処理するテキストまたはCSVファイルが非常に大きい場合がありますが、最初にその大きなファイルの小さいファイルを作成する必要があります。その大きなファイルは、処理または開くのに時間がかかりすぎる可能性があるためです。そこで、ストアドプロシージャを使用してPLSQLで大きなテキスト/CSVファイルを複数のファイルに分割する例を以下に示します。
このPLSQLプロシージャに2つのパラメータを渡す必要があります。1つはデータベースディレクトリオブジェクト名で、テキストファイルが存在し、2つ目はソースファイル名(分割するファイル)です。
テキストファイルの場所にOracleディレクトリオブジェクトが存在しない場合は、次のように作成できます。
For windows: CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS 'D:\plsql\text_files';
For Linux/Unix (due to difference in path): CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS '/plsql/text_files';
ファイルの場所に応じて、上記のパスを変更してください。次に、スクリプトを実行して以下の手順を作成します。
CREATE OR REPLACE PROCEDURE split_file (p_db_dir IN VARCHAR2, p_file_name IN VARCHAR2) IS read_file UTL_FILE.file_type; write_file UTL_FILE.file_type; v_string VARCHAR2 (32767); j NUMBER := 1; BEGIN read_file := UTL_FILE.fopen (p_db_dir, p_file_name, 'r'); WHILE j > 0 LOOP write_file := UTL_FILE.fopen (p_db_dir, j || '_' || p_file_name, 'w'); FOR i IN 1 .. 100 LOOP -- example to dividing into 100 rows for each file.. you can increase the number as per your requirement UTL_FILE.get_line (read_file, v_string); UTL_FILE.put_line (write_file, v_string); END LOOP; UTL_FILE.fclose (write_file); j := J + 1; END LOOP; EXCEPTION WHEN OTHERS THEN -- this will handle if reading source file contents finish UTL_FILE.fclose (read_file); UTL_FILE.fclose (write_file); END;
この手順では、ファイルごとに100行を分割します。これは、必要に応じて変更できます。次に、データベースディレクトリオブジェクト名とファイル名を渡して、次のようにこの手順を実行します。
BEGIN
split_file ('CSV_FILE_DIR', 'text_file.csv');
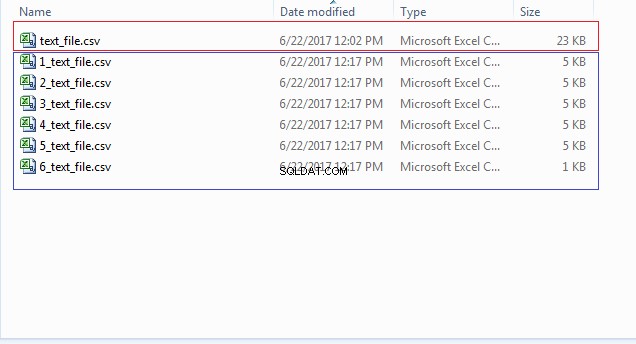
END; 次の画像に示すように、1_text_file.csv、2_text_file.csvなどの番号で始まる複数のファイルのファイルの場所(CSV_FILE_DIR)を確認できます。