ロードバランサーは、高可用性データベースセットアップの重要なコンポーネントです。これらは、1台のサーバーが過負荷になるのを防ぐことにより、重要なシステムとアプリケーションの容量と信頼性を高めるために使用されます。なぜそれらが必要なのか、どのように機能するのかなど、Severeninesブログでそれらについて多くのことを話します。 MySQLとMariaDBで利用できる最も人気のあるロードバランサーの1つは、HAProxyです。
機能的には、HAProxyはProxySQLやMaxScaleとは比較できません。ただし、HAProxyは高速で堅牢なロードバランサーであり、アプリケーションが読み取り/書き込み分割を実行し、SELECTクエリを1つのバックエンドに送信し、すべての書き込みとSELECT ... FOR UPDATEを別のバックエンドに送信できる限り、どの環境でも完全に機能します。バックエンド。
HAProxyによって利用可能になったすべてのメトリックを追跡することは非常に重要です。プロキシの状態を知ることができなければなりません。特に、問題が発生したかどうかを知る必要があります。
ClusterControlは、プロキシの状態をリアルタイムで表示するHAProxyステータスページを常に利用できるようにしています。現在、新しいPrometheusベースのSCUMM(Severalnines ClusterControl Unified Monitoring&Management)ダッシュボードを使用すると、これらのメトリックが時間の経過とともにどのように変化するかを簡単に追跡できます。
このブログ投稿では、HAProxySCUMMダッシュボードに表示されるさまざまなメトリックについて説明します。
ClusterControlでのHAProxyダッシュボードの探索
すべてのPrometheusおよびSCUMMダッシュボードは、ClusterControlではデフォルトで無効になっています。ただし、特定のクラスターにそれらをデプロイするには、ワンクリックで済みます。 ClusterControlを使用して複数のクラスターを監視する場合は、クラスターごとに同じPrometheusインスタンスを再利用できます。
デプロイしたら、HAProxyダッシュボードにアクセスできます。ダッシュボードで利用可能なデータを見てみましょう:
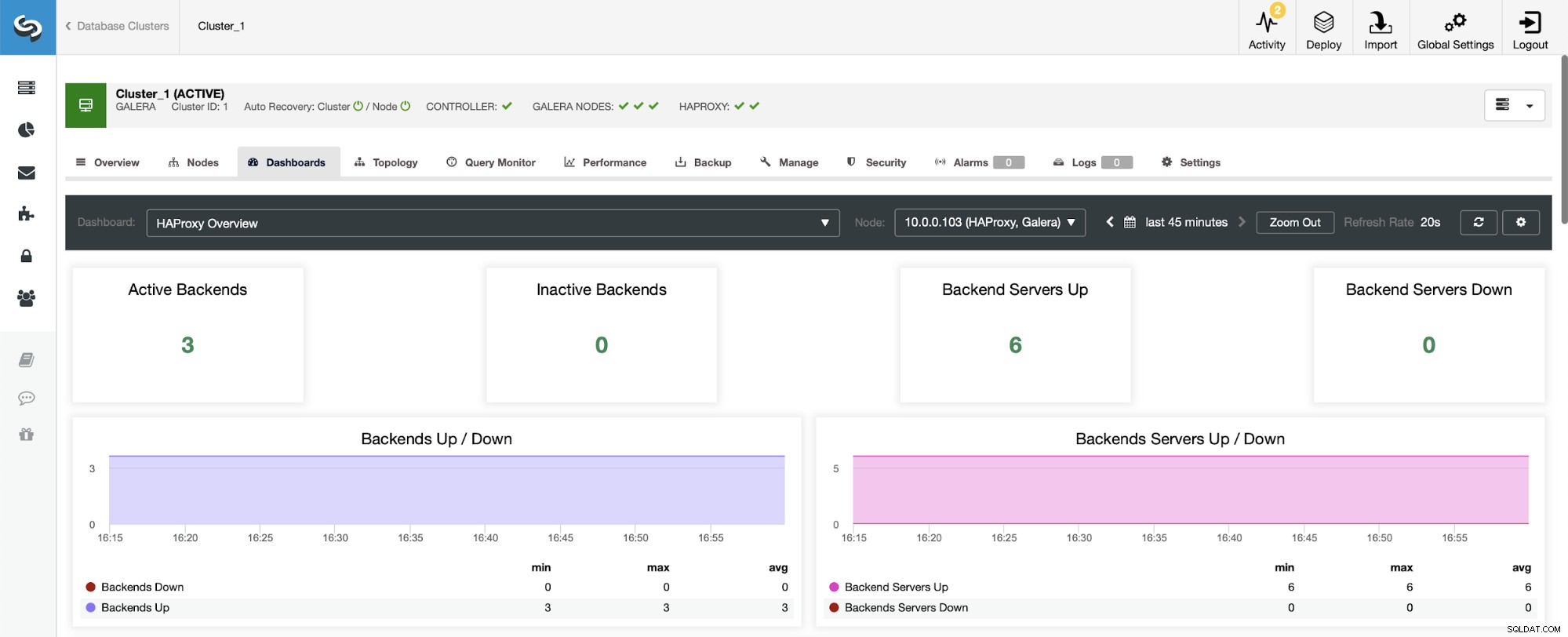
HAProxyダッシュボードに移動したときに最初に表示されるのはバックエンドの状態に関する情報。ここで表示される内容は、クラスタタイプとHAProxyのデプロイ方法によって異なる場合があることに注意してください。この場合、Galeraクラスターをデプロイし、HAProxyはラウンドロビン方式でデプロイされました。したがって、読み取り用に3つのバックエンド、書き込み用に3つ(合計6つ)のバックエンドが表示されます。これが、すべてのバックエンドが「アップ」とマークされている理由でもあります。
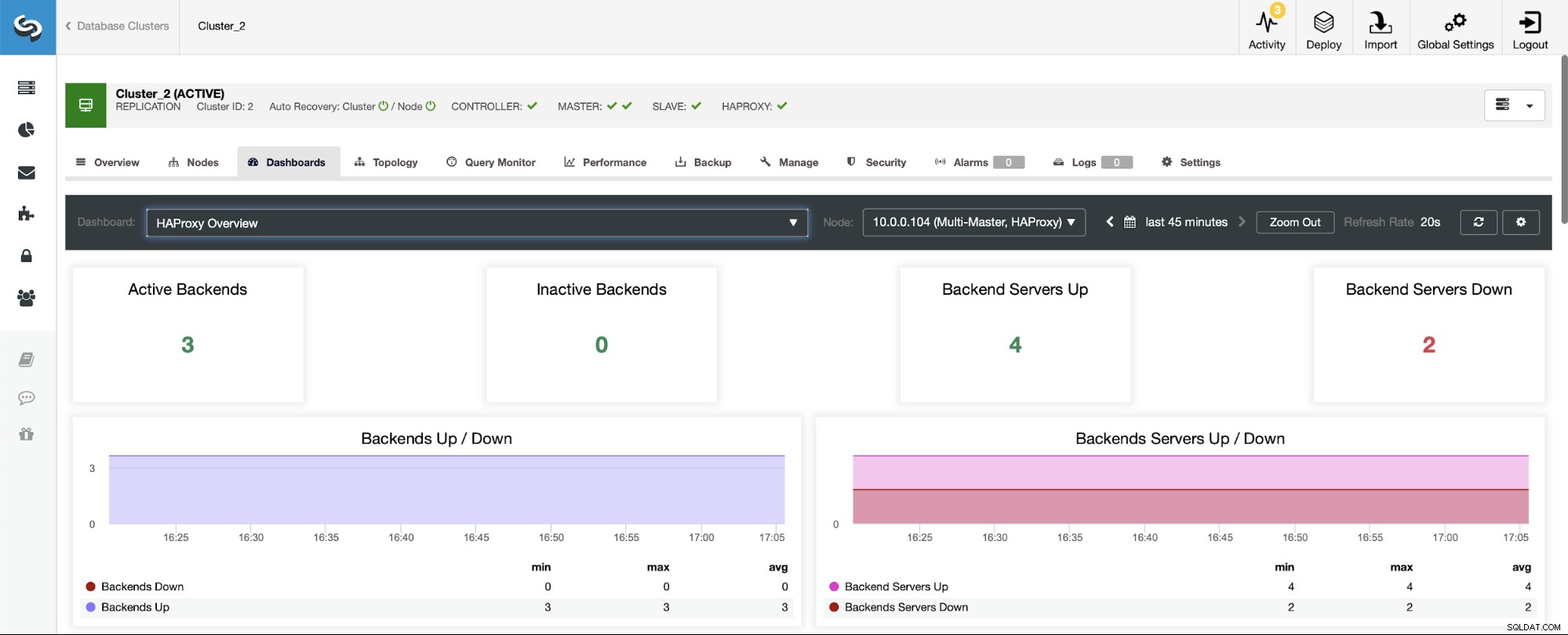
レプリケーションクラスターを使用するシナリオでは、HAProxyが読み取り/書き込み分割でデプロイされ、スクリプトによって1つのホスト(マスター)のみがライターで稼働し続けるため、状況が異なります。バックエンド。
注意、これが、以下に「ダウン」とマークされた2つのバックエンドサーバーが表示される理由です。
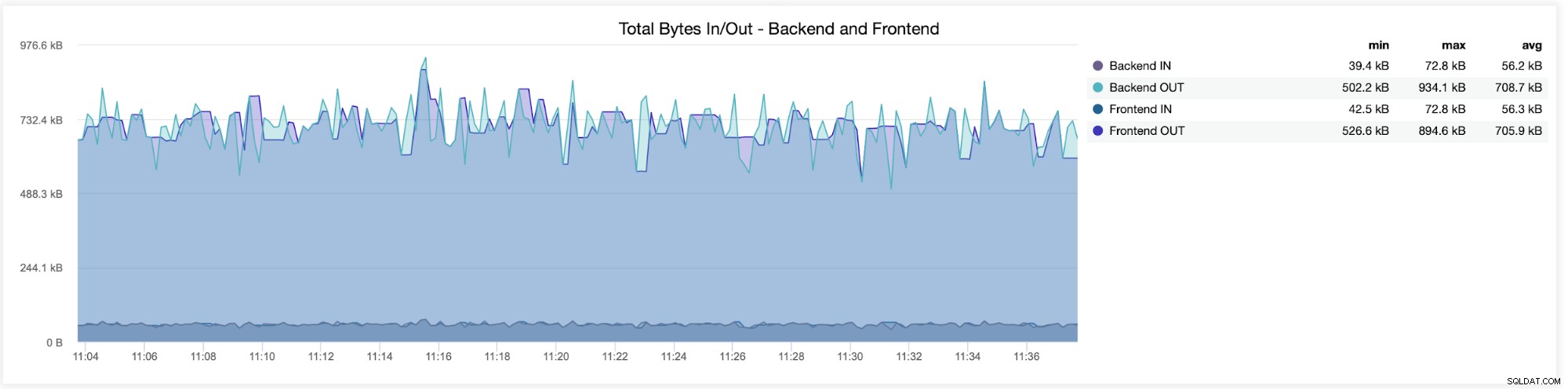
次のグラフでは、両方が送受信したデータが表示されます。バックエンド(HAProxyからデータベースサーバーへ)およびフロントエンド(HAProxyとクライアントホストの間):
HAProxy構成のバックエンド間のトラフィック分散を確認することもできます。この場合、2つのバックエンドがあり、クエリはポート3308を介して送信されます。ポート3308は、Galeraクラスターへのラウンドロビンアクセスポイントとして機能します。
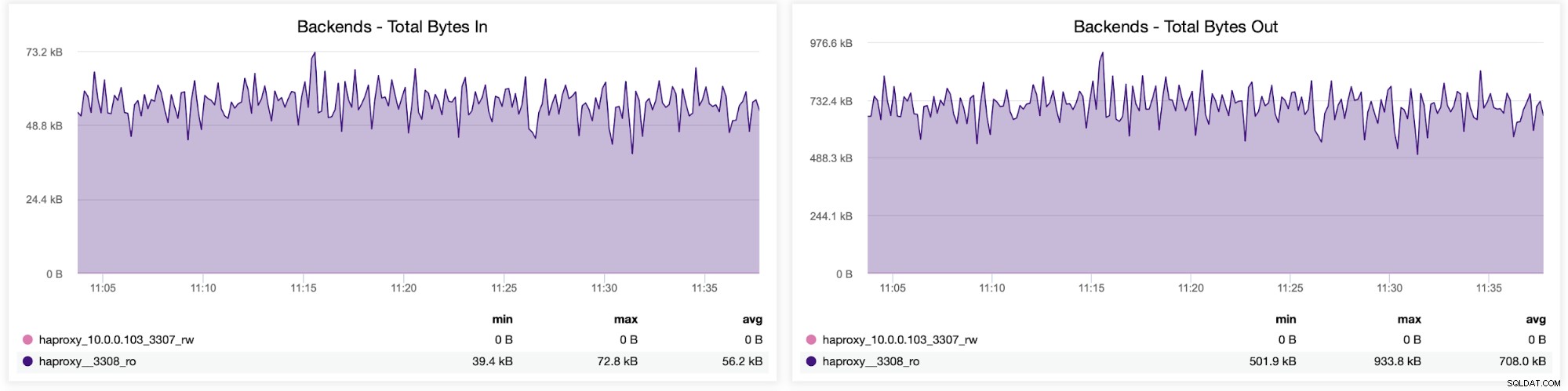
次に、トラフィックがすべてのバックエンドサーバーにどのように分散されたかを確認できます。このシナリオでは、ラウンドロビンアクセスパターンにより、データは3つのバックエンドGaleraサーバーすべてにほぼ均等に分散されていました。
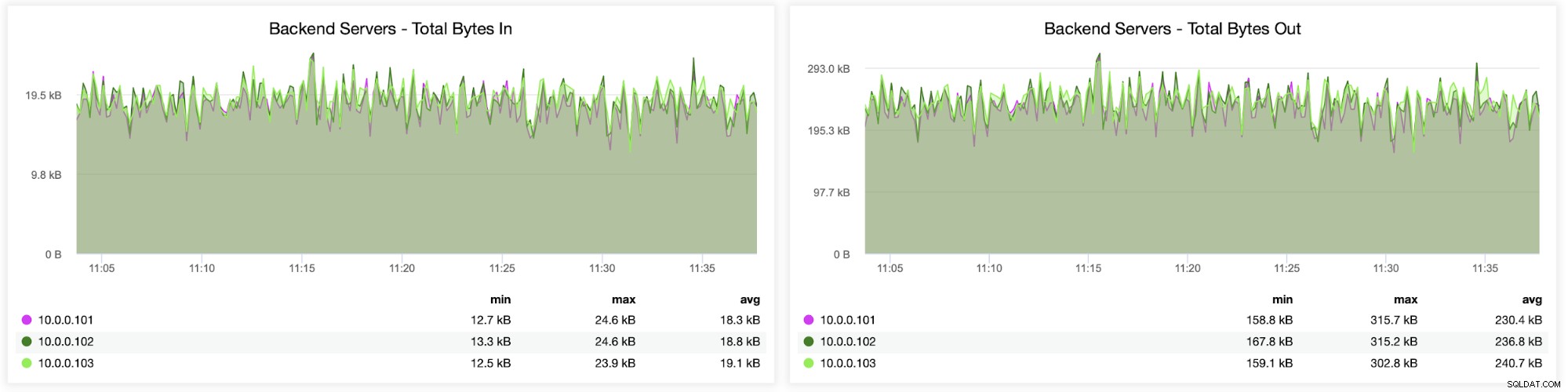
HAProxyからバックエンドに開かれたセッションの数など、セッションに関する情報次のグラフに示すように、サーバーも監視できます。また、1秒間にバックエンドに対して新しいセッションが開かれた回数と、それらのメトリックがバックエンドサーバーごとにどのように表示されるかを追跡することもできます。
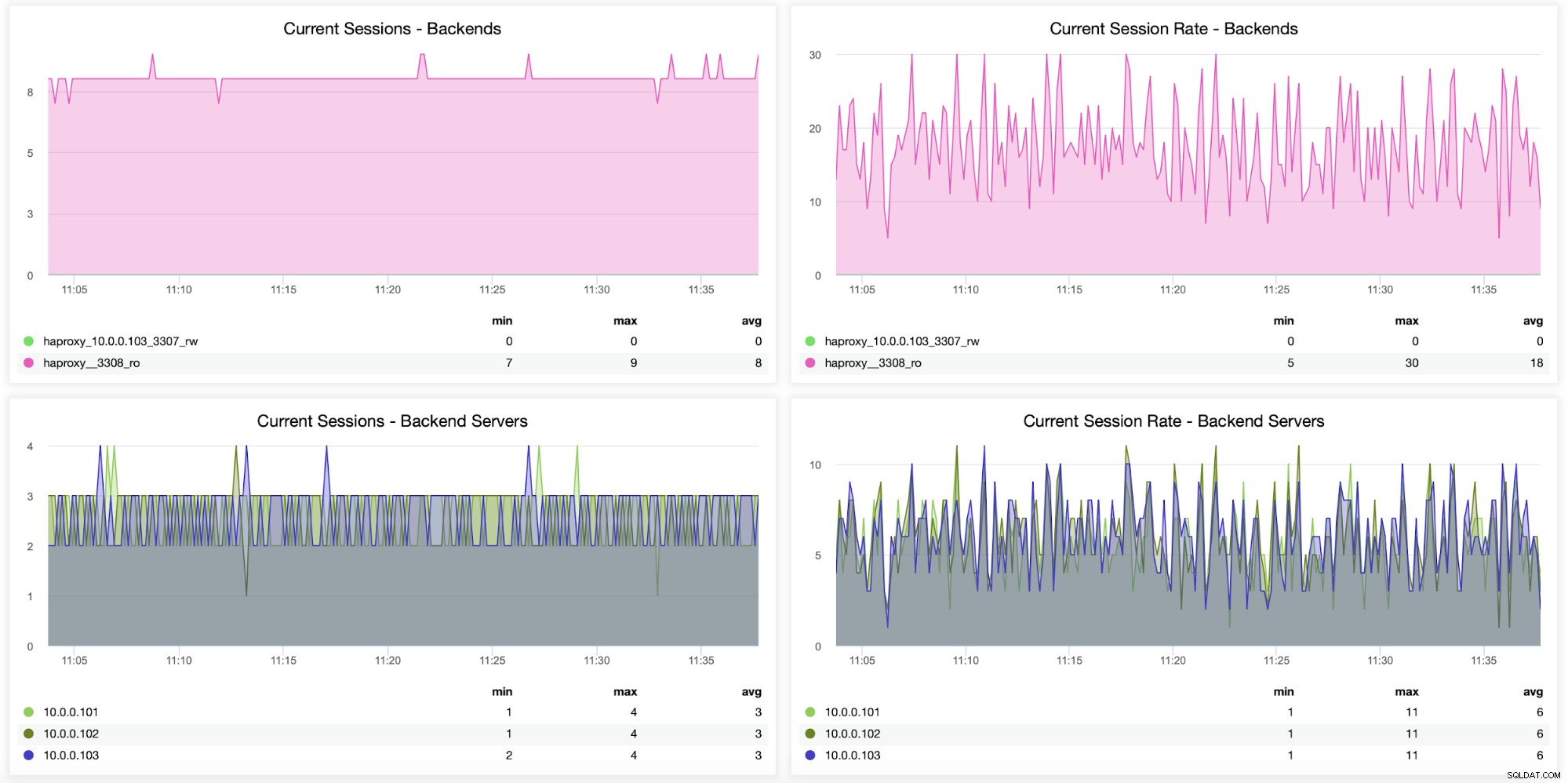
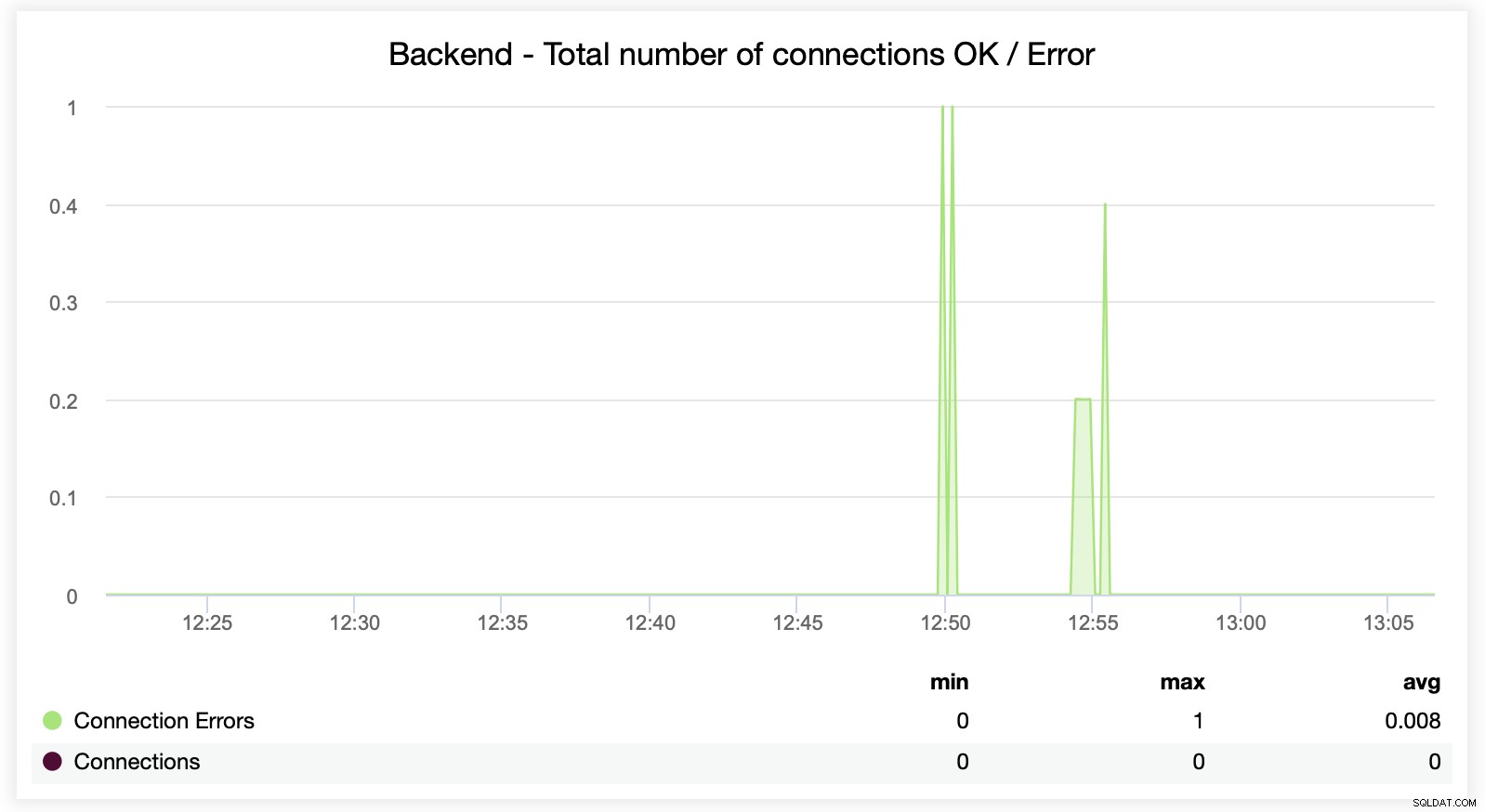
次の2つのグラフは、バックエンドサーバーあたりの最大セッション数と接続の問題が発生しました。これは、HAProxyインスタンスで構成エラーが発生し、接続が切断され始めるデバッグ目的で非常に役立ちます。
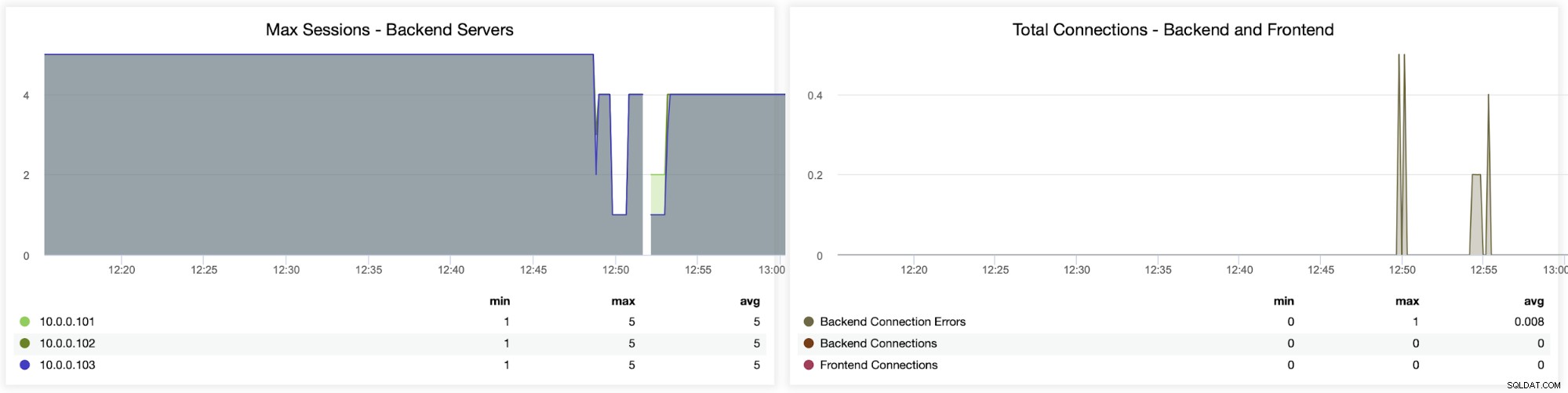
この次のグラフは、エラーに関連するさまざまなメトリックを示しているため、より価値がある可能性があります。エラー、リクエストエラー、バックエンド側での再試行などの処理。セッションメトリックの概要を示す「セッション」グラフもあります。
ここで、ClusterControlが接続エラーをリアルタイムで追跡していることがわかります。これは、問題が進展し始めた正確な時刻を特定するのに役立ちます。
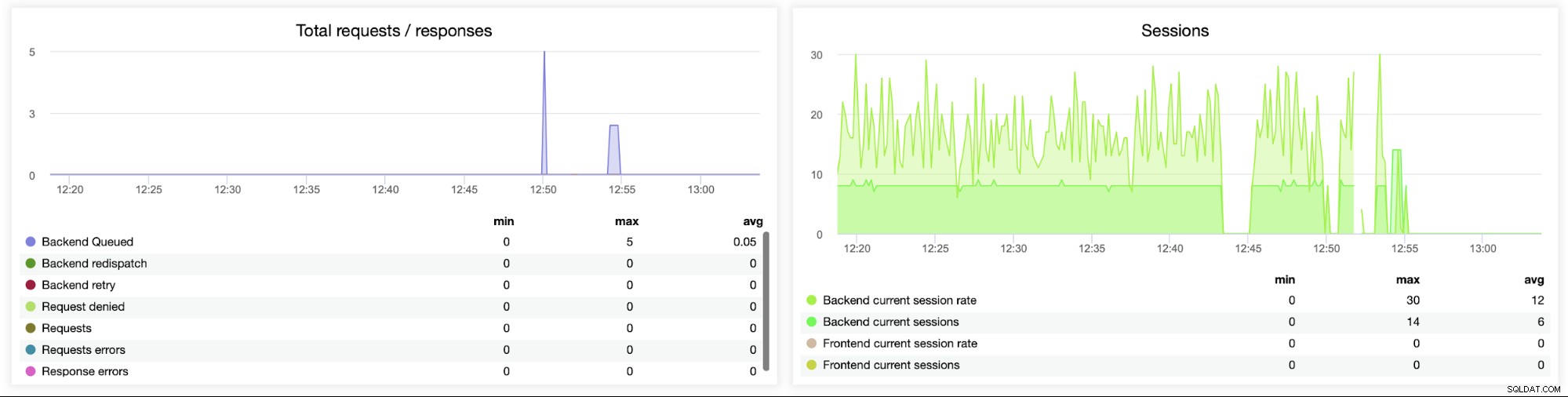
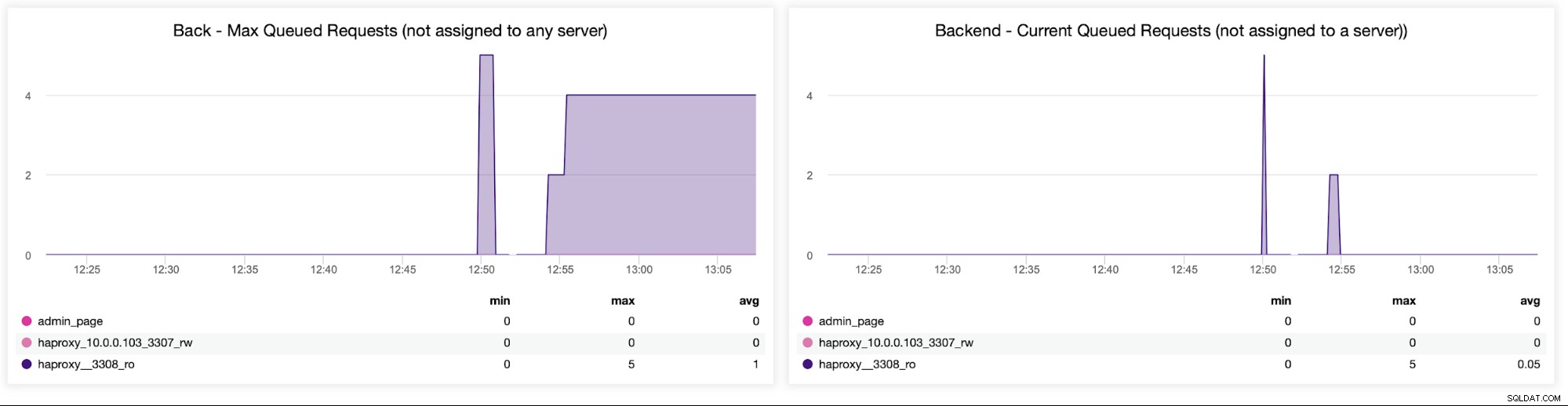
最後に、キューに入れられたリクエストに関連する次の2つのグラフを見ていきます。 。バックエンドサーバーが過飽和状態の場合、HAProxyはバックエンドへのリクエストをキューに入れます。これは、たとえば、これ以上トラフィックを処理できない過負荷のデータベースサーバーを指している可能性があります。
ClusterControlにHAProxyロードバランサーをデプロイして監視すると、接続の管理と監視を簡単に行うことができます。バックエンドのパフォーマンス、トラフィック分散、セッションメトリック、接続エラー、およびキューに入れられたリクエストの数を明確に把握することで、データベース設定の可用性とスケーラビリティを確保できます。
ClusterControlを使用すると、データベース構成のロードバランサーのセットアップと監視が簡単になります。 ClusterControlをまだ使用していませんか? ClusterControlを使用してHAProxyロードバランサーをデプロイおよび監視するのがいかに簡単であるかをご自身で確認したい場合は、文字列が添付されていないプラットフォームの30日間の無料トライアルにご招待します。負荷分散にHAProxyを使用する理由と方法の詳細なウォークスルーについては、HAProxyを使用したMySQL負荷分散に関するチュートリアルをご覧ください。