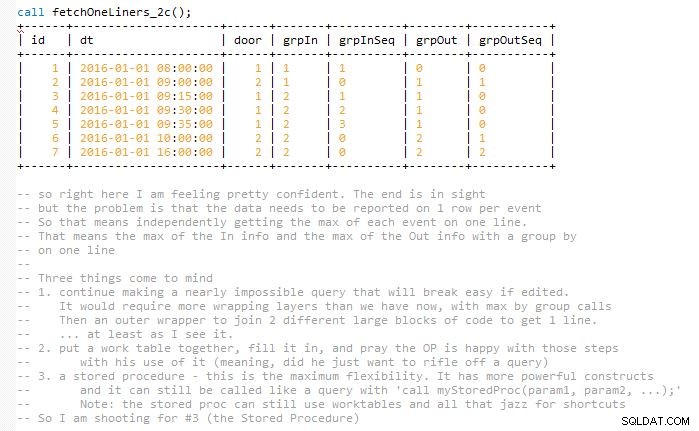
これは、(私の考えでは)サイズがほぼ2倍になる最終的なクエリをすべて一度に完了することなく、ソリューションを簡単に保守できるようにすることを目的としています。これは、結果が一致し、一致したInイベントとOutイベントで1つの行に表示される必要があるためです。最後に、いくつかのワークテーブルを使用します。ストアドプロシージャに実装されています。
ストアドプロシージャは、cross joinで取り込まれるいくつかの変数を使用します 。クロス結合は、変数を初期化するための単なるメカニズムと考えてください。変数は安全に維持されているので、このドキュメント
多くの場合、変数クエリで参照されます。参照の重要な部分は、行上の変数を安全に処理して、他の列がそれらを使用する前に変数を設定することを強制することです。これは、greatest()によって実現されます。 およびleast() これらの関数を使用せずに設定された変数よりも優先度の高い関数。 coalesce()にも注意してください 多くの場合、同じ目的で使用されます。 0または0より大きいことがわかっている数値の最大値を取るなど、それらの使用が奇妙に思われる場合は、それは意図的なことです。設定されている変数の優先順位を強制することを意図してください。
dummy2のような名前のクエリの列 などは、出力が使用されなかった列ですが、たとえばgreatest()内の変数を設定するために使用されました。 または別の。これは上で述べました。 if()に何らかの値が必要だったため、7777のような出力は3番目のスロットのプレースホルダーでした。 それが使用されました。ですから、それはすべて無視してください。
出力を視覚化するのに役立つように、コードがレイヤーごとに進行するときに、コードのスクリーンショットをいくつか含めました。そして、これらの開発の反復が、前の段階を拡張するために次の段階にゆっくりと折りたたまれる方法。
私の仲間は1つのクエリでこれを改善できると確信しています。私はそれをそのように終えることができたでしょう。しかし、それは、触れられた場合に壊れるであろう混乱した混乱をもたらしたであろうと私は信じています。
スキーム:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
ストアドプロシージャ:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
テスト:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
これで回答は終わりです。 以下は、ストアドプロシージャを完了するまでのステップを開発者が視覚化したものです。
最後まで続いた開発のバージョン。うまくいけば、これは、中サイズの紛らわしいコードのチャンクを単にドロップするのではなく、視覚化に役立つでしょう。
ステップA
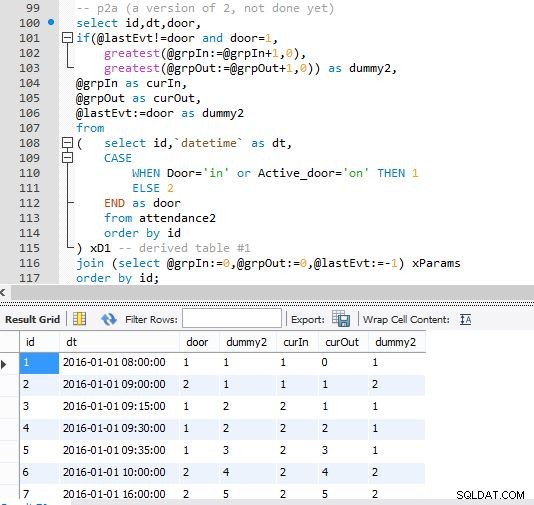
ステップB
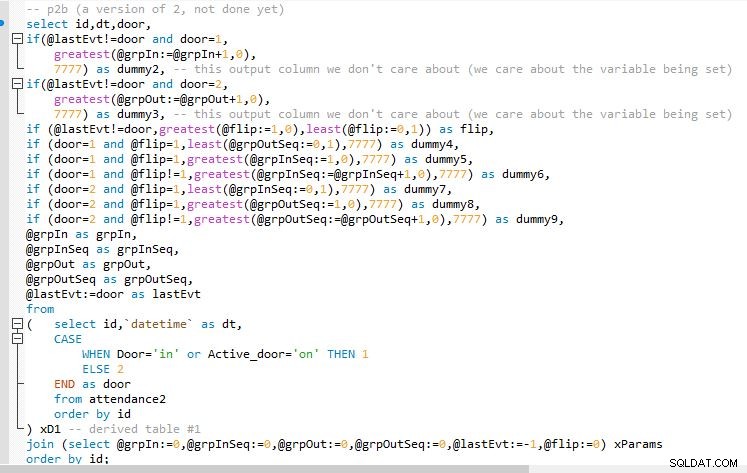
ステップBの出力

ステップC
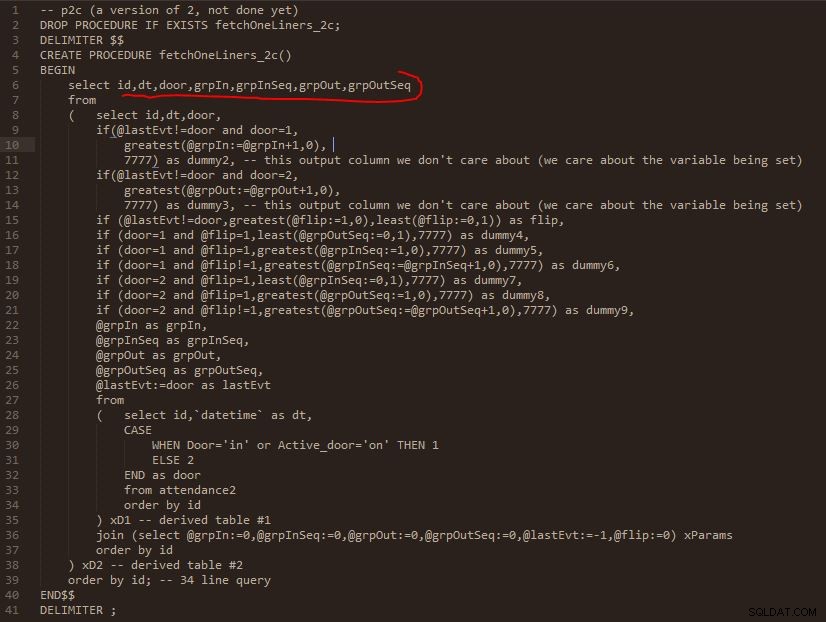
ステップC出力