
今月のT-SQL火曜日はMikeDonnelly(@SQLMD)によってホストされており、彼はトピックを次のように要約しています。
今月のトピックは単純明快ですが、非常にオープンエンドです。あなたは何か新しいことを学び、それを説明するブログ投稿を書かなければなりません。さて、マイクがトピックを発表した瞬間から、私は本当に新しいことを学ぶために着手しませんでした、そして週末が近づき、月曜日が陪審員の義務で私を襲うことを知っていたので、私はこれに座らなければならないと思いました月曜日。
それから、マーティン・スミスは私が知らなかった、またはずっと前に知っていたが忘れてしまったことを教えてくれました(時々あなたはあなたが知らないことを知らない、そして時々あなたはあなたが知らなかったこととあなたができないことを思い出せない覚えて)。私の記憶は、列をNOT NULLから変更したことでした。 NULLへ すべき NULLが原因で、他の理由でそのページが更新されるまでページへの書き込みが延期される、メタデータのみの操作である 少なくとも1つの行がNULLになるまで、ビットマップは実際には存在する必要はありません。 。
その同じ投稿で、@ ypercubeは、Books Onlineからのこの適切な引用(タイプミスおよびすべて)を思い出させました:
変更された列が非クラスター化インデックスによる参照である場合、列をNOT NULLからNULLに変更することは、オンライン操作としてサポートされていません。「オンライン操作ではない」は、「メタデータのみの操作ではない」と解釈できます。つまり、実際にはデータサイズの操作になります(インデックスが大きいほど、時間がかかります)。
NOT NULLから変換する特定のターゲット列に対して、非常に単純な(ただし長い)実験でこれを証明することに着手しました。 NULLへ 。 3つのテーブルを作成します。すべてクラスター化された主キーを使用しますが、それぞれが異なる非クラスター化インデックスを使用します。 1つはターゲット列をキー列として、もう1つはINCLUDEとして使用します。 列であり、3番目はターゲット列をまったく参照しません。
これが私のテーブルとそれらにどのようにデータを入力したかです:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
各テーブルには100,000行、クラスター化インデックスには310ページ、非クラスター化インデックスには272ページ(test1)がありました。 およびtest2 )または174ページ(test3 )。 (これらの値は、sys.dm_db_index_physical_statsから簡単に取得できます。 。)
次に、ページレベルでログに記録された操作をキャプチャする簡単な方法が必要でした。sys.fn_dblog()を選択しました。 、もっと深く掘り下げてページを直接見ることもできたでしょうが。 LSN値を操作して関数に渡す必要はありませんでした。これは、本番環境で実行しておらず、パフォーマンスをあまり気にかけていなかったためです。テスト後、関数の結果をダンプしました。 ALTER TABLEの前にログに記録されました 操作。
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
これで、セットアップよりもはるかに簡単なテストを実行できました。
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
これで、それぞれの場合にログに記録された操作を調べることができました:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; 結果は、ターゲット列がインデックスに言及されている場合は非クラスター化インデックスのすべてのリーフページがタッチされていることを示しているようですが、ターゲット列がインデックスに言及されていない場合はそのような操作は発生しません。非クラスター化インデックス:
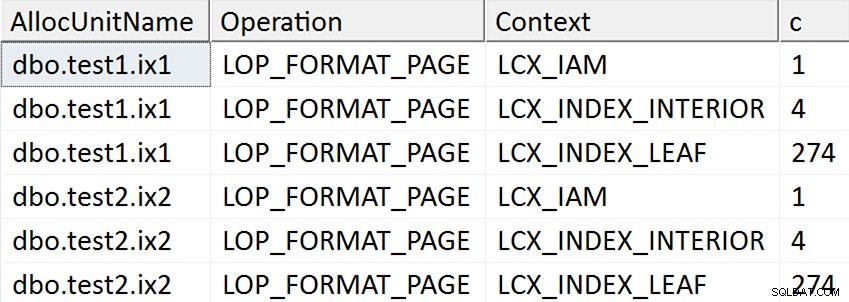
実際、最初の2つのケースでは、新しいページが割り当てられます(DBCC INDで検証できます 、Spörriが彼の回答で行ったように)、操作はオンラインで実行できますが、それが高速であることを意味するわけではありません(それでもすべてのデータのコピーを書き出して、NULLを作成する必要があるため) 新しい各ページの書き込みの一部としてビットマップが変更され、そのすべてのアクティビティがログに記録されます)。
ほとんどの人は、列をNOT NULLから変更することを疑うと思います NULLへ すべてのシナリオでメタデータのみになりますが、列が非クラスター化インデックスによって参照されている場合はこれが当てはまらないことをここに示しました(キーであるかINCLUDEであるかにかかわらず同様のことが起こります 桁)。おそらく、この操作を強制的にONLINEにすることもできます。 今日のAzureSQLデータベースで、または次のメジャーバージョンで可能になりますか?これにより、必ずしも実際の物理的な操作が速くなるとは限りませんが、結果としてブロックが防止されます。
私はそのシナリオをテストしませんでした(そして、それが本当にオンラインであるかどうかの分析はとにかくAzureでより困難です)、またヒープでテストしませんでした。将来の投稿で再訪できること。それまでの間、メタデータのみの操作について行う可能性のある仮定には注意してください。