ベンチマークは、データベース管理者が実行するアクティビティの1つです。それらを実行してハードウェアの動作を確認し、実行してアプリケーションとデータベースがプレッシャーの下でどのように連携するかを確認します。あなたは多くの異なる状況でそれらを実行します。それらについて少し話しましょう。直面する課題は何か、避けるべき問題は何か。
合成ベンチマークは通常、ある種のワークロードをシミュレートするツールです。これは、Sysbenchの場合のようにOLTPワークロードである可能性があり、TPC-CまたはTPC-Hの場合のような「標準」ベンチマークである可能性があります。通常、このようなベンチマークはある種のワークロードをシミュレートするという考え方であり、実際のワークロードが同じパターンに従う場合に役立つ可能性があります。また、特定のタイプのワークロードでハードウェア構成とデータベース構成の組み合わせがどのように連携するかを判断するためにも使用できます。合成ベンチマークの長所は非常に明確です。それらはどこでも実行でき、特定のセットアップやスキーマ設計に依存しません。そうですね、彼らはそうしますが、空のデータベースサーバーからすべてをセットアップするためのツールを考え出します。主な欠点は、これがワークロードではないことです。 Sysbenchを使用してOLTPテストを実行する場合は、アプリケーションがSysbenchになることはないことに注意する必要があります。また、OLTPワークロードを実行する場合もありますが、クエリの組み合わせは異なります。いかなる状況においても、合成ベンチマークは、特定のハードウェア/構成の組み合わせでアプリケーションがどのように動作するかを正確に教えてくれることはありません。
私たちが持っているスペクトルの反対側には、「現実世界」のベンチマークと呼ばれるものがあります。ここで意味するのは、アプリケーションに関連するデータセットとクエリを使用するベンチマークです。完全なデータセットと完全なクエリの組み合わせが常にあるとは限りません。アプリケーションの一部に焦点を当てたい場合もありますが、その背後にある主な考え方は、一般的または特定の側面で、アプリケーション、ハードウェア、およびデータベース構成間の正確な相互作用を理解したいということです。
前述のように、2つの主要な異なるタイプのベンチマークがありますが、それでも、ベンチマークを実行する際に考慮しなければならない一般的な事項がいくつかあります。
-
テストする対象を決定する
まず、ベンチマークを実行するためのベンチマークは無意味です。実際に何かを達成するように設計する必要があります。ベンチマークの実行から何を得たいですか?クエリを調整しますか?構成を微調整しますか?スタックのスケーラビリティを評価しますか?より高い負荷に備えてスタックを準備しますか?新しいプロジェクトの一般的な構成を調整しますか?ハードウェアに最適な設定を決定しますか?これらはあなたが達成したいと思うかもしれない目的の例です。これらはそれぞれ、異なるアプローチと異なるベンチマーク設定を必要とします。
-
一度に1つの変更を加えます
テストや調整を行う場合は、一度に1つの構成変更のみを行うことが最も重要です。これは本当に重要です。ベンチマークは、パフォーマンスに関するアイデアを提供することを目的としています。 1秒あたりのクエリ数、待機時間、99パーセンタイル。これはすべて、クエリの実行速度と、ワークロードの安定性と予測可能性を示しています。構成、ハードウェア、またはクエリミックスで行った変更によって何かが変更されたかどうかは、簡単にわかります。ベンチマークのメトリックは異なって見えます。重要なのは、同時にいくつかの変更を加えた場合、どちらが全体的な結果の原因であるかを判断する方法がないということです。それ以上に進むことができます。データベース構成で2つの値を変更したとします。値AおよびB。全体的な改善は20%であり、構成を変更するだけで非常に優れています。ただし、内部的には、値Aに変更すると30%の改善が見られ、値Bにさらに変更すると20%に戻ります。同時に複数の変更を行うと、それらの共通の影響しか観察できません。これは、行ったすべての変更の結果を適切に判断する方法ではありません。確かに、これによりベンチマークの実行に費やす時間が大幅に増加しますが、それが現状です。
-
複数のベンチマークを実行する
-
写真は数千語の価値があります
まあ、これはベンチマークの非常に正確な説明です。可能であれば、常にグラフを生成してください。理想的には、ベンチマーク中にできるだけ頻繁にメトリックを追跡します。ほとんどの場合、1秒の粒度で十分です。何千もの単語を書かないようにするために、この例を含めます。何がもっと便利だと思いますか?この一連のベンチマーク出力は、10パスごとの平均QPSを表し、パスごとに600秒かかります
11650.52
11237.97
11550.16
11247.08
11177.78
11163.76
11131.47
11235.06
11235.59
11277.25
またはこのプロット:
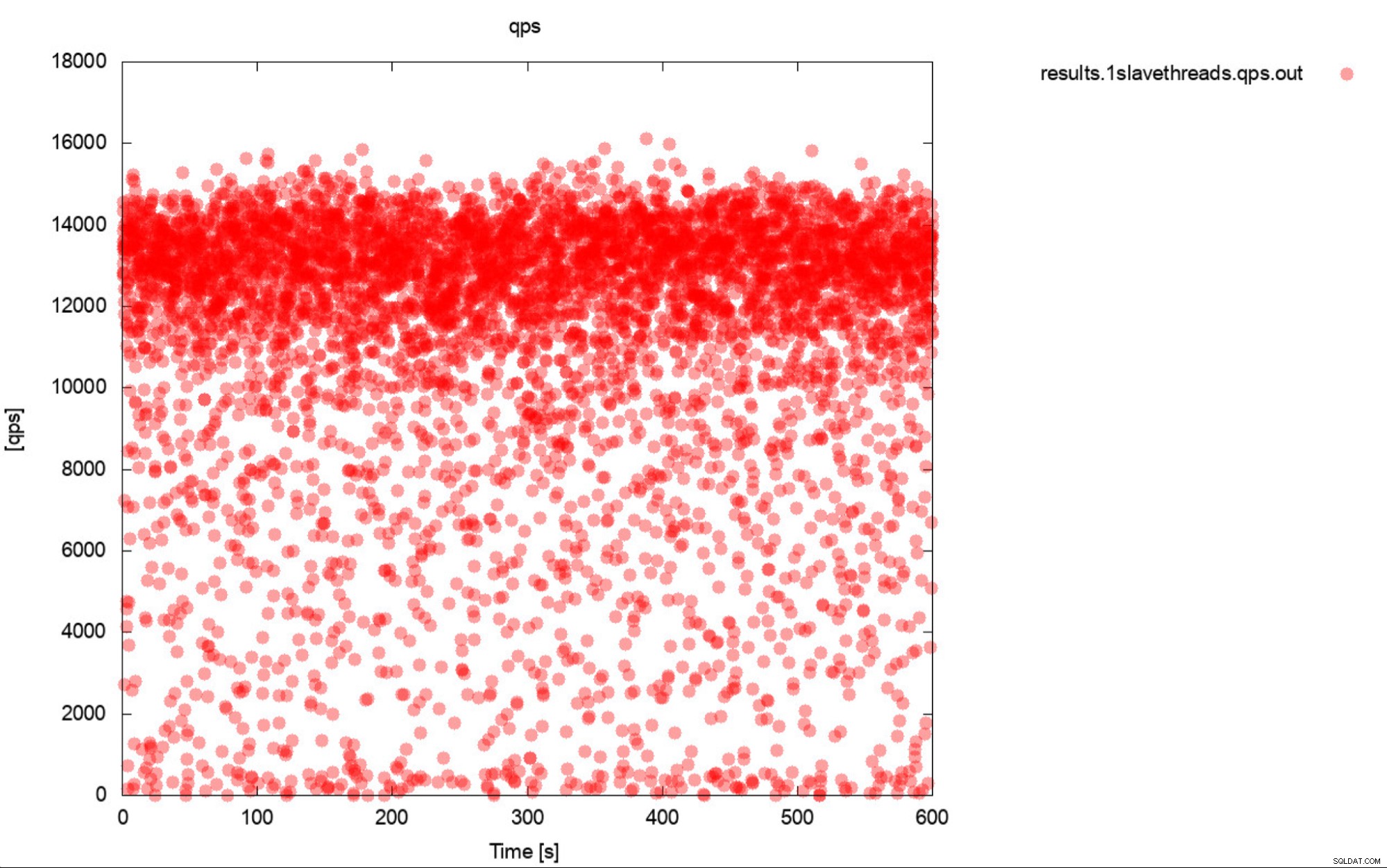
平均QPSは11kですが、実際にはパフォーマンスは全体に及んでいます。 1秒以内に実行される0クエリへのディップを含む場所であり、これは間違いなく、実稼働システムで作業および改善したいものです。
-
1秒あたりのクエリ数は最も重要な指標ではありません
1秒あたりのクエリは、データベースが1秒間に実行できるクエリの数を表すため、パフォーマンスの聖杯であると考えるかもしれません。真実は、特にベンチマークからの平均出力について話している場合、これは最も重要なメトリックではありません。 QPSはスループットを表しますが、レイテンシーは無視されます。大量のクエリをプッシュしようとすることはできますが、結果が返されるのを待つことになります。これは、ユーザーがアプリケーションに期待するものではありません。ユーザーは安定したパフォーマンスを期待しています。猛烈な速さである必要はありませんが、アクションの完了に1秒かかる場合、そのアクションの実行には常に1秒かかると予想される傾向があります。なんらかの理由で時間がかかり始めると、人間は不安になりがちです。これが、レイテンシー、特に信頼性の高いメトリックとしてのP99(99パーセンタイル)を好む傾向がある主な理由です。レイテンシーは、アプリケーションがデータベースからの結果を待機する必要があった時間を示します。 P99は、クエリの99%がより低いレイテンシーを示しています。 P99が100ミリ秒であるとしましょう。これは、クエリの99%が100ミリ秒以上の結果を返すことを意味します。 P99のレイテンシが低い場合は、ほとんどすべてのクエリが高速に返され、安定した予測可能な方法で実行されていることを意味します。これは、ユーザーが見たいものです。
-
結論を出す前に何が起こっているかを理解する
この短いブログの最後のポイントですが、これが最も重要なものだと思います。ベンチマーク中に、さまざまな奇妙で予期しない結果と動作が表示されます。さらに悪いことに、かなり標準的で反復的ですが、それでも欠陥のある結果が表示される場合があります。それらのほとんどは、データベースまたはハードウェアの動作を追跡できます。これは非常に重要です。結果を当然のことと考える前に、動作を説明し、何が起こったかを説明できる必要があります。それは簡単ではなく、データベース固有の知識、特にデータベースの内部に関連する知識が本当に必要であることを私たちは知っています。現実の世界では、人々は通常これを気にせず、ただいくつかの結果を得たいだけであることを私たちは知っています。特に、構成やハードウェアの調整によってパフォーマンスを向上させようとしている場合は、内部で何が起こったかを理解することで、チューニングを進める適切な方法を選択できます。また、実行されたベンチマークに意味があるかどうかを判断することもできます。実際に正しい要素をテストしていますか?例としては、ネットワーク上で実行されるテストがあります(ベンチマークツールにデータベースノードのローカルCPUコアを使用したくないため)。ネットワーク自体とsoftirqCPU負荷が制限要因になる可能性が非常に高く、CPU飽和などの「予想される」ボトルネックにぶつかるよりもはるかに早くなります。環境とその動作を認識していない場合は、CPUパフォーマンスではなく、ネットワークパフォーマンスを測定して大量のデータを転送します。
ご覧のとおり、ベンチマークは最も簡単な方法ではありません。何が起こっているのかをある程度認識している必要があります。また、何をしようとしているのかについて適切な計画を立てる必要があります。何をテストしたいですか?このブログの次のパートでは、実際のテストケースのいくつかを見ていきます。何がうまくいかないか、どのような問題が発生するか、そしてそれらにどのように対処するか。