オープンソースの学習管理システムであるMoodleは、パンデミックによる強制的な封鎖と教育活動の大部分が学校、大学、大学からオンラインプラットフォームに移行したため、昨年ますます人気が高まりました。これにより、ITチームは、これらのオンラインプラットフォームが以前よりもはるかに高い負荷に対応できるようにするよう圧力をかけられました。疑問が提起されました-増加した負荷を処理するためにMoodleプラットフォームをどのようにスケーリングできますか?一方では、アプリケーション自体のスケーリングは達成するのが難しいことではありませんが、他方では、データベースは別の動物です。データベースは、すべてのステートフルサービスと同様に、スケールアウトが難しいことで有名です。このブログ投稿では、Moodleデータベースをスケーリングするときに直面するいくつかの課題について説明したいと思います。
問題の主な原因は遺産です-多くのデータベースと同様に、Moodleは単一のデータベースの背景から来ているため、そのような環境に関連するいくつかの期待があります。典型的なものは、次々にトランザクションを実行でき、2番目のトランザクションは常に最初のトランザクションの結果を見るというものです。これは、ほとんどの分散データベース環境では必ずしも当てはまりません。非同期レプリケーションは約束をしません。その過程でトランザクションが失われる可能性があります。トランザクションデータがスレーブに転送される前に、マスターがクラッシュするだけで十分です。準同期レプリケーションは、データの安全性を約束しますが、それ以外のことは約束しません。スレーブは依然として遅れている可能性があり、データはリレーログとして永続ストレージに保存され、最終的にはデータセットに適用されますが、それがすでに適用されていることを意味するわけではありません。スレーブにクエリを実行しても、マスターに書き込んだばかりのデータは表示されません。
デフォルトでは、Galeraのようなクラスターでさえ、真の同期レプリケーションは付属していません。ギャップはレプリケーションシステムと比較して大幅に削減されていますが、それでも存在し、前回の書き込み後に実行された即時SELECTでは表示されない場合があります。 SELECTが以前の書き込みとは異なるGaleraノードにルーティングされたためにデータベースに保存したばかりのデータ。
MoodleMySQLデータベースをスケーリングするために使用できるいくつかの回避策があります。手始めに、レプリケーション設定を使用する場合は、Moodleの「安全な読み取り」機能を使用できます。これについては、以前のブログの1つで取り上げました。これにより、Moodleがどの書き込みをスレーブに分散し、どの書き込みをマスターにヒットさせるかを決定する状況になります。
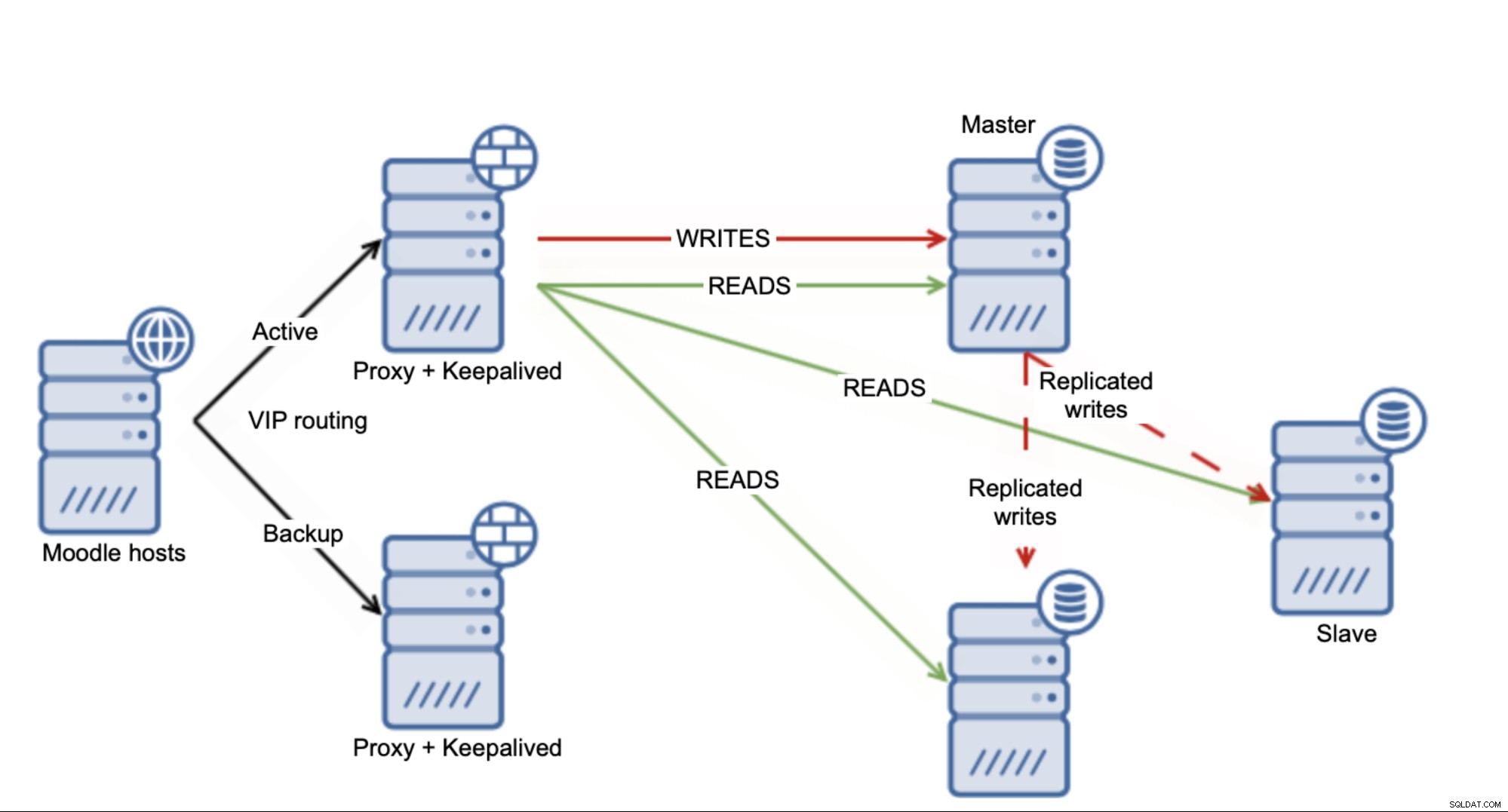
一方で、それは良いことです-接続された複数のスレーブを安全に使用できますマスターに、少なくともある程度マスターをオフロードできるようにします。一方、スレーブに送信できるのはSELECTのサブセットにすぎないため、理想からはほど遠いものです。もちろん、それはすべて正確なケースに依存しますが、マスターが負荷に関してボトルネックのままであることが期待できます。
別のアプローチとして、Galeraクラスターを使用し、すべてのノードに負荷を均等に分散させることができます。
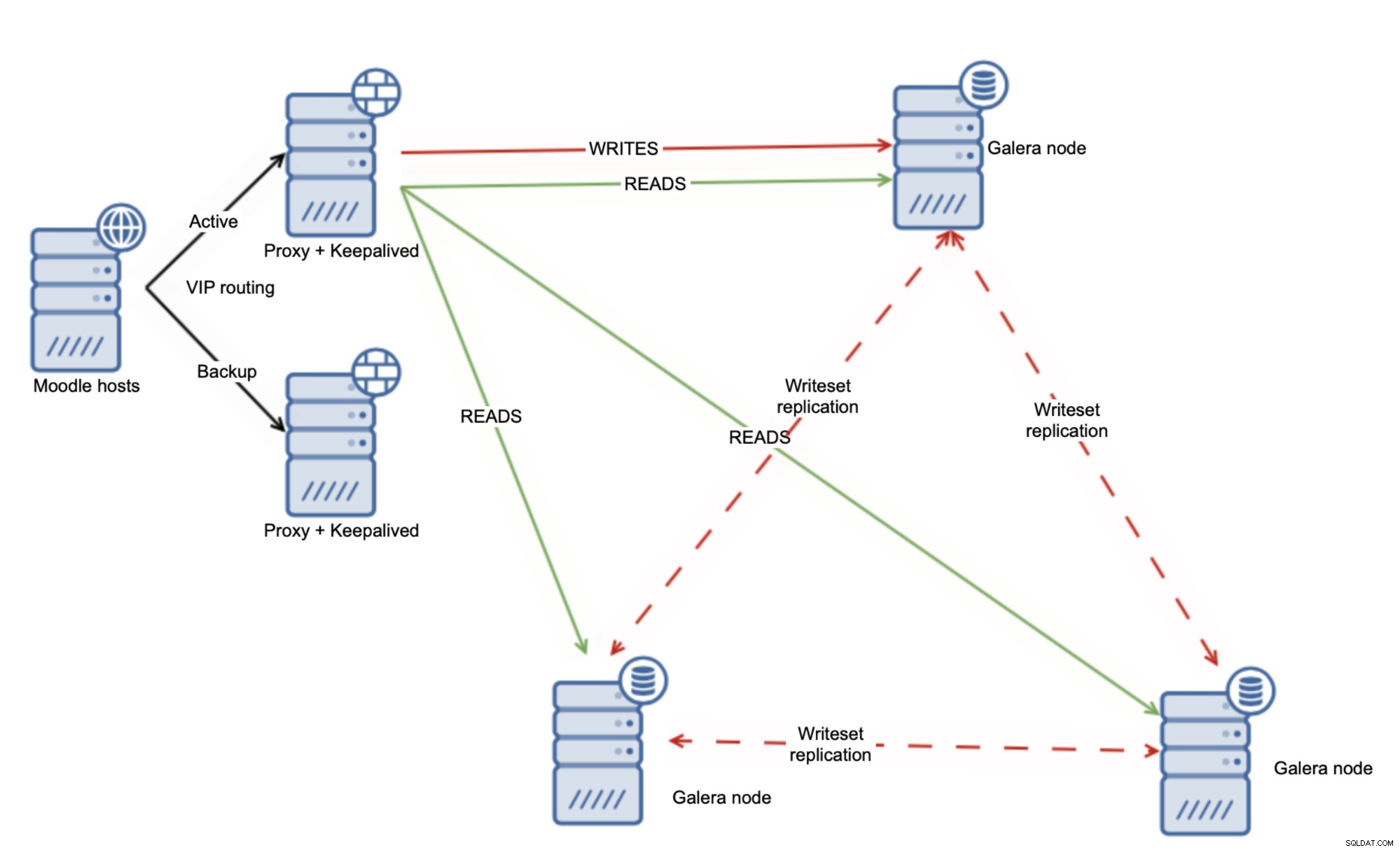
これだけでは、すべての後続を処理するには不十分です。 -書き込みの問題ですが、幸いなことに、wsrep-sync-wait変数を使用して、因果関係チェックが実施され、クラスターが実際の同期クラスターのように動作することを確認できます。この設定を使用すると、すべてのGaleraノードから安全に読み取ることができます。
もちろん、因果関係チェックを実施すると、Galeraのパフォーマンスに影響しますが、複数のGaleraノードから同時に読み取ることでメリットが得られるため、それでも意味があります。その時点から、Galeraクラスターを使用した読み取りのスケーリングは非常に簡単です。クラスターにGaleraノードを追加するだけです。ロードバランサーを再構成して、それらを取得し、読み取りの追加ターゲットとして使用して、10以上のリーダーノードにスケールアウトできるようにする必要があります。
ノード、レプリケーション、またはガレラを追加することは、実際には重要ではなく、クラスターの操作にいくらかの複雑さを追加することを覚えておく必要があります。ノードが適切に監視されていること、バックアップが機能していること、レプリケーションが適切に実行されていること、およびクラスター自体が正しい状態にあることを確認する必要があります。レプリケーション環境では、フェイルオーバーをいずれかの方法で処理する必要があります。Galeraとレプリケーションの両方で、クラスター全体で何らかのデータの不整合を検出した場合に、クラスター内のノードを再構築できるようにする必要があります。幸い、ClusterControlは、これらの課題を処理するのに大いに役立ちます。
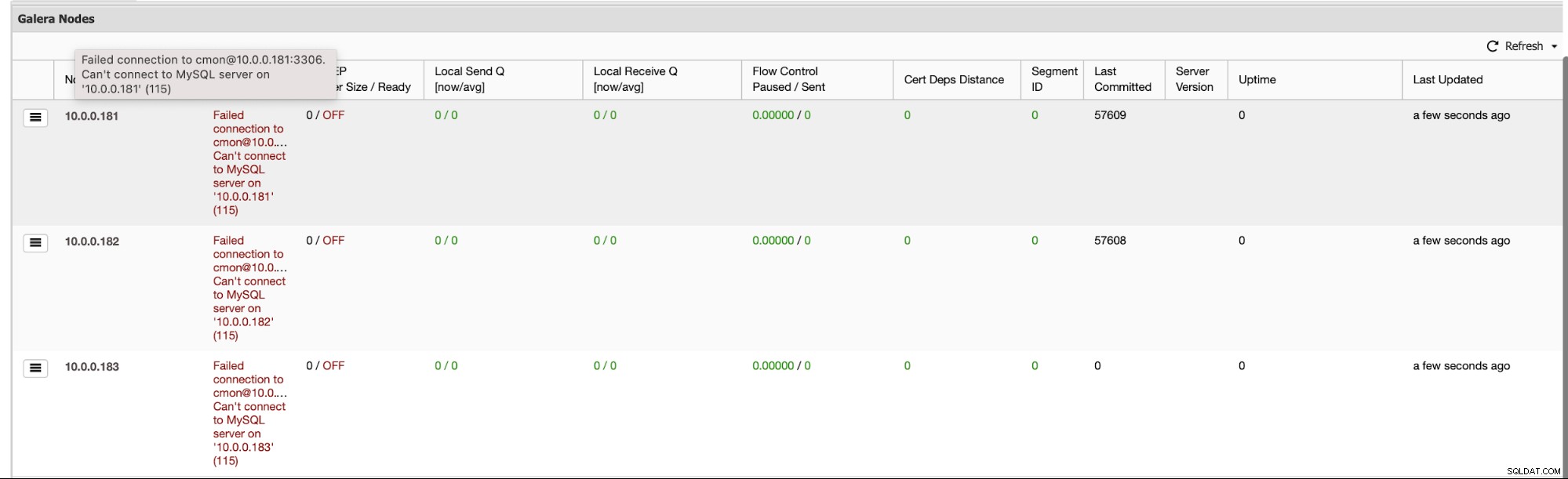
まず、クラスター全体が崩壊した場合、ClusterControlは自動化を実行しますクラスタリカバリ-すべてのノードが使用可能である限り、ClusterControlはクラスタリカバリプロセスを開始します:

しばらくすると、クラスター全体がオンラインに戻るはずです。
ClusterControlには、一連の管理オプションが付属しています:
ノードまたはレプリケーションスレーブを追加することで、クラスターをスケールアウトできます。メインクラスターから複製するスレーブクラスター全体を作成することもできます。
ClusterControlによって実行されるバックアップスケジュールを簡単に設定できます。自動バックアップ検証を設定することもできます。
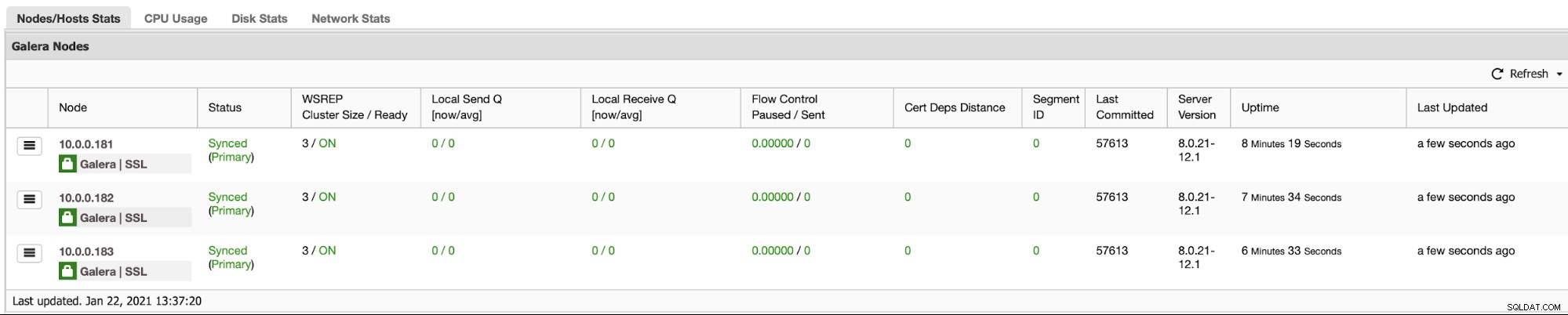
データベースクラスターを監視できるようにしたい場合があります。 ClusterControlを使用すると、まさにそれを行うことができます:
ご覧のとおり、ClusterControlは、MoodleMySQLデータベースのスケーリングと管理の複雑さを軽減するために使用できる優れたプラットフォームです。特にMoodleとそのデータベースをスケールアウトした経験についてお聞かせください。