あらゆる種類のデータベースインフラストラクチャを設計するときは、ビジネスニーズを理解し、達成する必要のある可用性の種類を決定することが重要です。
このブログ投稿では、最大のクラウドプロバイダーの1つであるGoogleCloudPlatformのMySQLベースのソリューションの高可用性オプションについて説明します。
GCPSQLインスタンスを使用した高可用性環境の導入
このブログで必要なのは、非常に単純な環境です。1つのデータベースに、おそらく1つまたは2つのレプリカがあります。マスターに障害が発生した場合に、簡単にフェイルオーバーし、できるだけ早く操作を復元できるようにする必要があります。選択したバージョンとしてMySQL5.7を使用し、インスタンス展開ウィザードから開始します。
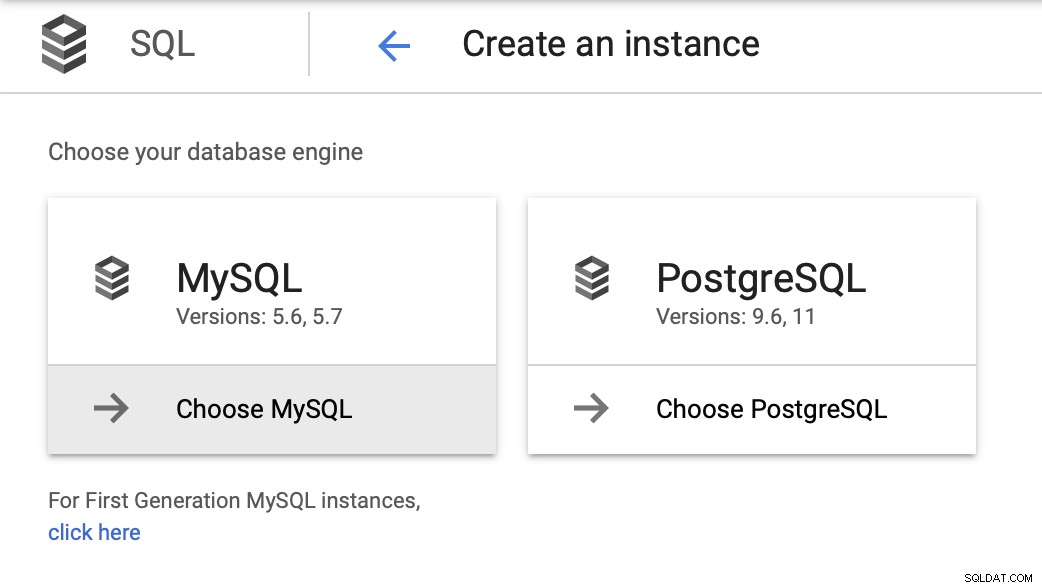
次に、ルートパスワードを作成し、インスタンス名を設定して、配置する場所を決定します:
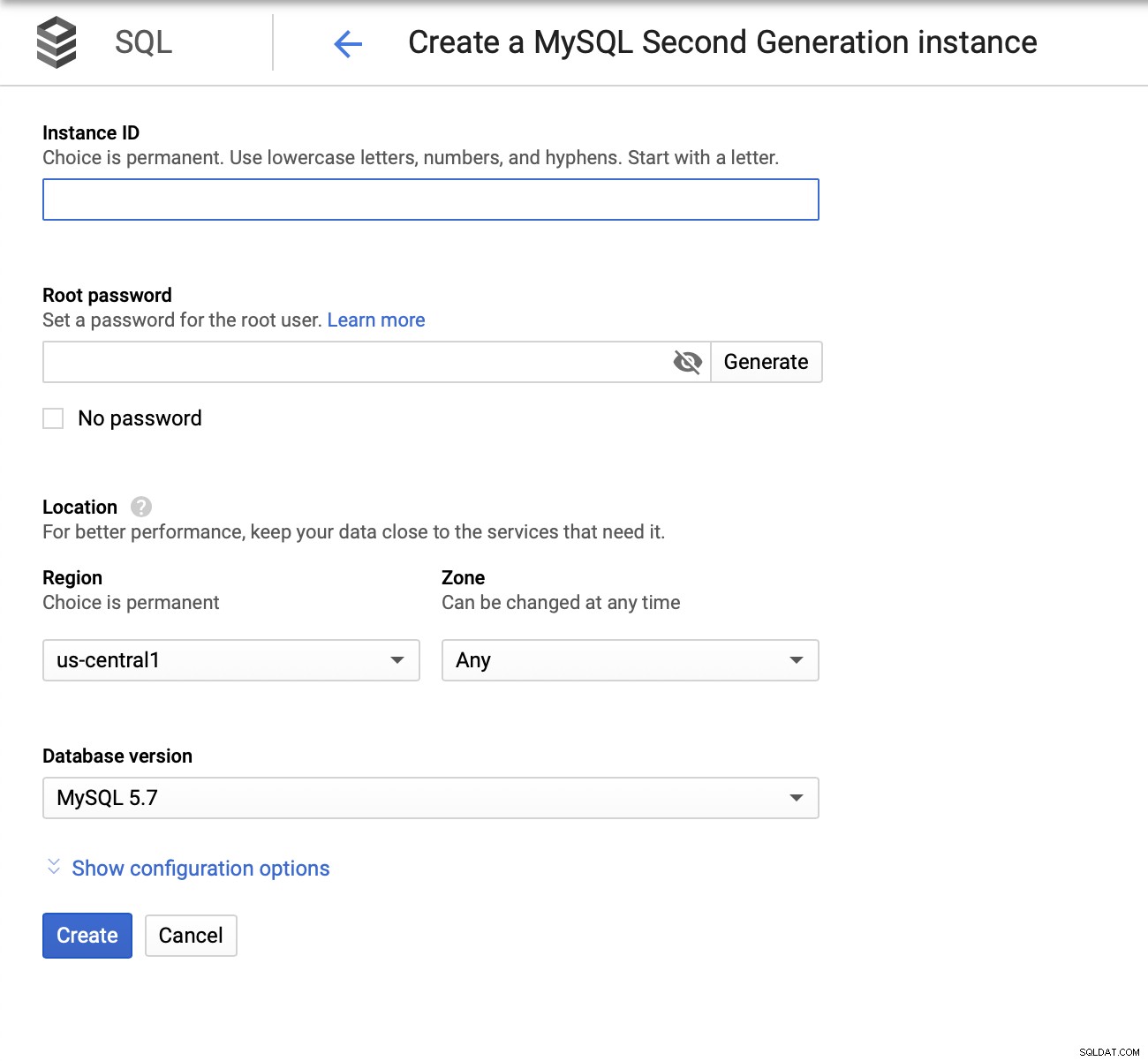
次に、構成オプションを調べます。
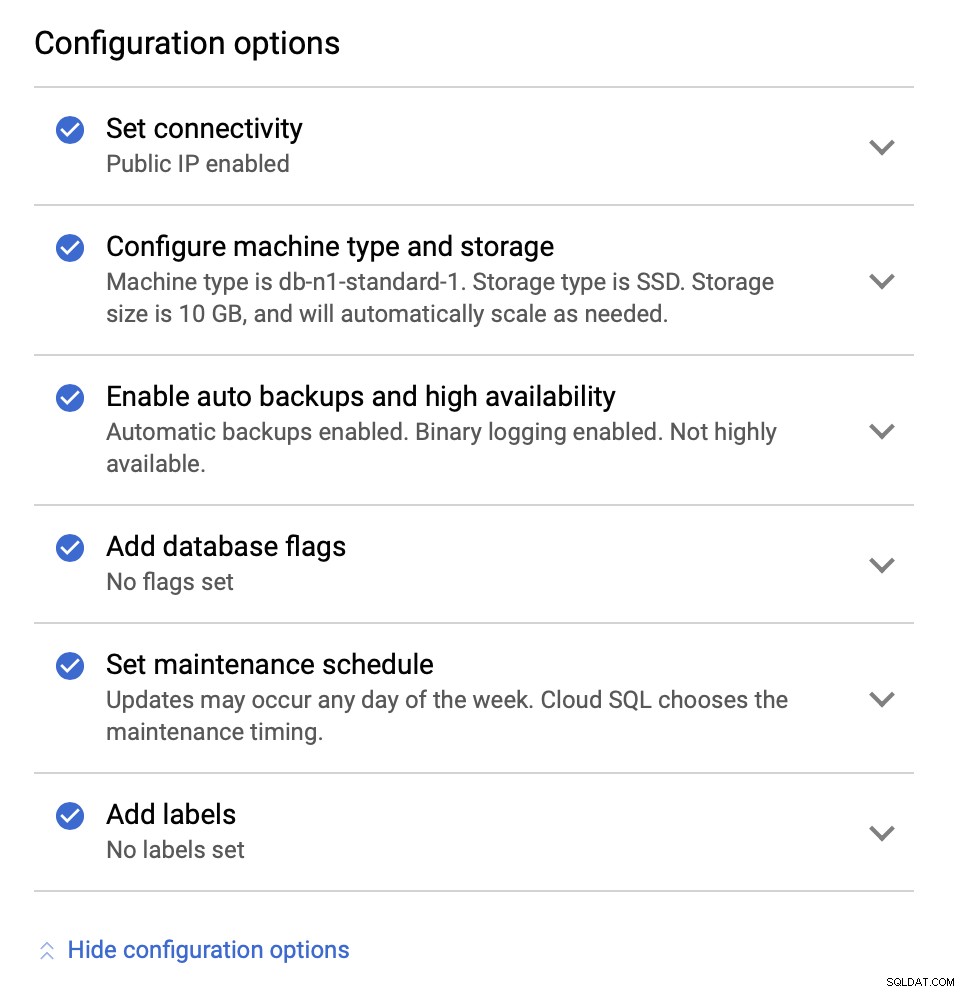
インスタンスサイズを変更できます( db-n1-standard-4)、ストレージ、およびメンテナンススケジュール。この設定で私たちにとって最も重要なのは、高可用性オプションです。
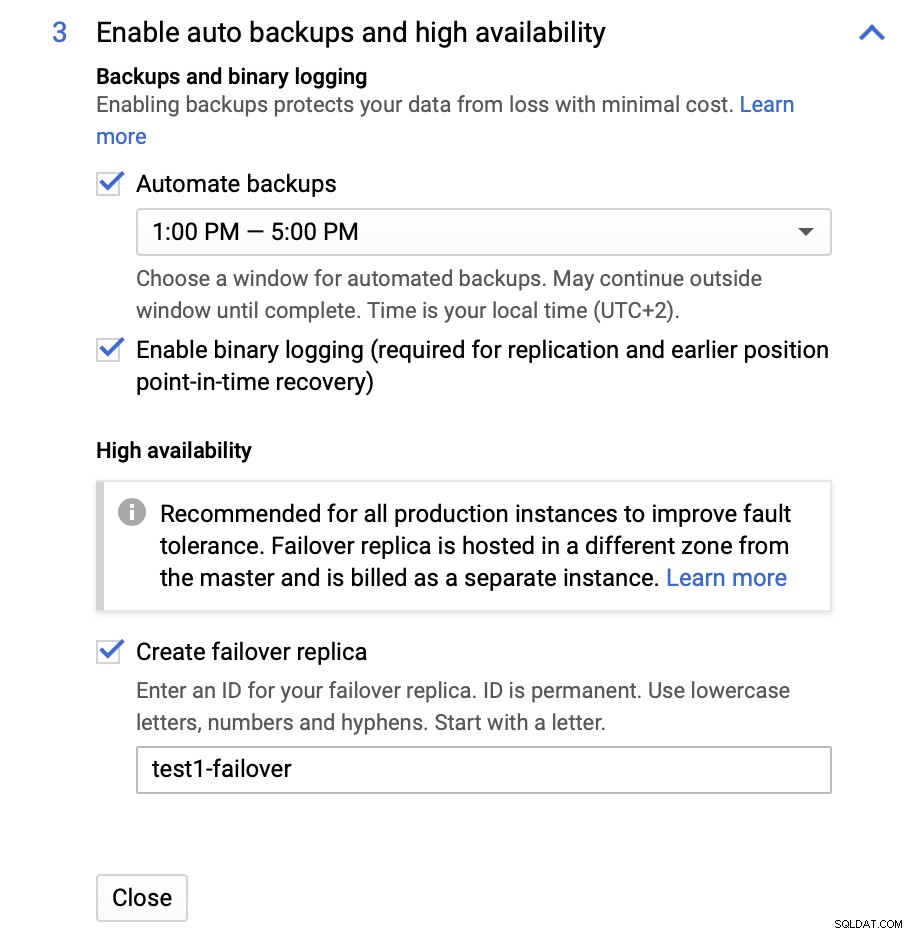
ここで、フェイルオーバーレプリカを作成することを選択できます。元のマスターに障害が発生した場合、このレプリカはマスターにプロモートされます。

セットアップをデプロイした後、レプリケーションスレーブを追加しましょう:
>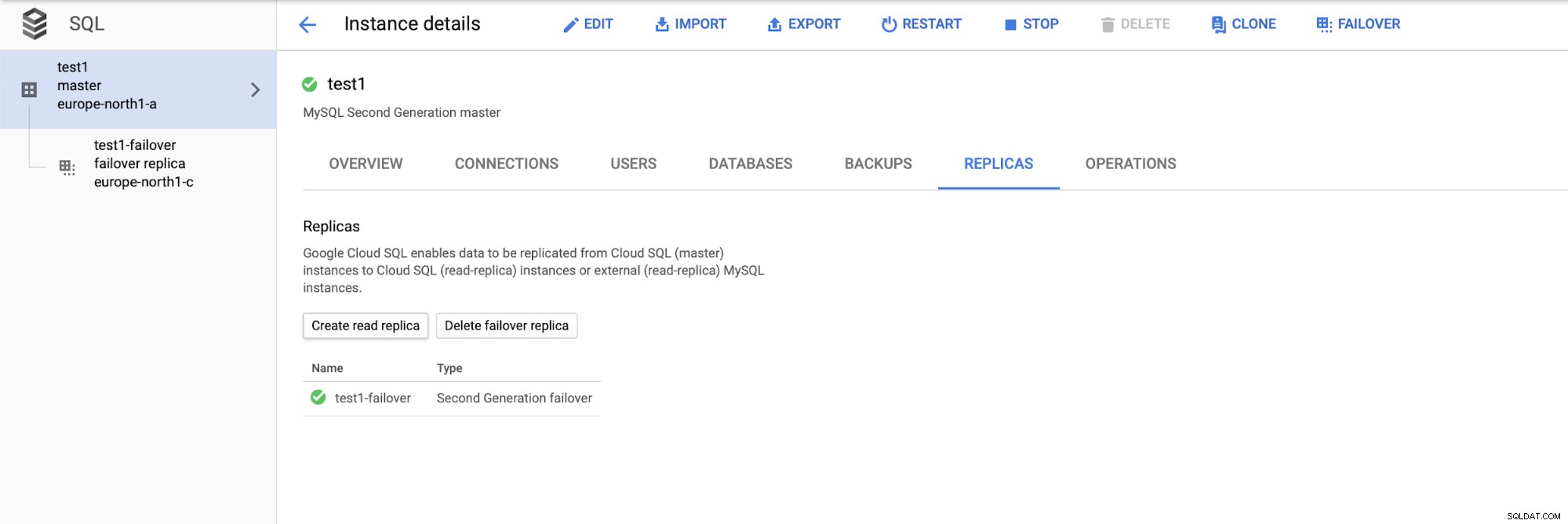
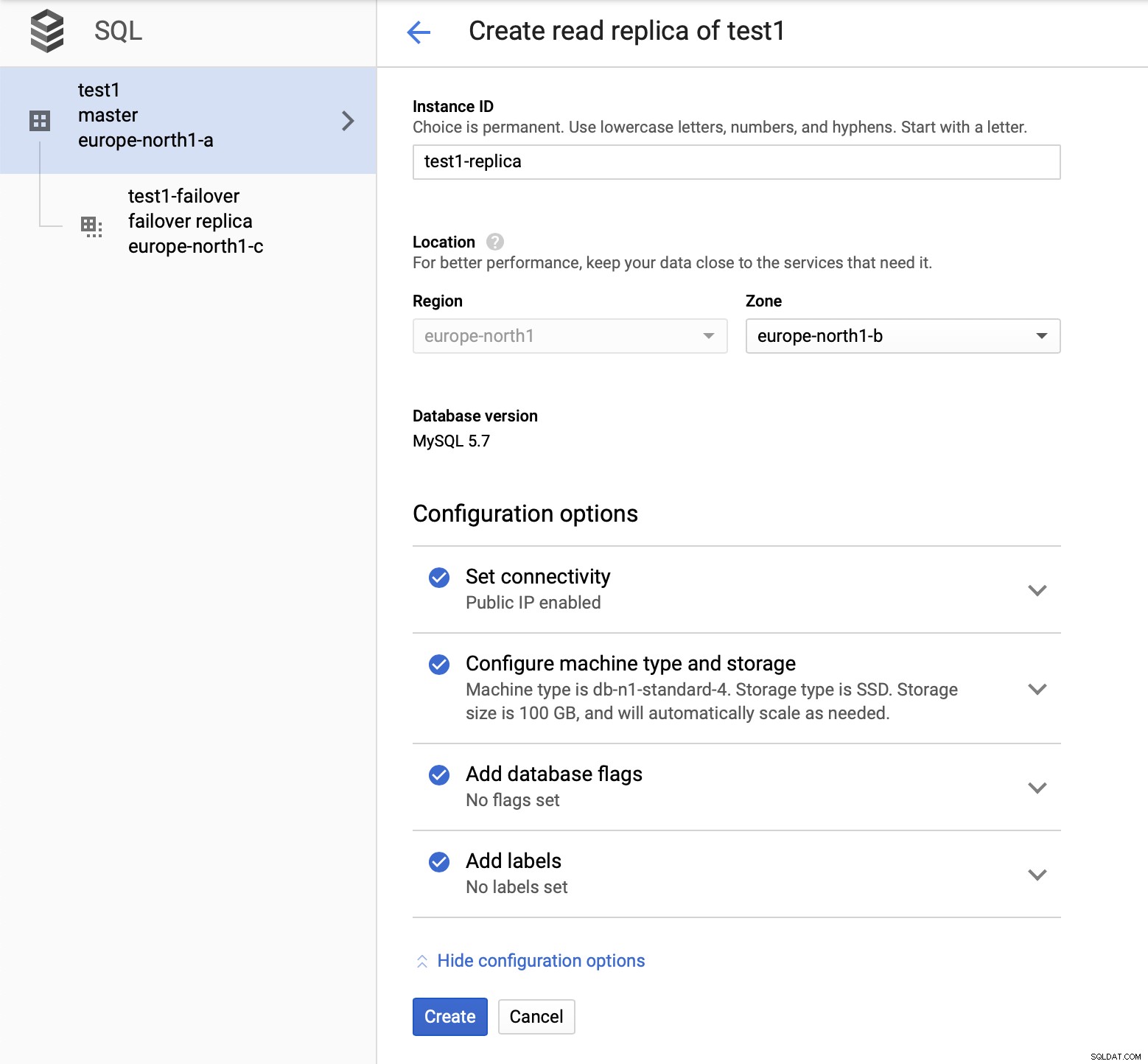
レプリカの追加プロセスが完了すると、準備が整います。テスト。マスター、フェイルオーバーレプリカ、およびリードレプリカでSysbenchを使用してテストワークロードを実行し、これがどのように機能するかを確認します。 3つのタイプのノードすべてのエンドポイントを使用して、Sysbenchの3つのインスタンスを実行します。
次に、UIを介して手動フェイルオーバーをトリガーします:
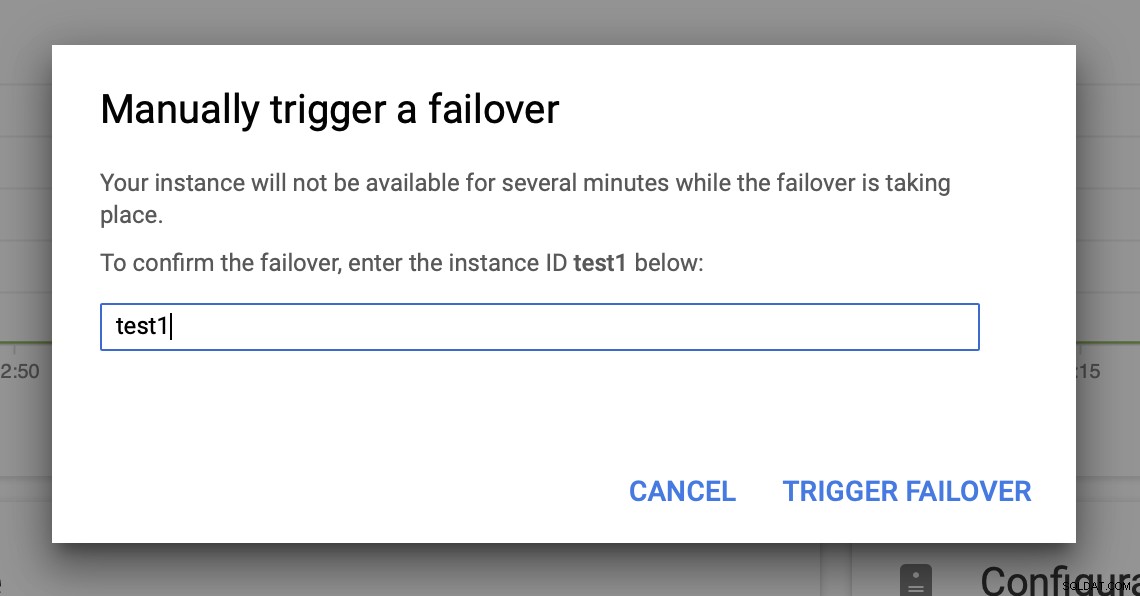
Google Cloud PlatformでMySQLフェイルオーバーをテストしますか?
GCPのSQLノードがどのように機能するかについての詳細な知識がなくても、この時点に到達しました。ただし、以前のMySQLの経験と、他のクラウドプロバイダーで見たものに基づいて、私はいくつかの期待を持っていました。手始めに、フェイルオーバーノードへのフェイルオーバーは非常に高速である必要があります。再構築を必要とせずに、レプリケーションスレーブを使用可能な状態に保つことが必要です。また、フェイルオーバーを2回目に実行する速度も確認したいと思います(問題がデータベース間で伝播することは珍しくありません)。
- フェイルオーバー中に、マスターは75〜80秒で再び利用可能になりました。
- フェイルオーバーレプリカは5〜6分間利用できませんでした。
- リードレプリカはフェイルオーバープロセス中に使用可能でしたが、フェイルオーバーレプリカが使用可能になってから55〜60秒間使用できなくなりました
フェイルオーバーレプリカが利用できない場合はどうなりますか?時間に基づいて、フェイルオーバーレプリカが再構築されているように見えます。これは理にかなっていますが、リカバリ時間はインスタンスのサイズ(特にI / Oパフォーマンス)とデータファイルのサイズに強く関係します。
フェイルオーバーレプリカが再構築された後、読み取りレプリカはどうなりますか?元々、リードレプリカはマスターに接続されていました。マスターに障害が発生すると、リードレプリカがデータセットの古いビューを提供することが期待されます。新しいマスターが表示されたら、レプリケーションを介してインスタンス(以前はフェールオーバーレプリカであり、マスターにプロモートされていた)に再接続する必要があります。 CHANGEMASTERの実行中に1分間のダウンタイムは必要ありません。
さらに重要なことは、フェイルオーバープロセス中に、別のフェイルオーバーを実行する方法がないことです(これは一種の意味があります):
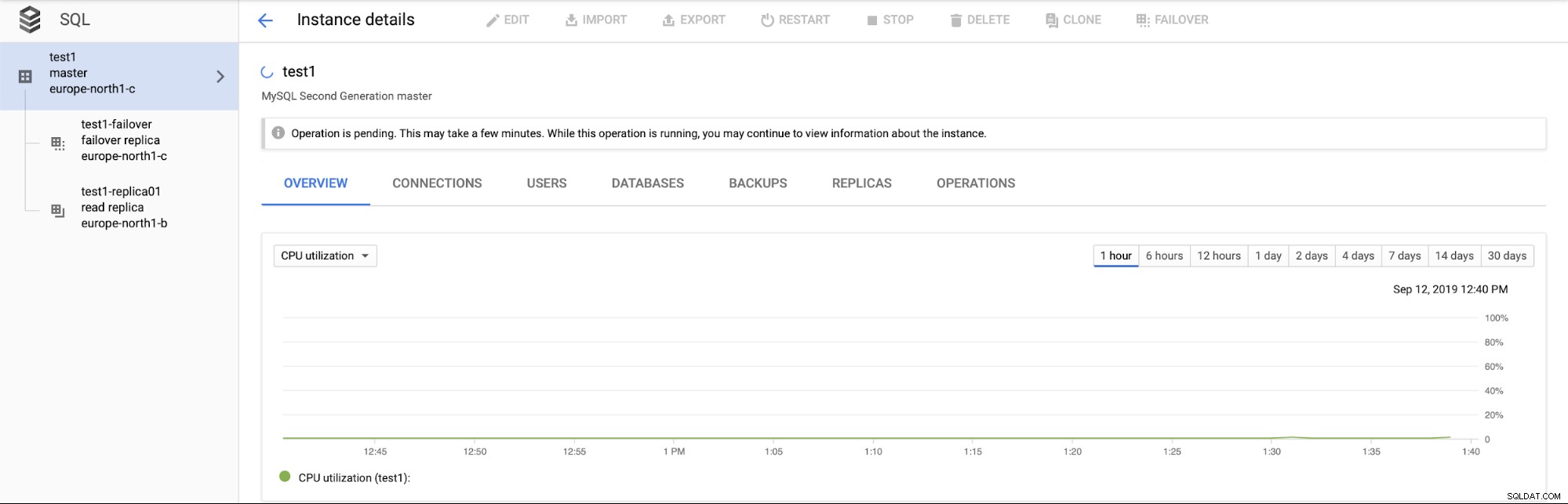
リードレプリカをプロモートすることもできません(必ずしも意味がありません)。 -リードレプリカをいつでもプロモートできると期待しています。

高可用性を提供するために、読み取りレプリカに依存していることに注意することが重要です。 (フェイルオーバーレプリカを作成せずに)実行可能なソリューションではありません。リードレプリカをマスターに昇格させることはできますが、新しいクラスターが作成されます。残りのノードから切り離されました。
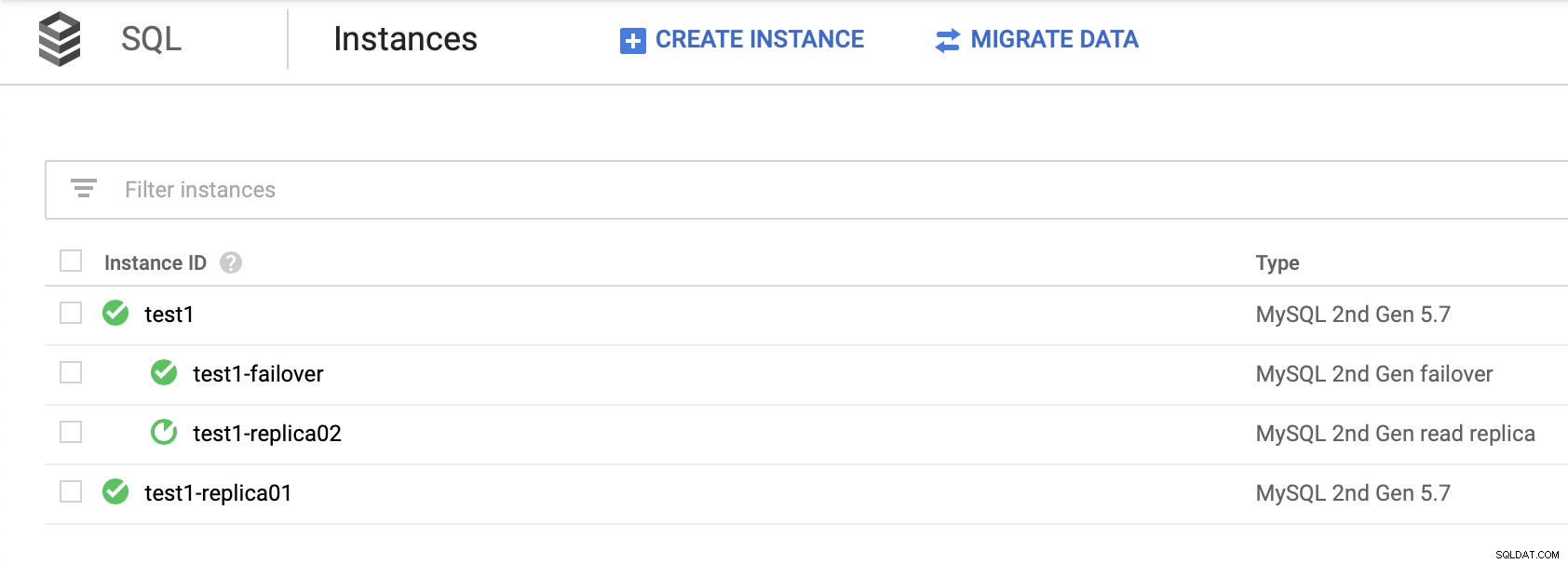
他のレプリカを新しいクラスターからスレーブ化する方法はありません。これを行う唯一の方法は、新しいレプリカを作成することですが、これは時間のかかるプロセスです。また、事実上使用できないため、フェールオーバーレプリカは、GoogleCloudPlatformのSQLノードの高可用性を実現するための唯一の現実的なオプションになります。
GCPでSQLノードの高可用性環境を作成することは可能ですが、マスターは約1分半の間利用できません。プロセス全体(フェールオーバーレプリカの再構築とリードレプリカに対するいくつかのアクションを含む)には、数分かかりました。その間、追加のフェイルオーバーをトリガーすることも、リードレプリカをプロモートすることもできませんでした。
GCPユーザーはいますか?どのようにして高可用性を実現していますか?