以下は、無料でダウンロードできるホワイトペーパー「高可用性オープンソースデータベース環境を設計する方法」からの抜粋です。
「高可用性」に関するいくつかの言葉
最近では、本格的な展開には高可用性が必須です。メンテナンスを実行するためにデータベースのダウンタイムを数時間スケジュールできる時代は過ぎ去りました。あなたのサービスが利用できない場合、あなたは顧客とお金を失っています。したがって、データベース環境を高可用性にすることは、通常、最優先事項の1つです。
これは、データベース管理者に重大な課題をもたらします。まず、環境が高可用性であるかどうかをどのように判断しますか?どのように測定しますか?可用性を向上させるために必要な手順は何ですか?最初から高可用性を実現するようにセットアップを設計するにはどうすればよいですか?
MySQL(およびMariaDB)エコシステムで利用できるHAソリューションはたくさんありますが、どのソリューションを信頼できるかをどのようにして知ることができますか?一部のソリューションは特定の条件下で機能する場合がありますが、これらの条件以外で適用すると、より多くの問題が発生する可能性があります。多くの方法で構成できるMySQLレプリケーションのような基本的な機能でさえ、重大な害を引き起こす可能性があります。たとえば、複数の書き込み可能なマスターを使用した循環レプリケーションなどです。レプリケーションを使用して「マルチマスターセットアップ」をセットアップするのは簡単ですが、非常に簡単に壊れて、異なるサーバー上に異なるデータセットが残る可能性があります。信頼できる唯一の情報源と見なされることが多いデータベースの場合、データの整合性が損なわれると、壊滅的な結果を招く可能性があります。
次の章では、データベースのセットアップにおける高可用性の要件と、システムをゼロから設計する方法について説明します。
高可用性の測定
高可用性とは何ですか?特定の環境が高可用性であるかどうかを判断できるようにするには、そのためのいくつかのメトリックが必要です。高可用性を測定する方法は多数あります。ここでは、最も基本的なもののいくつかに焦点を当てます。
ただし、最初に、この高可用性全体が何であるかを考えてみましょう。その目的は何ですか?それはあなたの環境がその目的を果たすことを確認することです。目的はさまざまな方法で定義できますが、通常は、何らかのサービスを提供することです。データベースの世界では、通常、データにある程度関連しています。内部アプリケーションにデータを提供している可能性があります。データを保存し、分析プロセスでクエリ可能にすることができます。ユーザー向けにデータを保存し、必要に応じて提供することもできます。目的が明確になったら、関連する成功要因を確立できます。これは、特定のケースで高可用性が何を意味するかを定義するのに役立ちます。
SLAの
サービスレベルアグリーメント(SLA)。内部サービスのSLAを定義することも非常に一般的です。 SLAとは何ですか?これは、顧客に提供する予定のサービスレベルの定義です。これは、購入したサービスまたは購入を計画しているサービスの安定性のレベルをよりよく理解するためです。 SLAを準備するために活用できる方法は多数ありますが、一般的な方法は次のとおりです。
- サービスの可用性(パーセント)
- サービスの応答性-レイテンシー(平均、最大、95パーセンタイル、99パーセンタイル)
- ネットワークでのパケット損失(パーセント)
- スループット(平均、最小、95パーセンタイル、99パーセンタイル)
ただし、それよりも複雑になる可能性があります。シャーディングされたマルチユーザー環境では、たとえば、SLAを次のように定義できます。「サービスは99,99%の時間利用可能であり、ユーザーの2%以上が影響を受けるとダウンタイムが宣言されます。インシデントの解決に15分以上かかることはありません。」このようなSLAを拡張して、クエリの応答時間を組み込むこともできます。「クエリのレイテンシの99パーセンタイルが200ミリ秒を超えると、ダウンタイムが呼び出されます」。
ナイン
可用性は通常「ナイン」で測定されます。特定の量の「ナイン」が正確に何を保証するかを調べてみましょう。以下の表はウィキペディアから抜粋したものです:
| 可用性% | 年間のダウンタイム | 1か月あたりのダウンタイム | 1週間あたりのダウンタイム | 1日あたりのダウンタイム |
|---|---|---|---|---|
| 90% ( "one nine") | 36。5日 | 72時間 | 16.8時間 | 2.4時間 |
| 95% ( "1.5ナイン") | 18。25日 | 36時間 | 8.4時間 | 1.2時間 |
| 97% | 10。96日 | 21.6時間 | 5.04時間 | 43.2分 |
| 98% | 7。30日 | 14.4時間 | 3.36時間 | 28.8分 |
| 99% ( "ツーナイン") | 3。65日 | 7.20時間 | 1.68時間 | 14.4分 |
| 99.5% ( "2.5ナイン") | 1。83日 | 3.60時間 | 50.4分 | 7.2分 |
| 99.8% | 17.52時間 | 86.23分 | 20.16分 | 2.88分 |
| 99.9% ( "スリーナイン") | 8.76時間 | 43.8分 | 10.1分 | 1.44分 |
| 99.95% ( "3.5ナイン") | 4.38時間 | 21.56分 | 5.04分 | 43.2秒 |
| 99.99% ( "フォーナイン") | 52.56分 | 4.38分 | 1.01分 | 8.64秒 |
| 99.995% ( "4.5ナイン") | 26.28分 | 2.16分 | 30.24秒 | 4.32秒 |
| 99.999% ( "ファイブナイン") | 5.26分 | 25.9秒 | 6.05秒 | 864.3ミリ秒 |
| 99.9999% ( "シックスナイン") | 31.5秒 | 2.59秒 | 604.8ミリ秒 | 86.4ミリ秒 |
| 99.99999% ( "セブンナイン") | 3.15秒 | 262.97ミリ秒 | 60.48ミリ秒 | 8.64ミリ秒 |
| 99.999999% ( "エイトナイン") | 315.569ミリ秒 | 26.297ミリ秒 | 6.048ミリ秒 | 0.864ミリ秒 |
| 99.9999999% ( "ナインナイン") | 31.5569ミリ秒 | 2.6297ミリ秒 | 0.6048ミリ秒 | 0.0864ミリ秒 |
ご覧のとおり、急速にエスカレートします。ファイブナイン(99,999%の可用性)は、1年間で5.26分のダウンタイムに相当します。可用性は、月ごと、週ごと、日ごとなど、さまざまな狭い範囲で計算することもできます。これらの数値は、さまざまなレベルの可用性の維持に関連するコストについて話し合うときに役立つため、覚えておいてください。
可用性の測定
ダウンタイムがあるかどうかを判断するには、環境についての洞察が必要です。システムの可用性を定義するメトリックを追跡する必要があります。全体像を考慮して、顧客の視点から測定する必要があることを覚えておくことが重要です。たとえば、ネットワークの問題が原因でデータベースにアクセスできない場合は、データベースが稼働しているかどうかは関係ありません。セットアップのすべてのビルディングブロックは、可用性に影響を与えます。
可用性データを探すのに適した場所の1つは、Webサーバーのログです。エラーが発生したすべてのリクエストは、何かが発生したことを意味します。データベース接続に失敗したため、アプリケーションから返されたHTTPエラー500である可能性があります。これらは、いくつかのデータベースの問題を指し示すプログラムエラーである可能性があり、Apacheのエラーログに記録されます。データベースサーバーの稼働時間として単純なメトリックを使用することもできますが、より複雑なSLAでは、1つのデータベースが利用できないことがユーザーベースにどのように影響したかを判断するのが難しい場合があります。何をするにしても、複数のメトリックを使用する必要があります。これは、環境のさまざまなレイヤーで発生した可能性のある問題をキャプチャするために必要です。
マジックナンバー:「スリー」
高可用性は冗長性にも関係しますが、データベースクラスターの場合、3つは魔法の数です。冗長性のために2つのノードを用意するだけでは不十分です。このようなセットアップでは、組み込みの高可用性は提供されません。確かに、単一のノードよりも優れている可能性がありますが、サービスを回復するには人間の介入が必要です。なぜそうなのか見てみましょう。
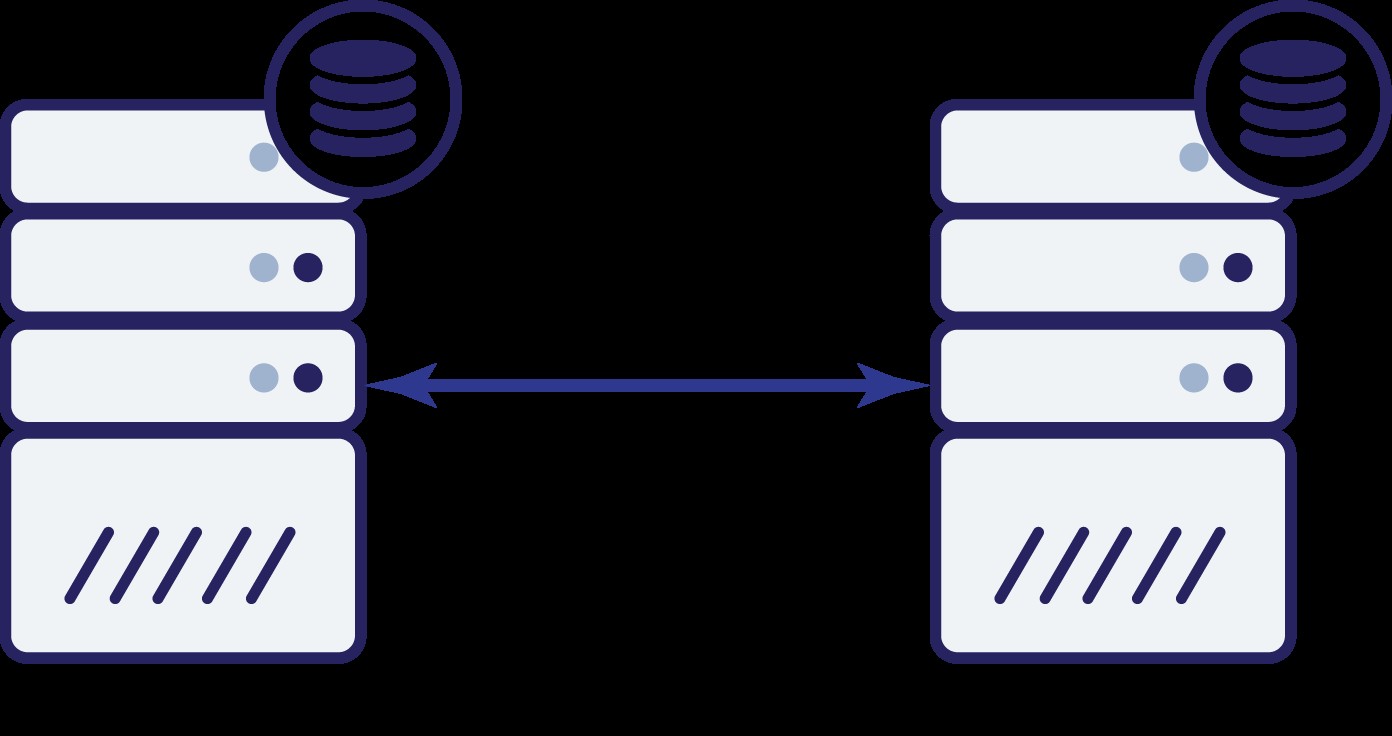
AとBの2つのノードがあると仮定します。それらの間にネットワークリンクがあります。 AとBの両方が書き込みを提供し、アプリケーションが接続先をランダムに選択するとします(つまり、アプリケーションの一部はノードAに接続し、他の部分はノードBに接続します)。ここで、AとBの間のネットワーク接続が失われるネットワークの問題があると想像してみましょう。
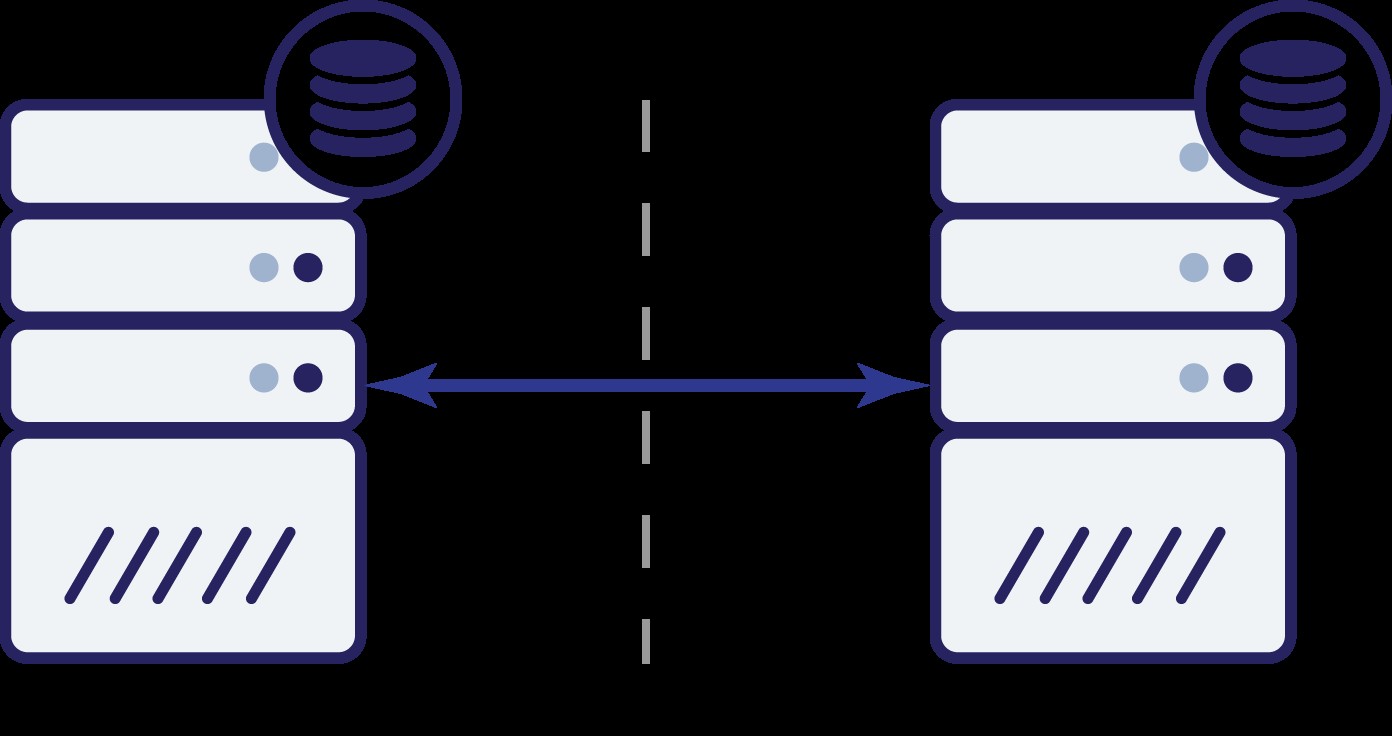
今何? AもBも、他のノードの状態を知ることはできません。両方のノードで実行できるアクションは2つあります。
- 引き続きトラフィックを受け入れることができます
- 彼らは活動を停止し、トラフィックの提供を拒否することができます
最初のオプションについて考えてみましょう。他のノードが実際にダウンしている限り、これが推奨されるアクションです。データベースでトラフィックを処理し続ける必要があります。結局のところ、これが高可用性の背後にある主なアイデアです。しかし、両方のノードが互いに切断されている間もトラフィックを受け入れ続けるとしたらどうなるでしょうか。新しいデータが両側に追加され、データセットが同期しなくなります。ネットワークの問題が解決されると、これら2つのデータセットをマージするのは困難な作業になります。したがって、両方のノードを稼働させ続けることはできません。問題は、ノードAがノードBが生きているかどうか(およびその逆)をどのように判断できるかということです。答えは-できません。すべての接続がダウンしている場合、障害が発生したノードと障害が発生したネットワークを区別する方法はありません。結果として、唯一の安全なアクションは、両方のノードがすべての操作を停止し、
トラフィックの提供を拒否することです。
ここで、このような状況で3番目のノードがどのように役立つかを考えてみましょう。
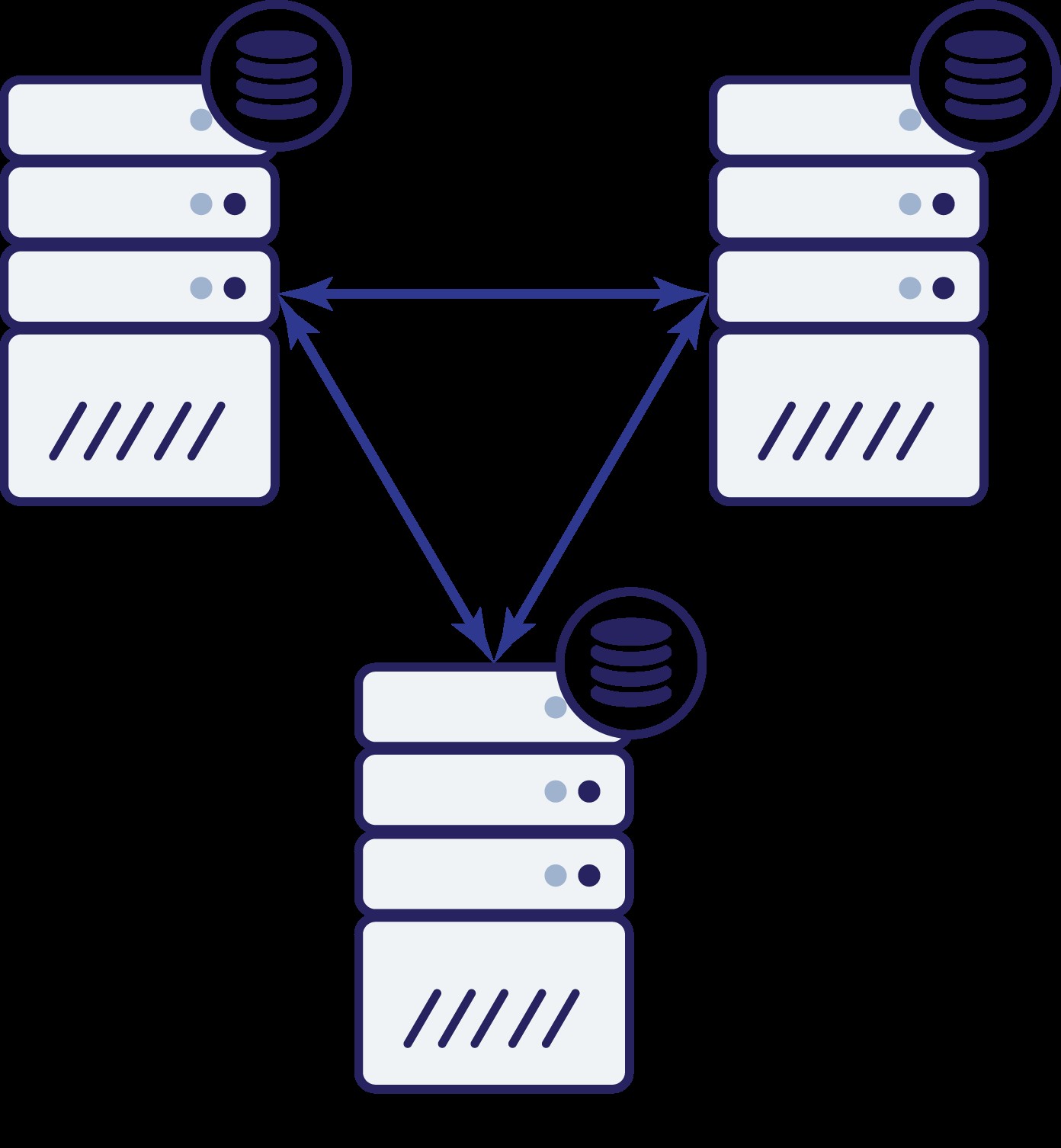
これで、A、B、Cの3つのノードができました。すべてが相互接続され、すべてが読み取りと書き込みを処理しています。
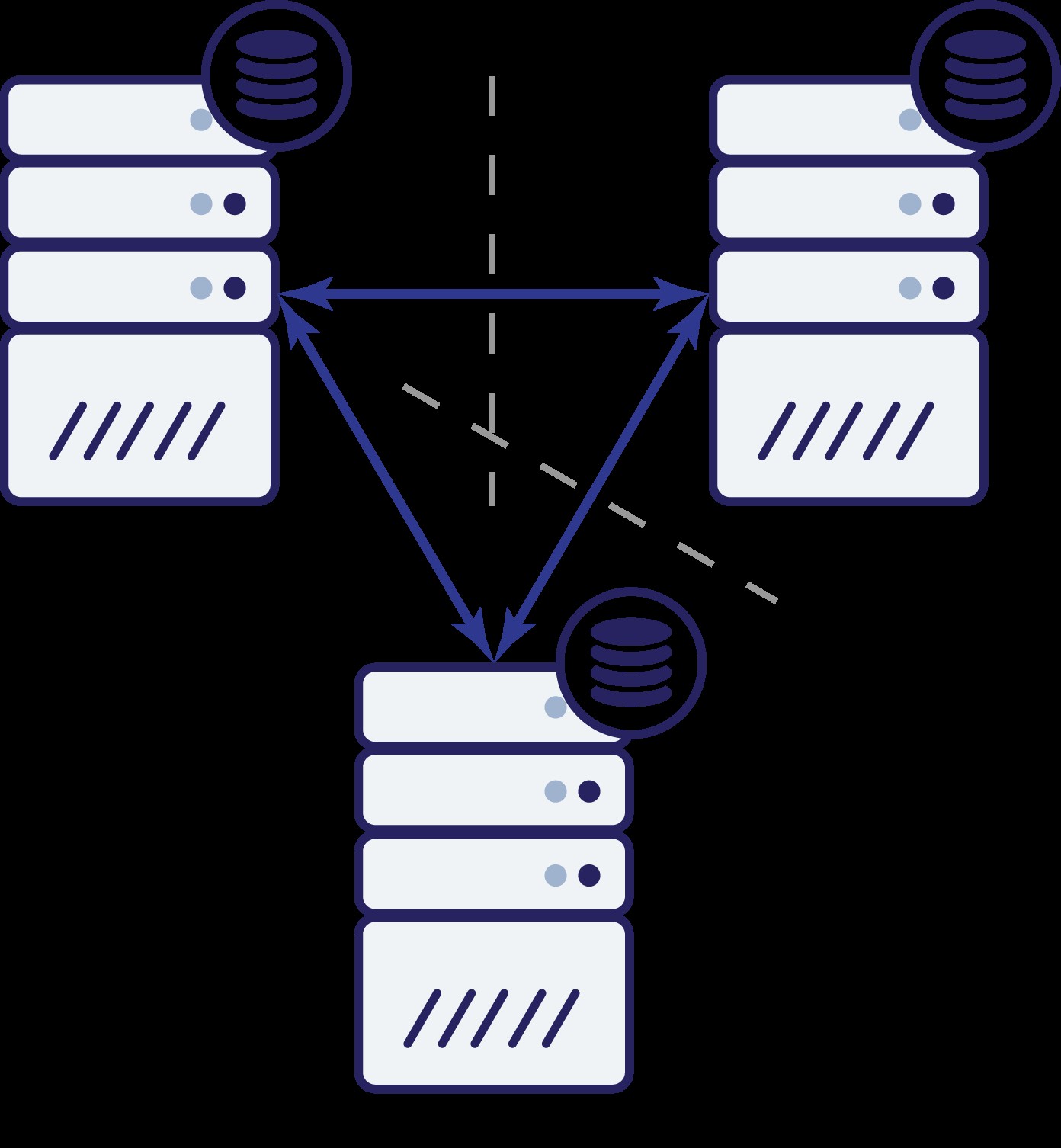
この場合も、前の例と同様に、ネットワークの問題により、ノードBがクラスターの残りの部分から切り離されています。次に何が起こる可能性がありますか?さて、状況は前に説明したものとかなり似ています。 2つのオプション-ノードBはダウンしている(そしてクラスターの残りの部分は継続する必要がある)か、アップしている可能性があります。その場合、ノードBはトラフィックの処理を許可されるべきではありません。クラスターの状態を確認できますか?実はそうです。ノードAとCは相互に通信でき、その結果、ノードBが使用できないことに同意できることがわかります。彼らはそれが起こった理由を知ることはできませんが、彼らが知っていることは、クラスター内の3つのノードのうち2つがまだ相互に接続しているということです。これらの2つのノードがクラスターの大部分を形成していることを考えると、トラフィックの処理を継続することができます。同時に、ノードBは、問題がその側にあることを推測することもできます。ノードAにもノードCにもアクセスできないため、ノードBはクラスターの残りの部分から分離されます。分離されており、過半数(1/3)の一部ではないため、安全なアクションは、トラフィックの配信を停止し、クエリの受け入れを拒否して、データのドリフトが発生しないようにすることだけです。
もちろん、クラスター内にノードを3つしか持てないという意味ではありません。より優れたフォールトトレランスが必要な場合は、さらに追加することをお勧めします。ただし、高可用性を向上させたい場合は、奇数にする必要があることに注意してください。また、上記の例では「ノード」について話していました。これは、データセンター、アベイラビリティーゾーンなどにも当てはまることに注意してください。それぞれが同じ数のノード(たとえば、それぞれ3つのノード)を持つ2つのデータセンターがあり、それら2つのDC間の接続が失われる場合、同じ原則がここに適用されます。 -クラスターのどちらの半分がトラフィックの処理を開始するかを判断できません。それを伝えるには、3番目のデータセンターにオブザーバーがいる必要があります。残りのデータセッターの状態を監視し、意思決定に参加するタスクを持つ、さらに別のノードのセット、または単一のホストにすることができます(ここでの例はGaleraアービトレーターです)。
単一障害点
高可用性とは、単一障害点(SPOF)を削除することであり、プロセスに新しい障害点を導入することではありません。 SPOFとは何ですか? SLAで定義されているように、障害が発生するとダウンタイムが発生するインフラストラクチャの部分は、SPOFと呼ばれます。インフラストラクチャの設計には全体的なアプローチが必要であり、さまざまなコンポーネントを互いに独立して設計することはできません。ほとんどの場合、設計全体に責任はありません。
データベース管理者は、ネットワーク層などではなく、データベースに集中する傾向があります。それでも、他の部分を念頭に置き、それらを担当するチームと協力して、担当する部分が正しく設計されているだけでなく、インフラストラクチャの残りの部分が同じ原則。さらに、インフラストラクチャ全体がどのように設計されているかについてのこのような知識は、データベーススタックの設計にも役立ちます。発生する可能性のある問題を知ることは、データベースの可用性に影響を与えないようにするためのメカニズムを構築するのに役立ちます。