はじめに
Galera Clusterを実行する場合、同じデータセンターまたは異なるデータセンターに1つ以上の非同期スレーブを追加するのが一般的な方法です。これにより、RTOが低く、運用コストが低い緊急時対応計画が提供されます。クラスタで回復不能な問題が発生した場合は、すぐにフェールオーバーして、アプリケーションが引き続きデータにアクセスできるようにすることができます。
このタイプのセットアップを使用する場合、以前のバックアップからクラスターを再構築することはできません。非同期スレーブが新しい真実の情報源になっているため、そこからクラスターを再構築する必要があります。
これは、私たちがそれを行う方法が1つしかないことを意味するのではなく、もっと良い方法があるかもしれません。この投稿の最後にあるコメントセクションで、お気軽にご提案ください。
トポロジ
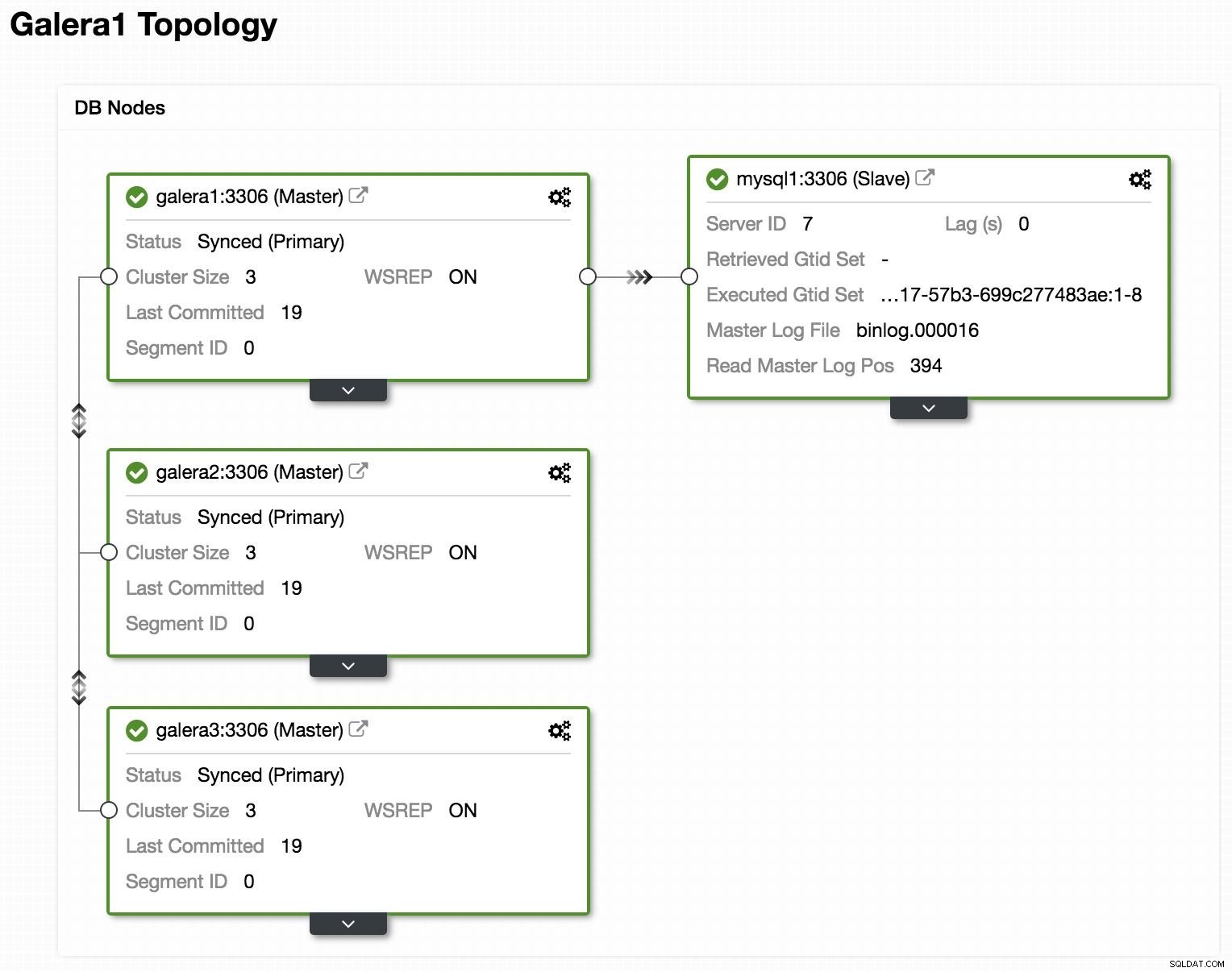 ClusterControlトポロジオンラインで表示
ClusterControlトポロジオンラインで表示 上記は、GaleraClusterと非同期レプリカ/スレーブを使用したトポロジの例です。
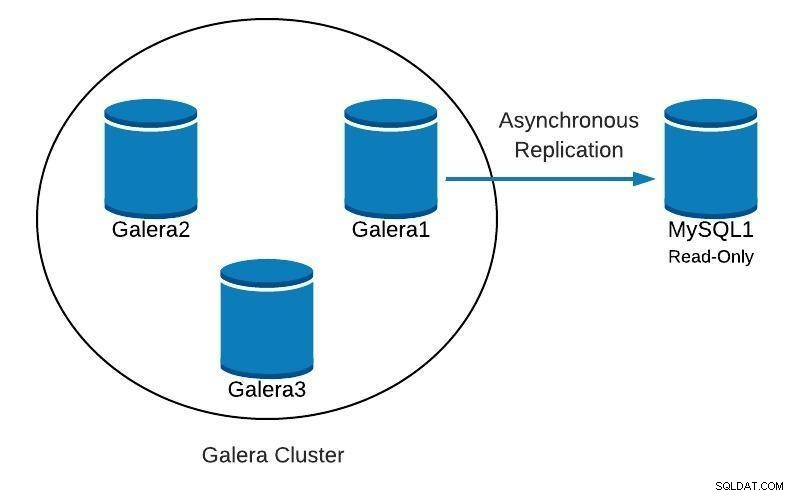 データベース図1
データベース図1 次に、次のようなものを見つけた場合に、スレーブから開始してクラスターを再作成する方法を確認します。
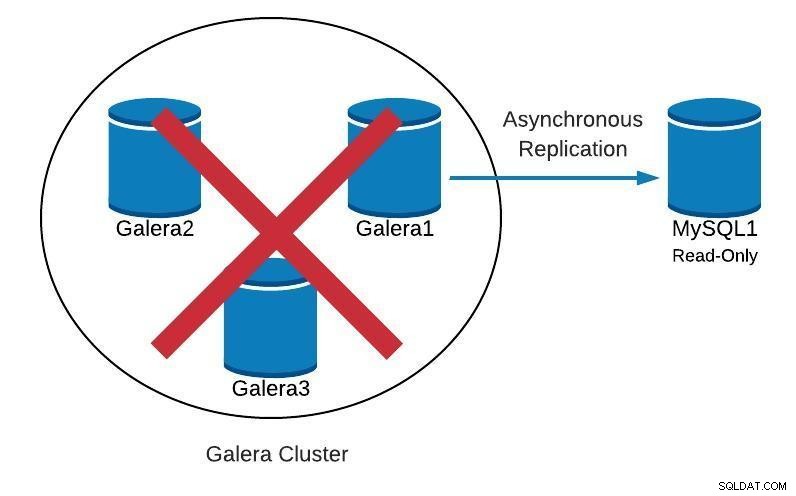 データベース図2
データベース図2 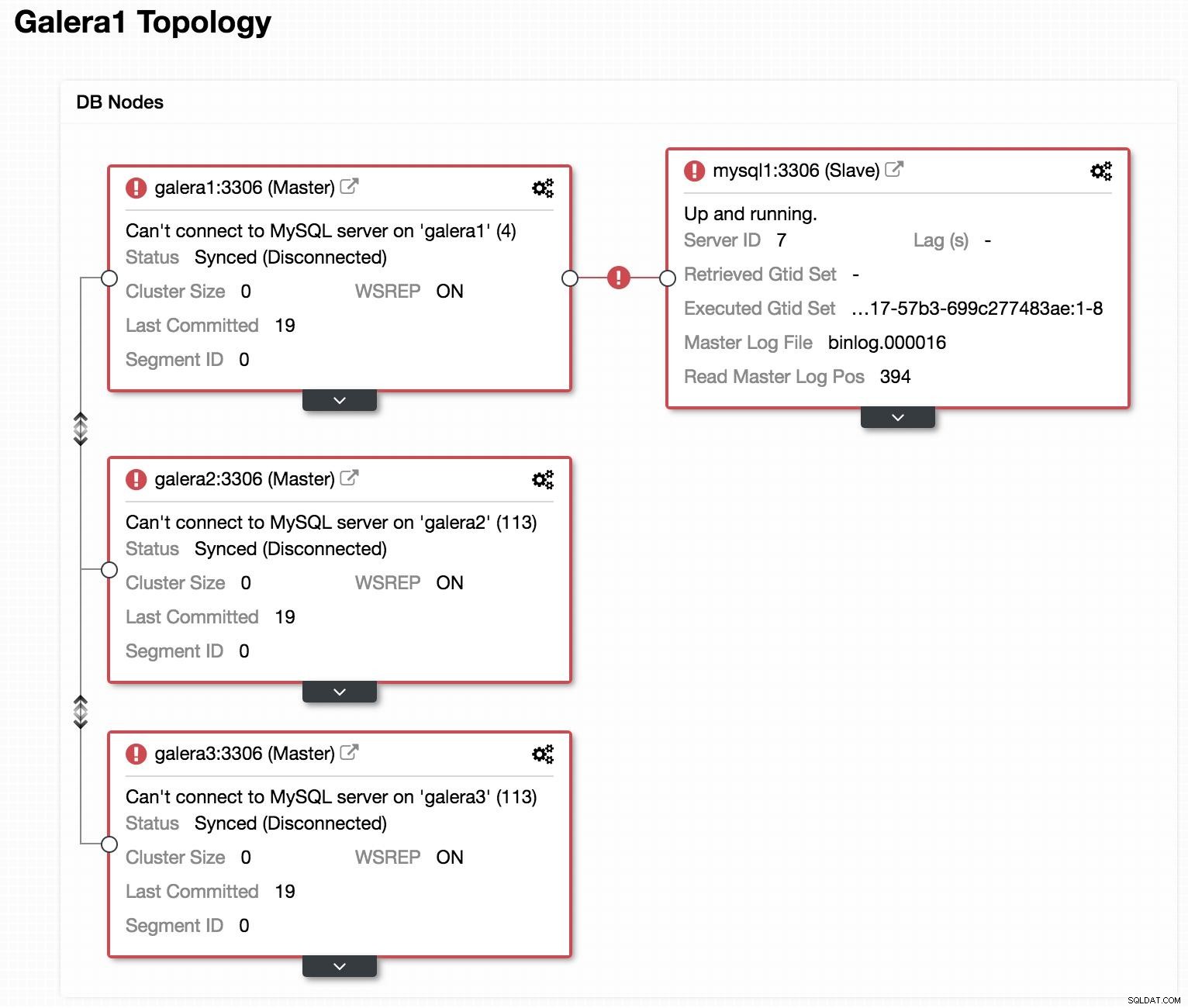 ClusterControlトポロジビューオフライン
ClusterControlトポロジビューオフライン 前の画像を見ると、3つのGaleraノードがダウンしていることがわかります。スレーブはGaleraマスターに接続できませんが、「稼働中」の状態です。
スレーブの昇格
スレーブが適切に機能しているので、スレーブをマスターしてアプリケーションをポイントするように昇格させることができます。このためには、スレーブの読み取り専用パラメータを無効にして、スレーブ構成をリセットする必要があります。
スレーブ(mysql1)の場合:
mysql> SET GLOBAL read_only=0;
Query OK, 0 rows affected (0.00 sec)
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.00 sec)
mysql> RESET SLAVE;
Query OK, 0 rows affected (0.18 sec)新しいクラスターを作成する
次に、失敗したクラスターの回復を開始するために、新しいガレラクラスターを作成します。これは、ClusterControl ClusterControlを介して簡単に実行できます。このブログをさらに下にスクロールして、方法を確認してください。
新しいGaleraクラスターをデプロイすると、次のようになります。
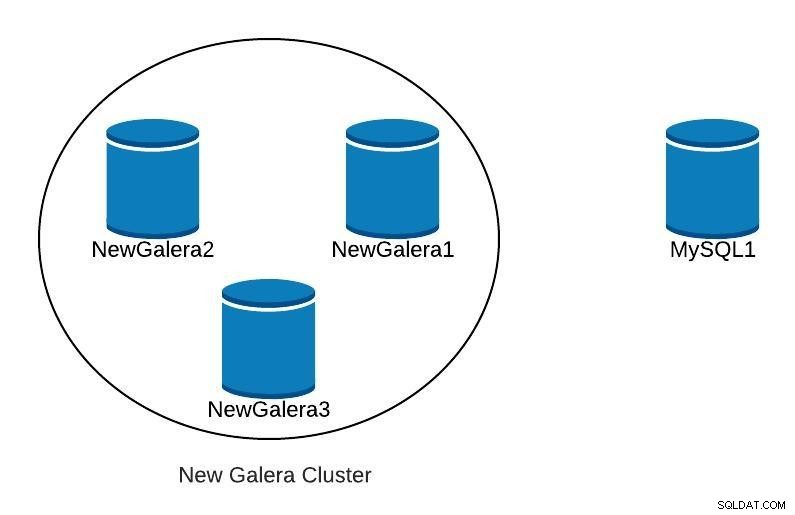 データベース図3
データベース図3 複製
レプリケーションパラメータが設定されていることを確認する必要があります。
Galeraノード(galera1、galera2、galera3)の場合:
server_id=<ID> # Different value in each node
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-bin
expire_logs_days = 7マスターノード(mysql1)の場合:
server_id=<ID> # Different value in each node
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
gtid_mode=ON
enforce_gtid_consistency=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON
sync_binlog=1
report_host=<HOSTNAME or IP> # Local server新しいスレーブ(galera1)が新しいマスター(mysql1)に接続するには、マスターに複製権限を持つユーザーを作成する必要があります。
新しいマスター(mysql1)の場合:
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%' IDENTIFIED BY 'slave_password';注:「%」は、スレーブとなるGalera ClusterノードのIP(この例ではgalera1)に置き換えることができます。
バックアップ
持っていない場合は、マスター(mysql1)の一貫したバックアップを作成し、新しいGaleraクラスターにロードする必要があります。このために、XtraBackupツールまたはmysqldumpを使用できます。両方のオプションを見てみましょう。
この例では、テストに使用できるsakilaデータベースを使用しています。
XtraBackupツール
新しいマスター(mysql1)でバックアップを生成します。この場合、ローカルディレクトリ/ root / backupに送信します:
$ innobackupex /root/backup/メッセージを受け取る必要があります:
180705 22:08:14 completed OK!バックアップを圧縮して、スレーブとなるノード(galera1)に送信します:
$ cd /root/backup
$ tar zcvf 2018-07-05_22-08-07.tar.gz 2018-07-05_22-08-07
$ scp /root/backup/2018-07-05_22-08-07.tar.gz galera1:/root/backup/galera1で、バックアップを抽出します:
$ tar zxvf /root/backup/2018-07-05_22-08-07.tar.gzクラスターを停止します(開始されている場合)。このために、3つのノードのmysqlサービスを停止します:
$ service mysql stopgalera1では、mysqlのデータディレクトリの名前を変更し、バックアップをロードします。
$ mv /var/lib/mysql /var/lib/mysql.bak
$ innobackupex --copy-back /root/backup/2018-07-05_22-08-07メッセージを受け取る必要があります:
180705 23:00:01 completed OK!データディレクトリに正しい権限を割り当てます:
$ chown -R mysql.mysql /var/lib/mysql次に、クラスターを初期化する必要があります。
最初のノードが初期化されたら、残りのノードに対してMySQLサービスを開始し、ファイルgrastate.datの以前のコピーを削除してから、データが更新されていることを確認する必要があります。
$ rm /var/lib/mysql/grastate.dat
$ service mysql start注:XtraBackupで使用されるユーザーが、初期化されたノードで作成され、各ノードで同じであることを確認してください。
mysqldump
一般に、mysqldumpを使用して実行することはお勧めしません。これは、大量のデータを使用すると非常に遅くなる可能性があるためです。ただし、これはタスクを実行するための代替手段です。
新しいマスター(mysql1)でバックアップを生成します:
$ mysqldump -uroot -p --single-transaction --skip-add-locks --triggers --routines --events --databases sakila > /root/backup/sakila_dump.sql圧縮してスレーブノード(galera1)に送信します:
$ gzip /root/backup/sakila_dump.sql
$ scp /root/backup/sakila_dump.sql.gz galera1:/root/backup/ダンプをgalera1にロードします。
$ gunzip /root/backup/sakila_dump.sql.gz
$ mysql -p < /root/backup/sakila_dump.sqlダンプがgalera1にロードされたら、残りのノードでMySQLサービスを再起動し、ファイルgrastate.datを削除して、データが更新されていることを確認する必要があります。
$ rm /var/lib/mysql/grastate.dat
$ service mysql startレプリケーションスレーブの開始
XtraBackupとmysqldumpのどちらのオプションを選択しても、すべてがうまくいけば、このステップで、スレーブとなるノード(galera1)でレプリケーションをオンにすることができます。
$ mysql> CHANGE MASTER TO MASTER_HOST = 'mysql1', MASTER_PORT = 3306, MASTER_USER = 'slave_user', MASTER_PASSWORD = 'slave_password', MASTER_AUTO_POSITION = 1;
$ mysql> START SLAVE;スレーブが機能していることを確認します:
mysql> SHOW SLAVE STATUS\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yesこの時点で、次のようなものがあります。
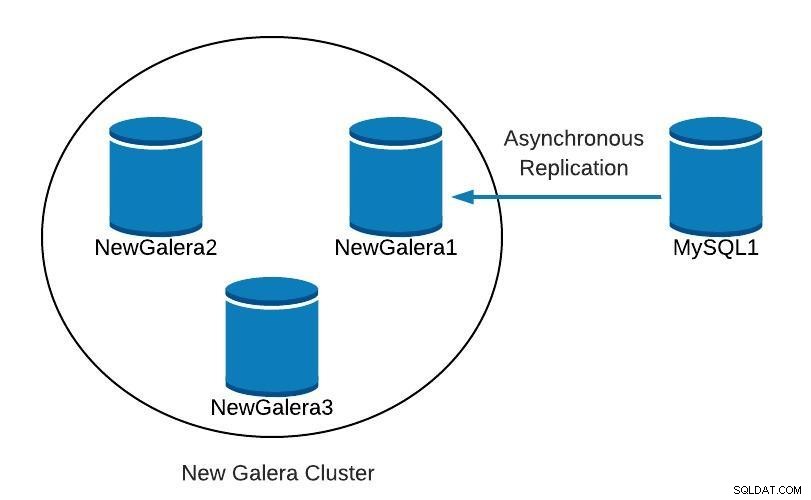 データベース図4
データベース図4 NewGalera1が最新の状態になったら、アプリケーションを新しいガレラクラスターに再ポイントし、非同期レプリケーションを再構成できます。
ClusterControl
前述したように、ClusterControlを使用すると、数回クリックするだけで上記のタスクのいくつかを実行できます。また、ノードとクラスターの両方に対して、自動回復オプションがあります。それが支援できるいくつかのタスクを見てみましょう。
 ClusterControl Deployment 1
ClusterControl Deployment 1 展開を実行するには、[データベースクラスターの展開]オプションを選択し、表示される指示に従います。
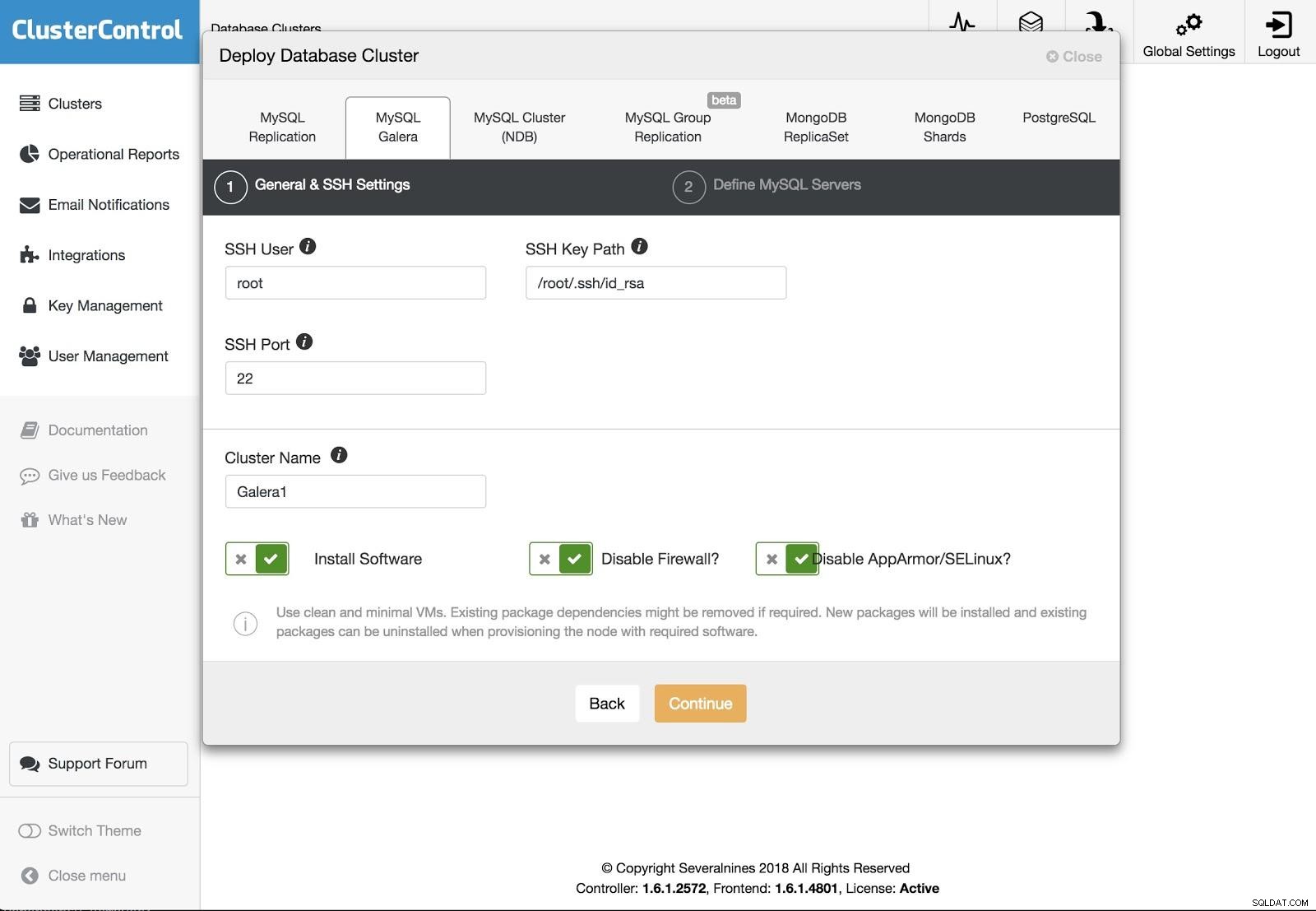 ClusterControl Deployment 2
ClusterControl Deployment 2 さまざまな種類のテクノロジーとベンダーから選択できます。 SSHでサーバーに接続するには、ユーザー、キー、またはパスワードとポートを指定する必要があります。また、新しいクラスターの名前と、ClusterControlに対応するソフトウェアと構成をインストールさせる場合も必要です。
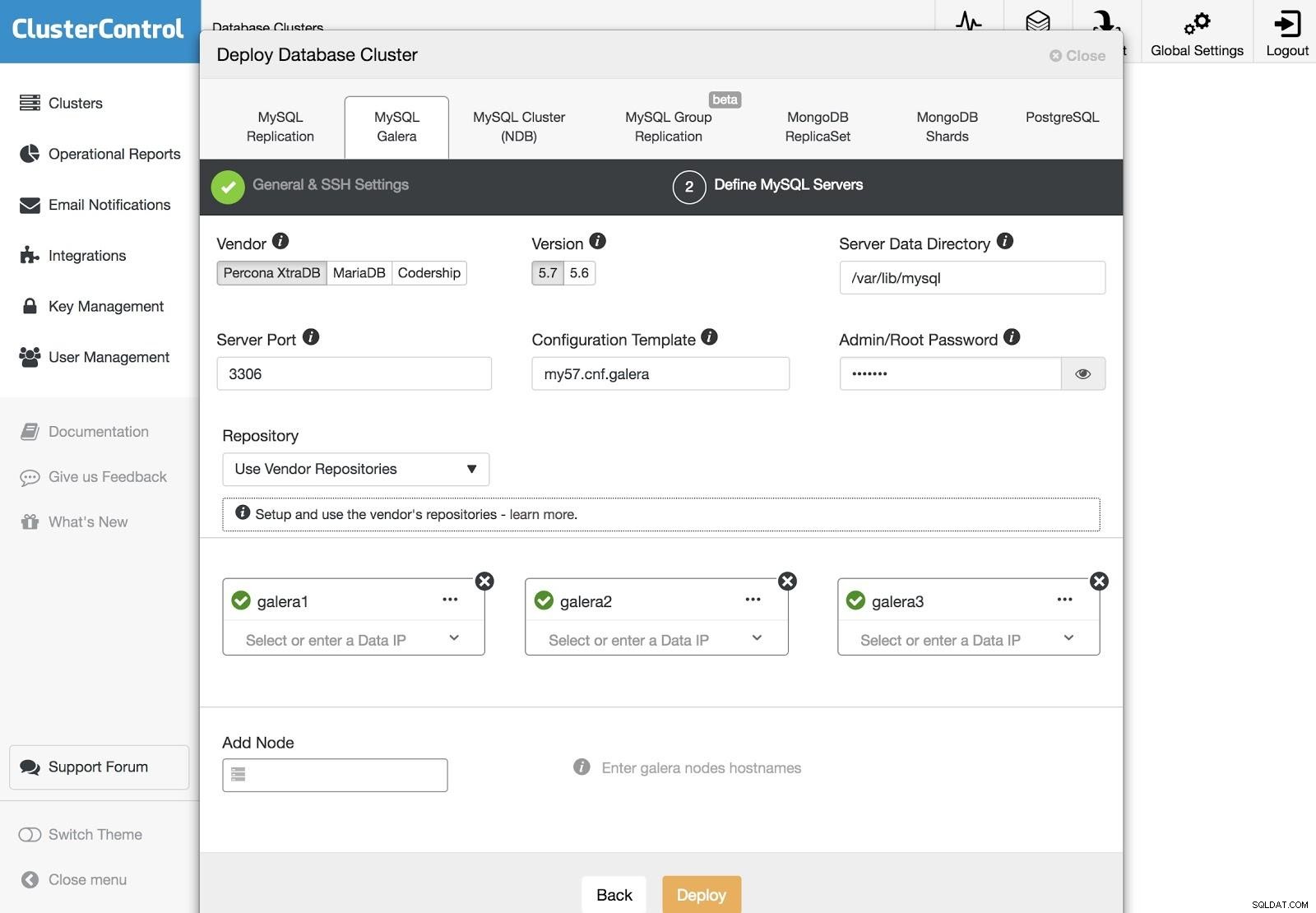 ClusterControl Deployment 3
ClusterControl Deployment 3 SSHアクセス情報を設定した後、クラスター内のノードを定義する必要があります。使用するリポジトリを指定することもできます。作成するクラスターにサーバーを追加する必要があります。
ClusterControlアクティビティモニターから新しいクラスターの作成ステータスを監視できます。
また、同じ手順に従って、現在のクラスターまたはデータベースのインポートを実行できます。この場合、すでにデータベースが実行されているため、ClusterControlはデータベースソフトウェアをインストールしません。
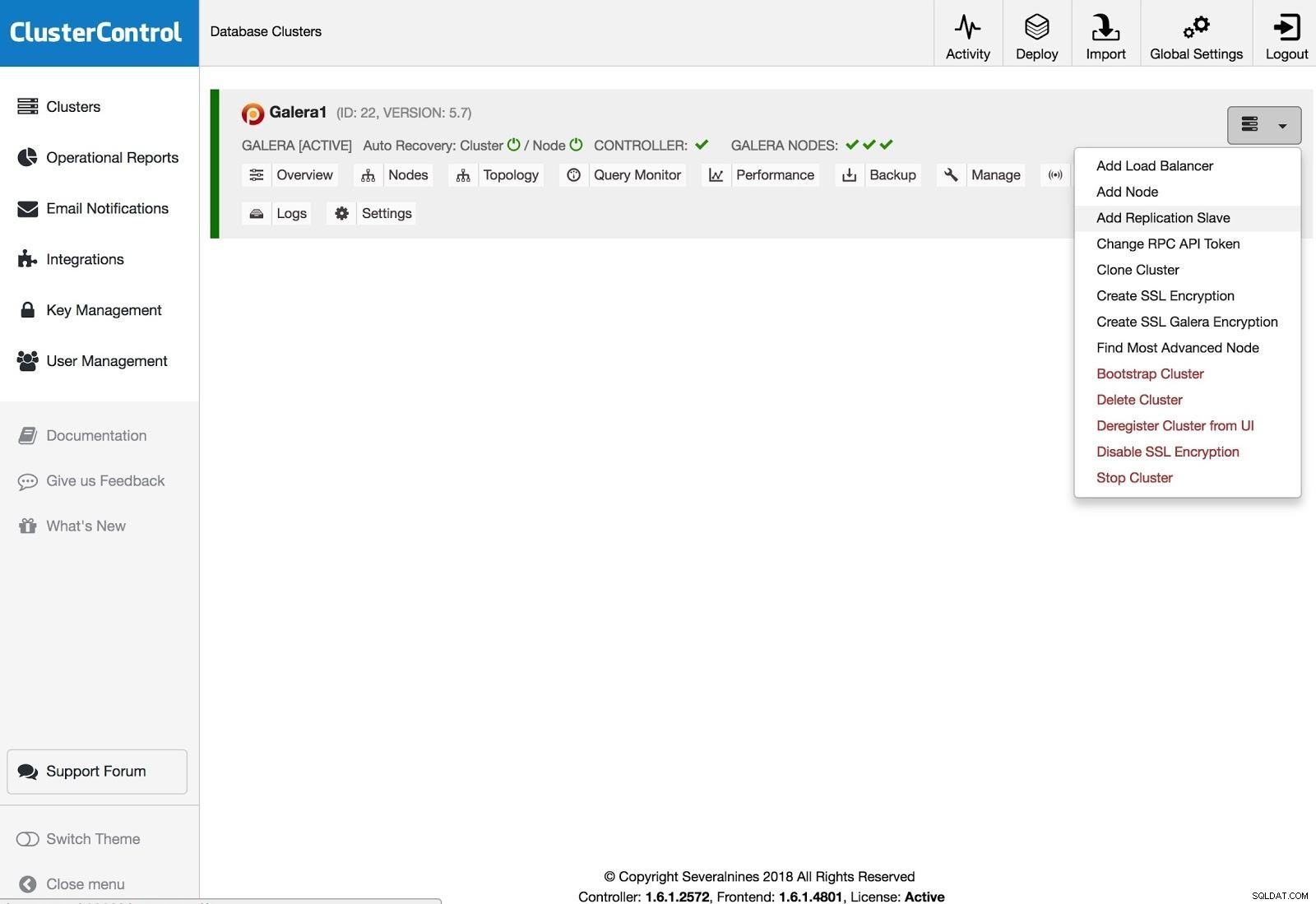 ClusterControl Add Replication Salve
ClusterControl Add Replication Salve レプリケーションスレーブを追加するには、[クラスターアクション]をクリックし、[レプリケーションスレーブの追加]を選択して、新しいサーバーのSSHアクセス情報を追加する必要があります。 ClusterControlはサーバーに接続して、このアクションに必要な構成を行います。
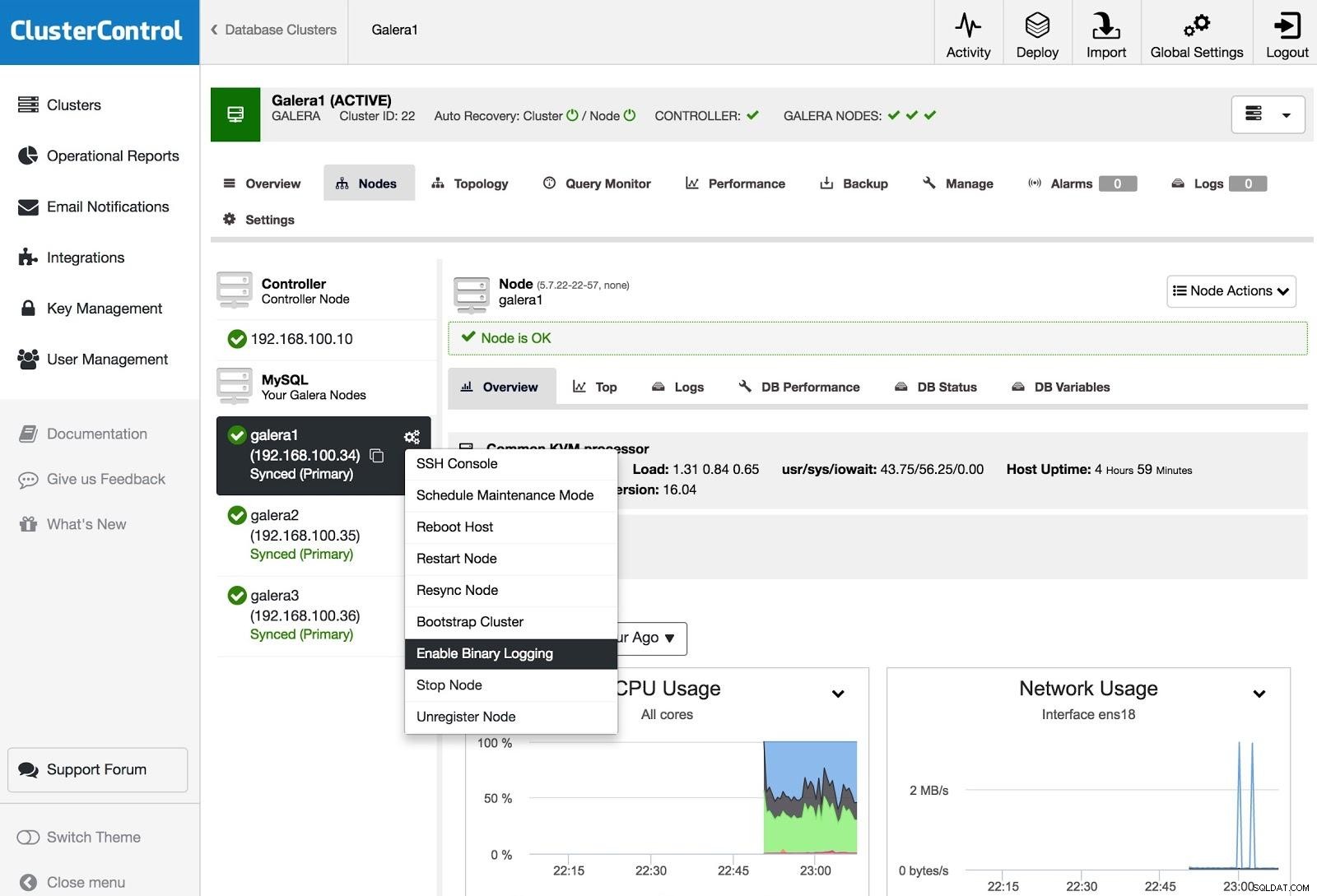 ClusterControlバイナリロギングを有効にする
ClusterControlバイナリロギングを有効にする 1つ以上のGaleraノードを(binlogを生成するという意味で)マスターサーバーに変換するには、[ノードアクション]に移動して[バイナリログを有効にする]を選択します。
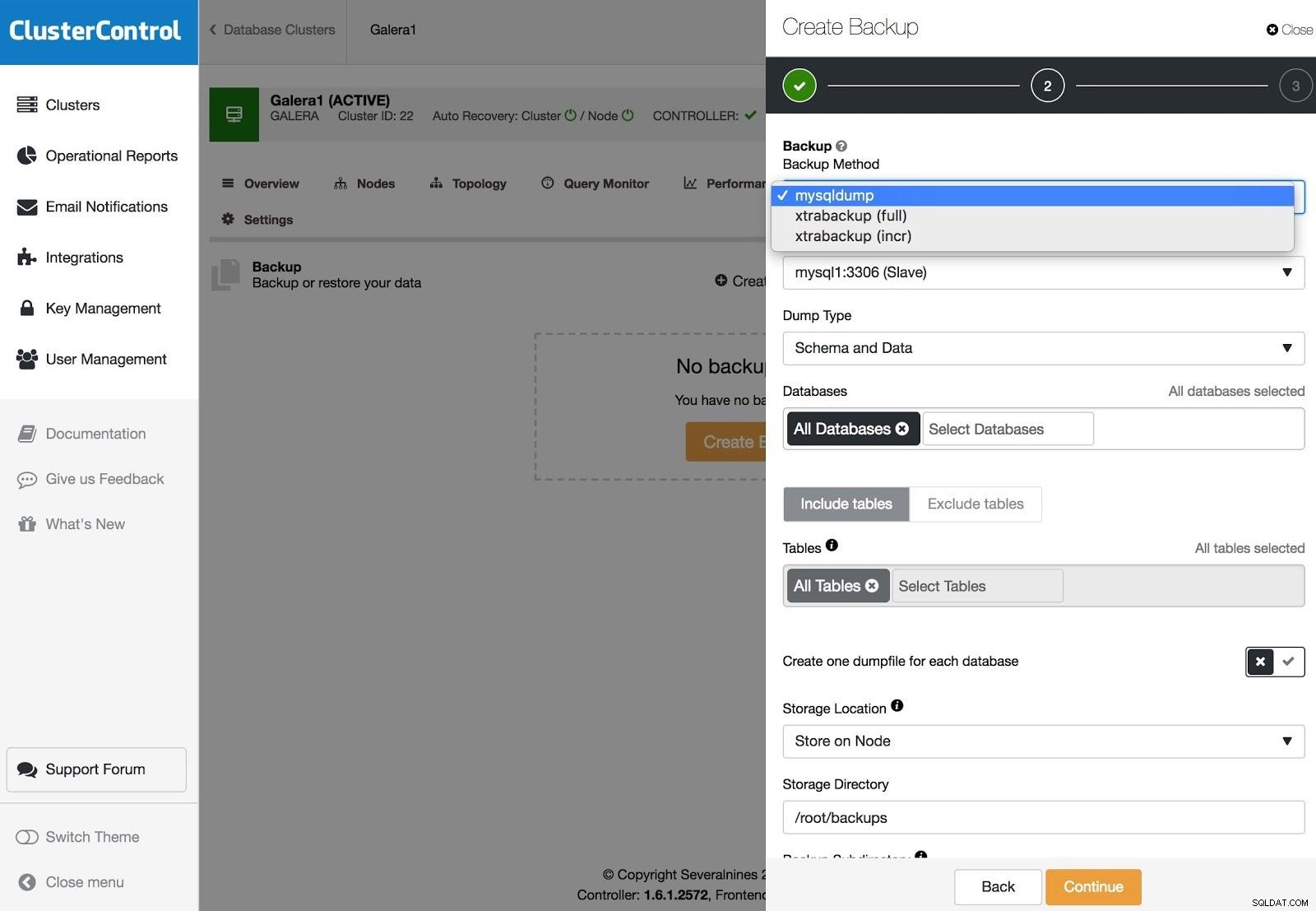 ClusterControlバックアップ
ClusterControlバックアップ バックアップはXtraBackup(フルまたはインクリメンタル)とmysqldumpで構成でき、バックアップをクラウドにアップロードする、暗号化、圧縮、スケジュールなどの他のオプションがあります。
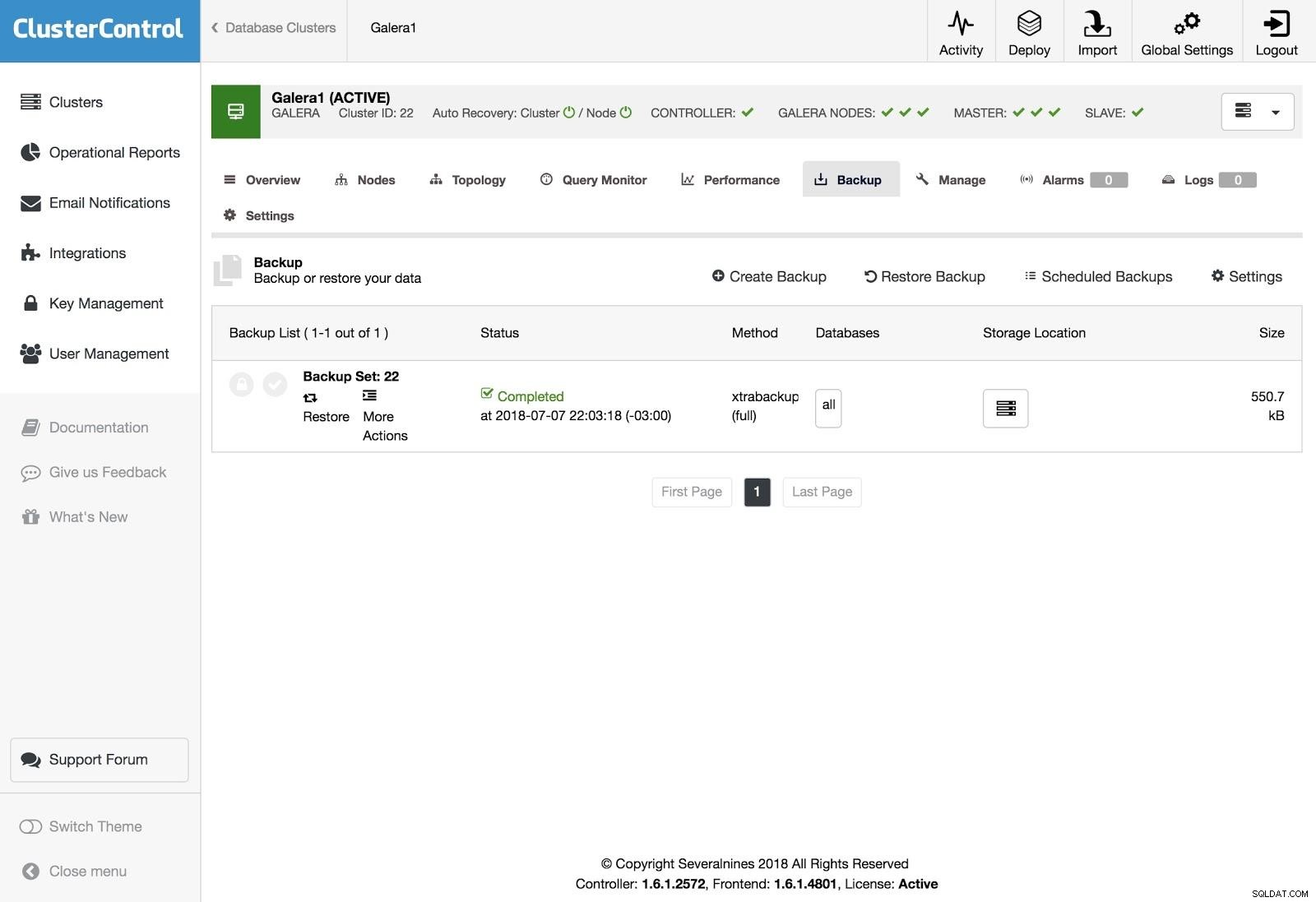 ClusterControl Restore
ClusterControl Restore バックアップを復元するには、[バックアップ]タブに移動し、[復元]オプションを選択してから、復元するサーバーを選択します。
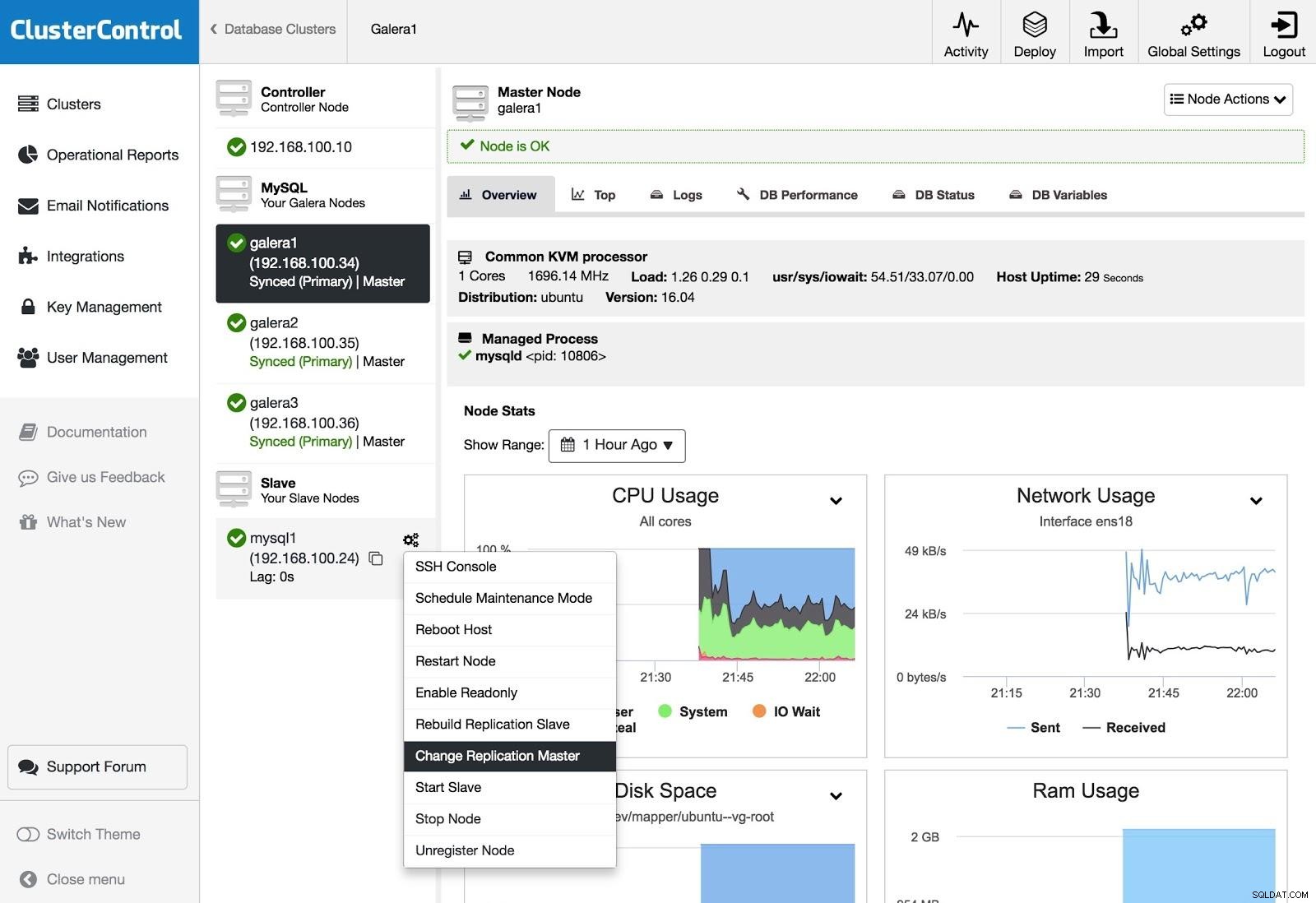 ClusterControlレプリケーションマスターの変更
ClusterControlレプリケーションマスターの変更 スレーブがあり、マスターを変更したり、レプリケーションを再構築したりする場合は、ノードアクションに移動してオプションを選択できます。
結論
ご覧のとおり、目標を達成する方法はいくつかあります。より複雑な方法もあれば、よりユーザーフレンドリーな方法もありますが、いずれの方法でも、非同期スレーブからクラスターを再作成できます。 Xtrabackupは、データ量が多いほど高速に復元します。オペレーターのエラー(たとえば、誤ったDROP TABLE)を防ぐために、遅延スレーブを使用して、ステートメントの伝播を停止する時間を確保することもできます。
この情報がお役に立てば幸いです。また、本番環境で使用する必要がないことを願っています;)