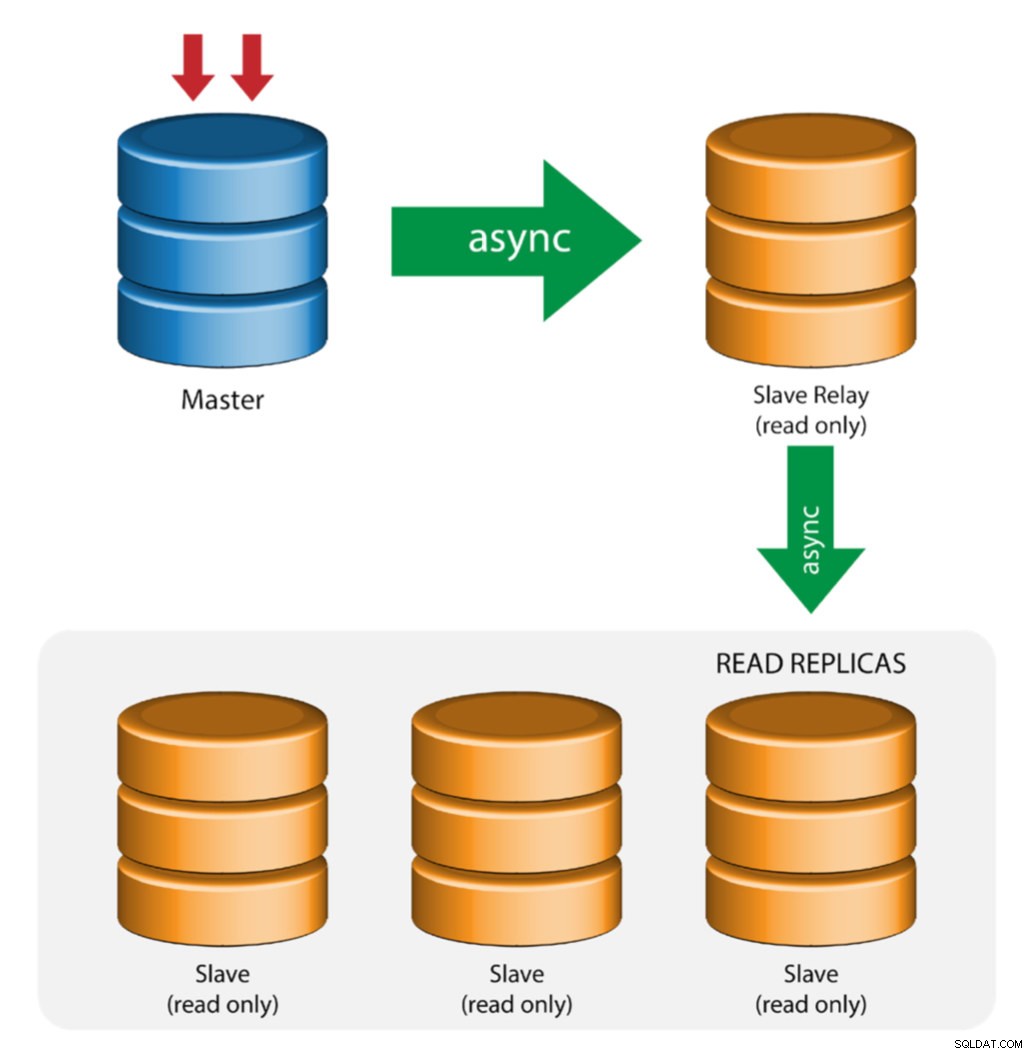
このセットアップでは、中間マスターを使用して、レプリケーションチェーン内の他のスレーブへのリレーとして機能します。マスターに接続されているスレーブが多数ある場合、マスターのネットワークインターフェイスが過負荷になる可能性があります。このトポロジにより、読み取りレプリカは、リレーサーバーからレプリケーションストリームをプルして、マスターサーバーの負荷を軽減できます。スレーブリレーサーバーでは、バイナリロギングとlog_slave_updatesを有効にする必要があります。これにより、スレーブサーバーがマスターサーバーから受信した更新は、スレーブ自身のバイナリログに記録されます。
スレーブリレーの使用には問題があります:
- log_slave_updatesにはパフォーマンス上のペナルティがあります。
- スレーブリレーサーバーでのレプリケーションの遅延により、すべてのスレーブで遅延が発生します。
- スレーブリレーサーバーでの不正なトランザクションは、そのすべてのスレーブに感染します。
- スレーブリレーサーバーに障害が発生し、GTIDを使用していない場合、そのすべてのスレーブは複製を停止し、再初期化する必要があります。
アクティブマスターを使用したマスター(循環レプリケーション)
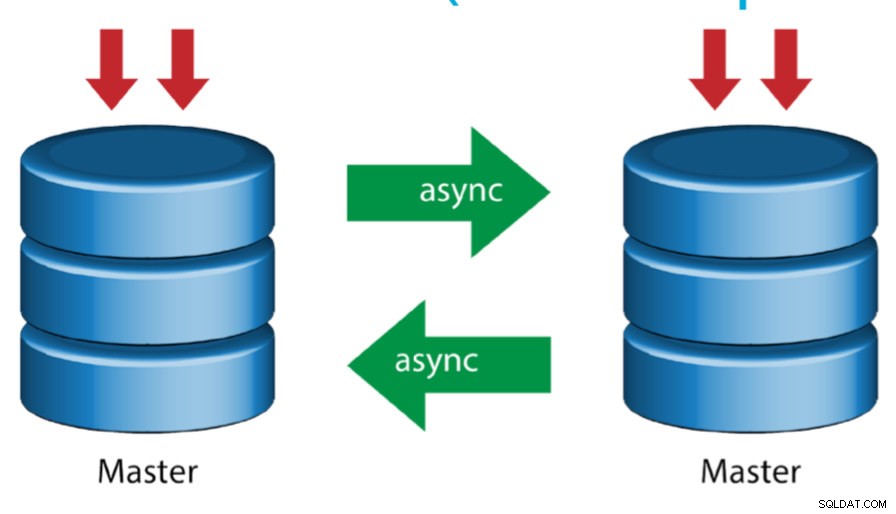
リングトポロジとも呼ばれるこのセットアップには、マスターとして機能する2つ以上のMySQLサーバーが必要です。すべてのマスターは書き込みを受け取り、いくつかの注意事項を付けてbinlogを生成します:
- 主キーの衝突を回避するには、各サーバーで自動インクリメントオフセットを設定する必要があります。
- 競合の解決はありません。
- MySQLレプリケーションは現在、2つの異なるサーバー間で分散された更新のアトミック性を保証するためのマスターとスレーブ間のロックプロトコルをサポートしていません。
- 一般的な方法は、一方のマスターにのみ書き込むことであり、もう一方のマスターはホットスタンバイノードとして機能します。それでも、その層の下にスレーブがある場合、指定されたマスターに障害が発生した場合は、手動で新しいマスターに切り替える必要があります。
- ClusterControlはこのトポロジをサポートします(レプリケーション設定で複数のライターを使用することはお勧めしません)。 ClusterControlを使用してデプロイする方法については、この以前のブログを参照してください。
マスターとバックアップマスター(複数のレプリケーション)
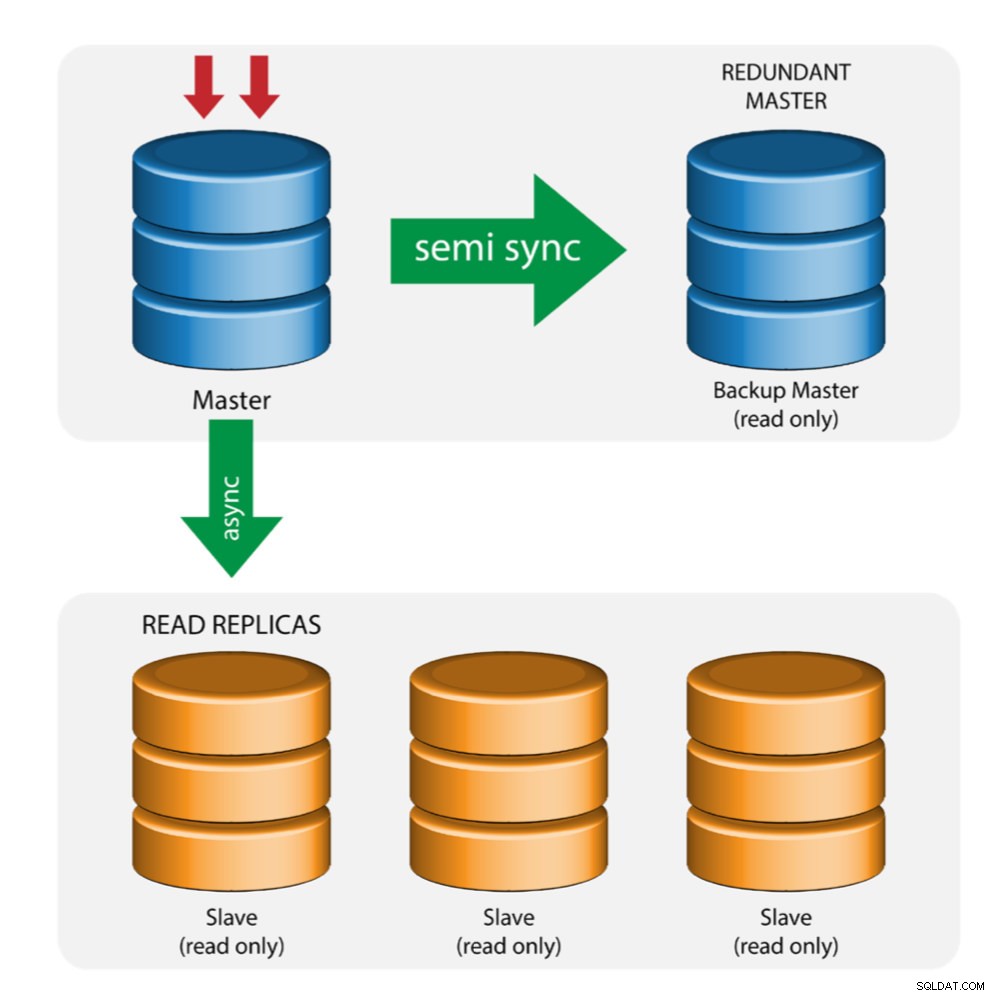
マスターは、変更をバックアップマスターと1つ以上のスレーブにプッシュします。マスターとバックアップマスターの間で準同期レプリケーションが使用されます。マスターは更新をバックアップマスターに送信し、トランザクションのコミットを待ちます。バックアップマスターは更新を取得し、リレーログに書き込み、ディスクにフラッシュします。次に、バックアップマスターは、マスターへのトランザクションの受信を確認し、トランザクションのコミットを続行します。半同期レプリケーションはパフォーマンスに影響を与えますが、データ損失のリスクは最小限に抑えられます。
このトポロジは、マスターがダウンした場合にマスターフェイルオーバーを実行するときに適切に機能します。バックアップマスターは、他のスレーブと比較して最新のデータを持つ可能性が最も高いため、ウォームスタンバイサーバーとして機能します。
複数のマスターから単一のスレーブ(マルチソースレプリケーション)
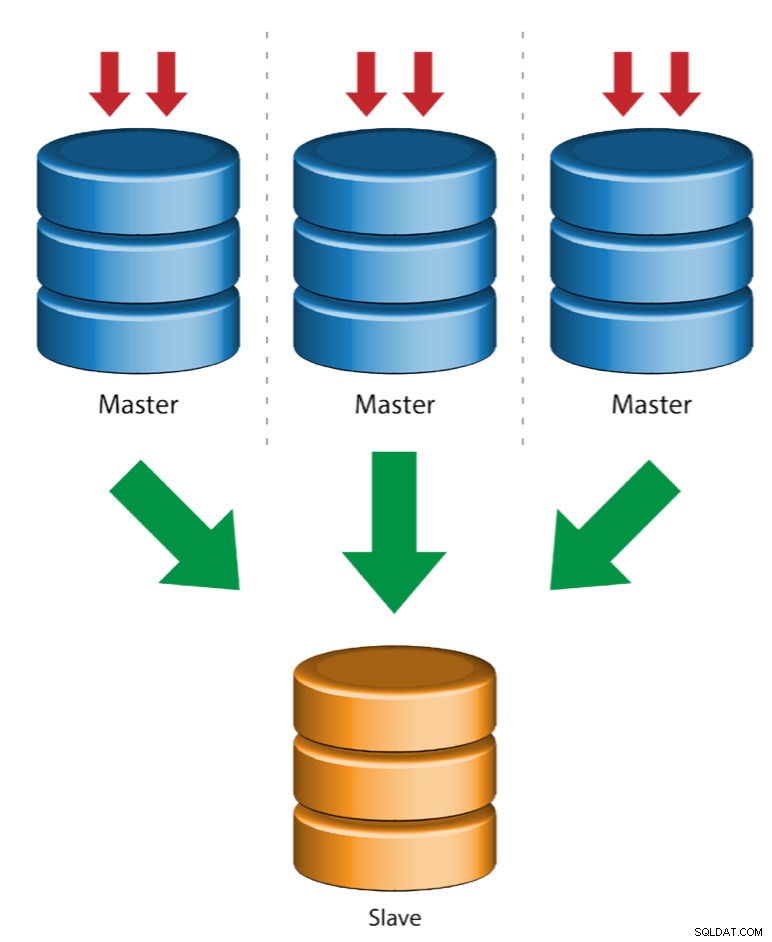
マルチソースレプリケーションにより、レプリケーションスレーブは複数のソースから同時にトランザクションを受信できます。マルチソースレプリケーションを使用して、複数のサーバーを1つのサーバーにバックアップしたり、テーブルシャードをマージしたり、複数のサーバーからのデータを1つのサーバーに統合したりできます。
MySQLとMariaDBには、マルチソースレプリケーションの実装が異なります。MariaDBでは、元のトランザクションを区別するようにgtid-domain-idを設定したGTIDが必要ですが、MySQLは、スレーブがレプリケートするマスターごとに個別のレプリケーションチャネルを使用します。 MySQLでは、マルチソースレプリケーショントポロジのマスターは、グローバルトランザクション識別子(GTID)ベースのレプリケーションまたはバイナリログ位置ベースのレプリケーションのいずれかを使用するように構成できます。
MariaDBマルチソースレプリケーションの詳細については、このブログ投稿をご覧ください。 MySQLについては、MySQLのドキュメントを参照してください。
レプリケーションスレーブを備えたガレラ(ハイブリッドレプリケーション)
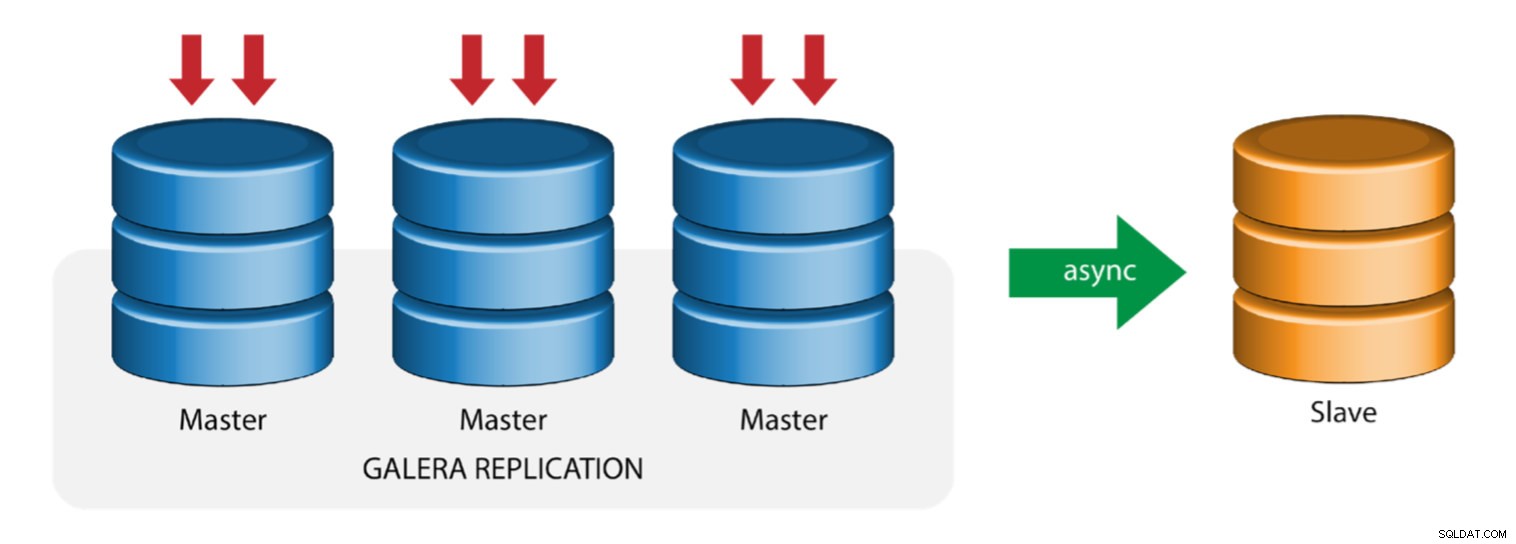
ハイブリッドレプリケーションは、Galeraが提供するMySQL非同期レプリケーションと仮想同期レプリケーションの組み合わせです。 MySQLレプリケーションでのGTIDの実装により、展開が簡素化され、マスターフェイルオーバーの設定と実行がスレーブ側での簡単なプロセスになりました。
Galeraクラスターのパフォーマンスは、最も遅いノードと同じくらい高速です。非同期レプリケーションスレーブを使用すると、長時間実行されるレポート/ OLAPタイプのクエリをスレーブに送信する場合、またはmysqldumpのようなロックを必要とする重いジョブを実行する場合に、クラスターへの影響を最小限に抑えることができます。スレーブは、オンサイトおよびオフサイトのディザスタリカバリのライブバックアップとしても機能します。
ハイブリッドレプリケーションはClusterControlでサポートされており、ClusterControlUIから直接デプロイできます。これを行う方法の詳細については、ブログ投稿(MySQL 5.6を使用したハイブリッドレプリケーションおよびMariaDB10.xを使用したハイブリッドレプリケーション)を参照してください。
GCPおよびAWSプラットフォームの準備
「現実の」問題
このブログでは、2つの異なるパブリッククラウドプラットフォーム上のインスタンスが、異なるリージョンおよび異なるアベイラビリティーゾーンでMySQLレプリケーションを使用して通信する「マルチレプリケーション」トポロジを示し、使用します。このシナリオは、組織がスケーラビリティ、冗長性、復元力/フォールトトレランスのために複数のクラウドプラットフォーム上でインフラストラクチャを設計したいという現実の問題に基づいています。同様の概念がMongoDBまたはPostgreSQLにも当てはまります。
東南アジアに海外支社を持つ米国の組織を考えてみましょう。私たちのトラフィックは、アジアを拠点とする地域内で高くなっています。書き込みと読み取りに対応する場合、レイテンシは低くする必要がありますが、同時に、米国を拠点とする地域は、アジアを拠点とするトラフィックからのレコードをプルアップすることもできます。
クラウドアーキテクチャフロー
このセクションでは、建築設計について説明します。まず、GoogleComputeノードとAWSEC2ノードがインターネットからパッケージを通信、更新、またはインストールでき、AZ(Availability Zone)がダウンした場合に安全で可用性が高く、複製でき、セキュリティで保護されたレイヤーを介して別のクラウドプラットフォームと通信します。説明については、以下の画像を参照してください:

上の図に基づくと、AWSプラットフォームでは、すべてのノードが異なるアベイラビリティーゾーンで実行されています。すべての計算ノードがプライベートサブネット上にあるプライベートサブネットとパブリックサブネットがあります。したがって、インターネットの外部に出て、必要に応じてシステムパッケージをプルおよび更新できます。 VPNゲートウェイがあり、そのチャネルでGCPとやり取りする必要があります。インターネットをバイパスしますが、安全でプライベートなチャネルを経由します。 GCPと同様に、すべてのコンピューティングノードは異なるアベイラビリティーゾーンにあり、必要に応じてNATゲートウェイを使用してシステムパッケージを更新し、VPN接続を使用して異なるリージョン(アジアパシフィック(シンガポール))でホストされているAWSノードとやり取りします。一方、米国を拠点とする地域は、us-east1の下でホストされています。ノードにアクセスするために、アーキテクチャ内の1つのノードが要塞ノードとして機能し、ジャンプホストとして使用してClusterControlをインストールします。これについては、このブログの後半で取り上げます。
GCPとAWS環境のセットアップ
最初のGCPアカウントを登録するときに、GoogleはデフォルトのVPC(仮想プライベートクラウド)アカウントを提供します。したがって、デフォルトとは別のVPCを作成し、必要に応じてカスタマイズすることをお勧めします。
ここでの目標は、計算ノードをプライベートサブネットに配置することです。そうしないと、ノードはパブリックIPv4でセットアップされません。したがって、両方のパブリッククラウドは互いに通信できる必要があります。 AWSとGCPのコンピューティングノードは、前述のように異なるCIDRで動作します。したがって、次のCIDRがあります。
AWSコンピューティングノード: 172.21.0.0/16
GCPコンピューティングノード: 10.142.0.0/20
このAWSセットアップでは、インターネットゲートウェイではなくNATゲートウェイを持つ3つのサブネットを割り当てました。インターネットゲートウェイを持つ1つのサブネット。これらの各サブネットは、異なるアベイラビリティーゾーン(AZ)で個別にホストされます。
ap-southeast-1a =172.21.1.0/24
ap-southeast-1b =172.21.8.0/24
ap-southeast-1c =172.21.24.0/24
GCPでは、us-east1の下のVPCで作成されたデフォルトのサブネットである10.142.0.0/20CIDRが使用されます。したがって、これらはマルチパブリッククラウドプラットフォームをセットアップするために実行できる手順です。
-
この演習では、次のサブネットが10.142.0.0/20のus-east1リージョンにVPCを作成しました。以下を参照してください:

-
静的IPを予約します。これは、AWSでカスタマーゲートウェイとして設定するIPです
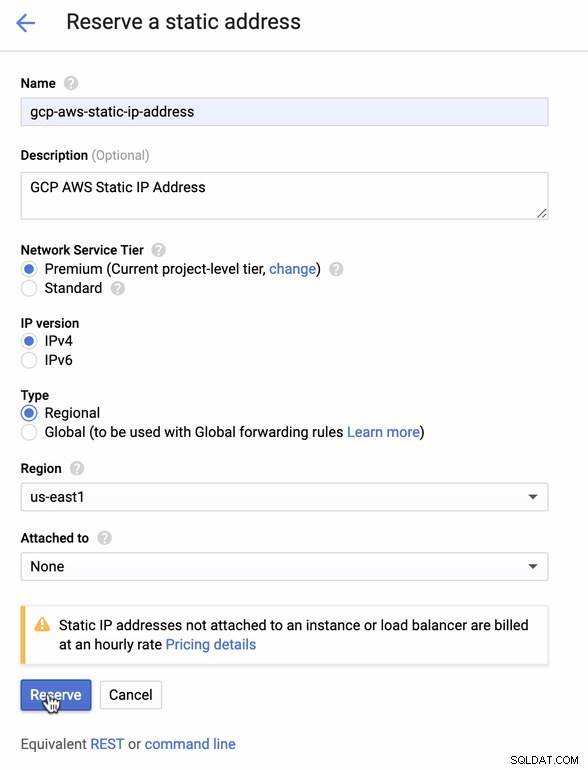
-
サブネットが配置されているため( subset-us-east1としてプロビジョニングされています )、 GCP-> VPC Network-> VPC Networksに移動します 作成したVPCを選択し、ファイアウォールルールに移動します 。このセクションでは、入力と出力を指定してルールを追加します。基本的に、これらはAWSまたはファイアウォールの着信および発信接続のインバウンド/アウトバウンドルールです。このセットアップでは、AWSとGCP VPCで設定されたCIDR範囲からすべてのTCPプロトコルを開いて、このブログの目的のために簡単にしました。したがって、これはセキュリティのための最適な方法ではありません。下の画像を参照してください:
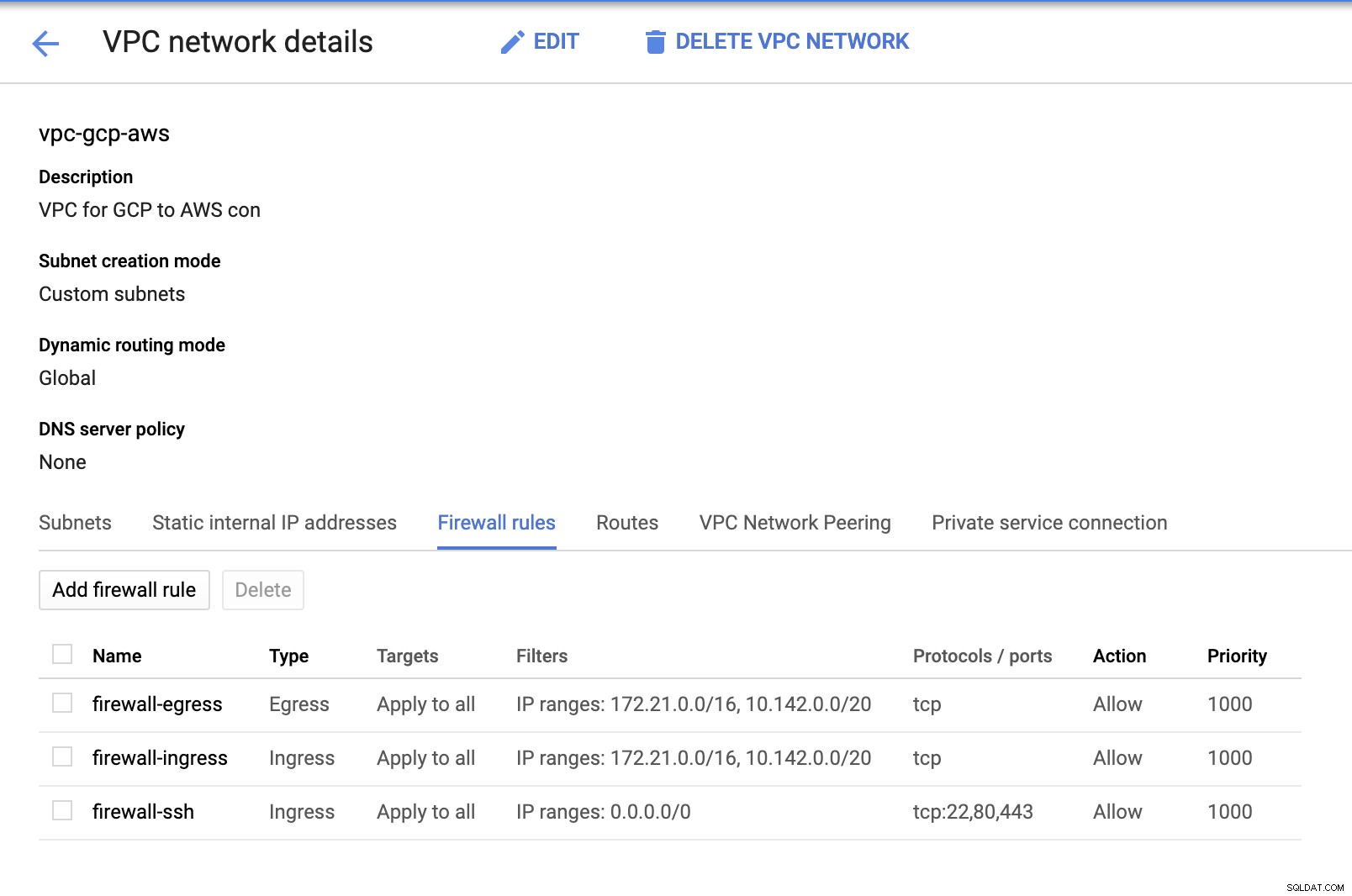
ここでのfirewall-sshは、ssh、HTTP、およびHTTPSの着信接続を許可するために使用されます。
-
次に、AWSに切り替えて、VPCを作成します。このブログでは、CIDR(クラスレスドメイン間ルーティング)172.21.0.0/16を使用しました
-
各AZ(アベイラビリティーゾーン)で割り当てる必要のあるサブネットを作成します。少なくとも1つのサブネットをNATゲートウェイを処理するパブリックサブネット用に予約し、残りはEC2ノード用に予約します。

-
次に、ルートテーブルを作成し、「宛先」と「ターゲット」が正しく設定されていることを確認します。このブログでは、2つのルートテーブルを作成しました。私の計算ノードが個別に割り当てられ、パブリックIPがないため、インターネットゲートウェイなしで割り当てられる3つのAZを処理するもの。次に、もう1つはNATゲートウェイを処理し、パブリックサブネットにあるインターネットゲートウェイを持ちます。下の画像を参照してください:

前述のように、3つのサブネットを処理するプライベートルートの宛先の例は、NATゲートウェイターゲットと仮想ゲートウェイターゲットを持っていることを示しています。これについては、後の手順で説明します。

-
次に、「インターネットゲートウェイ」を作成し、AWSVPCセクションで以前に作成したVPCに割り当てます。このインターネットゲートウェイは、インターネットに接続する必要があるサービスであるため、パブリックサブネットへの宛先としてのみ設定する必要があります。明らかに、その名前はインターネットゲートウェイサービスを表しています。
-
次に、「NATゲートウェイ」を作成します。 「NATゲートウェイ」を作成するときは、NATが公開されているサブネットに割り当てられていることを確認してください。 NATゲートウェイは、パブリックIPv4が割り当てられていないプライベートサブネットまたはEC2ノードからインターネットにアクセスするためのチャネルです。次に、EIP(Elastic IP)を作成または割り当てます。これは、AWSでは、パブリックIPv4が割り当てられているコンピューティングノードのみがインターネットに直接接続できるためです。
-
現在、 VPC-> Security-> Security Groups(SG) 、作成したVPCにはデフォルトのSGがあります。この設定では、各CIDRにソースが割り当てられた「インバウンドルール」を作成しました。つまり、GCPでは10.142.0.0/20、AWSでは172.21.0.0/16です。以下を参照してください:

「アウトバウンドルール」の場合、「インバウンドルール」へのルールの割り当ては二国間であるため、そのままにしておくことができます。つまり、「アウトバウンドルール」に対してもオープンになります。これはセキュリティグループを設定するための最適な方法ではないことに注意してください。ただし、この設定を簡単にするために、ポート範囲とソースの範囲も広くしました。また、このブログではUDPを扱っていないため、プロトコルはTCP接続にのみ固有です。
さらに、VPC->セキュリティ->ネットワークACL> ソースに記載されているCIDRからのtcp接続を拒否しない限り、変更されません。 -
次に、AWSプラットフォームでホストされるVPN構成をセットアップします。 VPC->カスタマーゲートウェイの下 、前の手順で作成した静的IPアドレスを使用してゲートウェイを作成します。下の画像を見てください:
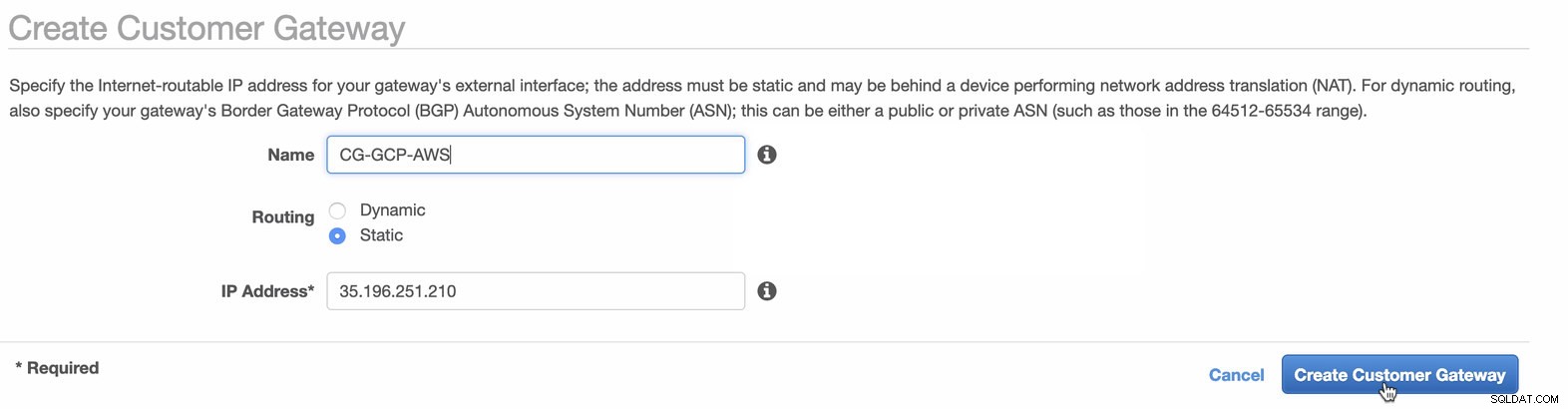
-
次に、仮想プライベートゲートウェイを作成し、これを前の手順で作成した現在のVPCに接続します。下の画像を参照してください:

-
次に、AWSとGCP間のサイト間接続に使用されるVPN接続を作成します。 VPN接続を作成するときは、前の手順で作成した正しい仮想プライベートゲートウェイとカスタマーゲートウェイを選択していることを確認してください。下の画像を参照してください:
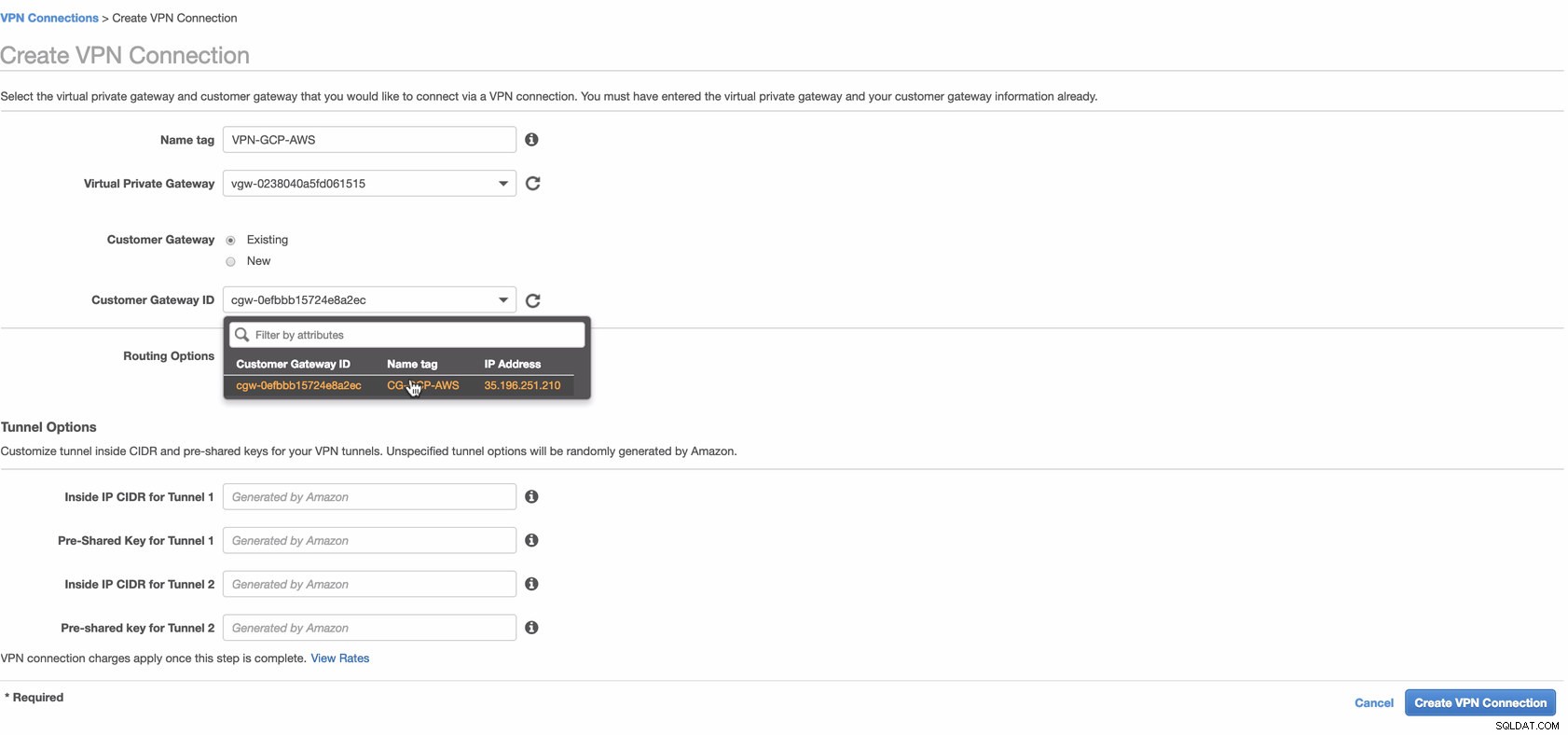
AWSがVPN接続を作成している間、これには時間がかかる場合があります。その後、VPN接続がプロビジョニングされると、(VPN接続を選択した後の)[トンネル]タブで、外部IPアドレスが表示されるのはなぜか疑問に思うかもしれません。 ダウンしています。クライアントからまだ接続が確立されていないため、これは正常です。以下の画像の例を見てください:

VPN接続の準備ができたら、作成したVPN接続を選択し、構成をダウンロードします。これには、クライアントとのサイト間VPN接続を作成するための次の手順に必要な資格情報が含まれています。
注: IPsec IS UPでVPNを設定した場合 ただし、ステータス ダウンです 下の画像のように

これは、BGPセッションまたはクラウドルーターのセットアップ中に特定のパラメーターに誤った値が設定されていることが原因である可能性があります。 VPNのトラブルシューティングについては、こちらをご覧ください。
-
AWSでVPN接続をホストする準備ができているので、GCPでVPN接続を作成しましょう。それでは、GCPに戻って、そこでクライアント接続を設定しましょう。 GCPで、 GCP-> Hybrid Connectivity-> VPNに移動します 。このブログにある正しい地域を選択していることを確認してください。us-east1を使用しています 。次に、前の手順で作成した静的IPアドレスを選択します。下の画像を参照してください:
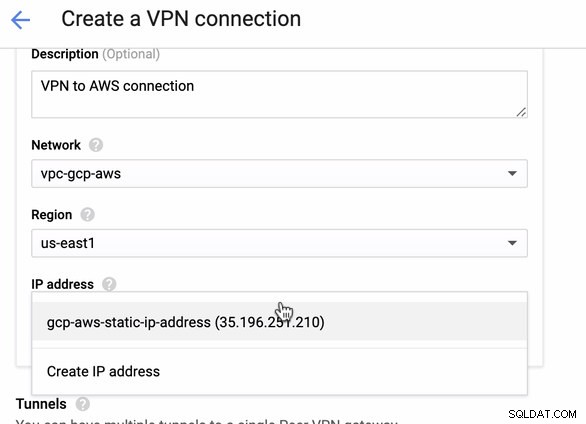
次に、トンネルで セクションでは、これは、以前に作成したAWSVPN接続からダウンロードしたクレデンシャルに基づいて設定する必要がある場所です。 Googleのこの役立つガイドを確認することをお勧めします。たとえば、セットアップ中のトンネルの1つを次の画像に示します。
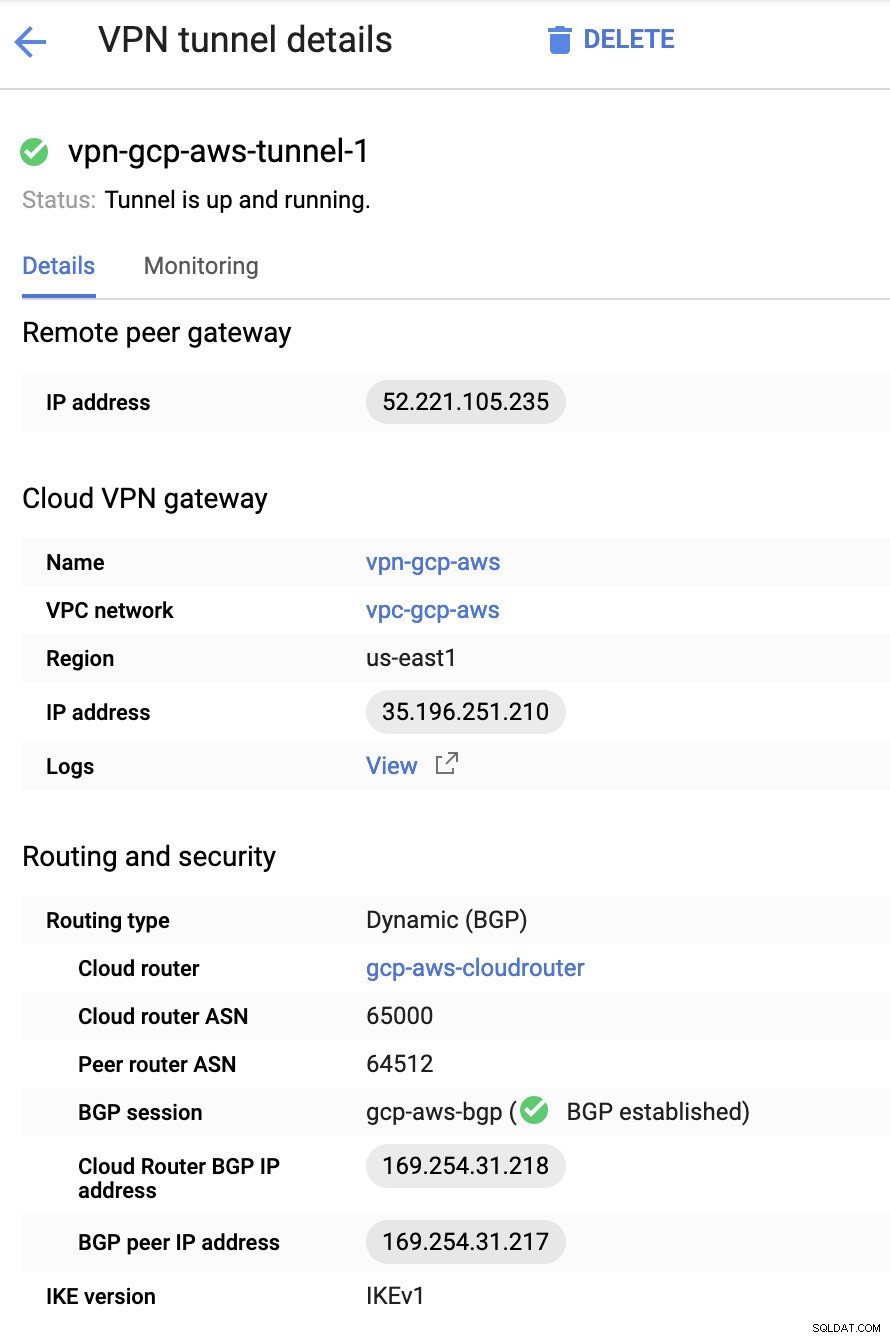
基本的に、ここで最も重要なことは次のとおりです。
- リモートピアゲートウェイ:IPアドレス-これは、トンネルの詳細->外部IPアドレスに記載されているVPNサーバーのIPです。 。これは、GCPで作成した静的IPと混同しないでください。これがクラウドVPNゲートウェイ->IPアドレスです。
- クラウドルーターASN-デフォルトでは、AWSは65000を使用します。ただし、この情報は、ダウンロードした構成ファイルから取得される可能性があります。
- ピアルーターASN-これは仮想プライベートゲートウェイASNです。 ダウンロードした構成ファイルにあります。
- クラウドルーターのBGPIPアドレス-これはカスタマーゲートウェイです ダウンロードした構成ファイルにあります。
- BGPピアIPアドレス-これは仮想プライベートゲートウェイです ダウンロードした構成ファイルにあります。
-
以下にある設定ファイルの例を見てください:
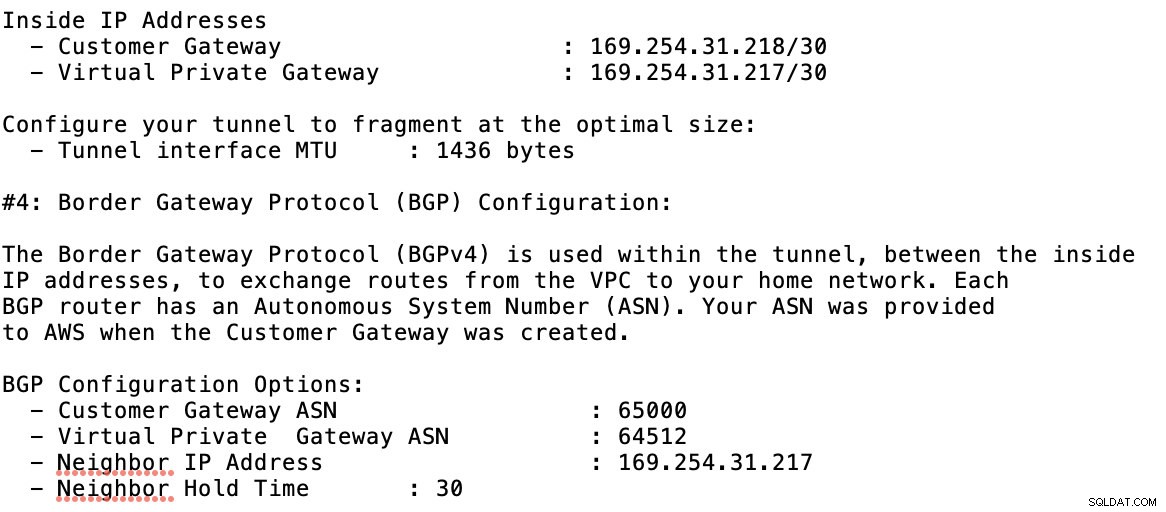
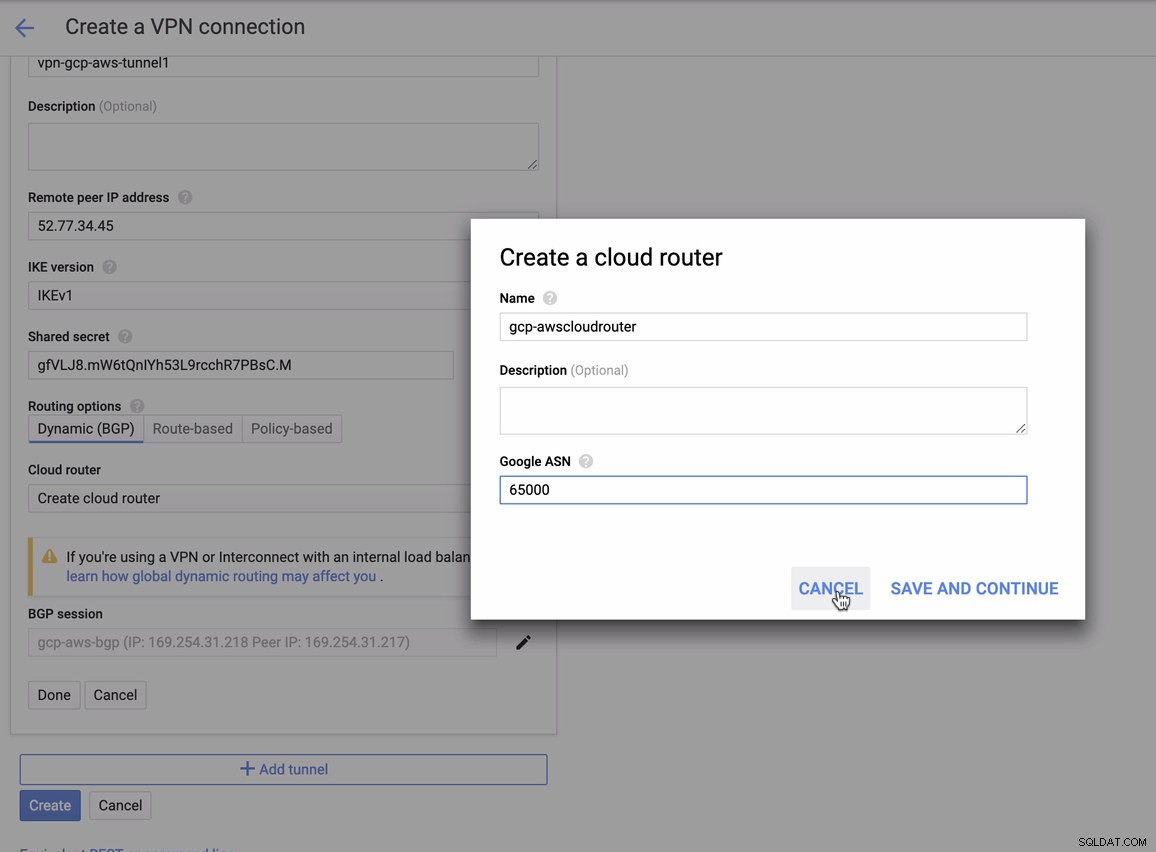
GCP->ハイブリッド接続->VPNでトンネルを追加するときにこれを一致させる必要があります 接続のセットアップ。サンプルトンネルの作成中にクラウドルーターとBGPセッションを作成した以下の画像を参照してください。
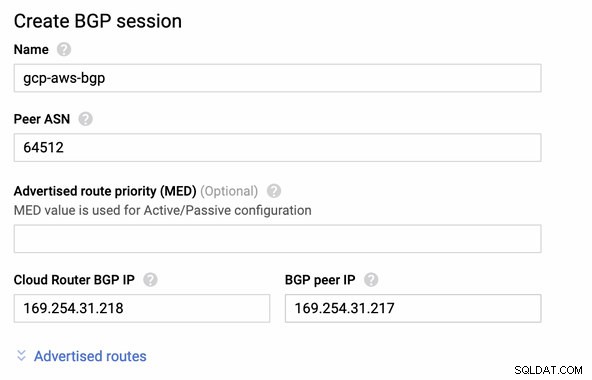
次に、BGPセッションとして

注: ダウンロードされた設定ファイルには、AWSにも接続の準備ができている2つのVPNサーバーが含まれているIPSec設定トンネルが含まれています。高可用性セットアップを使用できるように、両方をセットアップする必要があります。両方のトンネルが正しく設定されると、[トンネル]タブのAWS VPN接続で、両方の外部IPアドレスが表示されます。 上がっています。下の画像を参照してください:

-
最後に、インターネットゲートウェイとNATゲートウェイを作成したので、パブリックサブネットとプライベートサブネットに正しい宛先を正しく入力します。 およびターゲット 前の手順のスクリーンショットにあるように。これは、サービス->ネットワーキングとコンテンツ配信->VPC->ルートテーブルに移動して設定できます。 前の手順で説明した、作成したルートテーブルを選択します。下の画像を参照してください:
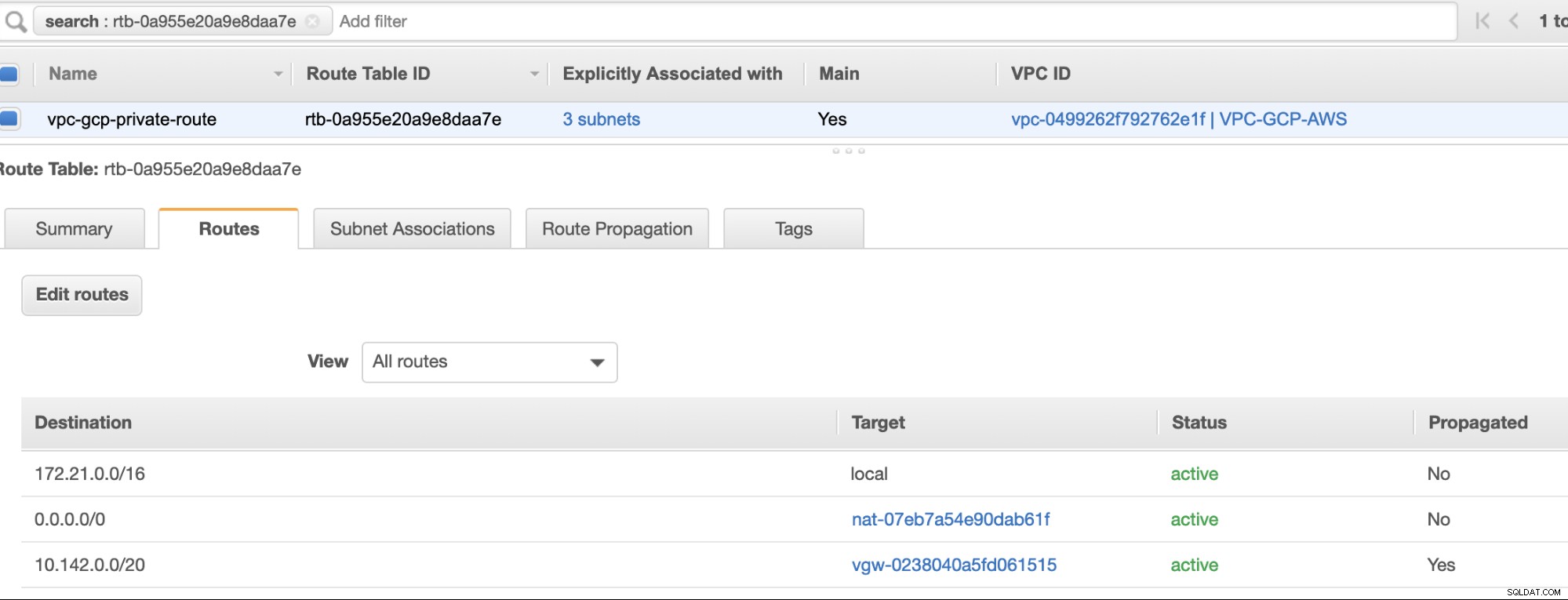
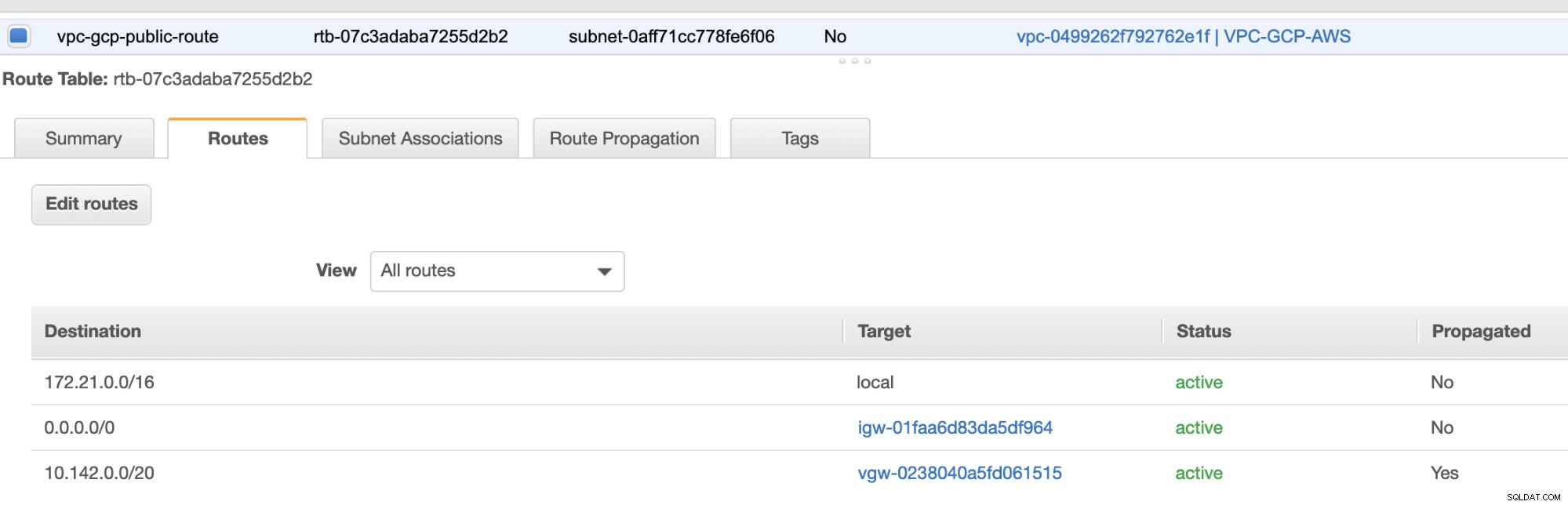
お気づきのとおり、 igw-01faa6d83da5df964 は、私たちが作成し、パブリックルートで使用されているインターネットゲートウェイです。一方、プライベートルートテーブルでは、宛先とターゲットが nat-07eb7a54e90dab61fに設定されています。 これらの両方に宛先があります さまざまなIPv4接続から許可されるため、0.0.0.0/0に設定します。また、ルート伝搬を設定することを忘れないでください ターゲットvgw-0238040a5fd061515を持つスクリーンショットに見られるように仮想ゲートウェイに対して正しく 。下のスクリーンショットのように、[ルートの伝播]をクリックして[はい]に設定するだけです。
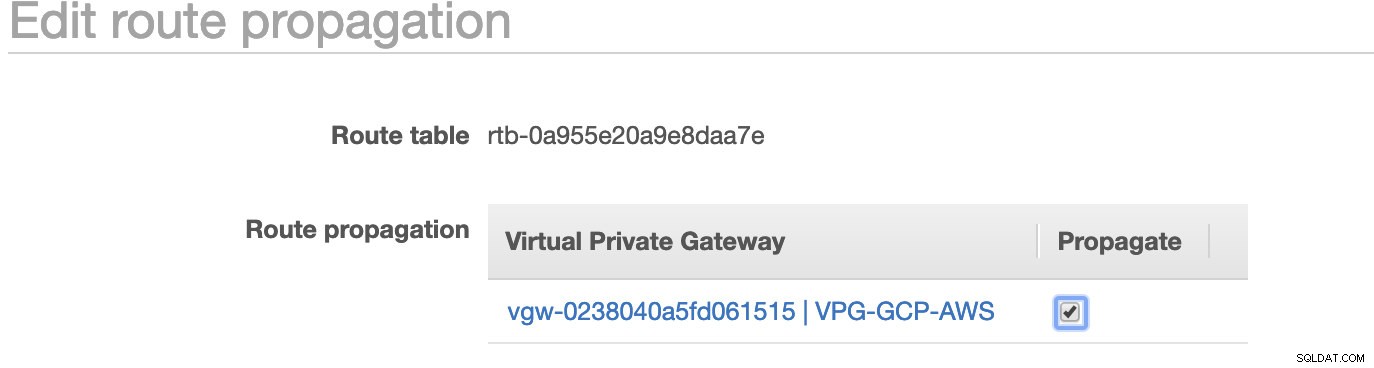
これは、外部GCP接続からの接続がAWSのルートテーブルにルーティングされ、それ以上の手動作業が不要になるようにするために非常に重要です。そうしないと、GCPがAWSへの接続を確立できません。
VPNが起動したので、要塞ホストを含むプライベートノードの設定を続行します。
コンピューティングエンジンノードの設定
Compute Engine / EC2ノードのセットアップは、すべてのセットアップが整っているため、すばやく簡単に行えます。詳細については説明しませんが、セットアップについて説明している以下のスクリーンショットを確認してください。
AWSEC2ノード :

GCPコンピューティングノード :
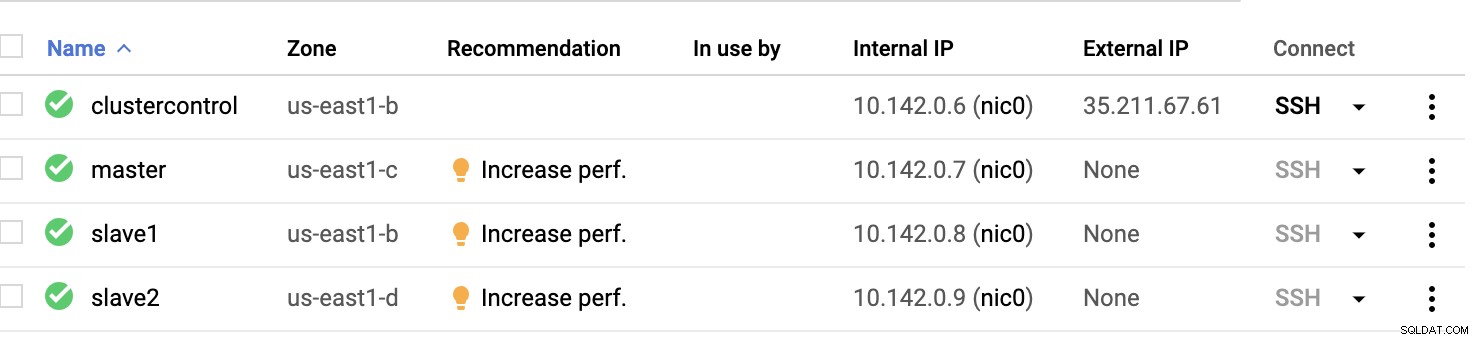
基本的に、この設定では。ホストclustercontrol 要塞またはジャンプホストになり、ClusterControlがインストールされます。明らかに、ここのすべてのノードはインターネットにアクセスできるわけではありません。外部IPv4が割り当てられておらず、ノードはVPNを使用して非常に安全なチャネルを介して通信しています。
最後に、AWSからGCPまでのこれらすべてのノードは、次のセクションで必要となる、sudoアクセスを持つ1人の統一されたシステムユーザーでセットアップされます。 ClusterControlを使用すると、マルチクラウドおよびマルチリージョンでの生活がどのように楽になるかをご覧ください。
ClusterControl To the Rescue !!!
複数のノードを処理し、異なるパブリッククラウドプラットフォームで、さらに異なる「地域」で処理することは、「本当に苦痛で困難な」作業になる可能性があります。それをどのように効果的に監視しますか? ClusterControlは、スイスナイフとしてだけでなく、仮想DBAとしても機能します。それでは、ClusterControlがどのようにあなたの生活を楽にすることができるか見てみましょう。
ClusterControlを使用した複数レプリケーションクラスターの作成
それでは、「マルチレプリケーション」トポロジに従って、MariaDBマスタースレーブレプリケーションクラスターを作成してみましょう。
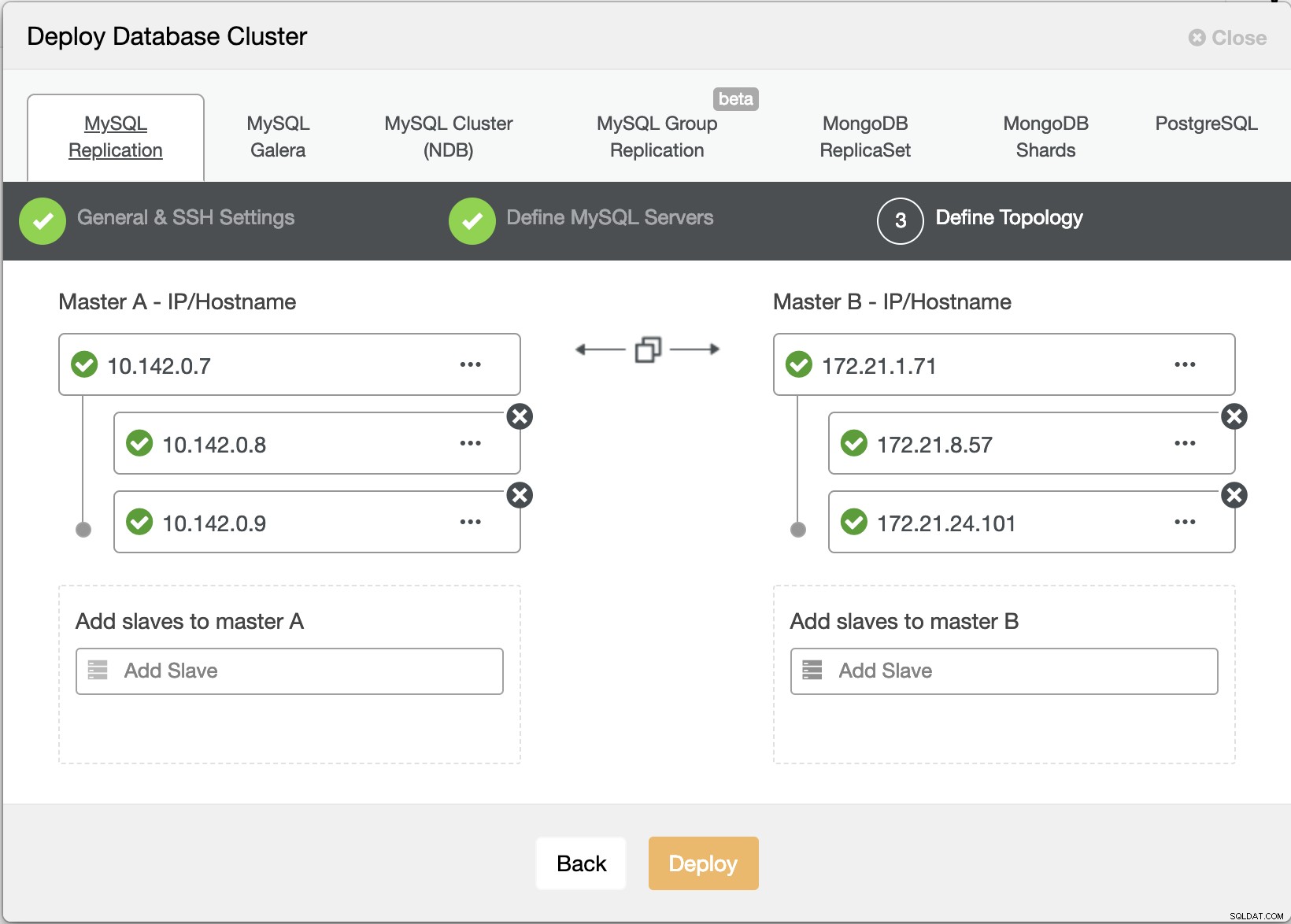 ClusterControlデプロイウィザード
ClusterControlデプロイウィザード 展開を押す ボタンはパッケージをインストールし、それに応じてノードをセットアップします。したがって、トポロジがどのように見えるかの論理ビュー:
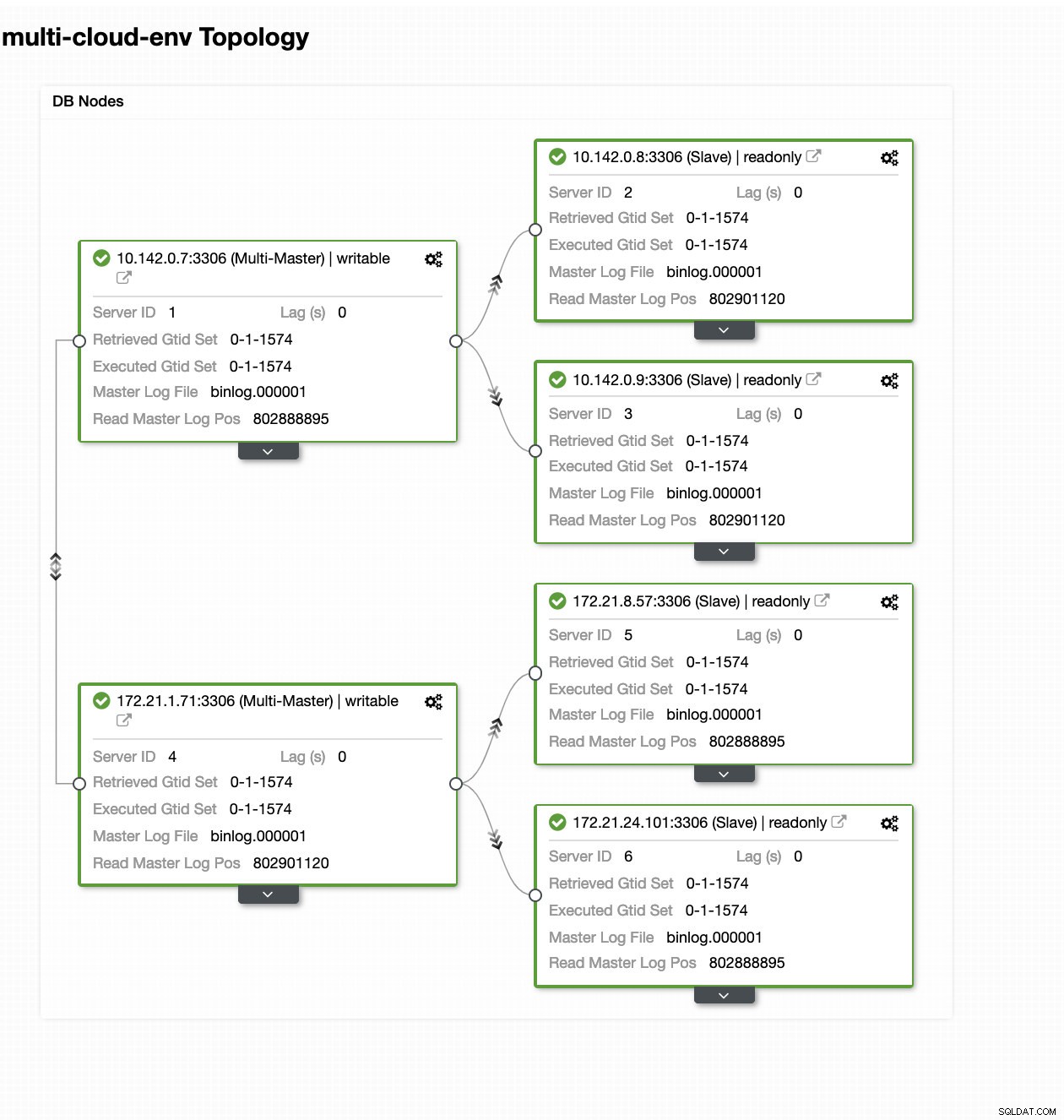 ClusterControl-トポロジビュー
ClusterControl-トポロジビュー ノード172.21.0.0/16の範囲のIPは、GCPで実行されているマスターから複製されています。
では、マスターに書き込みをロードしてみてはどうでしょうか。接続性または遅延に関する問題はスレーブラグを生成する可能性があります。ClusterControlを使用してこれを見つけることができます。以下のスクリーンショットを参照してください:
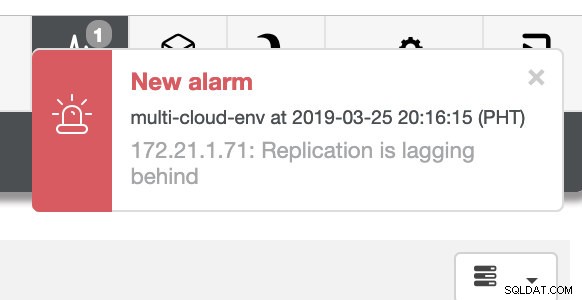
スクリーンショットの右上隅に表示されているように、問題が検出されたことを示すため、赤に変わります。したがって、この問題が検出されている間、アラームが送信されていました。以下を参照してください:
これを掘り下げる必要があります。きめ細かい監視のために、データベースインスタンスでエージェントを有効にしました。ダッシュボードを見てみましょう。
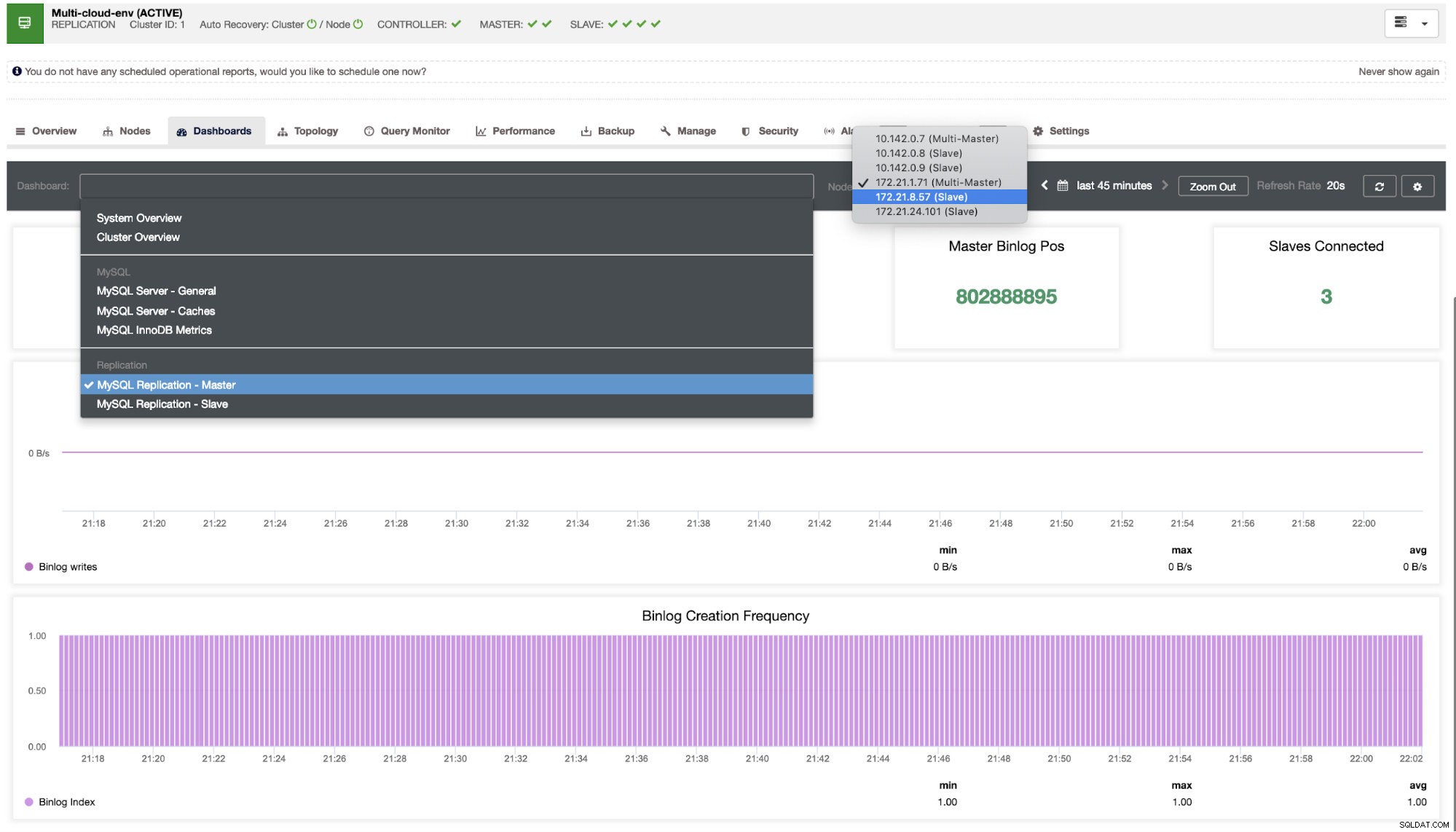
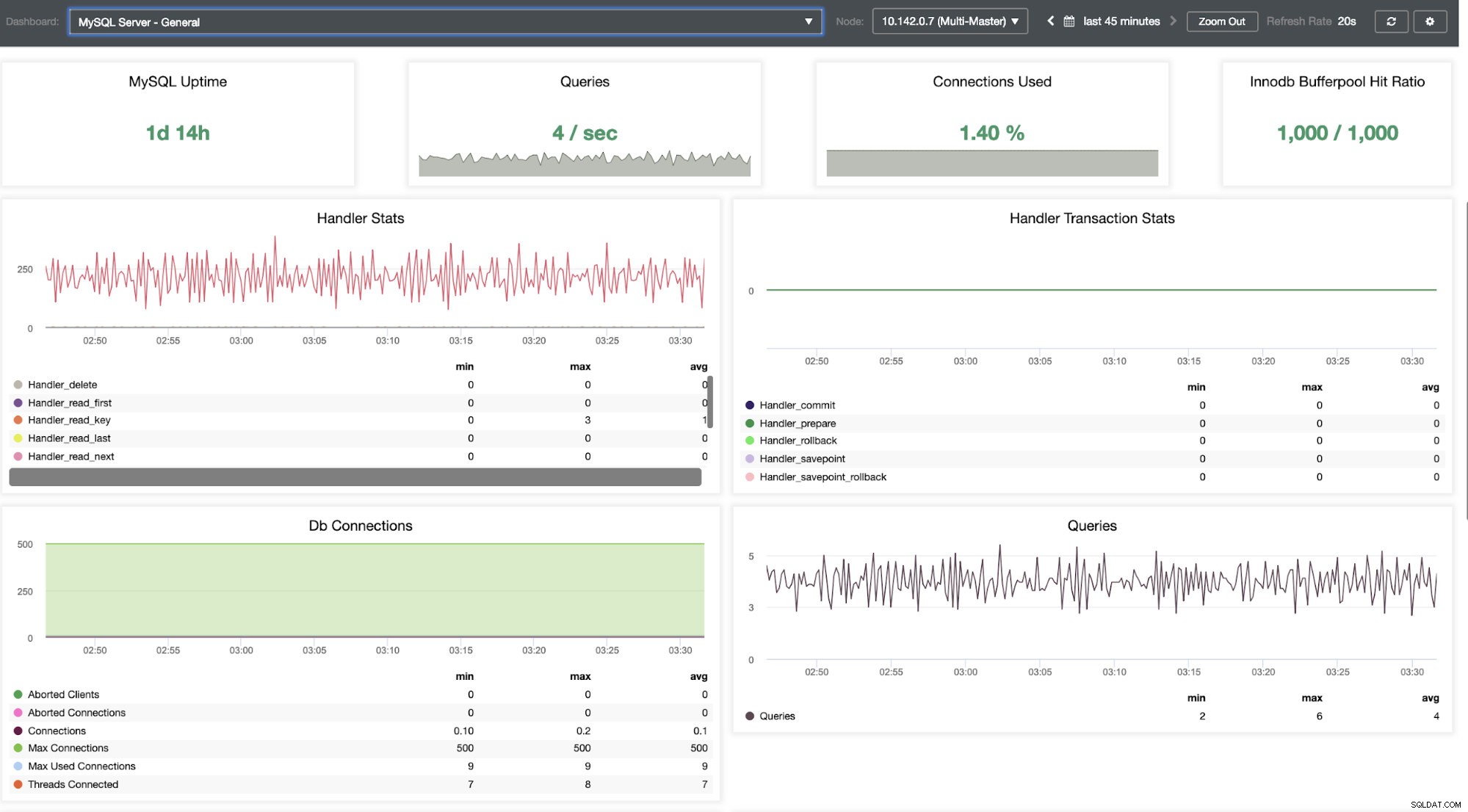
ノードの監視に関して非常にスムーズなエクスペリエンスを提供します。
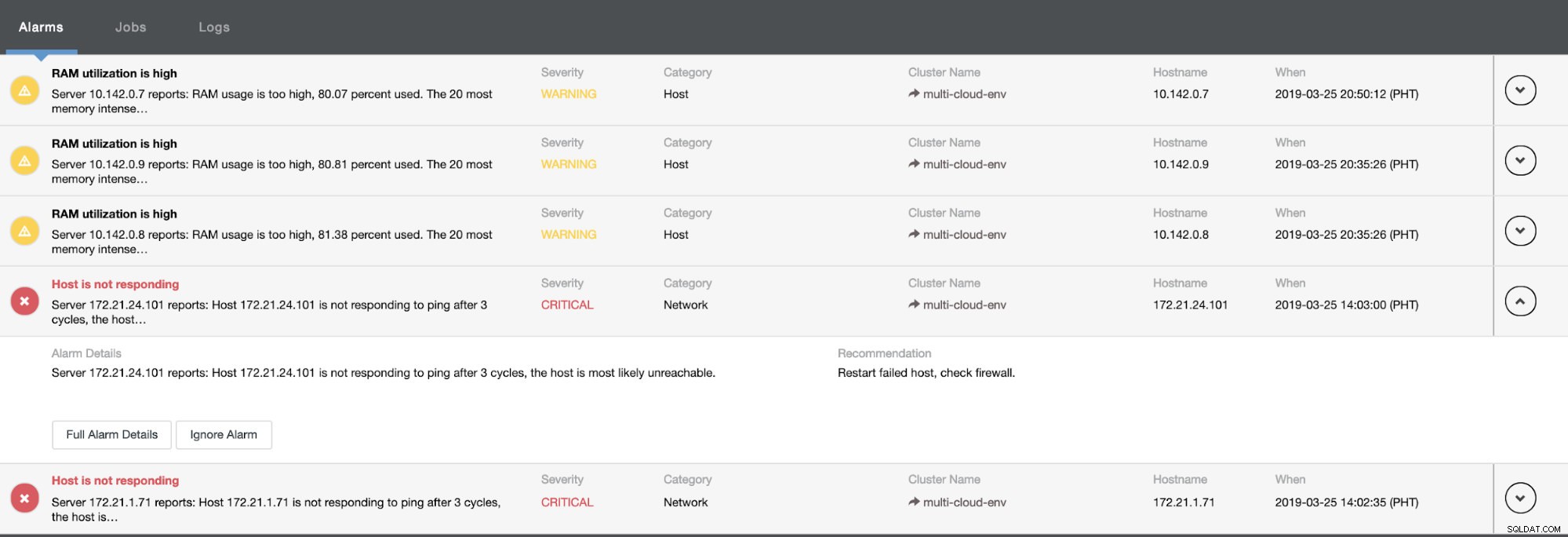
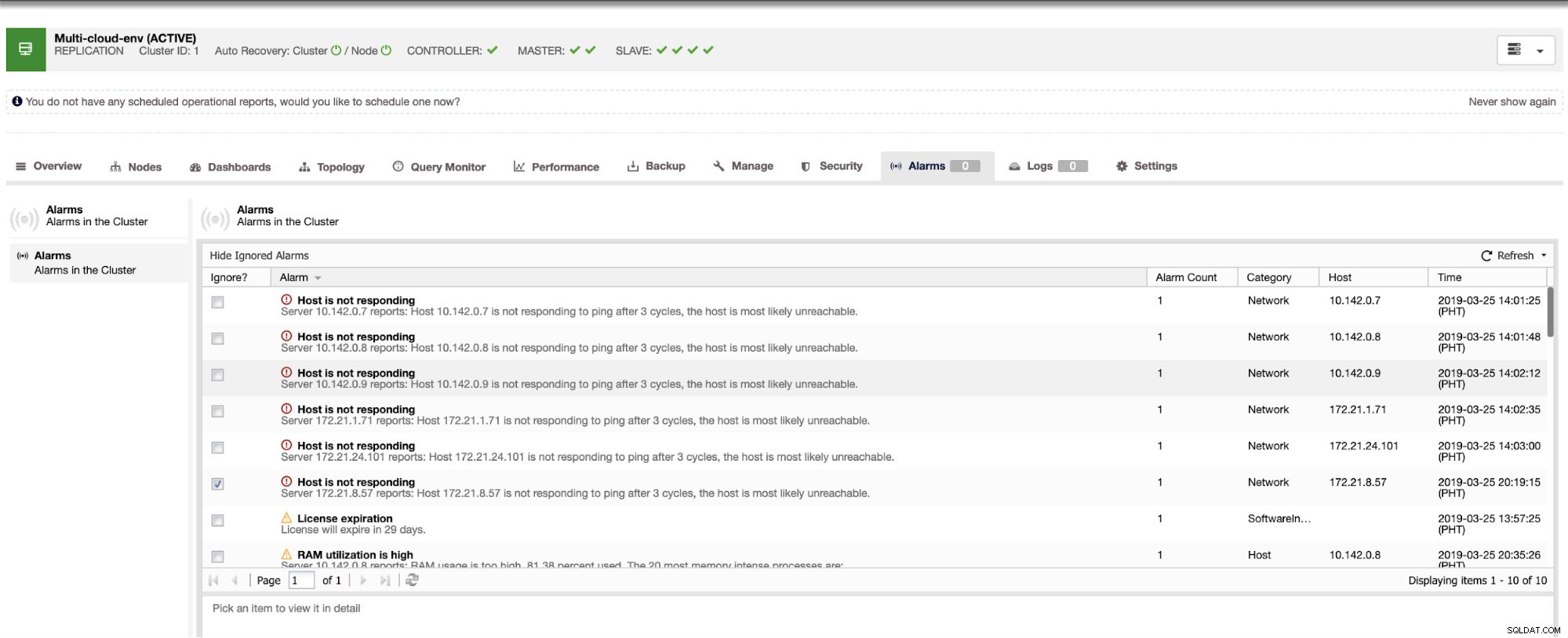
使用率が高いか、ホストが応答していないことを示しています。これは単なるpingでしたが 応答が失敗した場合は、アラートを無視して、攻撃を阻止できます。したがって、必要に応じて、Clustercontrolの[クラスター]-> [アラーム]に移動して、「無視しない」ことができます。以下を参照してください:
障害の管理とフェイルオーバーの実行
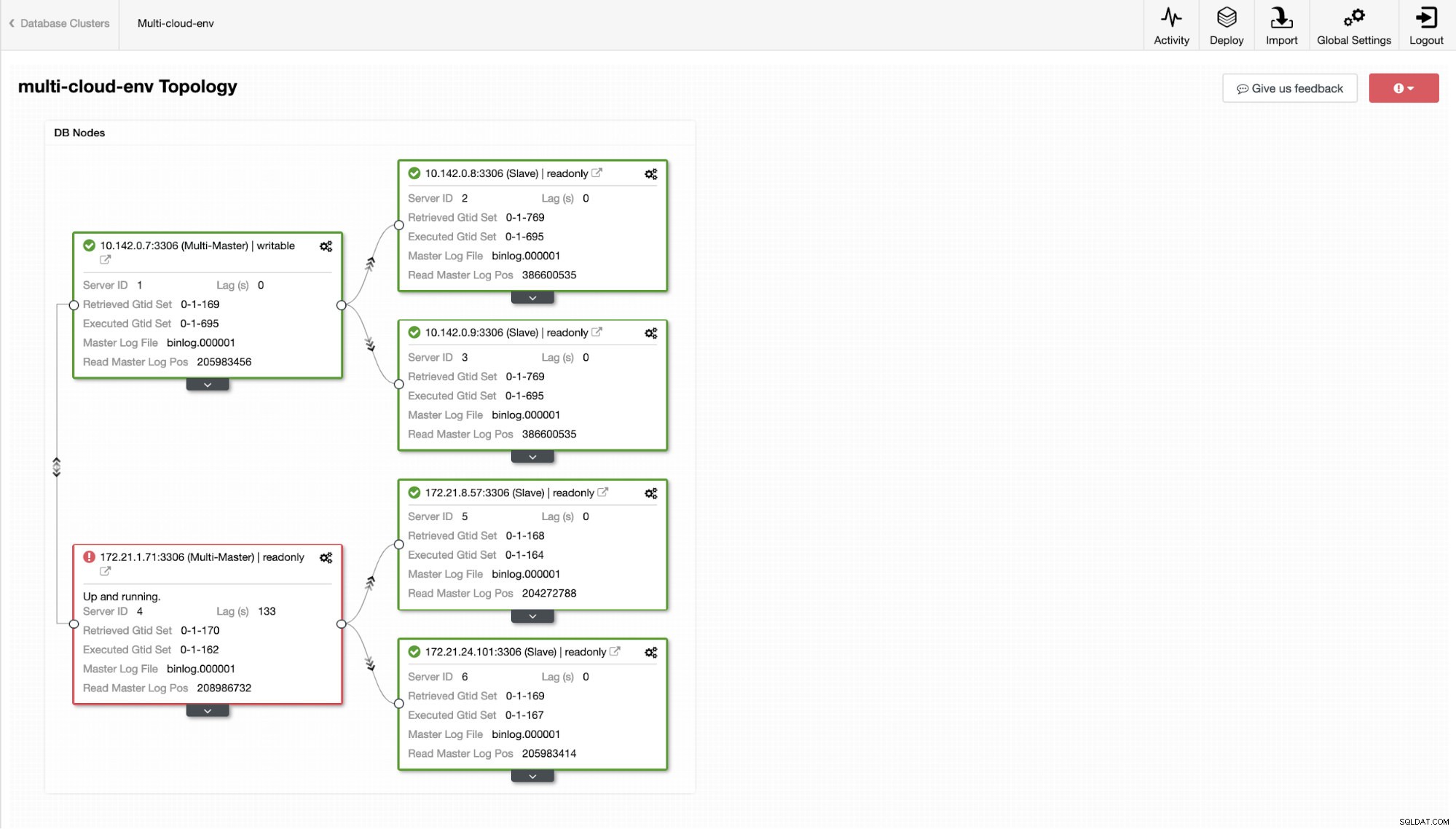
us-east1マスターノードに障害が発生したか、システムまたはハードウェアのアップグレードのために大幅なオーバーホールが必要であるとしましょう。これが現在のトポロジであるとしましょう(下の画像を参照):
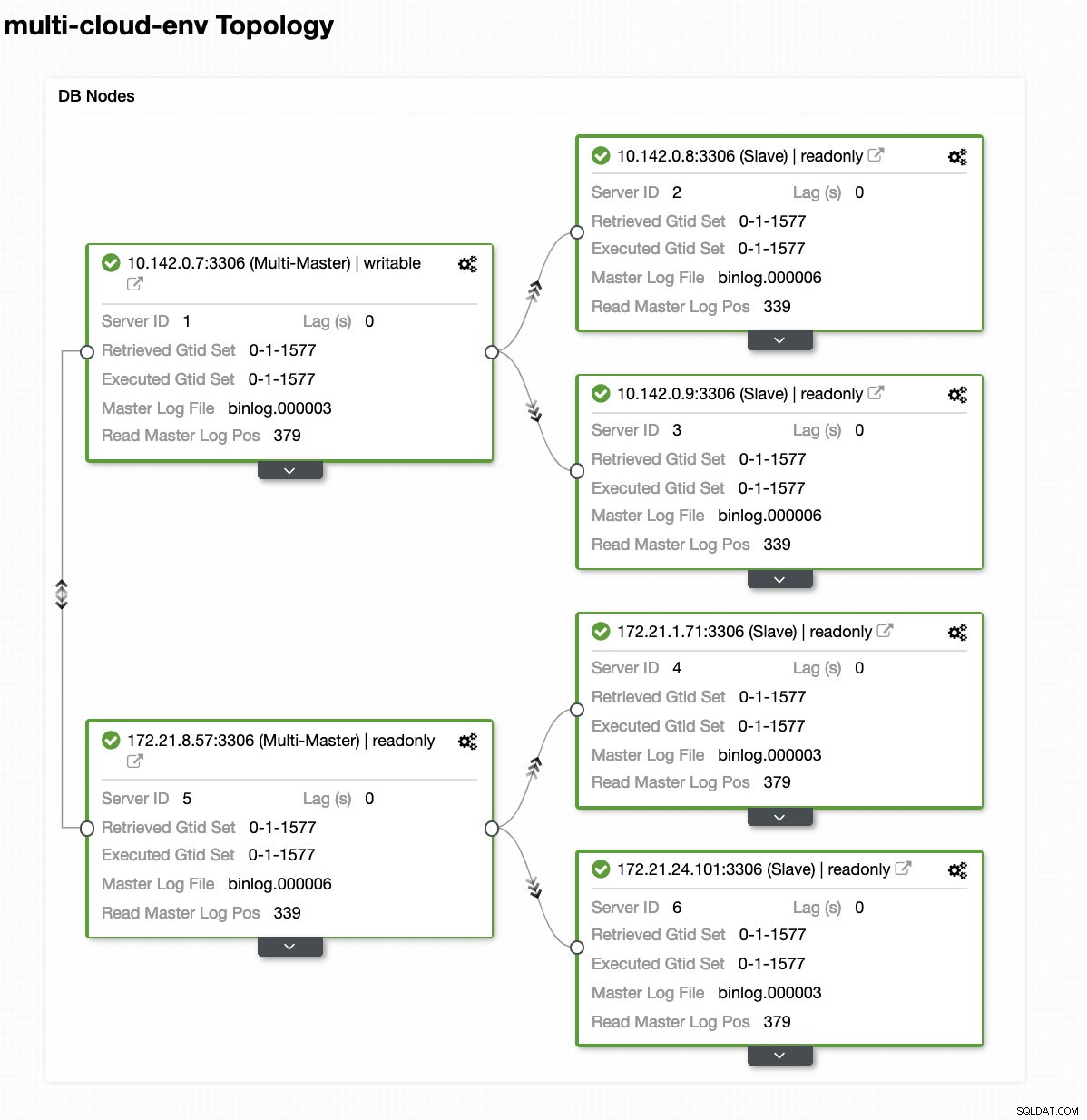
リージョンus-east1のマスターであるホスト10.142.0.7をシャットダウンしてみましょう。 ClusterControlがこれにどのように反応するかを以下のスクリーンショットで確認してください:
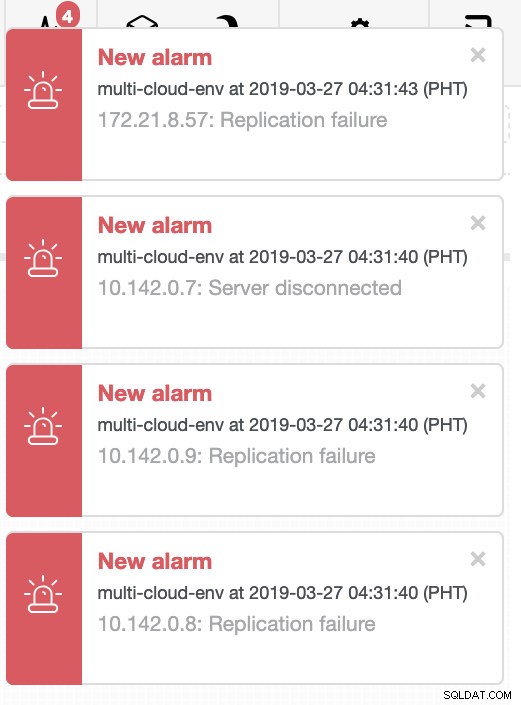
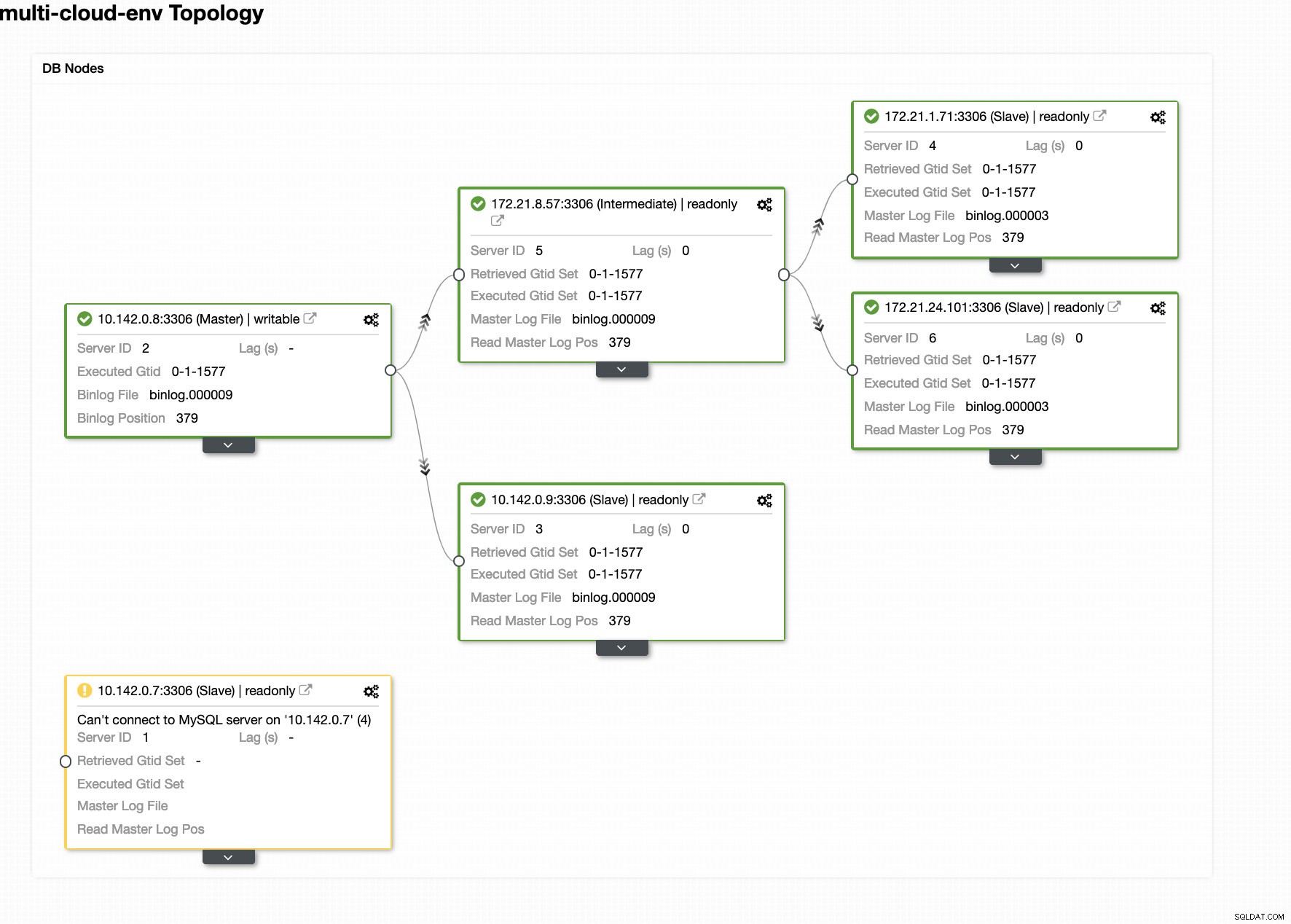
ClusterControlは、クラスター内の異常を検出するとアラームを送信します。次に、適切な候補を選択して、新しいマスターへのフェイルオーバーを試みます(下の画像を参照):

次に、クラスターから既に取り出されている障害のあるマスターを脇に置きます(下の画像を参照):
これは、ClusterControlでできることのほんの一瞥です。バックアップ、クエリモニタリング、ロードバランサーのデプロイ/管理など、他にも多くの優れた機能があります。
結論
マルチクラウドでMySQLレプリケーションの設定を管理するのは難しい場合があります。セットアップを保護するために多くの注意を払う必要があるため、このブログでサブネットを定義してデータベースノードを保護する方法についてのアイデアが得られることを願っています。セキュリティの後で、管理することがいくつかあります。これは、ClusterControlが非常に役立つ場合があります。
今すぐ試して、どうなるか教えてください。こちらからいつでもお問い合わせいただけます。