以前、Google Cloud Platform(GCP)でのMySQLフェイルオーバーとフェイルバックの実現について説明したブログを投稿しました。このブログでは、ライバルであるAmazon Relational Database Service(RDS)がフェイルオーバーをどのように処理するかを見ていきます。また、以前のマスターノードのフェールバックを実行して、マスターとしての元の順序に戻す方法についても説明します。
マネージドリレーショナルデータベースサービスをサポートするハイテクジャイアントパブリッククラウドを比較すると、Amazonは(MySQL / MariaDB、PostgreSQL、Oracle、SQL Serverとともに)代替オプションを提供する唯一のオプションです。 AmazonAuroraと呼ばれる独自の種類のデータベース管理。 Auroraに慣れていない人にとっては、MySQLおよびPostgreSQLと互換性のあるフルマネージドのリレーショナルデータベースエンジンです。 Auroraは、マネージドデータベースサービスであるAmazon RDSの一部です。これは、クラウドでのリレーショナルデータベースのセットアップ、操作、スケーリングを容易にするWebサービスです。
フェイルオーバーまたはフェイルバックが必要な理由
フォールトトレラントで可用性が高く、単一障害点(SPOF)のない大規模なシステムを設計するには、問題が発生したときにどのように反応するかを判断するための適切なテストが必要です。
システムの障害検出、分離、および回復(FDIR)に応答するときにシステムがどのように動作するかが心配な場合は、フェイルオーバーとフェイルバックが非常に重要になります。
AmazonRDSでのデータベースフェイルオーバー
フェイルオーバーは自動的に発生します(手動フェイルオーバーはスイッチオーバーと呼ばれるため)。以前のブログで説明したように、現在のデータベースマスターでネットワーク障害が発生したり、ホストシステムが異常終了したりすると、フェイルオーバーが必要になります。フェイルオーバーは、冗長性の安定した状態、またはスタンバイコンピューターサーバー、システム、ハードウェアコンポーネント、またはネットワークに切り替えます。
Amazon RDSでは、これを行う必要はありません。また、RDSはマネージドデータベースサービスであるため、自分で監視する必要もありません(つまり、Amazonがジョブを処理します)。このサービスは、ハードウェアの問題、バックアップとリカバリ、ソフトウェアの更新、ストレージのアップグレード、さらにはソフトウェアのパッチ適用などを管理します。これについては、このブログの後半で説明します。
AmazonRDSでのデータベースフェイルバック
前のブログでは、フェイルバックが必要な理由についても説明しました。一般的な複製環境では、特にワークロード要件が高い場合、マスターは大きな負荷を運ぶのに十分強力である必要があります。マスターセットアップには、書き込みの処理、レプリケーションイベントの生成、重要な読み取りの処理などを安定した方法で実行できるようにするための適切なハードウェア仕様が必要です。ディザスタリカバリ中(またはメンテナンス)にフェイルオーバーが必要な場合、新しいマスターを昇格させるときに劣ったハードウェアを使用する可能性があることは珍しくありません。この状況は一時的には問題ないかもしれませんが、長期的には、正常であると見なされた後(またはメンテナンスが完了した後)に、指定されたマスターを元に戻してレプリケーションを主導する必要があります。
フェイルオーバーとは異なり、フェイルバック操作は通常、スイッチオーバーを使用して制御された環境で発生します。パニックモードではめったに行われません。このアプローチにより、エンジニアは慎重に計画を立て、演習をリハーサルしてスムーズに移行できるようになります。その主な目的は、古き良きマスターを最新の状態に戻し、レプリケーション設定を元のトポロジに復元することです。 Amazon RDSを扱っているので、これらのタイプの問題について過度に心配する必要はありません。これは、ほとんどのジョブがAmazonによって処理されるマネージドサービスだからです。
Amazon RDSはデータベースフェイルオーバーをどのように処理しますか?
Amazon RDSノードをデプロイする場合、データベースクラスターをマルチアベイラビリティーゾーン(AZ)またはシングルアベイラビリティーゾーンにセットアップできます。フェイルオーバーがどのように処理されているかをそれぞれ確認してみましょう。
マルチAZセットアップとは何ですか?
データベースインスタンスが影響を受ける計画外の停止や自然災害などの大災害や災害が発生すると、AmazonRDSは自動的に別のアベイラビリティーゾーンのスタンバイレプリカに切り替わります。このAZは通常、データセンターの別のブランチにあり、インスタンスが配置されている現在のアベイラビリティーゾーンから遠く離れていることがよくあります。これらのAZは、データベースインスタンスを保護する高可用性の最先端の機能です。フェイルオーバー時間は、セットアップの完了に依存します。これは、多くの場合、データベースのサイズとアクティビティ、およびプライマリDBインスタンスが使用できなくなったときに存在したその他の条件に基づいています。
フェイルオーバー時間は通常60〜120秒です。ただし、大規模なトランザクションや長いリカバリプロセスによりフェイルオーバー時間が長くなる可能性があるため、これらは長くなる可能性があります。フェイルオーバーが完了すると、RDSコンソール(UI)が新しいアベイラビリティーゾーンを反映するまでにさらに時間がかかる場合があります。
シングルAZセットアップとは何ですか?
シングルAZセットアップは、RTO(目標復旧時間)とRPO(目標復旧時点)が十分に高い場合にのみ、データベースインスタンスに使用する必要があります。シングルAZの使用には、業務に支障をきたす可能性のある大きなダウンタイムなどのリスクがあります。
ダウンタイムの量は、障害の種類によって異なります。これらが何であるか、およびインスタンスの回復がどのように処理されるかを見てみましょう。
Amazon RDSインスタンスの障害は、基盤となるEC2インスタンスに障害が発生した場合に発生します。発生すると、AWSはイベント通知をトリガーし、AmazonRDSイベント通知を使用してアラートを送信します。このシステムは、アラートプロセッサとしてAWS Simple Notification Service(SNS)を使用します。
RDSは、同じアベイラビリティーゾーンで新しいインスタンスを自動的に起動し、EBSボリュームを接続して、リカバリを試みます。このシナリオでは、RTOは通常30分未満です。 EBSボリュームを回復できたため、RPOはゼロです。 EBSボリュームは単一のアベイラビリティーゾーンにあり、このタイプのリカバリは元のインスタンスと同じアベイラビリティーゾーンで発生します。
RDSインスタンスのリカバリが失敗した場合(または基盤となるEBSボリュームでデータ損失が発生した場合)、ポイントインタイムリカバリ(PITR)が必要です。 PITRはAmazonによって自動的に処理されないため、(AWS Lambdaを使用して)自動化するスクリプトを作成するか、手動で実行する必要があります。
RTOのタイミングでは、新しいAmazon RDSインスタンスを起動する必要があります。このインスタンスは、作成されると新しいDNS名を持ち、最後のバックアップ以降のすべての変更を適用します。
RPOは通常5分ですが、RDS:describe-db-instances:LatestRestorableTimeを呼び出すことで見つけることができます。時間は、適用する必要のあるログの数に応じて、10分から数時間まで変化する可能性があります。これは、データベースのサイズ、最後のバックアップ以降に行われた変更の数、およびデータベースのワークロードレベルに依存するため、テストによってのみ決定できます。バックアップとトランザクションログはAmazonS3に保存されるため、このリカバリは、リージョン内でサポートされている任意のアベイラビリティーゾーンで発生する可能性があります。
新しいインスタンスが作成されたら、クライアントのエンドポイント名を更新する必要があります。古いDBインスタンスのエンドポイント名に名前を変更するオプションもありますが(ただし、失敗した古いインスタンスを削除する必要があります)、問題の根本原因を特定することは不可能です。
アベイラビリティーゾーンの中断は一時的なものであり、まれですが、AZの障害がより永続的な場合、インスタンスは障害状態に設定されます。リカバリは前述のように機能し、ポイントインタイムリカバリを使用して別のAZで新しいインスタンスを作成できます。この手順は、手動またはスクリプトで実行する必要があります。このタイプのリカバリシナリオの戦略は、より大規模なディザスタリカバリ(DR)計画の一部である必要があります。
アベイラビリティーゾーンの障害が一時的なものである場合、データベースはダウンしますが、使用可能な状態のままになります。このタイプのシナリオを検出するには、アプリケーションレベルの監視(Amazonまたはサードパーティのツールを使用)を行う必要があります。これが発生した場合は、アベイラビリティーゾーンが回復するのを待つか、ポイントインタイムリカバリを使用してインスタンスを別のアベイラビリティーゾーンに回復することを選択できます。
RTOは、新しいRDSインスタンスを起動し、最後のバックアップ以降のすべての変更を適用するのにかかる時間です。アベイラビリティーゾーンの障害が発生するまで、RPOは長くなる可能性があります。
AmazonRDSでのフェイルオーバーとフェイルバックのテスト
DB.r4.largeを使用してAmazonRDSAuroraを作成し、セットアップしました。マルチAZデプロイメント(別のAZにAuroraレプリカ/リーダーを作成します)を使用して、EC2経由でのみアクセスできます。フェイルオーバーメカニズムとしてAmazonRDSを使用する場合は、作成時に必ずこのオプションを選択する必要があります。
RDSインスタンスのプロビジョニング中、約11分かかりましたインスタンスが利用可能になり、アクセス可能になりました。以下は、作成後にRDSで使用可能なノードのスクリーンショットです。
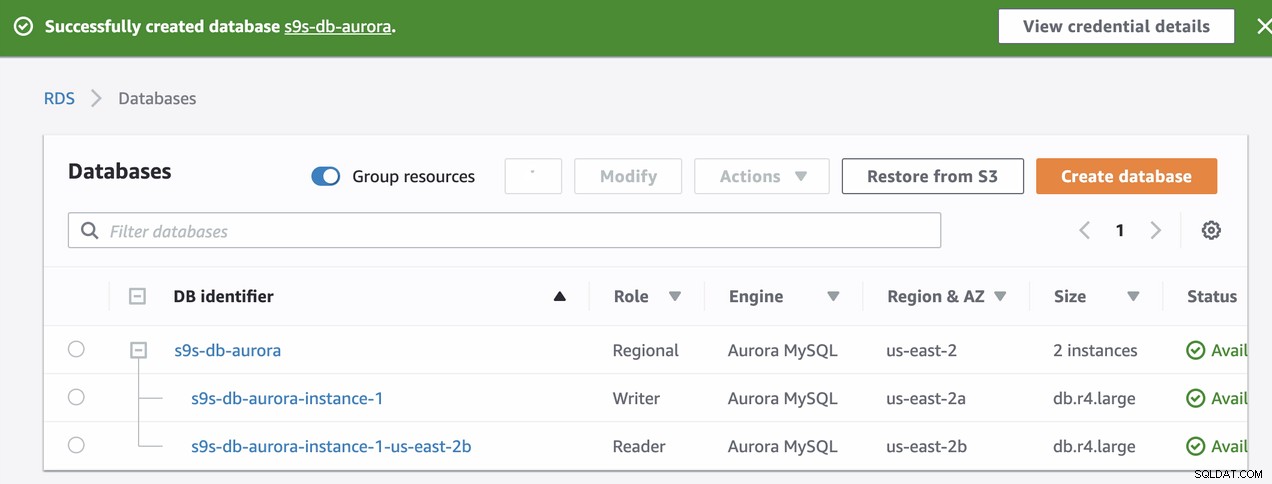
これら2つのノードには、独自の指定されたエンドポイント名があります。クライアントの観点から接続するために使用します。最初に確認し、これらの各ノードの基になるホスト名を確認してください。確認するには、以下のbashコマンドを実行し、それに応じてホスト名/エンドポイント名を置き換えることができます。
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)ここで、クラッシュをシミュレートして、Amazon RDS Auroraライターインスタンスのフェイルオーバーをシミュレートしましょう。これは、エンドポイントs9s-db-aurora.cluster-cmu8qdlvkepg.usを持つs9s-db-aurora-instance-1です。 -east-2.rds.amazonaws.com。
これを行うには、mysqlクライアントコマンドプロンプトを使用してライターインスタンスに接続し、以下の構文を発行します。
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];このコマンドを発行すると、Amazon RDSリカバリが検出され、非常に迅速に機能します。クエリはテストを目的としていますが、実際のイベントでこの発生が発生した場合は異なる場合があります。ドキュメントでインスタンスのクラッシュのテストについて詳しく知りたいと思うかもしれません。以下でどのように終わるかをご覧ください:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)上記のSQLコマンドを実行すると、少なくとも3分間ディスク障害をシミュレートする必要があります。シミュレーションを開始する時点を監視しましたが、フェイルオーバーが開始するまでに約18秒かかりました。
RDSがシミュレーションの失敗とフェイルオーバーを処理する方法については、以下を参照してください
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+- 10:06:29頃、上記のようにシミュレーションクエリの実行を開始しました。
- 10:06:44頃に、エンドポイントs9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.comにホスト名ip-10-20-1-が割り当てられていることが示されています。 139実際には読み取り専用インスタンスですが、シミュレーションコマンドが読み取り/書き込みインスタンスで実行されたにもかかわらず、アクセスできなくなりました。
- 10:06:51頃に、エンドポイントs9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.comにホスト名ip-10-20-1-が割り当てられていることが示されます。 139は稼働していますが、読み取り/書き込み状態としてマークされています。変数innodb_read_onlyは、Aurora MySQL管理対象インスタンスの場合、ホストが読み取り/書き込みノードか読み取り専用ノードかを判別するための識別子であり、AuroraもMySQL互換インスタンスのInnoDBストレージエンジンでのみ実行されることに注意してください。
- 10:07:13頃、順序が変更されました。これは、フェイルオーバーが実行され、インスタンスが指定されたエンドポイントに割り当てられたことを意味します。
RDSコンソールに表示される以下の結果を確認してください。
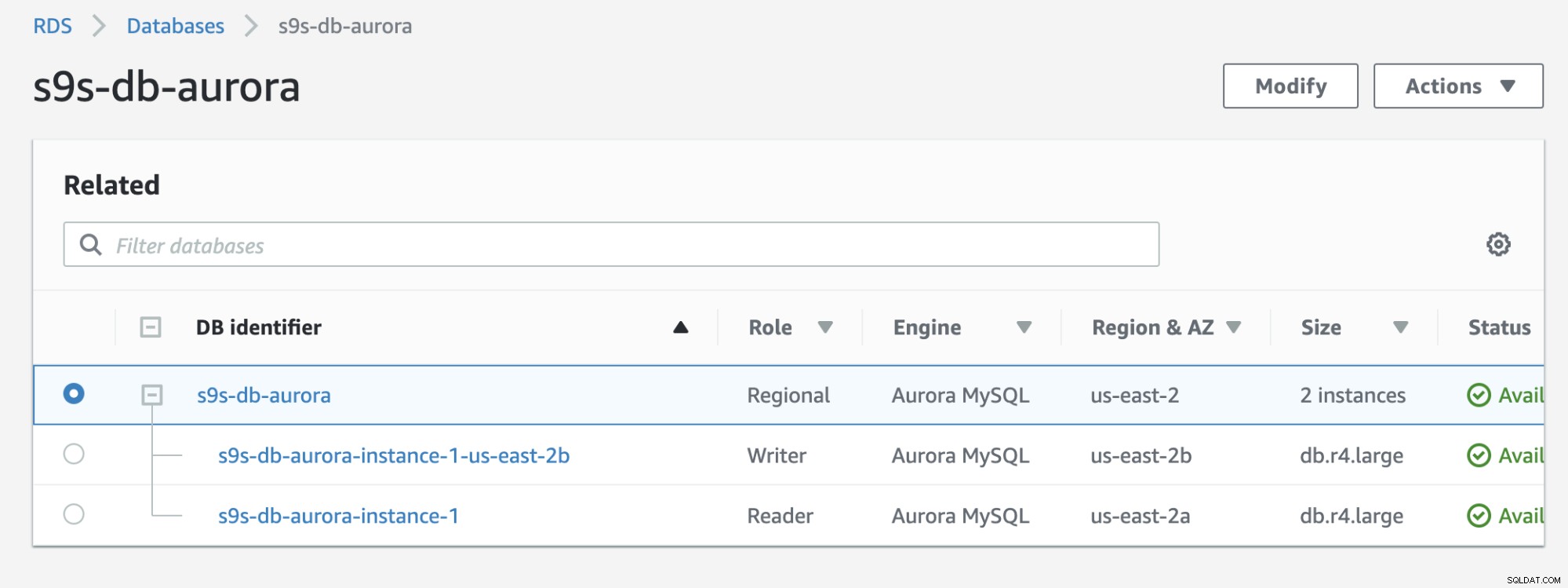
以前のものと比較すると、s9s-db-aurora- instance-1はリーダーでしたが、フェイルオーバー後にライターとして昇格しました。テストを含むプロセスは、タスクを完了するのに約44秒かかりましたが、フェイルオーバーはほぼ30秒で完了したことを示しています。これは、特にこれがマネージドサービスデータベースであることを考えると、フェイルオーバーにとって印象的で高速です。つまり、ハードウェアやメンテナンスの問題について心配する必要はありません。
AmazonRDSでフェイルバックを実行する
AmazonRDSでのフェイルオーバーは非常に簡単です。実行する前に、新しいリーダーレプリカを追加しましょう。 AWS RDSが目的のマスターにフェールバック(または前のマスターにフェールバック)しようとしたときに選択するノードをテストおよび識別し、優先度に基づいて適切なノードを選択するかどうかを確認するオプションが必要です。現在のインスタンスの現在のリストとそのエンドポイントを以下に示します。
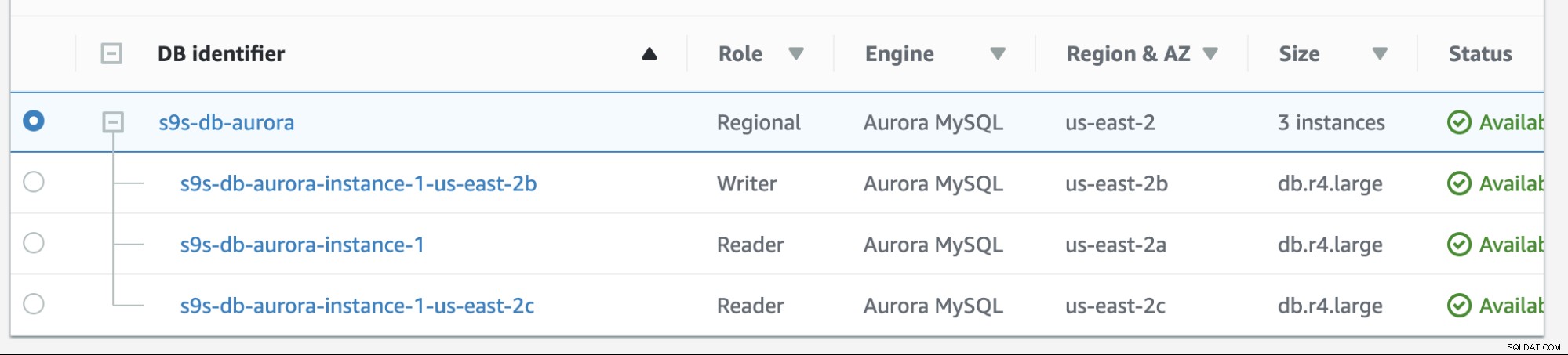

新しいレプリカはus-east-2cAZにあり、dbホスト名が付いていますip-10-20-2-239の。
インスタンスs9s-db-aurora-instance-1を目的のフェールバックターゲットとして使用して、フェイルバックを実行しようとします。この設定では、2つのリーダーインスタンスがあります。フェイルオーバー中に正しいノードが確実に取得されるようにするには、優先度または可用性が最上位であるかどうかを確認する必要があります(ティア0>ティア1>ティア2など、ティア15まで)。これは、インスタンスを変更するか、レプリカの作成中に行うことができます。
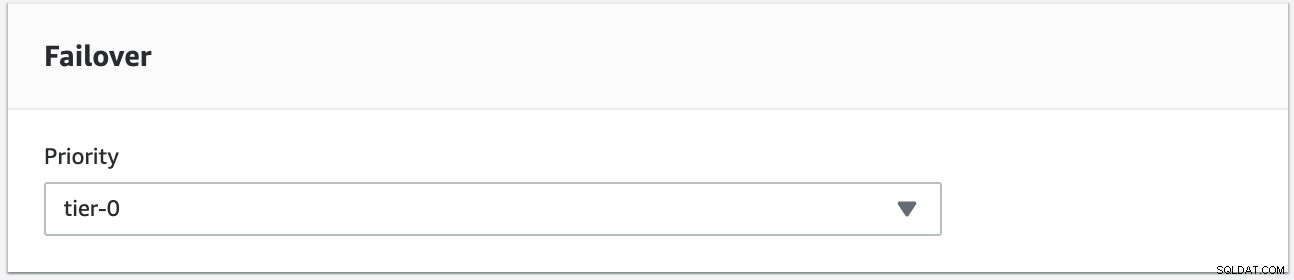
これは、RDSコンソールで確認できます。
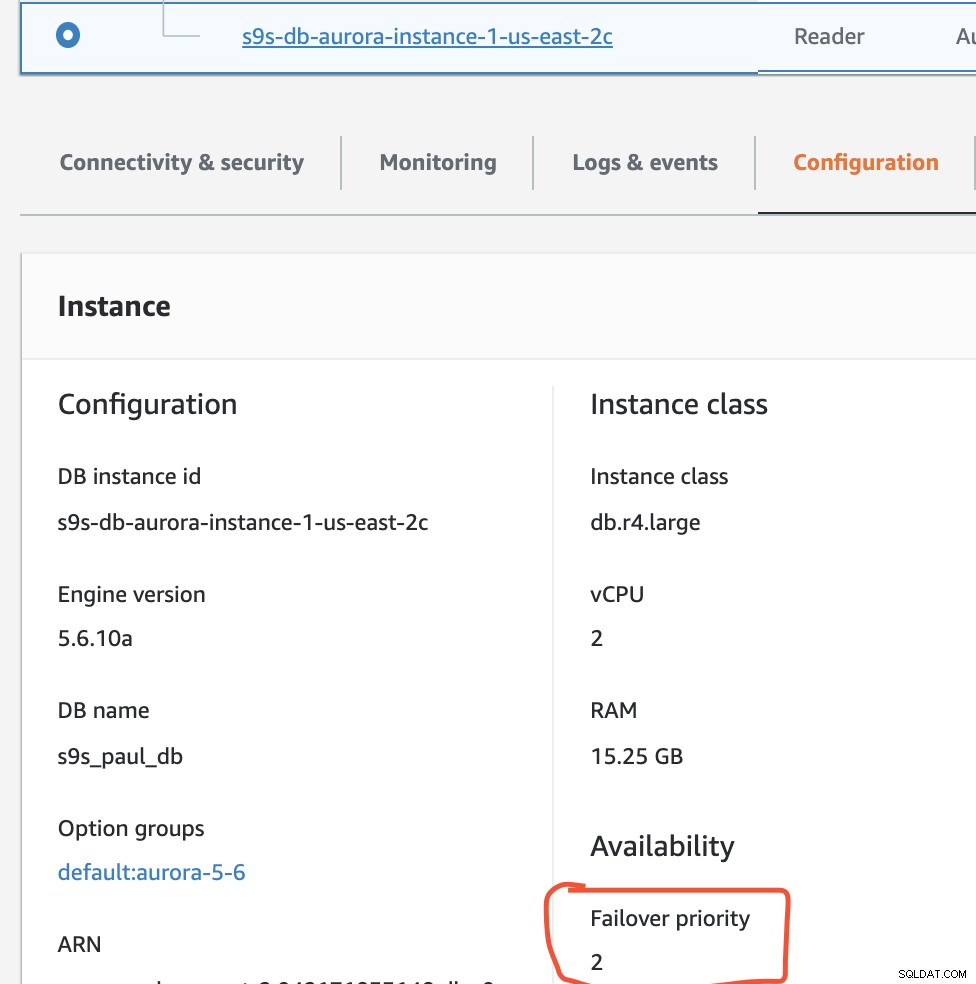
この設定では、s9s-db-aurora-instance-1が優先されます=0(およびリードレプリカ)、s9s-db-aurora-instance-1-us-east-2bの優先度=1(および現在のライター)、およびs9s-db-aurora-instance-1-us- east-2cの優先度は2です(これはリードレプリカでもあります)。フェイルバックしようとするとどうなるか見てみましょう。
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;フェイルオーバーがトリガーされた後、フェイルオーバーは目的のターゲットであるノードs9s-db-aurora-instance-1にフェイルバックします。
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+フェイルバックの試行は13:30:59に開始され、13:31:38(最も近い30秒のマーク)頃に完了しました。このテストでは最終的に約32秒になりますが、それでも高速です。
フェイルオーバー/フェイルバックを複数回検証し、インスタンスs9s-db-aurora-instance-1とs9s-db-aurora-instance-1-の間で読み取り/書き込み状態を一貫して交換しています。 us-east-2b。これにより、両方のノードで問題が発生しない限り、s9s-db-aurora-instance-1-us-east-2cは選択されないままになります(これらはすべて異なるAZに配置されているため、非常にまれです)。
フェイルオーバー/フェイルバックの試行中、RDSは、フェイルオーバー中に約15〜25秒(非常に高速)の急速な移行ペースで進みます。このインスタンスには巨大なデータファイルが保存されていないことを覚えておいてください。ただし、これ以上管理するものがないことを考えると、それでも非常に印象的です。
シングルAZを実行すると、フェイルオーバーを実行するときに危険が生じます。 Amazon RDSを使用すると、シングルAZを変更してマルチAZ対応のセットアップに変換できますが、これにはいくらかのコストがかかります。 RTOとRPOの時間が長くても問題がない場合は、シングルAZで問題ないかもしれませんが、トラフィックが多く、ミッションクリティカルなビジネスアプリケーションには絶対にお勧めしません。
Multi-AZを使用すると、Amazon RDSでフェイルオーバーとフェイルバックを自動化でき、クエリの調整や最適化に時間を費やすことができます。これにより、DevOpsまたはDBAが直面する多くの問題が緩和されます。
Amazon RDSは一部の組織でジレンマを引き起こす可能性がありますが(プラットフォームに依存しないため)、それでも検討する価値があります。特に、アプリケーションで長期のDR計画が必要であり、ハードウェアと容量の計画について心配することに時間を費やす必要がない場合。