あるブログのコメントセクションで、ある読者が、wsrep_slave_threadsがGaleraClusterのI/Oパフォーマンスとスケーラビリティに与える影響について質問しました。当時、その質問に簡単に答えて、より多くのデータでバックアップすることはできませんでしたが、最終的に環境を設定し、いくつかのテストを実行することができました。
私たちの読者は、wsrep_slave_threadsを増やしてもGaleraクラスターのパフォーマンスに影響がないことを示すベンチマークを指摘しました。
その設定の影響を説明するために、3つのノード(m5d.xlarge)の小さなクラスターを設定しました。これにより、MySQLデータディレクトリに直接接続されたnvmeSSDを利用できるようになりました。これにより、ストレージがセットアップのボトルネックになる可能性を最小限に抑えました。
InnoDBバッファープールを8GBに設定し、ログを2つのファイル(それぞれ1GB)にやり直します。また、innodb_io_capacityを2000に、innodb_io_capacity_maxを10000に増やしました。これは、これらの設定のどちらもパフォーマンスに影響を与えないようにすることも目的としています。
このようなベンチマークの全体的な問題は、ボトルネックが非常に多いため、それらを1つずつ削除する必要があることです。構成の調整を行い、ハードウェアに問題がないことを確認した後でのみ、さらに微妙な制限が表示されることを期待できます。
sysbenchを使用して最大90GBのデータを生成しました:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepare次に、ベンチマークが実行されました。 wsrep_slave_threads=1とwsrep_slave_threads=16の2つの設定をテストしました。ハードウェアは、この変数をさらに増やすことで利益を得るほど強力ではありませんでした。また、最高のパフォーマンスを得るためにwsrep_slave_threadsを16、8、または4に設定する必要があるかどうかを判断するために、詳細なベンチマークを行っていないことにも注意してください。クラスターへの影響を示すことができるかどうかを確認することに興味がありました。そして、はい、その影響ははっきりと見えました。手始めに、いくつかのフロー制御グラフ。
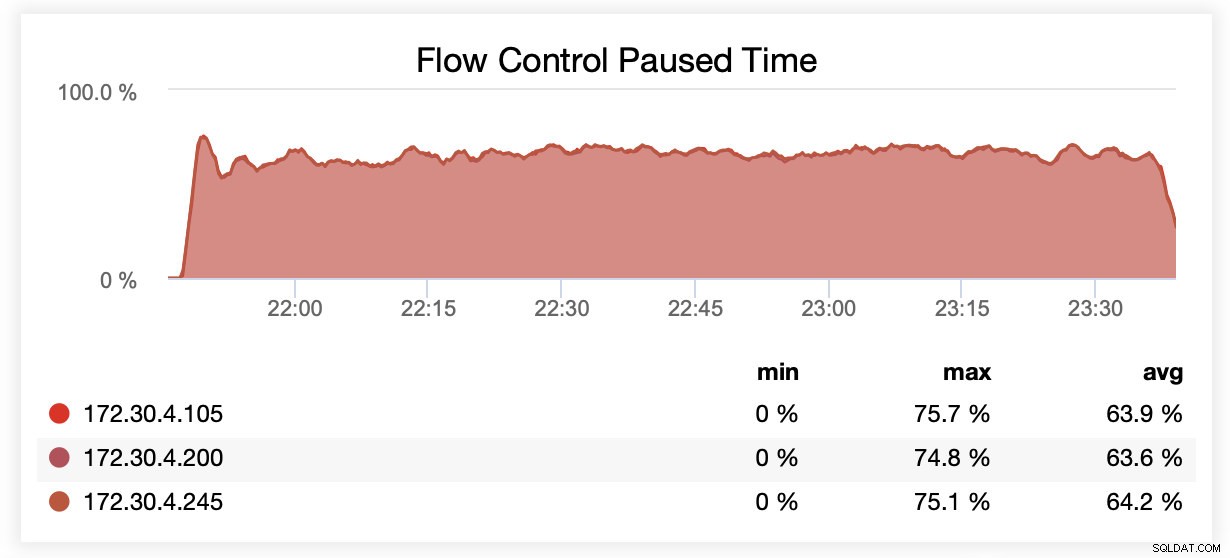
wsrep_slave_threads =1で実行している間、平均して、ノードはフロー制御のために一時停止されました。これは、最大64%の時間です。
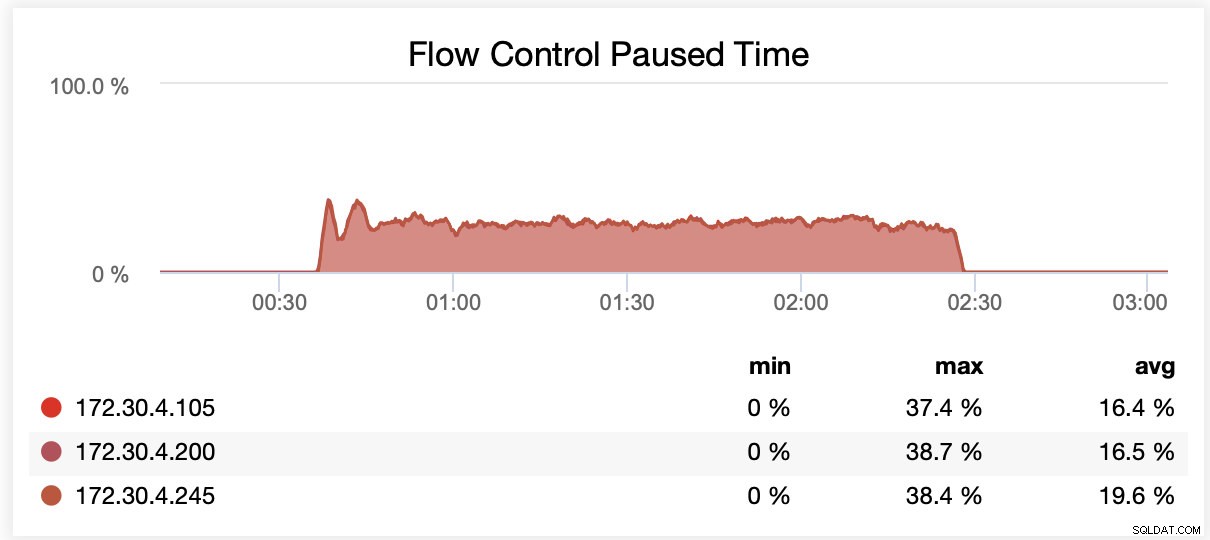
wsrep_slave_threads =16で実行している間、平均して、ノードはフロー制御のために最大20%の時間一時停止されました。
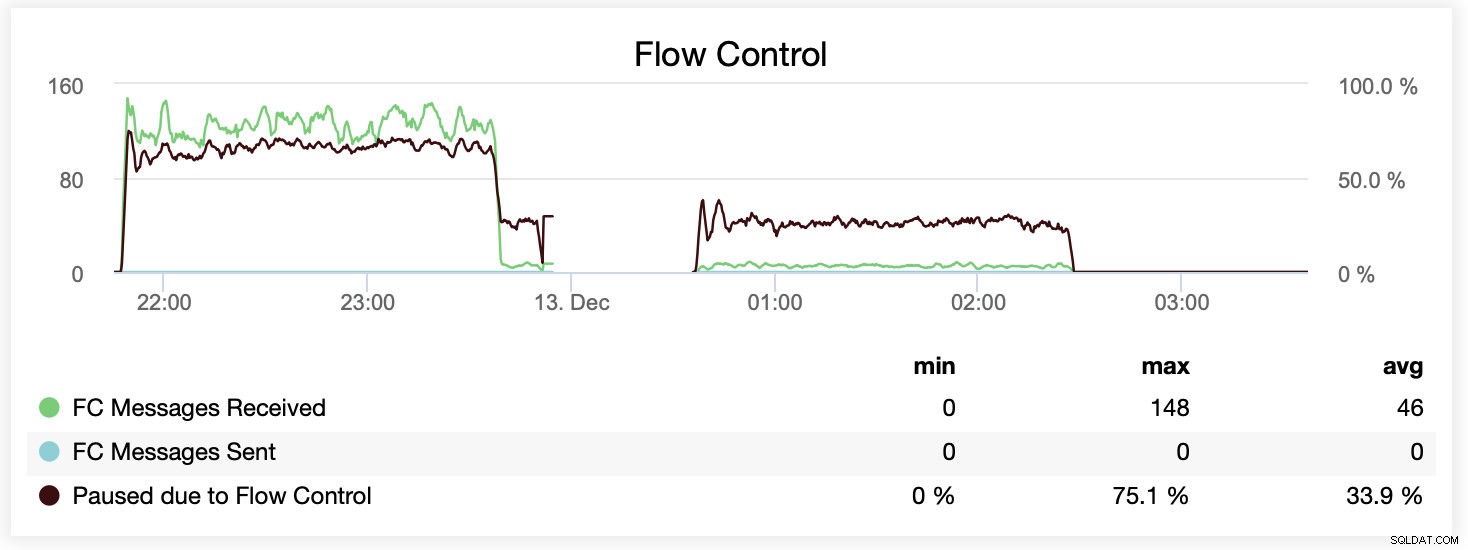
1つのグラフで違いを比較することもできます。最初の部分の最後のドロップは、wsrep_slave_threads=16で実行する最初の試みです。サーバーはバイナリログ用のディスクスペースを使い果たしたため、後でそのベンチマークをもう一度実行する必要がありました。
これはパフォーマンスの観点からどのように変換されましたか?違いは明らかですが、それほど壮観ではありません。
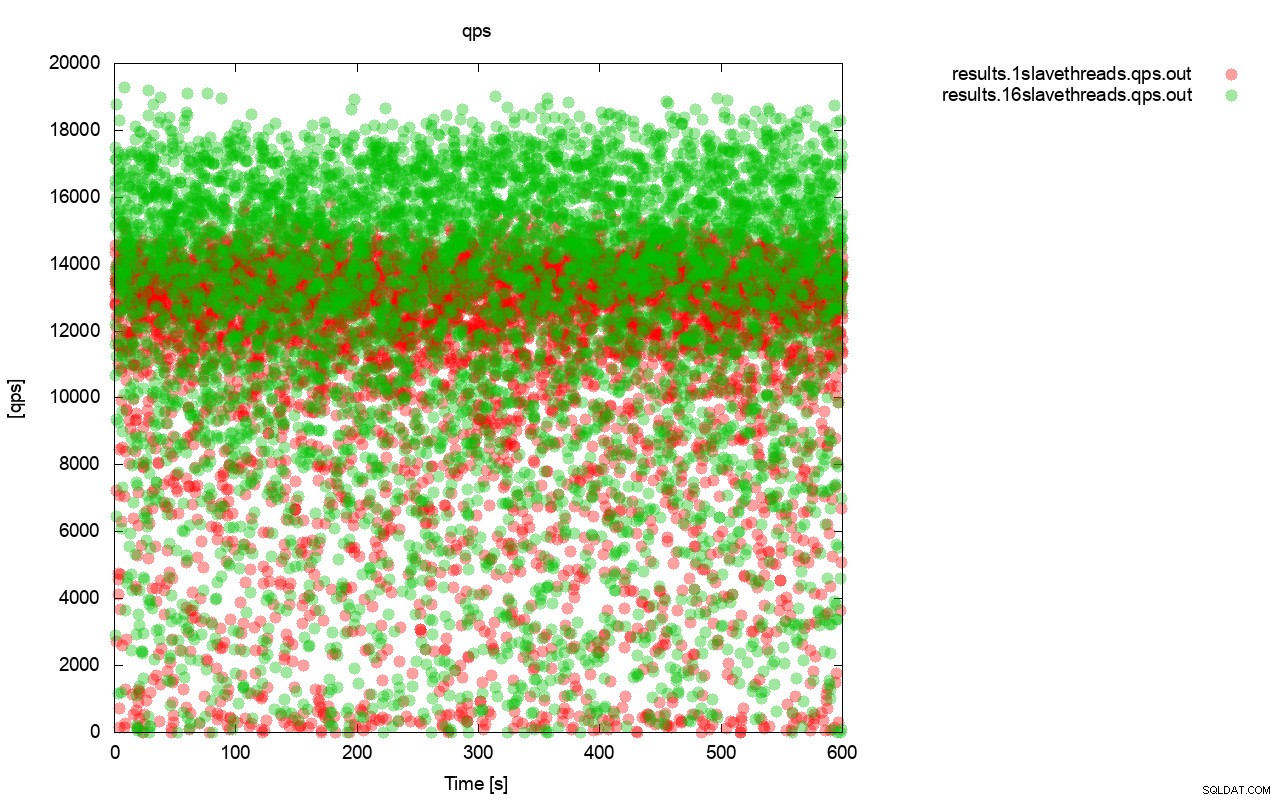
まず、1秒あたりのクエリ数のグラフ。まず第一に、どちらの場合も結果がいたるところにあることに気付くでしょう。これは主に、I / Oストレージの不安定なパフォーマンスと、ランダムに開始されるフロー制御に関連しています。「赤」の結果(wsrep_slave_threads =1)のパフォーマンスは、「緑」の結果(wsrep_slave_threads =1)よりもかなり低いことがわかります。 wsrep_slave_threads =16)。
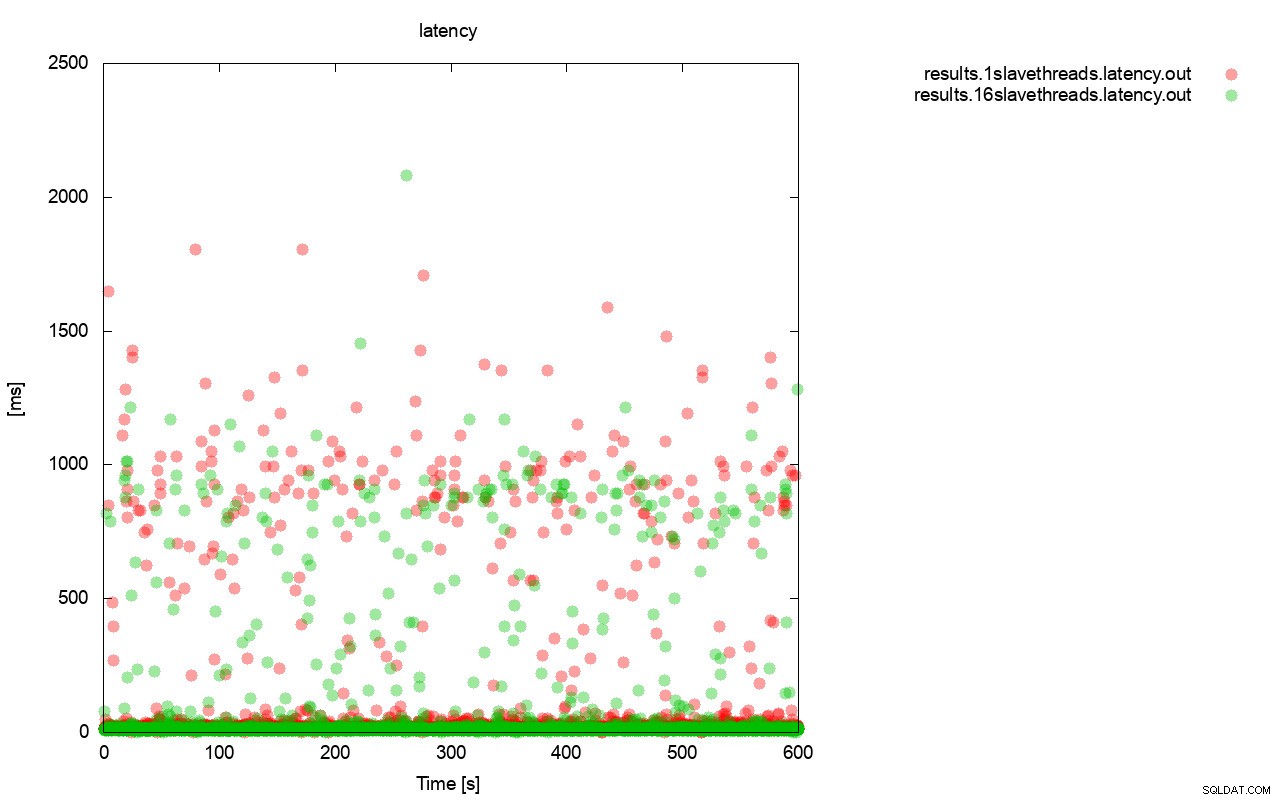
レイテンシーを見ると、非常によく似た状況です。 wsrep_slave_thread =1を使用して実行すると、より多くの(通常はより深い)ストールを確認できます。
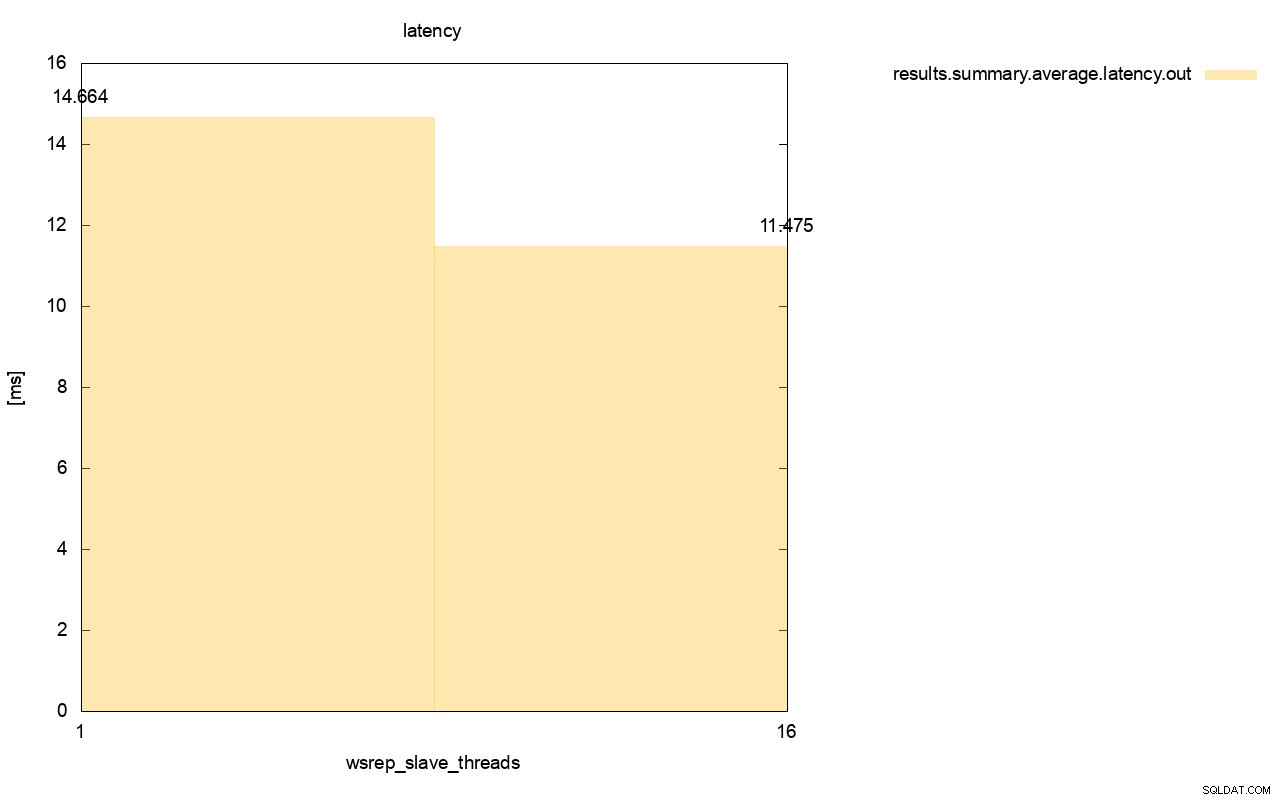
すべての実行の平均レイテンシーを計算すると、この違いはさらに明白になります。wsrep_slave_thread=1のレイテンシーは16のスレーブスレッドのレイテンシーより27%高いことがわかります。これは、レイテンシーを低くしたいので明らかに良くありません。 、高くはありません。
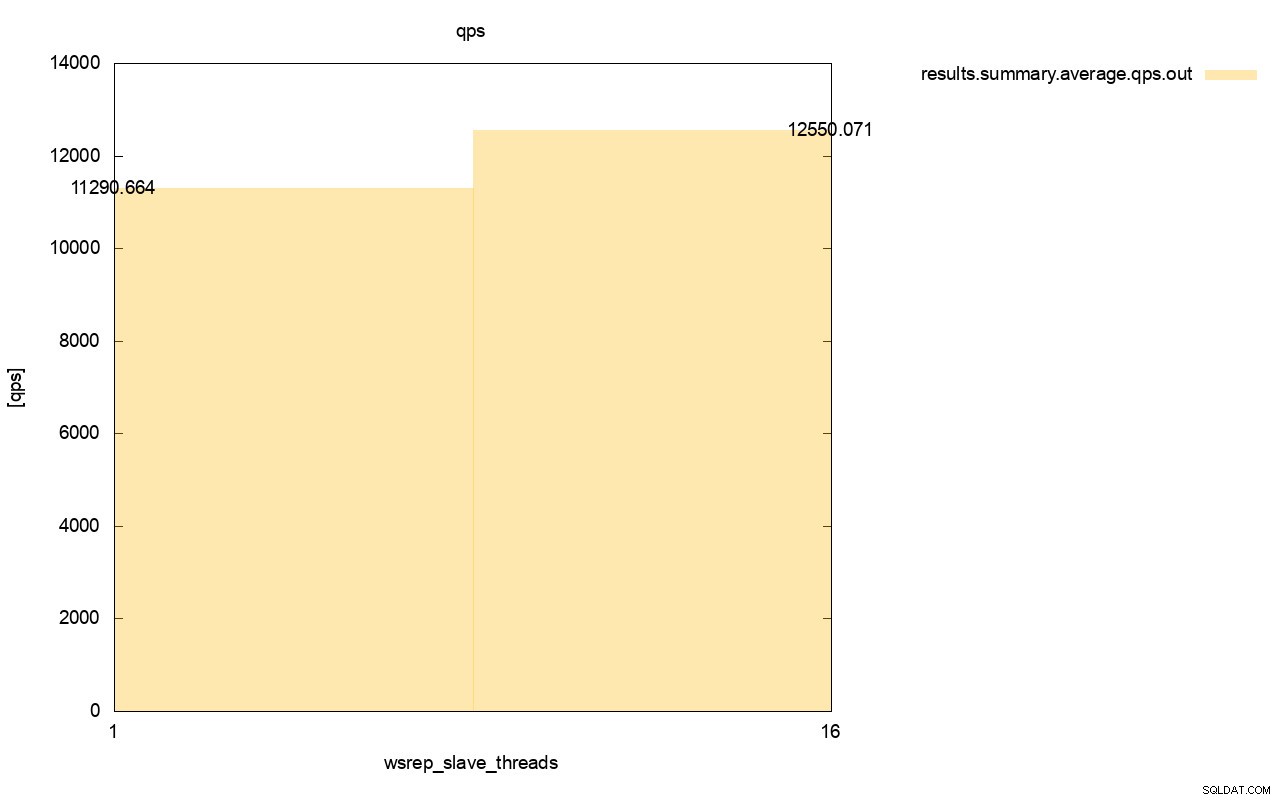
スループットの違いも明らかであり、wsrep_slave_threadsを追加した場合の改善の約11%です。
ご覧のとおり、影響はあります。これは決して16倍ではありませんが(Galeraでスレーブスレッドの数を増やしたとしても)、統計上の異常として分類できないほど十分に目立つようになっています。
この場合、非常に小さなノードを使用したことに注意してください。何千ものIOPSがプロビジョニングされたEBSボリュームで実行されている大規模なインスタンスについて話している場合、違いはさらに大きくなるはずです。
そうすれば、同時操作の数を増やして、sysbenchをさらに積極的に実行できるようになります。これにより、書き込みセットの並列化が改善され、マルチスレッドからのゲインがさらに改善されます。また、ハードウェアが高速であるということは、Galeraがこれらの16スレッドをより効率的に利用できることを意味します。
このようなテストを実行するときは、セットアップをほぼ限界までプッシュする必要があることに注意する必要があります。シングルスレッドレプリケーションは非常に多くの負荷を処理できるため、実際にタスクを処理するのに十分なパフォーマンスを発揮しないようにするには、大量のトラフィックを実行する必要があります。
このブログ投稿で、ライトセットを並行して適用するGaleraClusterの機能とその周辺の制限要因についての洞察が得られることを願っています。