データベースは最適に実行する必要がありますが、それはそれほど簡単な作業ではありません。 INFORMATION SCHEMAデータベースは、データベース最適化の戦争における秘密兵器になる可能性があります。
グラフィカルインターフェイスまたは一連のSQLコマンドを使用してデータベースを作成することに慣れています。それはまったく問題ありませんが、バックグラウンドで何が起こっているのかを少し理解するのも良いことです。これは、データベースの作成、保守、および最適化にとって重要であり、「舞台裏」で発生する変更を追跡するための優れた方法でもあります。
この記事では、MySQLデータベースの動作を調べるのに役立ついくつかのSQLクエリについて説明します。
INFORMATION_SCHEMAデータベース
INFORMATION_SCHEMAについてはすでに説明しました この記事のデータベース。まだ読んでいない場合は、続行する前に必ず読んでおくことをお勧めします。
INFORMATION_SCHEMAの復習が必要な場合 データベース–または最初の記事を読まないことにした場合–知っておく必要のある基本的な事実は次のとおりです。
-
INFORMATION_SCHEMAデータベースはANSI規格の一部です。 MySQLを使用しますが、他のRDBMSにはバリアントがあります。 H2データベース、HSQLDB、MariaDB、Microsoft SQL Server、およびPostgreSQLのバージョンを見つけることができます。 - これは、サーバー上の他のすべてのデータベースを追跡するデータベースです。ここにすべてのオブジェクトの説明があります。
- 他のデータベースと同様に、
INFORMATION_SCHEMAデータベースには、関連するテーブルとさまざまなオブジェクトに関する情報が多数含まれています。 - SQLを使用してこのデータベースにクエリを実行し、その結果を次のように使用できます。
- データベースのステータスとパフォーマンスを監視し、
- クエリ結果に基づいてコードを自動的に生成します。
次に、INFORMATION_SCHEMAデータベースのクエリに移ります。まず、使用するデータモデルを確認します。
データモデル
この記事で使用するモデルを以下に示します。
これは、クラス、インストラクター、学生、およびその他の関連する詳細に関する情報を保存できるようにする簡略化されたモデルです。テーブルを簡単に見てみましょう。
インストラクターのリストはlecturer テーブル。講師ごとに、first_nameを記録します およびlast_name 。
class 表には、私たちの学校にあるすべてのクラスがリストされています。このテーブルのレコードごとに、class_nameを保存します 、講師のID、計画されたstart_date およびend_date 、および追加のclass_details 。簡単にするために、クラスごとに1人の講師しかいないと仮定します。
クラスは通常、一連の講義として編成されます。通常、1つ以上の試験が必要です。関連する講義と試験のリストをlecture およびexam テーブル。どちらにも、関連するクラスのIDと予想されるstart_timeが含まれます。 およびend_time 。
今、私たちはクラスのために学生を必要としています。すべての学生のリストはstudent テーブル。繰り返しになりますが、first_nameのみを保存します およびlast_name 各学生の。
最後に、生徒の活動を追跡する必要があります。学生が登録したすべてのクラスのリスト、学生の出席記録、および試験結果を保存します。残りの3つのテーブルのそれぞれ– on_class 、on_lecture およびon_exam –生徒への参照と適切なテーブルへの参照があります。 on_exam テーブルには追加の値があります:grade。
はい、このモデルは非常に単純です。学生、講師、クラスに関する他の多くの詳細を追加できます。レコードが更新または削除されたときに履歴値を保存できます。それでも、このモデルはこの記事の目的には十分です。
データベースの作成
ローカルサーバー上にデータベースを作成し、その内部で何が起こっているかを調べる準備ができました。 「Generate SQL script」を使用してモデルを(Vertabeloで)エクスポートします " ボタン。
次に、MySQLサーバーインスタンスにデータベースを作成します。私は自分のデータベースを「classes_and_students」と呼びました 」。
次に行う必要があるのは、以前に生成されたSQLスクリプトを実行することです。
これで、すべてのオブジェクト(テーブル、主キーと外部キー、代替キー)を含むデータベースができました。
データベースサイズ
スクリプトの実行後、「classes and students」に関するデータ 」データベースはINFORMATION_SCHEMAに保存されます データベース。このデータは多くの異なるテーブルにあります。ここではそれらすべてを再度リストすることはしません。前回の記事でそれを行いました。
このデータベースで標準SQLを使用する方法を見てみましょう。まず、非常に重要なクエリを1つ紹介します。
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
クエリを実行しているのはINFORMATION_SCHEMA.TABLES こちらの表。このテーブルは、サーバー上のすべてのテーブルに関する十分な詳細を提供するはずです。 「classes_and_students」からテーブルのみをフィルタリングしたことに注意してください "SETを使用したデータベース 最初の行で変数を使用し、後でクエリでこの値を使用します。ほとんどのテーブルには、TABLE_NAME列が含まれています およびTABLE_SCHEMA 、このデータが属するテーブルとスキーマ/データベースを示します。
このクエリは、データベースの現在のサイズとデータベース用に予約されている空き領域を返します。実際の結果は次のとおりです。

予想どおり、空のデータベースのサイズは1 MB未満であり、予約済みの空き領域ははるかに大きくなっています。
テーブルのサイズとプロパティ
次に行うべき興味深いことは、データベース内のテーブルのサイズを調べることです。そのために、次のクエリを使用します:
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
クエリは、1つの例外を除いて、前のクエリとほぼ同じです。結果はテーブルレベルでグループ化されます。
このクエリによって返される結果の画像は次のとおりです。
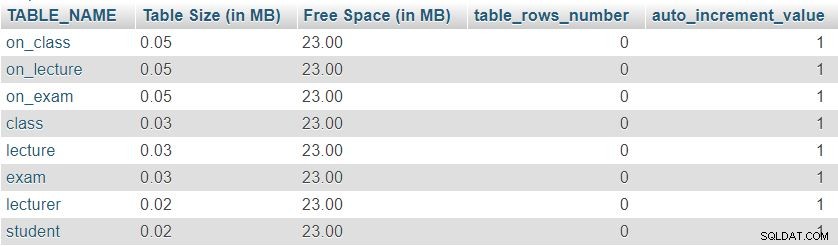
まず、8つのテーブルすべてに最小の「テーブルサイズ」があることがわかります。 列、主キー、およびインデックスを含むテーブル定義用に予約されています。 「空き容量」 すべてのテーブルに均等に分散されます。
また、各テーブルに現在ある行数と auto_incrementの現在の値も確認できます。 各テーブルのプロパティ。すべてのテーブルが完全に空であるため、データがなく、 auto_increment 1(次に挿入される行に割り当てられる値)に設定されます。
主キー
各テーブルには主キー値を定義する必要があるため、これがデータベースに当てはまるかどうかを確認することをお勧めします。これを行う1つの方法は、すべてのテーブルのリストを制約のリストと結合することです。これにより、必要な情報が得られるはずです。
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
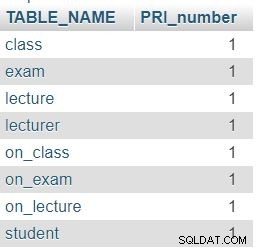
INFORMATION_SCHEMA.COLUMNS このクエリのテーブル。クエリの最初の部分はデータベース内のすべてのテーブルを返すだけですが、2番目の部分(LEFT JOINの後)は )これらのテーブルのPRIの数をカウントします。 LEFT JOINを使用しました COLUMNSにテーブルのPRIが0であるかどうかを確認したいからです。 テーブル。
予想どおり、データベースの各テーブルには、主キー(PRI)列が1つだけ含まれています。
「島」?
「島」は、モデルの他の部分から完全に分離されたテーブルです。これらは、テーブルに外部キーが含まれておらず、他のテーブルで参照されていない場合に発生します。本当に正当な理由がない限り、これは実際には発生しないはずです。テーブルにパラメータが含まれている場合、または結果やレポートがモデル内に保存されている場合。
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
このクエリの背後にある考え方は何ですか?ええと、私たちはINFORMATION_SCHEMA.KEY_COLUMN_USAGE テーブル内のいずれかの列が別のテーブルへの参照であるかどうか、または任意の列が他のテーブルの参照として使用されているかどうかをテストするためのテーブル。クエリの最初の部分は、すべてのテーブルを選択します。最初のLEFTJOINの後、このテーブルの任意の列が参照として使用された回数をカウントします。 2番目のLEFTJOINの後、このテーブルの任意の列が他のテーブルを参照した回数をカウントします。
返される結果は次のとおりです。
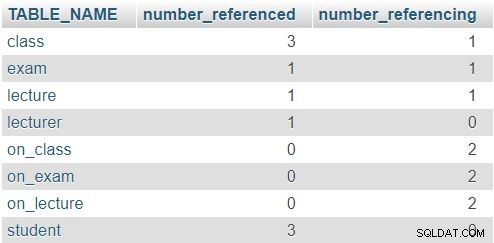
class 表の番号3と1は、この表が3回参照されたことを示します(lecture 、exam 、およびon_class テーブル)、および別のテーブルを参照する1つの属性が含まれていること(lecturer_id )。他の表も同様のパターンに従いますが、実際の数はもちろん異なります。ここでのルールは、両方の列に0が含まれる行はないということです。
行の追加
これまでのところ、すべてが期待どおりに進んでいます。データモデルをVertabeloからローカルのMySQLサーバーに正常にインポートしました。すべてのテーブルには、必要に応じてキーが含まれており、すべてのテーブルは相互に関連しています。モデルには「島」はありません。
次に、テーブルにいくつかの行を挿入し、前に示したクエリを使用してデータベースの変更を追跡します。
講師のテーブルに1,000行を追加した後、「Table Sizes and Properties」からクエリを再度実行します " セクション。次の結果が返されます:
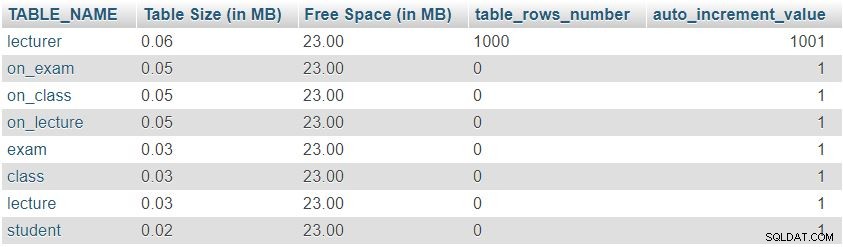
行数とauto_increment値が期待どおりに変更されたことは簡単にわかりますが、テーブルサイズに大きな変更はありませんでした。
これは単なるテスト例です。実際の状況では、大きな変化に気付くでしょう。行数は、ユーザーまたは自動化されたプロセスによって入力されたテーブル(つまり、ディクショナリではないテーブル)で大幅に変化します。このようなテーブルのサイズと値を確認することは、不要な動作をすばやく見つけて修正するための非常に良い方法です。
共有しますか?
データベースの操作は、最適なパフォーマンスを常に追求しています。その追求でより成功するために、あなたは利用可能などんなツールでも使うべきです。今日、パフォーマンスを向上させるための戦いに役立つクエリをいくつか見てきました。他に役立つものはありますか? INFORMATION_SCHEMAで遊んだことがありますか 以前のデータベース?以下のコメントであなたの経験を共有してください。