データの取得に関するデータベースの現在の主要なユースケースを考慮すると、そのパフォーマンスが非常に高いことが非常に重要になります。これは、データがストレージから可能な限り最も効率的な方法でフェッチされた場合にのみ達成できます。同じことを達成するために行われた多くの成功した発明と実装がありました。ほとんどのデータベースで採用されているよく知られたアプローチの1つは、テーブルにインデックスを付けることです。
データベースインデックスとは何ですか?
データベースインデックスは、その名前が示すように、実際のデータへのインデックスを維持し、それによって実際のテーブルからデータを取得するためのパフォーマンスを向上させます。よりデータベースの用語では、インデックスを使用すると、データが特定の順序で並べ替えられるため、インデックス付きデータを含むページを最小限のトラバーサルでフェッチできます。インデックスの利点は、追加のデータを書き込むために追加のストレージスペースを犠牲にしてもたらされます。インデックスは基になるテーブルに固有であり、1つ以上のキー(つまり、指定されたテーブルの1つ以上の列)で構成されます。インデックスアーキテクチャには主に2つのタイプがあります
- クラスター化インデックス–インデックスデータはデータの他の部分と一緒に保存され、データはインデックスキーに基づいて並べ替えられます。指定されたテーブルに対して、このカテゴリに存在できるインデックスは最大で1つだけです。
- 非クラスター化インデックス–インデックスデータは個別に保存され、データの他の部分が保存されているストレージへのポインターがあります。これは、セカンダリインデックスとも呼ばれます。このカテゴリには、指定したテーブルに必要な数のインデックスを含めることができます。
インデックスの実装にはさまざまなデータ構造が使用されますが、大多数のデータベースで広く採用されているのはBツリーとハッシュです。
PostgreSQLインデックスとは何ですか?
PostgreSQLは非クラスター化インデックスのみをサポートします。つまり、インデックスデータ および完全なデータ(以降、ヒープデータと呼びます) )は別のストレージに保存されます。非クラスター化インデックスは、あらゆるドキュメントの「目次」のようなもので、最初にページ番号を確認し、次にそれらのページ番号を確認してコンテンツ全体を読み取ります。インデックスに基づいて完全なデータを取得するために、対応するヒープデータへのポインタを維持します。ページ番号を知った後と同じです。そのページに移動して、ページの実際のコンテンツを取得する必要があります。
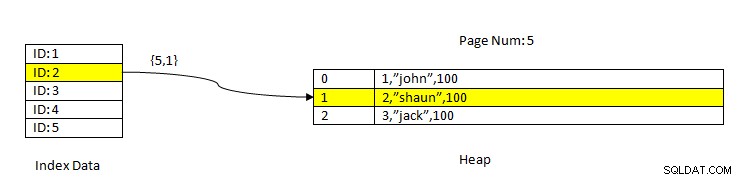 PostgreSQL:インデックスを使用して読み取られたデータ
PostgreSQL:インデックスを使用して読み取られたデータ たとえば、3つの列と列 IDのインデックスを持つテーブルについて考えてみます。 。キーID=2に基づいてデータを読み取るために、最初に、ID値2のインデックス付きデータが検索されます。これには、ページ番号(つまり、ブロック番号)とそのページ内のデータのオフセットに関するポインター(アイテムポインターと呼ばれる)が含まれます。現在の例では、インデックスはページ番号5とページの2番目のラインアイテムを指しており、データ全体にオフセットされています(2、 "Shaun"、100)。データ全体にインデックス付きデータも含まれていることに注意してください。これは、同じデータが2つのストレージで繰り返されることを意味します。
INDEXはパフォーマンスの向上にどのように役立ちますか? INDEXレコードを選択するには、すべてのページを順番にスキャンするのではなく、基になるIndexデータ構造を使用して一部のページを部分的にスキャンする必要があります。ただし、ねじれがあります。各レコードはインデックスデータから検出されるため、ヒープデータでデータ全体を調べる必要があります。これにより、ランダムなI / Oが大量に発生し、シーケンシャルI/Oよりもパフォーマンスが低下すると見なされます。したがって、(PostgreSQLオプティマイザのコストに基づいて決定された)レコードのごく一部が選択されている場合にのみ、PostgreSQLのみがインデックススキャンを選択します。それ以外の場合は、テーブルにインデックスがあり、シーケンススキャンを引き続き使用します。
要約すると、インデックスの作成はパフォーマンスを高速化しますが、ストレージのオーバーヘッドがあり、INSERTのパフォーマンスが低下するため、慎重に選択する必要があります。
ここで、データのインデックス部分のみが必要な場合、インデックスストレージページからのみフェッチできるのではないかと思うかもしれません。これに対する答えは、次に説明するように、MVCCがインデックスストレージでどのように機能するかに直接関係しています。
インデックス作成にMVCCを使用する
ヒープページと同様に、インデックスページは複数のバージョンのインデックスタプルを維持しますが、可視性情報は維持しません。以前のMVCCで説明したように ブログでは、タプルの適切な表示バージョンを決定するために、トランザクションを比較する必要があります。タプルを挿入/更新/削除したトランザクションは、ヒープタプルとともに維持されますが、インデックスタプルでは維持されません。これは純粋にストレージを節約するために行われ、スペースとパフォーマンスの間のトレードオフです。
元の質問に戻ります。インデックスタプルの可視性情報がないため、対応するヒープタプルを調べて、選択したデータが表示されているかどうかを確認する必要があります。したがって、ヒープタプルからのデータの他の部分は必要ありませんが、可視性を確認するためにヒープページにアクセスする必要があります。ただし、ここでも、特定のページ(インデックスで示されるページ、つまりItemPointer)のすべてのタプルが表示され、「可視性チェック」のためにヒープページの各アイテムを参照する必要がないため、データのみを返すことができる場合に、ねじれがあります。インデックスページから。この特殊なケースは「インデックスのみのスキャン」と呼ばれます。これをサポートするために、PostgreSQLは各ページの可視性マップを維持してページレベルの可視性をチェックします。
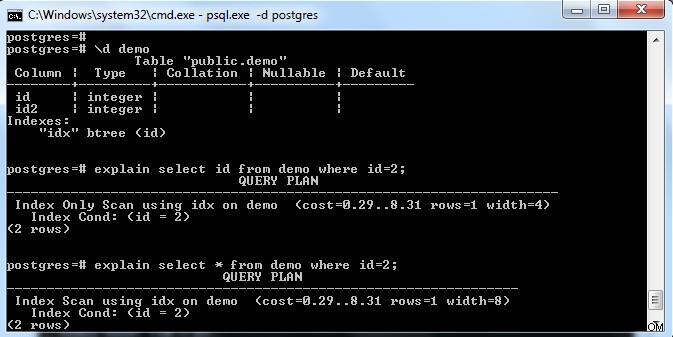
上の画像に示されているように、テーブル「demo」には、列「id」にキーが付いたインデックスがあります。インデックスフィールド(つまり、id)のみを選択しようとすると、「インデックスのみのスキャン」が選択されます(参照ページが完全に表示されていることを考慮)。
クラスター化されたインデックス
PostgreSQLでは直接クラスター化インデックスはサポートされていませんが、部分的に同じことを実現する間接的な方法があります。これは、以下のSQLコマンドによって実現されます。
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]最初のコマンドは、指定されたインデックスを使用してテーブルをクラスター化する(つまり、テーブルをソートする)ようにデータベースに指示します。このインデックスはすでに作成されているはずです。このクラスタリングは1回限りの操作であり、このテーブルに対する後続の操作の後もその影響は残りません。つまり、さらにレコードが挿入/更新された場合、テーブルは順序付けられたままにならない可能性があります。ユーザーがテーブルをクラスター化(順序付け)しておく必要がある場合は、インデックス名を指定せずに最初のコマンドを使用できます。
2番目のコマンドは、テーブル(つまり、何らかのインデックスを使用してすでにクラスター化されているテーブル)を再クラスター化する場合にのみ役立ちます。このコマンドは、現在接続しているユーザーに表示される現在のデータベース内のすべてのテーブルを再クラスター化します。
たとえば、次の図では、クラスター化されたインデックスがないため、最初のSELECTはソートされていない順序でレコードを返します。クラスター化されていないインデックスはすでに存在しますが、レコードは、レコードがソートされていないヒープ領域から選択されます。
2番目のSELECTは、列「id」を含むインデックスを使用してクラスター化されているため、列「id」でソートされたレコードを返します。
3番目のSELECTは、部分的なレコードをソートされた順序で返しますが、新しく挿入されたレコードはソートされません。 4番目のSELECTは、テーブルが再度クラスター化されているため、すべてのレコードをソートされた順序で返します
。 PostgreSQLクラスターコマンド
PostgreSQLクラスターコマンド インデックスタイプ
PostgreSQLは、以下のようにいくつかのタイプのインデックスを提供します。
- Bツリー
- ハッシュ
- GiST
- GIN
- BRIN
各インデックスタイプは、さまざまなタイプのクエリに最適な、さまざまな種類の基になるデータ構造を実装します。デフォルトでは、広く使用されているインデックスであるBツリーインデックスが作成されます。各インデックスタイプの詳細については、今後のブログで取り上げます。
その他:部分インデックスと式インデックス
テーブルの1つ以上の列のインデックスについてのみ説明しましたが、PostgreSQLでインデックスを作成する方法は他に2つあります
。- 部分インデックス: 部分インデックスは、特定のテーブルのキー列のサブセットを使用して作成されたインデックスです。サブセットは、インデックスの作成中に指定された条件式によって定義されます。したがって、部分インデックスを使用すると、インデックスデータを格納するためのストレージスペースが節約されます。したがって、ユーザーは、それらがあまり一般的な値ではないように条件を選択する必要があります。より頻繁な(一般的な)値については、とにかくインデックススキャンは選択されません。残りの機能は、通常のインデックスの場合と同じです。 例:部分インデックス
- 表現インデックス: 式インデックスは、PostgreSQLに別の種類の柔軟性を提供します。部分インデックスを含め、これまでに説明したすべてのインデックスは、特定の列のセットにあります。ただし、式(1つ以上の列を含む式)に基づくテーブルへのアクセスがクエリに含まれている場合、式インデックスがないと、インデックススキャンは選択されません。したがって、この種のクエリに高速にアクセスするために、PostgreSQLでは式にインデックスを作成できます。残りの機能は、通常のインデックスの場合と同じです。
 例:式インデックス
例:式インデックス
InnoDBのインデックスストレージ
Indexの使用法と機能はPostgreSQLとほとんど同じですが、ClusteredIndexの点で大きな違いがあります。
InnoDBは、次の2つのカテゴリのインデックスをサポートしています。
- クラスター化されたインデックス
- セカンダリインデックス
クラスター化されたインデックス
Clustered Indexは、InnoDBの特別な種類のインデックスです。ここでは、インデックス付きデータは個別に保存されるのではなく、行データ全体の一部です。つまり、クラスター化インデックスは、インデックスのキー列を使用してテーブルデータを物理的に並べ替えるだけです。これは、データがアルファベットに基づいてソートされる「辞書」と見なすことができます。
クラスタ化インデックスはインデックスキーを使用して行を並べ替えるため、クラスタ化インデックスは1つしか存在できません。また、InnoDBはさまざまなデータ操作中にデータを最適に操作するために同じものを使用するため、クラスター化されたインデックスが1つ必要です。
クラスター化インデックスは、以下の優先順位に従って、テーブル列の1つを使用して(テーブル作成の一部として)自動的に作成されます。
- テーブル作成の一部として主キーが言及されている場合は、主キーを使用します。
- すべてのキー列がNULLではない一意の列を選択します。
- それ以外の場合は、各行の行IDを含むシステム列に非表示のクラスター化インデックスを内部的に生成します。
PostgreSQLの非クラスター化インデックスとは異なり、InnoDBはクラスター化インデックスを使用して行にアクセスする速度が速くなります。これは、インデックス検索によってすべての行データが含まれるページに直接アクセスできるため、ランダムなI/Oが回避されるためです。
また、すべてのデータがすでに並べ替えられており、データ全体が利用可能であるため、クラスター化されたインデックスを使用して並べ替えられた順序でテーブルデータを取得することも非常に高速です。
セカンダリインデックス
InnoDBで明示的に作成されたインデックスは、PostgreSQLの非クラスター化インデックスと同様のセカンダリインデックスと見なされます。セカンダリインデックスストレージの各レコードには、行のプライマリキー列(クラスター化インデックスの作成に使用された)と、セカンダリインデックスの作成に指定された列が含まれています。
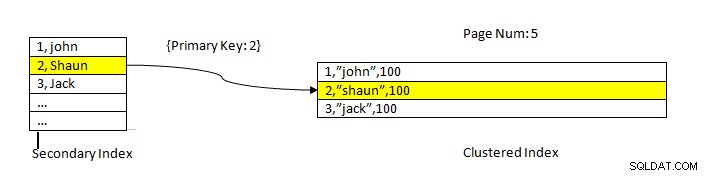 InnoDB:インデックスを使用して読み取られたデータ
InnoDB:インデックスを使用して読み取られたデータ セカンダリインデックスを使用したデータのフェッチは、PostgreSQLの場合と似ていますが、InnoDBセカンダリインデックスルックアップが、クラスター化インデックスから残りのデータをフェッチするためのポインターとしてプライマリキーを提供する点が異なります。
たとえば、上の図に示すように、クラスター化されたインデックスは列 IDにあります。 したがって、テーブルデータは同じ順序で並べ替えられます。セカンダリインデックスは「名前」の列にあります 」、つまり、セカンダリインデックスにはIDと名前の両方の値があります。セカンダリインデックスを使用してルックアップすると、対応するキー値を持つ適切なスロットが見つかります。次に、対応する主キーを使用して、クラスター化されたインデックスからのデータの残りの部分を参照します。
インデックス用のMVCC
クラスター化インデックスMVCCは、従来のInnoDB Undoモデルを使用します(クラスター化インデックスはデータ全体にすぎないため、実際にはデータ全体のMVCCと同じです)。
ただし、セカンダリインデックスMVCCの使用法は、MVCCを維持するために少し異なります。セカンダリインデックスが更新されると、古いインデックスエントリに削除マークが付けられ、新しいレコードが同じストレージに挿入されます。つまり、UPDATEはインプレースではありません。最後に、古いインデックスエントリが削除されます。これまでに、InnoDBセカンダリインデックスMVCCがPostgreSQLMVCCモデルのインデックスとほぼ同じであることに気付いたかもしれません。
インデックスタイプ
InnoDBはBツリータイプのインデックスのみをサポートしているため、インデックスの作成時に指定する必要はありません。
その他:アダプティブハッシュインデックス
前のセクションで述べたように、InnoDBでサポートされているのはBツリータイプのインデックスだけですが、ひねりがあります。 InnoDBには、クエリがハッシュインデックスを作成することでメリットがあり、テーブルのデータ全体がメモリに収まるかどうかを自動的に検出する機能があり、自動的にそうなります。
ハッシュインデックスは、クエリに応じて既存のBツリーインデックスを使用して構築されます。複数のセカンダリBツリーインデックスがある場合は、クエリに従って適格なものを選択します。構築されたハッシュインデックスは完全ではなく、データ使用パターンに従って部分インデックスを構築するだけです。
これは、クエリのパフォーマンスを動的に向上させるための非常に強力な機能の1つです。
結論
任意のデータベースで任意のインデックスを使用すると、READのパフォーマンスを向上させるのに非常に役立ちますが、同時に、追加のデータを書き込む必要があるため、INSERT/UPDATEのパフォーマンスが低下します。したがって、インデックスは非常に賢明に選択する必要があり、インデックスキーがデータをフェッチするための述語として使用される場合にのみ作成する必要があります。
InnoDBは、クラスター化されたインデックスに関して非常に優れた機能を提供します。これは、ユースケースによっては非常に役立つ場合があります。また、その適応型ハッシュインデックスは非常に強力です。
PostgreSQLはさまざまなタイプのインデックスを提供しますが、これは実際に機能到達オプションを提供でき、ビジネスのユースケースに応じて1つまたはすべてを使用できます。また、ユースケースによっては、部分インデックスと式インデックスが非常に役立ちます。