リリーステストは通常、展開プロセス全体のステップの1つです。コードを記述し、ステージング環境での動作を確認してから、最後に新しいコードを本番環境にデプロイします。データベースはあらゆる種類のアプリケーションの内部にあるため、データベース関連の変更によってアプリケーションがどのように変更されるかを確認することが重要です。いくつかの方法でそれを検証することが可能です。それらの1つは、専用のレプリカを使用することです。それがどのように行われるかを見てみましょう。
明らかに、このプロセスを手動で行う必要はありません。会社のCI/CDプロセスの一部である必要があります。使用している正確なアプリケーション、環境、およびプロセスに応じて、アドホックに作成されたレプリカ、または常にデータベース環境の一部であるレプリカを使用できます。
Galera Clusterが機能する方法は、特定の方法でスキーマの変更を処理することです。クラスタ内の単一ノードでスキーマ変更を実行することは可能ですが、考えられるすべてのスキーマ変更をサポートしているわけではなく、問題が発生した場合に本番環境に影響を与えるため、注意が必要です。このようなノードは、SSTを使用して完全に再構築する必要があります。つまり、残りのGaleraノードの1つがドナーとして機能し、そのすべてのデータをネットワーク経由で転送する必要があります。
別の方法として、レプリカを使用するか、レプリカとして機能する追加のガレラクラスター全体を使用することもできます。明らかに、プロセスを開発パイプラインにプラグインするには、プロセスを自動化する必要があります。これを行うには多くの方法があります。スクリプト、またはAnsible、Chef、Puppet、Saltスタックなどの多数のインフラストラクチャオーケストレーションツールです。詳細については説明しませんが、プロセス全体が適切に機能するために必要な手順を示していただきたいと思います。実装はいずれかのツールに任せます。
まず、新しいデータベースを簡単に展開できるようにする必要があります。最近のデータを使用してプロビジョニングする必要があります。これはさまざまな方法で実行できます。データを本番データベースからテストサーバーにコピーできます。それが最も簡単なことです。または、最新のバックアップを使用することもできます。このようなアプローチには、バックアップの復元をテストするという追加の利点があります。バックアップの検証は、あらゆる種類の深刻な展開で必須であり、テストセットアップの再構築は、復元プロセスが機能することを再確認するための優れた方法です。また、復元プロセスの時間を計るのにも役立ちます。バックアップの復元にかかる時間を知ることは、災害復旧シナリオの状況を正しく評価するのに役立ちます。
データベースにデータがプロビジョニングされたら、そのノードをプライマリクラスターのレプリカとして設定することをお勧めします。それには長所と短所があります。スタンドアロンノードへのすべてのトラフィックを再実行できれば、それは完璧です。そのような場合、レプリケーションを設定する必要はありません。 ProxySQLなどの一部のロードバランサーでは、トラフィックをミラーリングして、そのコピーを別の場所に送信できます。一方、レプリケーションは次善の策です。はい、そのノードで直接書き込みを実行することはできません。これにより、クエリを再実行する方法を計画する必要があります。これは、単に応答するという最も単純なアプローチでは機能しないためです。一方、すべての書き込みは最終的にSQLスレッドを介して実行されるため、SELECTクエリの処理方法を計画するだけで済みます。
正確な変更に応じて、スキーマ変更プロセスをテストすることをお勧めします。スキーマの変更は非常に一般的に実行され、データベースのパフォーマンスに深刻な影響を与える可能性があります。したがって、本番環境に適用する前に、それらを検証することが重要です。変更の実行に必要な時間を調べて、変更をノードに個別に適用できるかどうか、またはトポロジ全体で同時に変更を実行する必要があるかどうかを確認します。これにより、特定のスキーマ変更に使用する必要があるプロセスがわかります。
ClusterControlを使用したリリーステストの自動化の改善
ClusterControlには、リリーステストの自動化に役立つ一連の機能が付属しています。それが提供するものを見てみましょう。明確にするために、これから紹介する機能はいくつかの方法で利用できます。最も簡単な方法はUIを使用することですが、自動化を考えている場合は、何をしたいのかは不要です。これを行うには、さらに2つの方法があります。ClusterControlへのコマンドラインインターフェイスとRPCAPIです。どちらの場合も、ジョブは外部スクリプトからトリガーできるため、既存のCI/CDプロセスにプラグインできます。また、クラスターのデプロイは、手動でセットアップするのではなく、1つのコマンドを実行するだけで済むため、時間を大幅に節約できます。
何よりもまず、ClusterControlには、新しいクラスターをデプロイし、既存のデータベースのデータを使用してプロビジョニングするオプションがあります。この機能だけで、ステージングサーバーのプロビジョニングを簡単に実装できます。
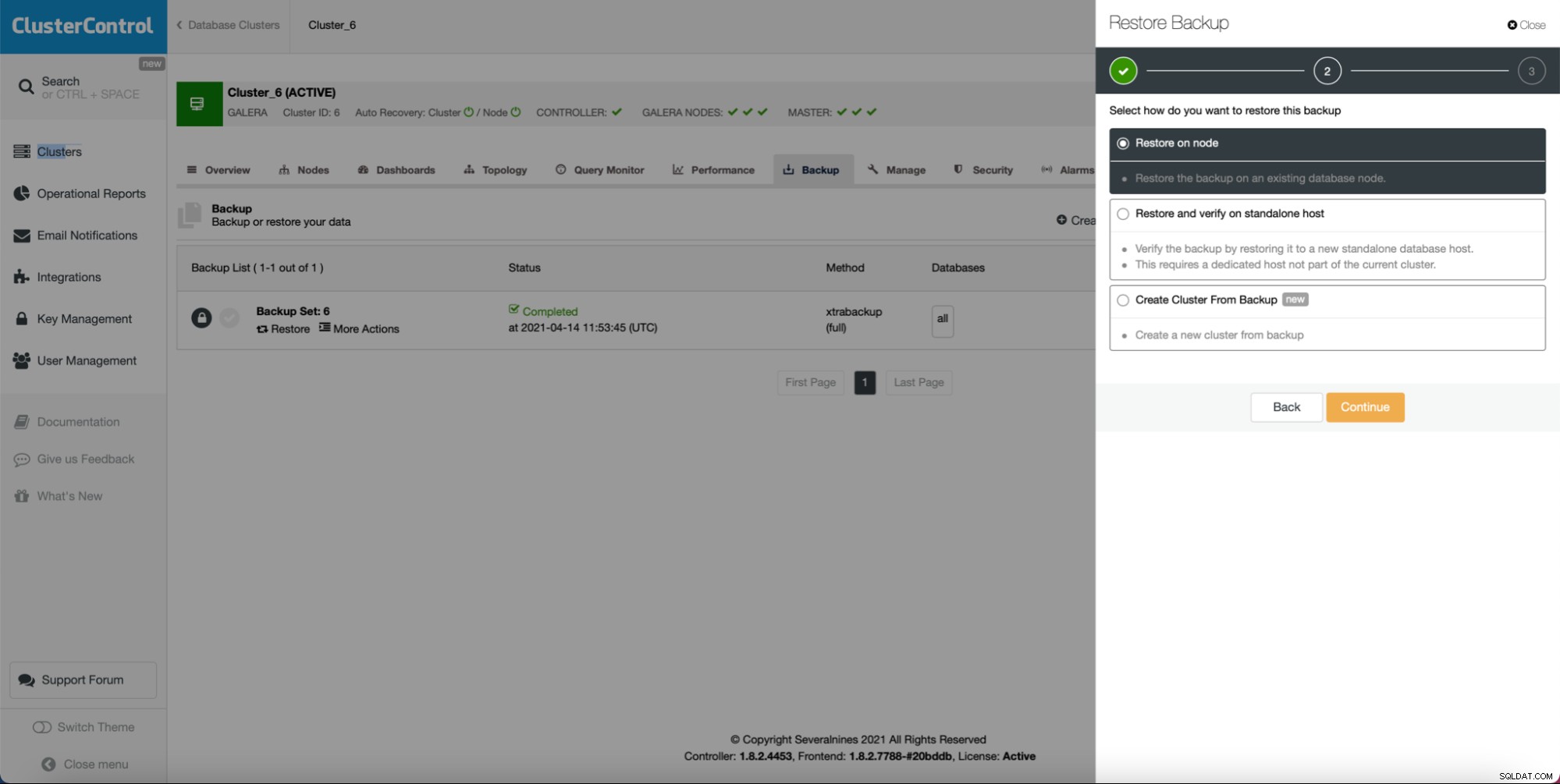
ご覧のとおり、バックアップが作成されている限り、新しいクラスターを作成し、バックアップのデータを使用してプロビジョニングできます:
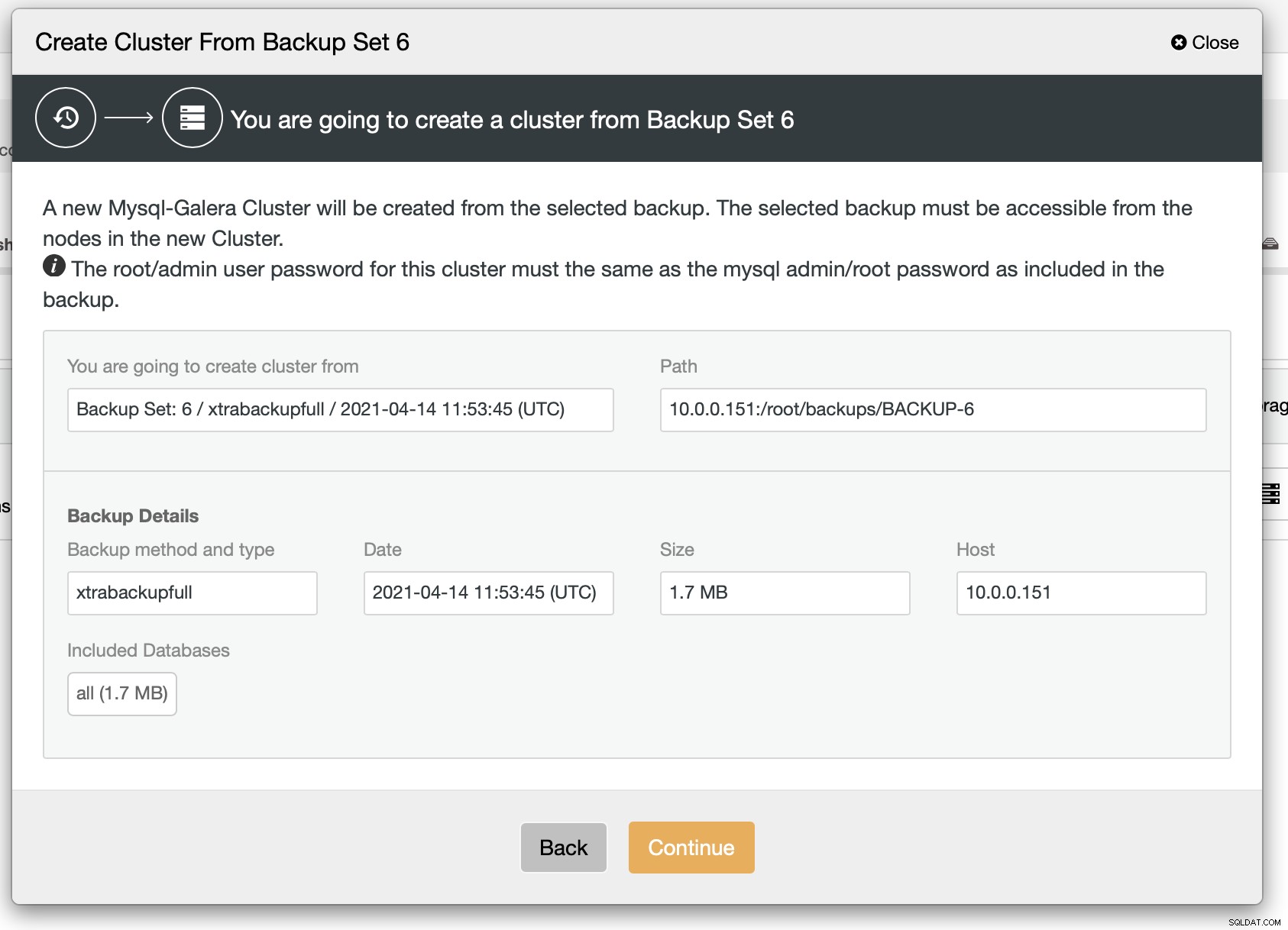
ご覧のとおり、何が起こるかについての簡単な要約があります。 [続行]をクリックすると、さらに先に進みます。
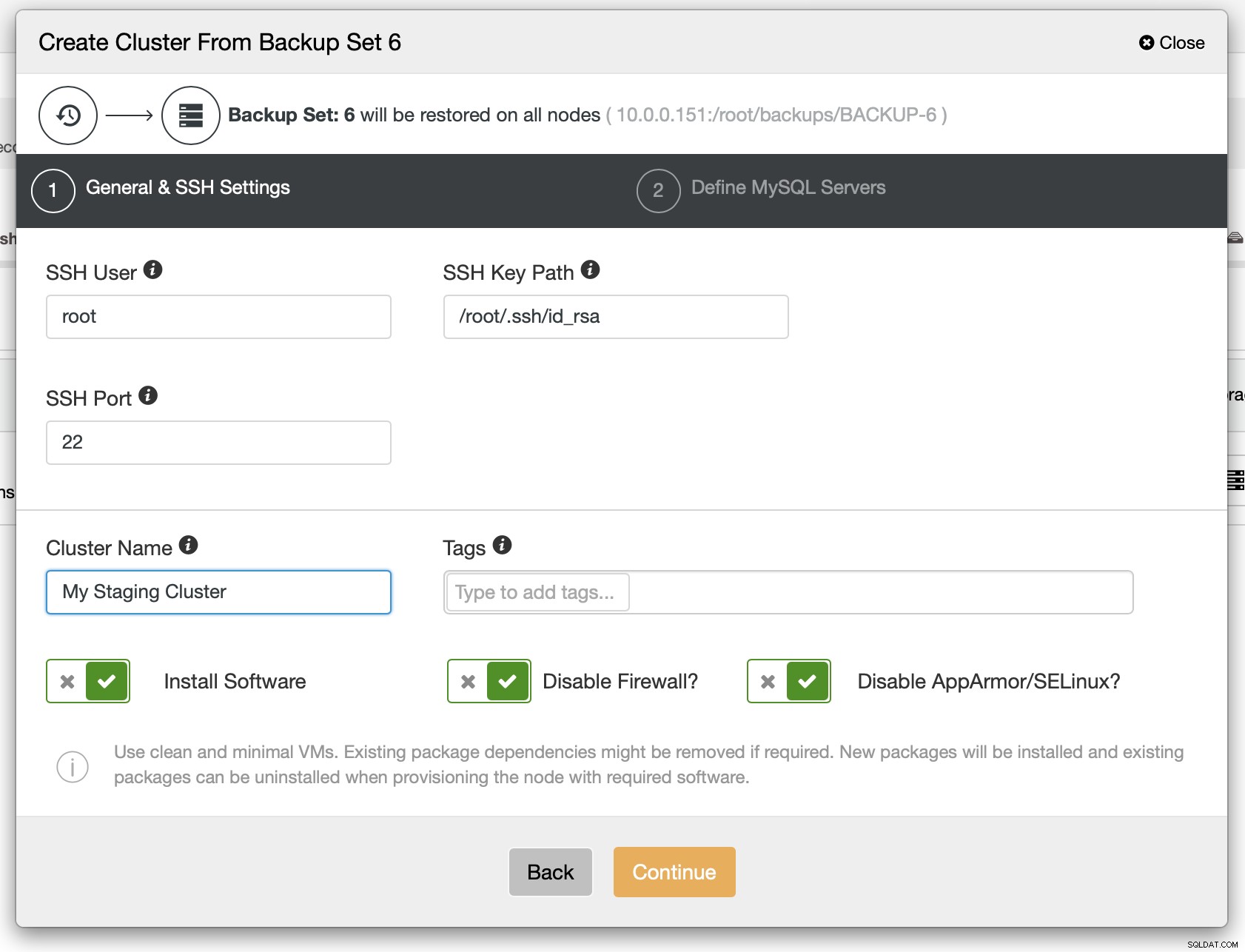
次のステップとして、SSH接続を定義する必要があります。ClusterControlがノードをデプロイする前にSSH接続を設定する必要があります。
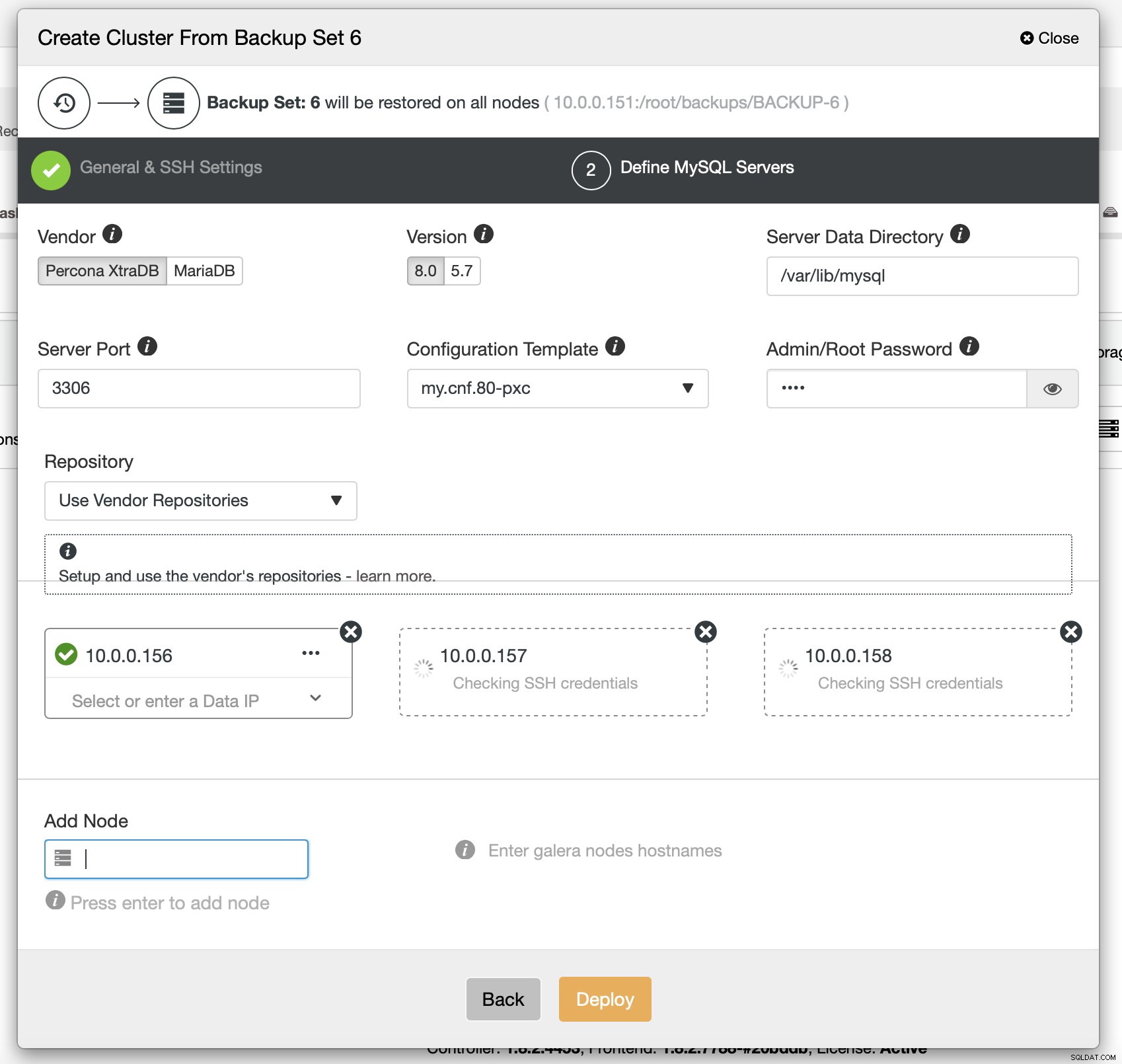
最後に、クラスターで使用するノードのベンダー、バージョン、およびホスト名を(とりわけ)選択する必要があります。それだけです。
s9s cluster --create --cluster-type=galera --nodes="10.0.0.156;10.0.0.157;10.0.0.158" --vendor=percona --cluster-name=PXC --provider-version=8.0 --os-user=root --os-key-file=/root/.ssh/id_rsa --backup-id=6クラスターがデプロイされている場合は、本番トラフィックをクラスターに送信して、新しいスキーマが既存のトラフィックをどのように処理するかを確認することができます。これを行う1つの方法は、ProxySQLを使用することです。
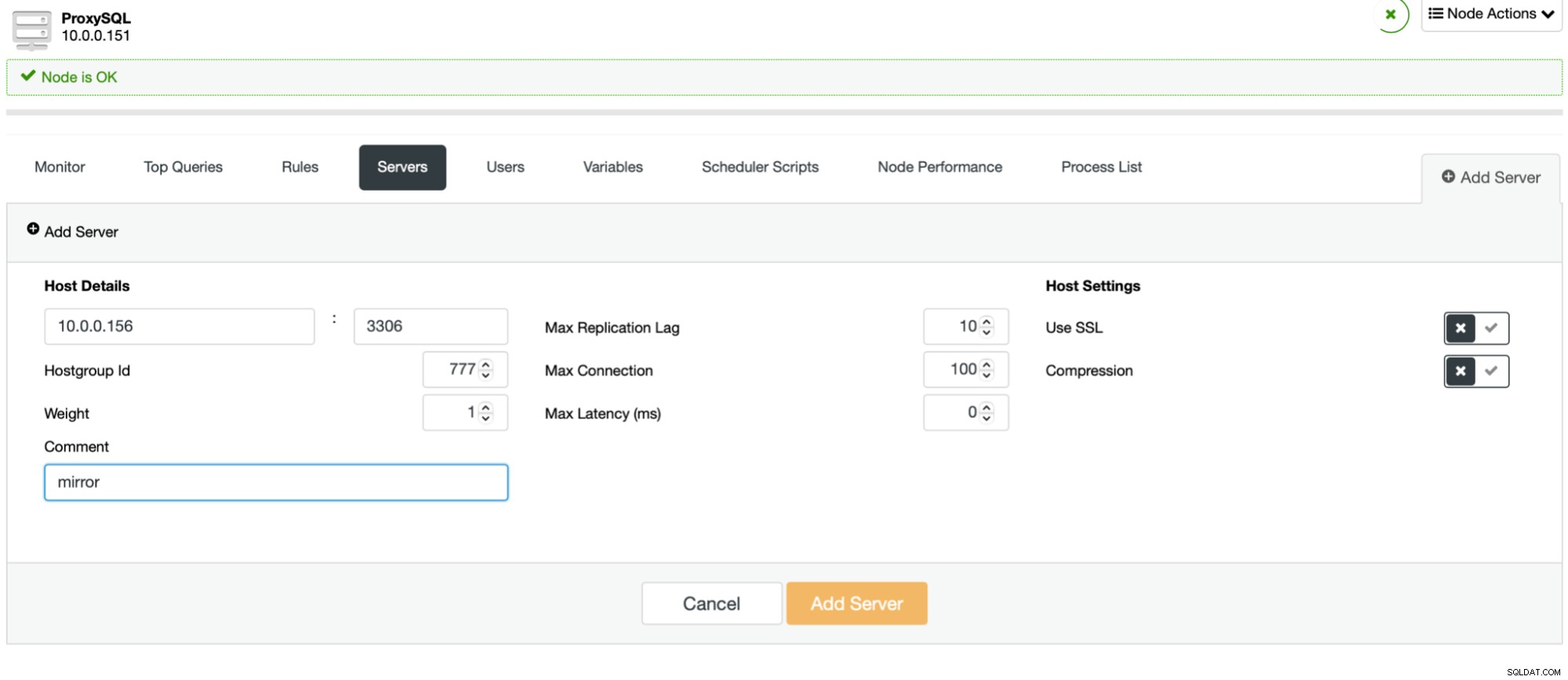
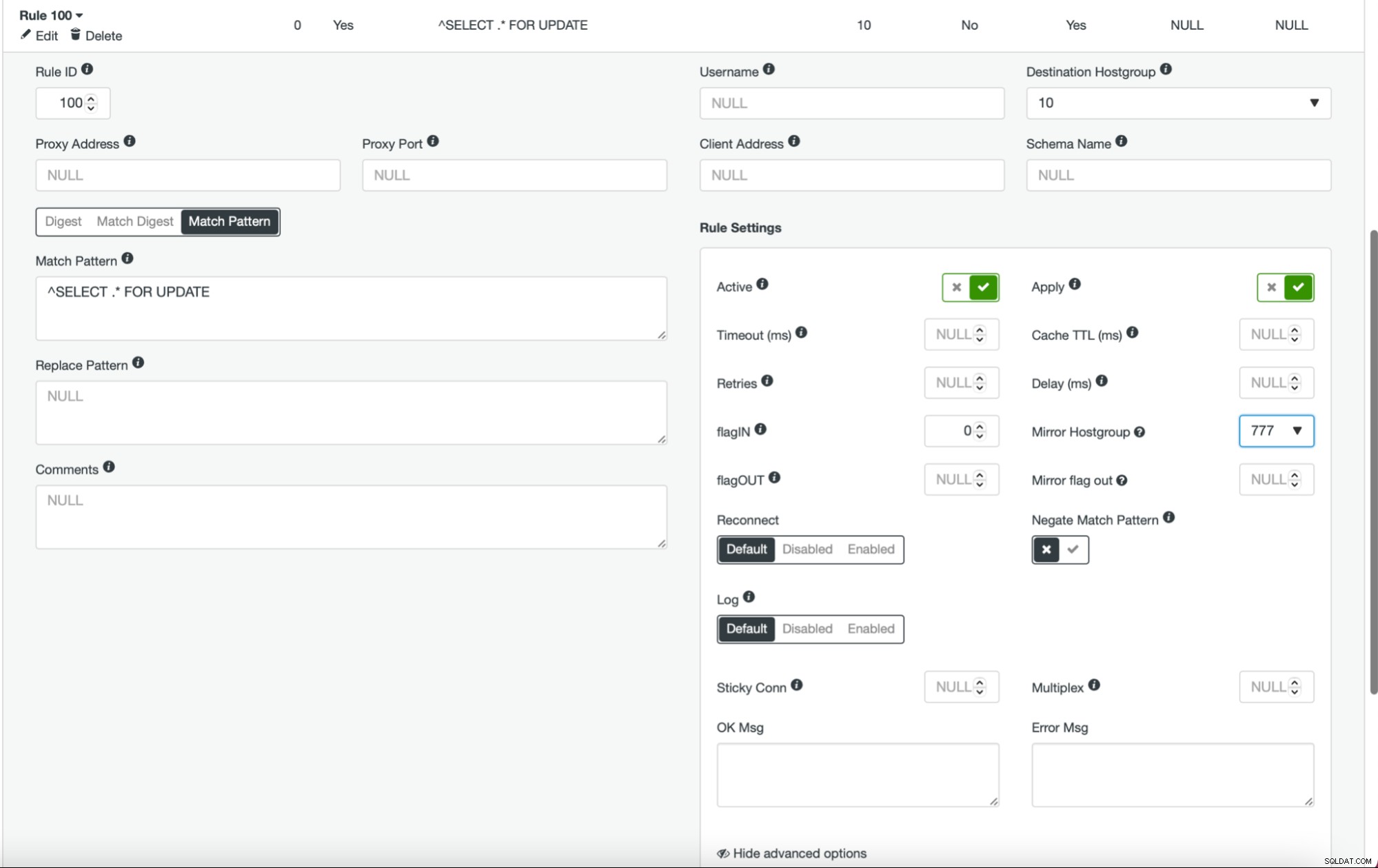
これが完了し、すべて(または一部)のノードがホストグループに構成されたら、クエリルールを編集して、ミラーホストグループを定義できます(詳細オプションで使用できます)。すべてのトラフィックに対してこれを実行する場合は、この方法ですべてのクエリルールを編集することをお勧めします。 SELECTクエリのみをミラーリングする場合は、適切なクエリルールを編集する必要があります。これが完了すると、ステージングクラスターは本番トラフィックの受信を開始するはずです。
前に説明したように、別の解決策は、既存のセットアップのレプリカとして機能する新しいクラスターを作成することです。このようなアプローチでは、レプリケーションを使用して、すべての書き込みを自動的にテストできます。 SELECTは、上記で説明したアプローチ(ProxySQLを介したミラーリング)を使用してテストできます。
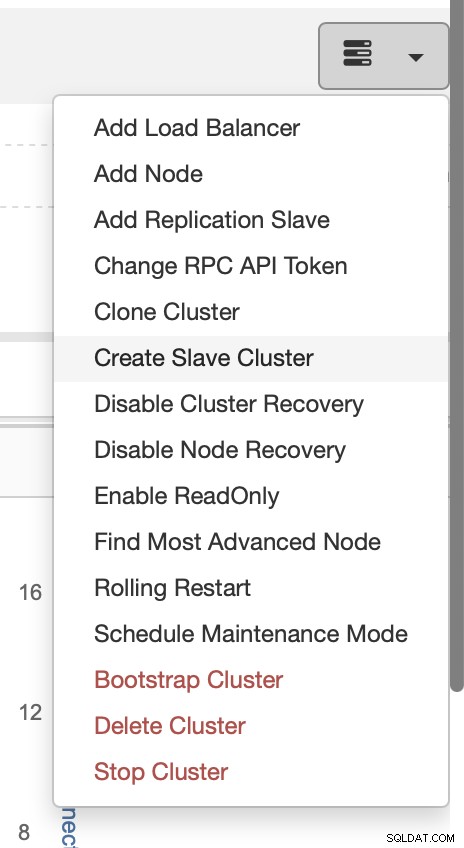
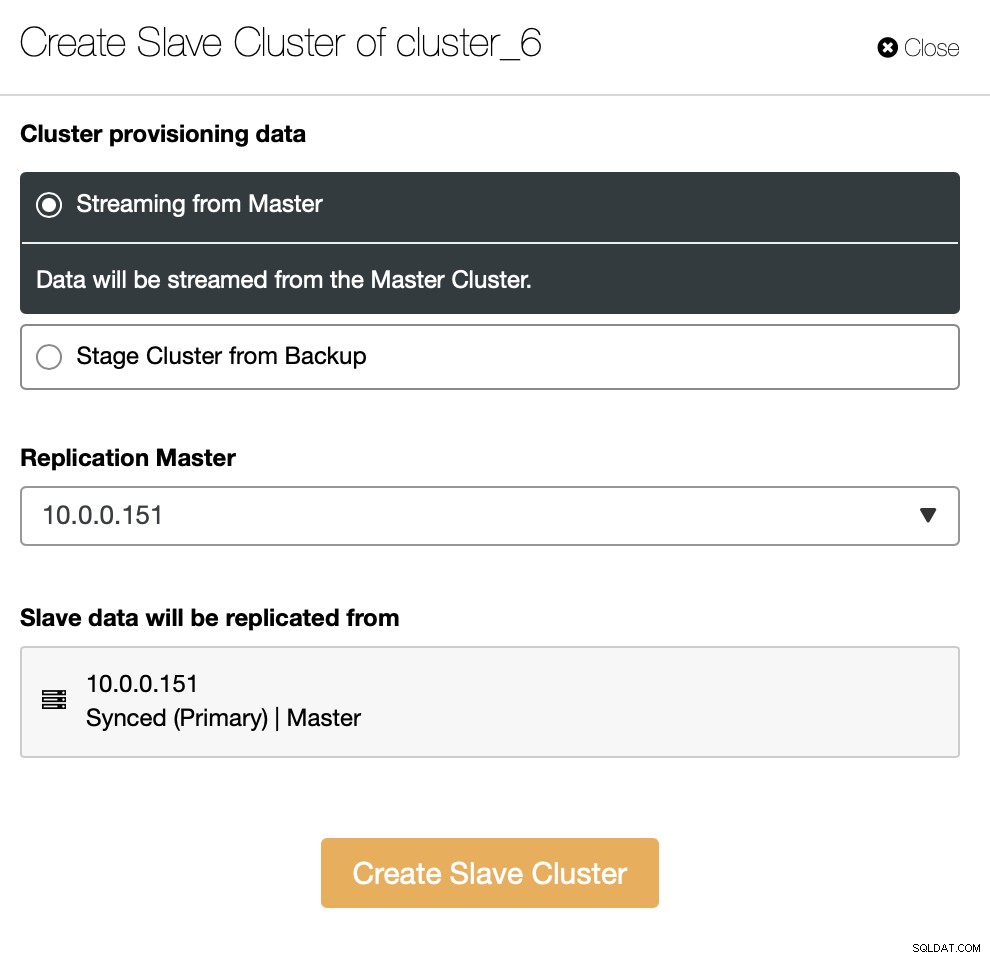
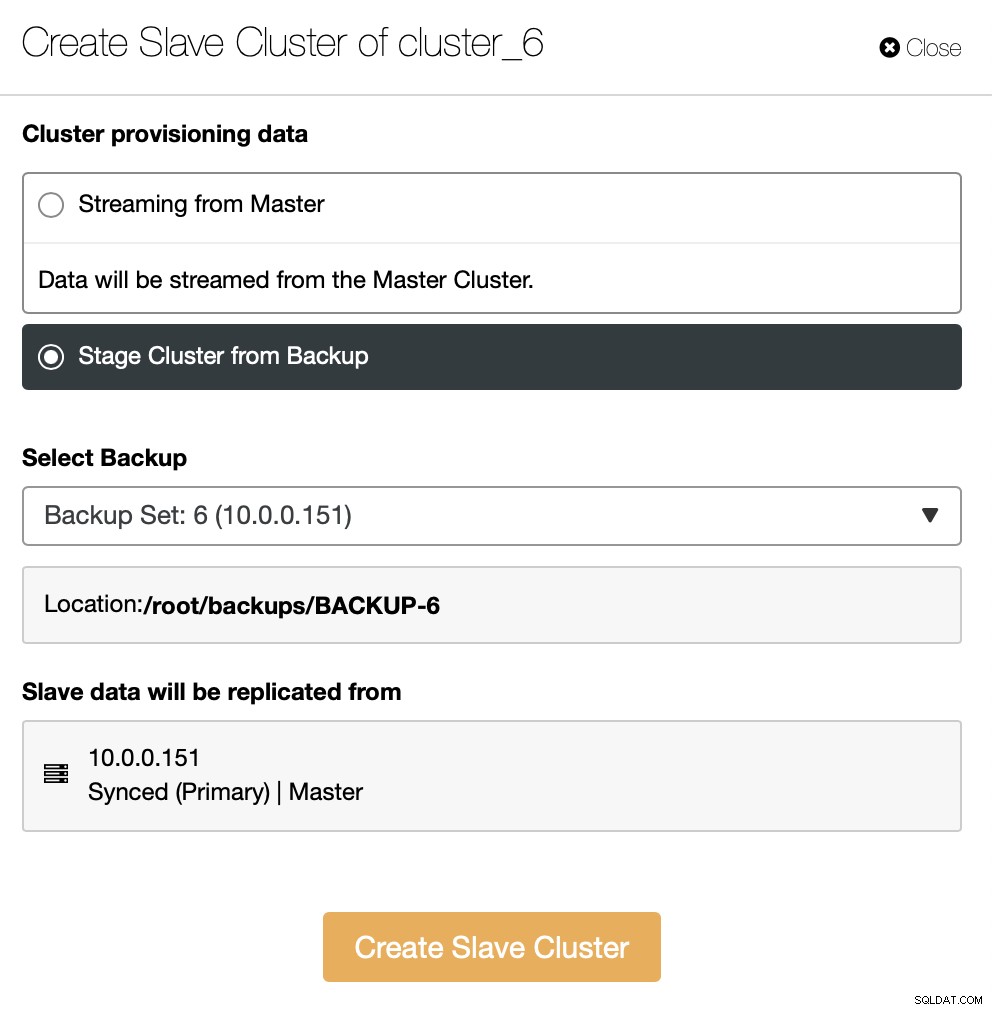
別の方法として、既存のバックアップを使用して新しいクラスターをプロビジョニングできます。これにより、マスターノードの作業負荷を軽減できます。すべてのデータを転送するのではなく、バックアップが作成されてからレプリケーションが設定されるまでの間に実行されたトランザクションのみを転送する必要があります。
残りは、SSH接続、バージョン、ベンダー、ホストなどを定義する、標準のデプロイメントウィザードに従うことです。デプロイされると、クラスターがリストに表示されます。
UIの代替ソリューションは、RPCを介してこれを実現することです。
{
"command": "create_cluster",
"job_data": {
"cluster_name": "",
"cluster_type": "galera",
"company_id": null,
"config_template": "my.cnf.80-pxc",
"data_center": 0,
"datadir": "/var/lib/mysql",
"db_password": "pass",
"db_user": "root",
"disable_firewall": true,
"disable_selinux": true,
"enable_mysql_uninstall": true,
"generate_token": true,
"install_software": true,
"port": "3306",
"remote_cluster_id": 6,
"software_package": "",
"ssh_keyfile": "/root/.ssh/id_rsa",
"ssh_port": "22",
"ssh_user": "root",
"sudo_password": "",
"type": "mysql",
"user_id": 5,
"vendor": "percona",
"version": "8.0",
"nodes": [
{
"hostname": "10.0.0.155",
"hostname_data": "10.0.0.155",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.159",
"hostname_data": "10.0.0.159",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.160",
"hostname_data": "10.0.0.160",
"hostname_internal": "",
"port": "3306"
}
],
"with_tags": []
}
}プロセスをClusterControlと統合する方法について詳しく知りたい場合は、ClusterControlが機能するソリューションの開発に関するセクション全体があるドキュメントを参照してください。重要な役割:
https://docs.severalnines.com/docs/clustercontrol/developer-guide/cmon-rpc/
https://docs.severalnines.com/docs/clustercontrol/user-guide-cli/
この短いブログが有益でお役に立てば幸いです。 ClusterControlをご使用の環境に統合することに関してご不明な点がございましたら、お問い合わせください。できる限りサポートさせていただきます。