2 番目の質問から始めましょう。こちらの方が簡単です。 dplyr の使用 パッケージ、 top_n を使用できます 特定の列の n 個の最大行を取得します。例:
> top_n(p_ash_r_100a, 3, SMPL_CNT) %>% arrange(desc(SMPL_CNT))
# A tibble: 3 × 5
SMPL_TIME SQL_ID MODULE EVENT SMPL_CNT
<dttm> <chr> <chr> <chr> <int>
1 2017-04-11 09:01:00 NO_SQL GoldenGate CPU 7
2 2017-04-11 09:00:00 dgzp3at57cagd GoldenGate db file sequential read 2
3 2017-04-11 09:01:00 37cspa0acgqxp GoldenGate db file sequential read 2
n 位に同点がある場合は、n 行を超えることに注意してください。したがって、top_n(p_ash_r_100, 10, SMPL_CNT) 4 番目の 17 ウェイ タイのため、サンプル データ セット全体が返されます。
最初の質問については、 geom_area のドキュメント 手がかりを提供します:
これは、geom_area が x にマップされる列は数値である必要があります。 p_ash_r_100 のリストに基づく 、 SMPL_TIME は文字ベクトルのようです。 lubridate で パッケージ、SMPL_TIME を変換できます dmy_hm で日時に :
p_ash_r_100a <- p_ash_r_100 %>%
mutate_at(vars(SMPL_TIME), dmy_hm)
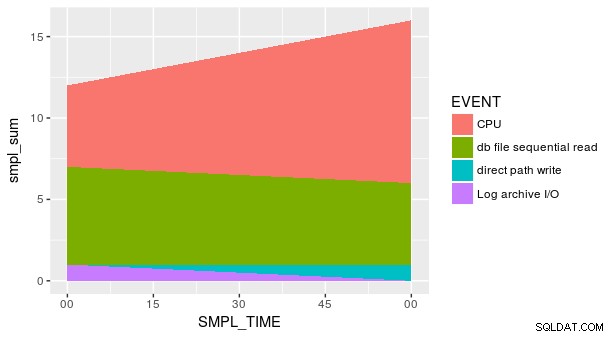
ただし、 y の値が複数あるため、必要なプロットを取得するにはこれだけでは不十分です。 x の組み合わせごとに と fill (これは geom_area の正しい美学です 、「col」ではありません "). プロットする前にデータを要約する必要があります:
p_ash_r_100a %>%
group_by(SMPL_TIME, EVENT) %>%
summarise(total = sum(SMPL_CNT)) %>%
ggplot(aes(SMPL_TIME, total, fill = EVENT)) +
geom_area()
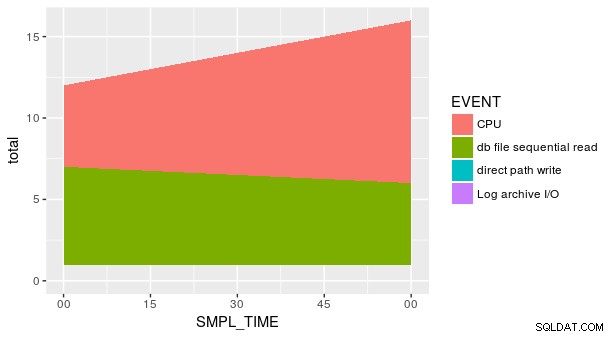
しかし、プロットはまだ正しくありません。これは SMPL_TIME のすべての組み合わせのためです と EVENT はデータセットに表示されません。 geom_area を明示的に伝える必要があります その y 行が欠落している場合、 はゼロに等しくなります。 1 つの方法は、便利な fill を使用することです。 tidyr::spread の引数 .
group_by(p_ash_r_100a, SMPL_TIME, EVENT) %>%
summarise(smpl_sum = sum(SMPL_CNT)) %>%
spread(EVENT, smpl_sum, fill = 0) %>%
gather(EVENT, smpl_sum, CPU, `db file sequential read`,
`direct path write`,
`Log archive I/O`) %>%
ggplot(aes(x = SMPL_TIME, y = smpl_sum, fill = EVENT)) +
geom_area()