Galeraの優れた機能の1つは、自動ノードプロビジョニングとメンバーシップ制御です。ノードに障害が発生したり、通信が失われたりすると、ノードはクラスターから自動的に削除され、動作しなくなります。大多数のノードがまだ通信している限り(GaleraはこのPCをプライマリコンポーネントと呼んでいます)、接続が回復すると、障害が発生したノードが自動的に再参加、再同期、およびレプリケーションを再開できる可能性が非常に高くなります。
>一般的に、すべてのガレラノードは同じです。これらは、マスターと同じデータセットと同じ役割を持ち、Galeraグループ通信と認証ベースのレプリケーションプラグインのおかげで、読み取りと書き込みを同時に処理できます。したがって、この平衡状態のため、データベースの観点からは実際にはフェイルオーバーはありません。フェイルオーバーが必要なアプリケーション側からのみ、クラスターがパーティション化されている間、動作していないノードをスキップします。
このブログ投稿では、ネットワークパーティションが発生した場合に、GaleraClusterがノードとクラスターのリカバリをどのように実行するかを理解する方法について説明します。補足として、このブログ投稿で同様のトピックをしばらく前に取り上げました。 Codershipは、ドキュメントページのノード障害と回復でGaleraの回復の概念を詳細に説明しています。
ノードの障害とエビクション
リカバリを理解するには、Galeraがノードの障害と排除プロセスを最初に検出する方法を理解する必要があります。立ち退きプロセスをよりよく理解できるように、これを制御されたテストシナリオに入れましょう。以下に示すように、3ノードのGaleraクラスターがあるとします。
次のコマンドを使用して、Galeraプロバイダーオプションを取得できます。
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\Gこれは長いリストですが、プロセスを説明するためにいくつかのパラメーターに焦点を当てる必要があります。
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;まず、GaleraはISO8601形式に従って期間を表します。 P1Dは期間が1日であることを意味し、PT15Sは期間が15秒であることを意味します(時間値の前にある時間指定子Tに注意してください)。たとえば、 evs.view_forget_timeoutを増やしたい場合 1日半にすると、P1DT12HまたはPT36Hに設定されます。
すべてのホストがファイアウォールルールで構成されていないことを考慮して、 block_galera.shという次のスクリプトを使用します。 このノードとの間のネットワーク障害をシミュレートするには、galera2で:
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateスクリプトを実行すると、次の出力が得られます。
$ ./block_galera.sh
Wed Jul 4 16:46:02 UTC 2018報告されたタイムスタンプは、galera1とgalera3がオンラインでアクセス可能である間に、galera2が失われるクラスター分割の開始と見なすことができます。この時点で、GaleraClusterアーキテクチャは次のようになっています。
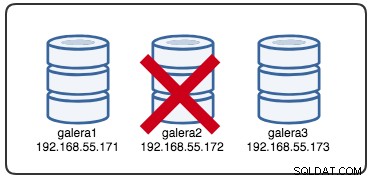
パーティション化されたノードの観点から
galera2では、MySQLエラーログ内にいくつかのプリントアウトが表示されます。それらをいくつかの部分に分けてみましょう。ダウンタイムは、UTC時間の16:46:02頃、および gmcast.peer_timeout =PT3Sの後に開始されました。 、次のように表示されます:
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0evs.suspect_timeout =PT5Sを通過したとき 、ノードgalera1とgalera3の両方がgalera2によって死んでいると疑われています:
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive次に、Galeraは現在のクラスタービューとこのノードの位置を修正します:
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})新しいクラスタービューでは、Galeraはクォーラム計算を実行して、このノードがプライマリコンポーネントの一部であるかどうかを判断します。新しいコンポーネントで「primary=no」が検出された場合、Galeraはローカルノードの状態をSYNCEDからOPENに降格します:
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)クラスタービューとノード状態の最新の変更により、Galeraは削除後のクラスタービューとグローバル状態を次のように返します。
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.この期間中に、galera2の次のグローバルステータスが変更されたことがわかります。
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+この時点で、galera2上のMySQL / MariaDBサーバーは引き続きアクセス可能であり(データベースは3306でリッスンしており、Galeraは4567でリッスンしています)、mysqlシステムテーブルをクエリして、データベースとテーブルを一覧表示できます。ただし、非システムテーブルにジャンプして、次のような単純なクエリを実行すると、次のようになります。
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application usewsrep_ready によって報告されたように、WSREPがロードされているが、このノードで使用する準備ができていないことを示すエラーがすぐに表示されます。 状態。これは、ノードがプライマリコンポーネントへの接続を失い、非動作状態になっているためです(ローカルノードのステータスがSYNCEDからOPENに変更されました)。 wsrep_dirty_reads =ON を設定しない限り、非動作状態のノードからのデータ読み取りは失効していると見なされます。 読み取りを許可しますが、Galeraはデータベースを変更または更新するコマンドを引き続き拒否します。
最後に、Galeraはバックグラウンドで他のメンバーに無限に耳を傾け、再接続し続けます:
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60ネットワーク発行中のパーティション化されたノードのGaleraグループ通信による排除プロセスフローは、次のように要約できます。
- gmcast.peer_timeout の後で、クラスターから切断します 。
- evs.suspect_timeoutの後に他のノードを疑う 。
- 新しいクラスタービューを取得します。
- クォーラム計算を実行して、ノードの状態を判別します。
- ノードをSYNCEDからOPENにデモします。
- バックグラウンドでプライマリコンポーネント(他のGaleraノード)に再接続しようとします。
主要コンポーネントの観点から
それぞれgalera1とgalera3で、 gmcast.peer_timeout =PT3Sの後 、MySQLエラーログに次のように表示されます:
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0evs.suspect_timeout =PT5Sを通過した後 、galera2はgalera3(およびgalera1)によって死んでいると疑われています:
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveGaleraは、他のノードがgalera3のグループ通信に応答するかどうかをチェックし、galera1がプライマリで安定した状態にあることを検出します。
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primGaleraは、このノード(galera3)のクラスタービューを改訂します:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into disk次に、Galeraはパーティション化されたノードをプライマリコンポーネントから削除します:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)新しいプライマリコンポーネントは、galera1とgalera3の2つのノードで構成されています。
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2プライマリコンポーネントは、新しいクラスタービューとグローバル状態について合意するために、相互に状態を交換します。
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)Galeraは、オンラインメンバー間の州交換の定足数を計算して検証します。
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorGaleraは、galera2の削除後に、新しいクラスタービューとグローバル状態を更新します:
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)この時点で、galera1とgalera3の両方が同様のグローバルステータスを報告します:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+問題のあるメンバーをwsrep_evs_delayedにリストします。 状態。ローカル状態は「同期済み」であるため、これらのノードは動作可能であり、クライアント接続をgalera2からそれらのいずれかにリダイレクトできます。この手順が不便な場合は、データベースの前にあるロードバランサーを使用して、クライアントからの接続エンドポイントを簡素化することを検討してください。
ノードのリカバリと参加
パーティション化されたGaleraノードは、プライマリコンポーネントとの接続を無限に確立しようとし続けます。 galera2のiptablesルールをフラッシュして、残りのノードに接続できるようにしましょう:
# on galera2
$ iptables -Fノードがノードの1つに接続できるようになると、Galeraはグループ通信の再確立を自動的に開始します。
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stable次に、ノードgalera2はプライマリコンポーネントの1つ(この場合はgalera1、ノードID 737422d6)に接続して、現在のクラスタービューとノードの状態を取得します。
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskその後、Galeraは、プライマリコンポーネントを形成できる残りのメンバーと状態交換を実行します。
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)状態交換により、galera2はクォーラムを計算し、次の結果を生成できます。
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc次に、Galeraはローカルノードの状態をOPENからPRIMARYにプロモートし、プライマリコンポーネントへのノード接続を開始および確立します。
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)上記の行で報告されているように、Galeraは、ノードがクラスターからどれだけ遅れているかに関するギャップを計算します。このノードでは、2761994から書き込みセット番号2836958に追いつくために、状態転送が必要です。
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3Galeraは、このノードのポート4568でISTリスナーを準備し、クラスター内の同期ノードにドナーになるように要求します。この場合、Galeraは自動的にgalera3(192.168.55.173)を選択します。または、 wsrep_sst_donorの下のリストからドナーを選択することもできます。 (定義されている場合)同期操作の場合:
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.次に、ローカルノードの状態をPRIMARYからJOINERに変更します。この段階で、galera2は状態転送要求を許可され、書き込みセットのキャッシュを開始します:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetノードgalera2は、選択したドナーのgcache(galera3)から欠落している書き込みセットの受信を開始します:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.不足しているすべての書き込みセットが受信されて適用されると、Galeraはseqno 2837012までGalera2をJOINEDとしてプロモートします:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.ノードは、スレーブキューにキャッシュされたライトセットを適用し、クラスターへの追いつきを終了します。そのスレーブキューは空になりました。 Galeraはgalera2をSYNCEDにプロモートし、ノードが操作可能になり、クライアントにサービスを提供する準備ができたことを示します。
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsこの時点で、すべてのノードが再び動作可能になります。 galera2で次のステートメントを使用して確認できます:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+wsrep_cluster_size 3として報告され、クラスターステータスはプライマリです。これは、galera2がプライマリコンポーネントの一部であることを示しています。 wsrep_evs_delayed もクリアされ、ローカル状態が同期されました。
ネットワークの問題が発生したときのパーティション化されたノードのリカバリプロセスフローは、次のように要約できます。
- 他のノードへのグループ通信を再確立します。
- プライマリコンポーネントの1つからクラスタービューを取得します。
- プライマリコンポーネントとの状態交換を実行し、クォーラムを計算します。
- ローカルノードの状態をOPENからPRIMARYに変更します。
- ローカルノードとクラスター間のギャップを計算します。
- ローカルノードの状態をPRIMARYからJOINERに変更します。
- ポート4568でISTリスナー/レシーバーを準備します。
- ISTを介して状態の転送を要求し、ドナーを選択します。
- 選択したドナーのgcacheから不足しているライトセットの受信と適用を開始します。
- ローカルノードの状態をJOINERからJOINEDに変更します。
- スレーブキューにキャッシュされたライトセットを適用することで、クラスターに追いつきます。
- ローカルノードの状態をJOINEDからSYNCEDに変更します。
クラスター障害
プライマリコンポーネント(PC)が利用できない場合、Galeraクラスターは失敗したと見なされます。次の図に示すように、同様の3ノードのGaleraクラスターについて考えてみます。
すべてのノードまたはノードの大部分がオンラインである場合、クラスターは動作可能であると見なされます。オンラインとは、Galeraのレプリケーショントラフィックまたはグループ通信を通じてお互いを見ることができることを意味します。ノードに出入りするトラフィックがない場合、クラスターはノードにハートビートビーコンを送信して、タイムリーに応答します。それ以外の場合は、ノードの応答に応じて、遅延または疑わしいリストに入れられます。
ノードがダウンした場合、たとえばノードCの場合、ノードAとBはまだクォーラムにあり、3つのうち2つがプライマリコンポーネントを形成しているため、クラスターは動作し続けます。 AとBで次のクラスター状態を取得する必要があります。
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+次の図に示すように、プライマリスイッチが機能しなくなったとしましょう。
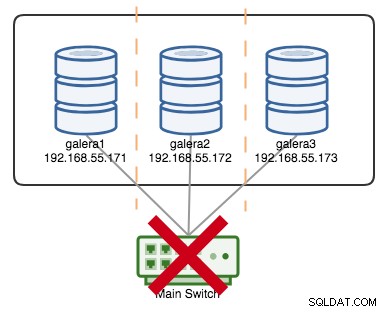
この時点で、すべての単一ノードが相互に通信を失い、クラスター状態はすべてのノードで非プライマリとして報告されます(前のケースでgalera2に起こったことと同様)。すべてのノードがクォーラムを計算し、それが少数派(3つのうち1つ)であることがわかり、クォーラムが失われます。つまり、プライマリコンポーネントが形成されず、すべてのノードがデータの提供を拒否します。これはクラスター障害と見なされます。
ネットワークの問題が解決されると、Galeraはメンバー間の通信を自動的に再確立し、ノードの状態を交換し、ノードの状態、UUID、およびseqnoを比較することによってプライマリコンポーネントを再構築する可能性を判断します。確率が存在する場合、Galeraは次の行に示すように主要コンポーネントをマージします。
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
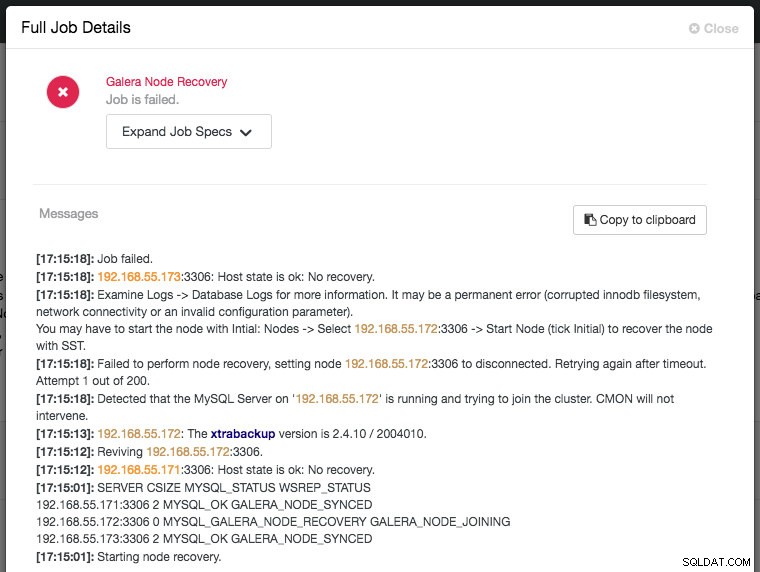
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
結論
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.