開発者としての私の最大の喜びの1つは、さまざまなテクノロジーがどのように交差するかを学ぶことです。
何年にもわたって、私はさまざまな種類のソフトウェアやツールを扱う機会がありました。私が使用した多くのツールの中で、PythonとStructured Query Language(SQL)は私のお気に入りの2つです。
この記事では、PythonとさまざまなSQLデータベースがどのように相互作用するかを紹介します。
最も人気のあるデータベース、SQLite、MySQL、およびPostgreSQLについて説明します。各データベースの主な違いと対応するユースケースについて説明します。そして、Pythonコードで記事を終了します。
このコードは、PostgreSQLデータベースからデータをプルしてパンダのデータフレームにデータを保存するSQLクエリを作成する方法を示しています。
リレーショナルデータベース(RDBMS)に慣れていない場合は、RDBMSの基本的な用語に関するSameerの記事をここで確認することをお勧めします。記事の残りの部分では、Sameerの記事で参照されている用語を使用します。
SQLite
SQLiteは統合データベースとして最もよく知られています。これは、データベースを実行するために追加のアプリケーションをインストールしたり、別のサーバーを使用したりする必要がないことを意味します。
MVPを作成している場合、または大量のデータストレージスペースが必要ない場合は、SQLiteデータベースを使用することをお勧めします。
長所は、MySQLやPostgreSQLに比べてSQLiteデータベースを使用するとより速く移動できることです。とはいえ、機能が制限されたままになります。機能をカスタマイズしたり、大量のマルチユーザー機能を追加したりすることはできません。
MySQL / PostgreSQL
MySQLとPostgreSQLには明確な違いがあります。とは言うものの、記事の文脈を考えると、それらは同様のカテゴリーに当てはまります。
どちらのデータベースタイプも、エンタープライズソリューションに最適です。高速にスケーリングする必要がある場合は、MySQLとPostgreSQLが最善の策です。それらは長期的なインフラストラクチャを提供し、セキュリティを強化します。
彼らが企業にとって素晴らしいもう一つの理由は、彼らが高性能の活動を扱うことができるということです。挿入、更新、および選択ステートメントが長くなると、多くの計算能力が必要になります。 SQLiteデータベースが提供するよりも短いレイテンシでこれらのステートメントを書くことができます。
PythonとSQLデータベースを接続する理由
「なぜPythonとSQLデータベースの接続を気にする必要があるのか」と疑問に思われるかもしれません。
誰かがPythonをSQLデータベースに接続したい場合の多くのユースケースがあります。先に述べたように、あなたはWebアプリケーションで作業しているかもしれません。この場合、Webアプリケーションからのデータを保存できるように、SQLデータベースに接続する必要があります。
おそらく、データエンジニアリングで働いていて、自動化されたETLパイプラインを構築する必要があります。 PythonをSQLデータベースに接続すると、Pythonを自動化機能に使用できるようになります。また、異なるデータソース間で通信することもできます。異なるプログラミング言語を切り替える必要はありません。
PythonとSQLデータベースを接続すると、データサイエンスの作業もより便利になります。 Pythonのスキルを使用して、SQLデータベースのデータを操作できるようになります。 CSVファイルは必要ありません。
PythonデータベースとSQLデータベースの接続方法

PythonデータベースとSQLデータベースは、カスタムPythonライブラリを介して接続します。これらのライブラリをPythonスクリプトにインポートできます。
データベース固有のPythonライブラリは、補足的な手順として機能します。これらの手順は、SQLデータベースとの対話方法についてコンピューターをガイドします。そうしないと、Pythonコードは接続しようとしているデータベースの外国語になります。
PostgreSQLデータベース、AWSRedshiftを例にとってみましょう。まず、psycopgライブラリをインポートする必要があります。これは、PostgreSQLデータベース用のユニバーサルPythonライブラリです。
#Library for connecting to AWS Redshift
import psycopg
#Library for reading the config file, which is in JSON
import json
#Data manipulation library
import pandas as pdJSONライブラリとpandasライブラリもインポートしたことに気付くでしょう。 JSON構成ファイルを作成することは、データベースの資格情報を安全に保存する方法であるため、JSONをインポートしました。他の誰かがそれらに目を向けてほしくない!
pandasライブラリを使用すると、Pythonスクリプトでpandasのすべての統計機能を使用できます。この場合、ライブラリにより、PythonはSQLクエリが返すデータをデータフレームに保存できるようになります。
次に、構成ファイルにアクセスします。 json.load() 関数はJSONファイルを読み取るため、次のステップでデータベースのクレデンシャルにアクセスできます。
config_file = open(r"C:\Users\yourname\config.json")
config = json.load(config_file)
PythonスクリプトがJSON構成ファイルにアクセスできるようになったので、データベース接続を作成する必要があります。構成ファイルから資格情報を読み取って使用する必要があります:
con = psycopg2.connect(dbname= "db_name", host=config[hostname], port = config["port"],user=config["user_id"], password=config["password_key"])
cur = con.cursor()データベース接続を作成しました。 psycopgライブラリをインポートすると、上記で記述したPythonコードをPostgreSQLデータベース(AWS Redshift)と通信するように変換しました。
それ自体では、AWSRedshiftは上記のコードを理解しません。ただし、psycopgライブラリをインポートしたため、AWSRedshiftが理解できる言語を話すようになりました。
Pythonの良いところは、SQLite、MySQL、およびPostgreSQL用のライブラリがあることです。テクノロジーを簡単に統合できるようになります。
SQLクエリの記述方法
EuropeanSoccerDataをPostgreSQLデータベースに自由にダウンロードしてください。この例では、そのデータを使用します。
前の手順で作成したデータベース接続を使用すると、SQLを記述して、Pythonに適したデータ構造にデータを格納できます。データベース接続が確立されたので、SQLクエリを記述してデータのプルを開始できます。
query = "SELECT *
FROM League
JOIN Country ON Country.id = League.country_id;"ただし、作業はまだ完了していません。 SQLクエリを実行する追加のPythonコードを作成する必要があります:
#Runs your SQL query
execute1 = cur.execute(query)
result = cur.fetchall()次に、返されたデータをパンダのデータフレームに保存する必要があります。
#Create initial dataframe from SQL data
raw_initial_df = pd.read_sql_query(query, con)
print(raw_initial_df)次のようなパンダデータフレーム(raw_initial_df)を取得する必要があります:
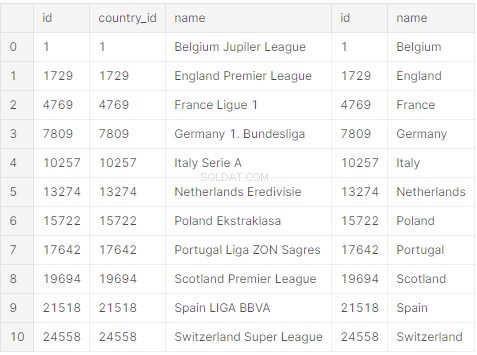

SQLite、MySQL、およびPostgreSQLにはすべて長所と短所があります。どちらを選択するかは、プロジェクトまたは会社のニーズによって異なります。また、数年先と比べて、現在必要なものを検討する必要があります。
覚えておくべき重要なことは、Pythonは各データベースタイプと統合できるということです。
この記事では、PythonをSQLデータベースに接続することで何が可能になるかについて説明します。ソフトウェアが交差し、組み合わされて信じられないほどの価値を付加する方法を見るのが大好きです。
このタイプのコンテンツをもっと知りたい場合は、Course to Hireで私を見つけることができます!より多くの人々がコーディングの方法を学び、テクノロジーに就職できるように支援したいと思います。ご不明な点がある場合や、こんにちはと言いたい場合は、お問い合わせください:)