クエリは、負荷の高いすべてのデータベースにキャッシュする必要があります。データベースがすべてのトラフィックを適切なパフォーマンスで処理する方法はありません。クエリキャッシュを実装できるメカニズムはさまざまです。 MySQLクエリキャッシュから始まります。これは、ほとんどが読み取り専用で同時実行性の低いワークロードで問題なく機能し、同時実行性の高いワークロード(OracleがMySQL 8.0で削除した範囲)には存在しません。外部のKey-ValueストアまでRedis、memcached、CouchBaseなど。
外部の専用データストアを使用する際の主な問題(MySQLクエリキャッシュを誰にも使用することはお勧めしません)は、これが管理する別のデータストアであるということです。これは、維持するためのさらに別の環境、処理するためのスケーリングの問題、デバッグするためのバグなどです。
では、プロキシを利用して1つの石で2羽の鳥を殺してみませんか?ここでの前提は、本番環境でプロキシを使用していることです。プロキシはインスタンス間でクエリの負荷を分散し、アプリケーションに単純なエンドポイントを提供することで基盤となるデータベーストポロジをマスクするのに役立ちます。 ProxySQLは、キャッシングレイヤーとして追加で機能できるため、このジョブに最適なツールです。このブログ投稿では、ClusterControlを使用してProxySQLにクエリをキャッシュする方法を紹介します。
ProxySQLでクエリキャッシュはどのように機能しますか?
まず、少し背景があります。 ProxySQLはクエリルールを介してトラフィックを管理し、同じメカニズムを使用してクエリキャッシュを実行できます。 ProxySQLは、キャッシュされたクエリをメモリ構造に格納します。キャッシュされたデータは、存続可能時間(TTL)設定を使用して削除されます。 TTLはクエリルールごとに個別に定義できるため、個別のTTLを使用してクエリルールを個別のクエリごとに定義するか、またはトラフィック。
クエリキャッシュの使用方法を定義する2つの構成設定があります。まず、 mysql-query_cache_size_MB これは、クエリキャッシュサイズのソフト制限を定義します。これは厳しい制限ではないため、ProxySQLはそれよりもわずかに多くのメモリを使用する可能性がありますが、メモリ使用率を制御するには十分です。微調整できる2番目の設定は、 mysql-query_cache_stores_empty_resultです。 。空の結果セットがキャッシュされるかどうかを定義します。
ProxySQLクエリキャッシュは、Key-Valueストアとして設計されています。値はクエリの結果セットであり、キーは、ユーザー、スキーマ、クエリテキストなどの連結された値で構成されます。次に、その文字列からハッシュが作成され、そのハッシュがキーとして使用されます。
ClusterControlを使用したクエリキャッシュとしてのProxySQLの設定
初期設定として、1つのマスターと1つのスレーブのレプリケーションクラスターがあります。 ProxySQLも1つあります。
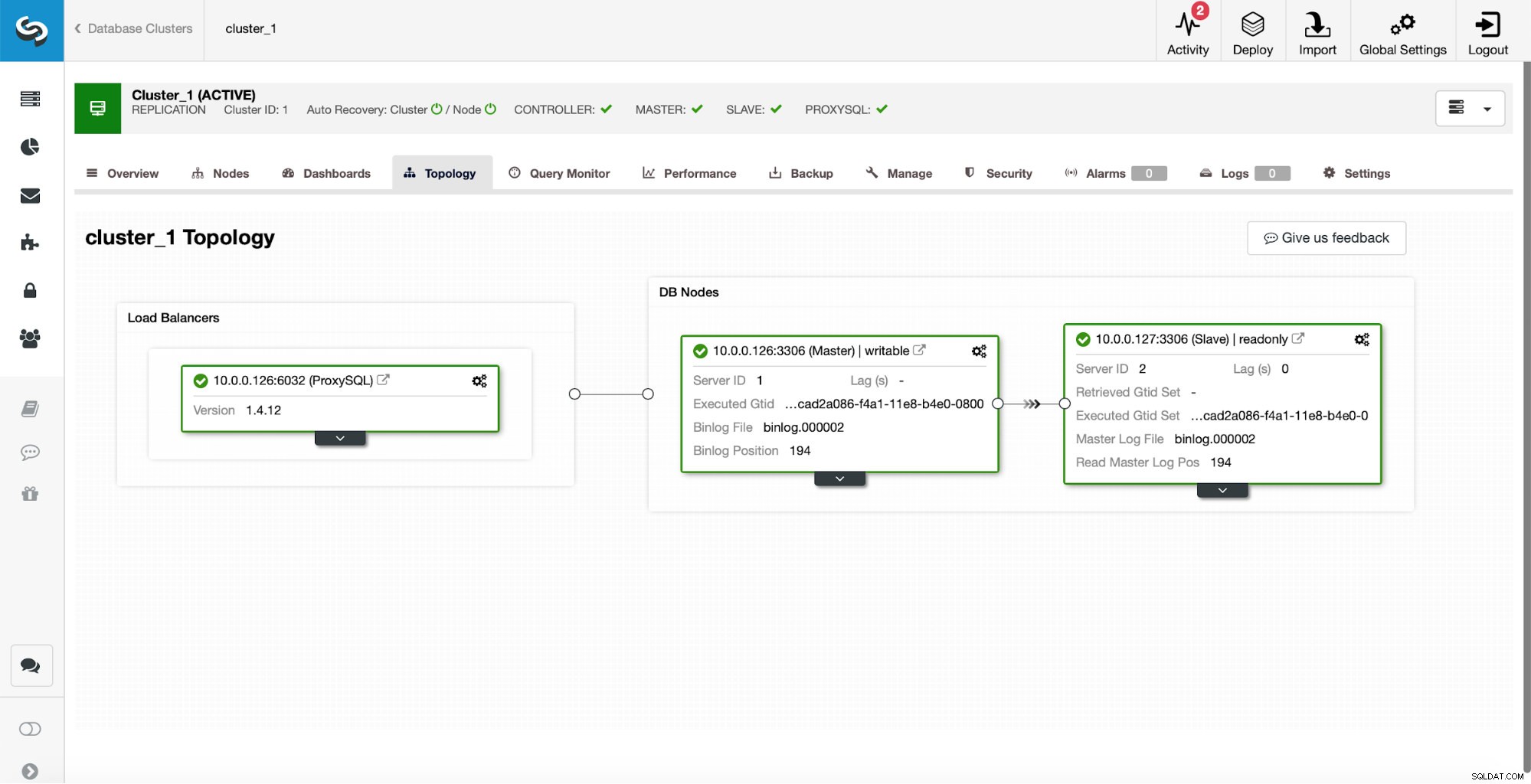
これは、プロキシレイヤーに何らかの高可用性を実装する必要があるため(たとえば、複数のProxySQLインスタンスをデプロイし、フローティング仮想IP用にそれらの上に保持することによって)、本番環境グレードのセットアップではありませんが、テストには十分すぎるでしょう。
まず、ProxySQLの構成を確認して、クエリキャッシュの設定が希望どおりであることを確認します。
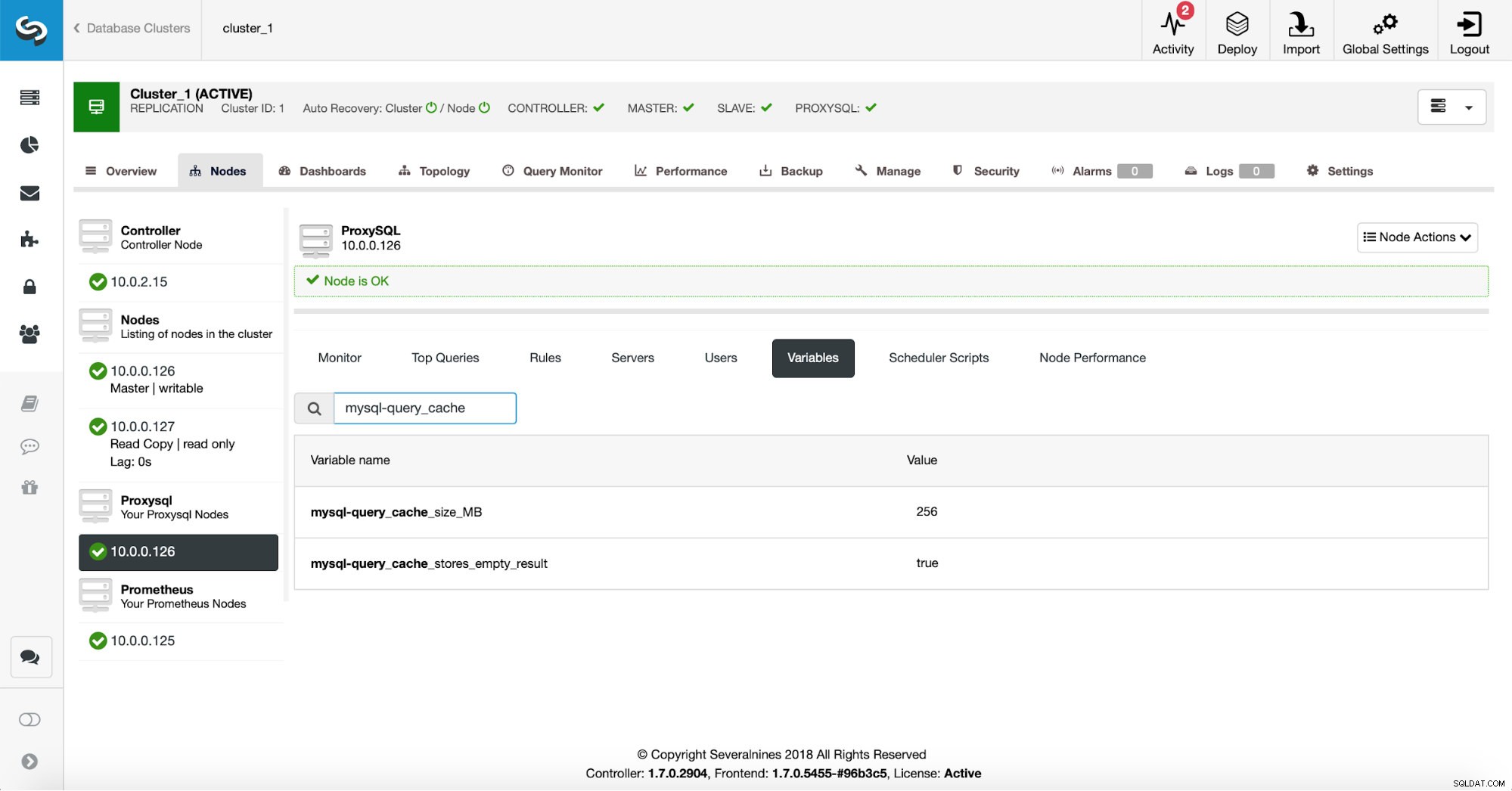
256 MBのクエリキャッシュはほぼ適切であり、空の結果セットもキャッシュする必要があります。データを返さないクエリでも、何も返さないことを確認するために多くの作業を行う必要がある場合があります。
次のステップは、キャッシュするクエリに一致するクエリルールを作成することです。 ClusterControlでこれを行うには2つの方法があります。
クエリルールの手動追加
最初の方法では、もう少し手動で操作する必要があります。 ClusterControlを使用すると、キャッシュを実行するクエリルールを含め、必要なクエリルールを簡単に作成できます。まず、ルールのリストを見てみましょう:
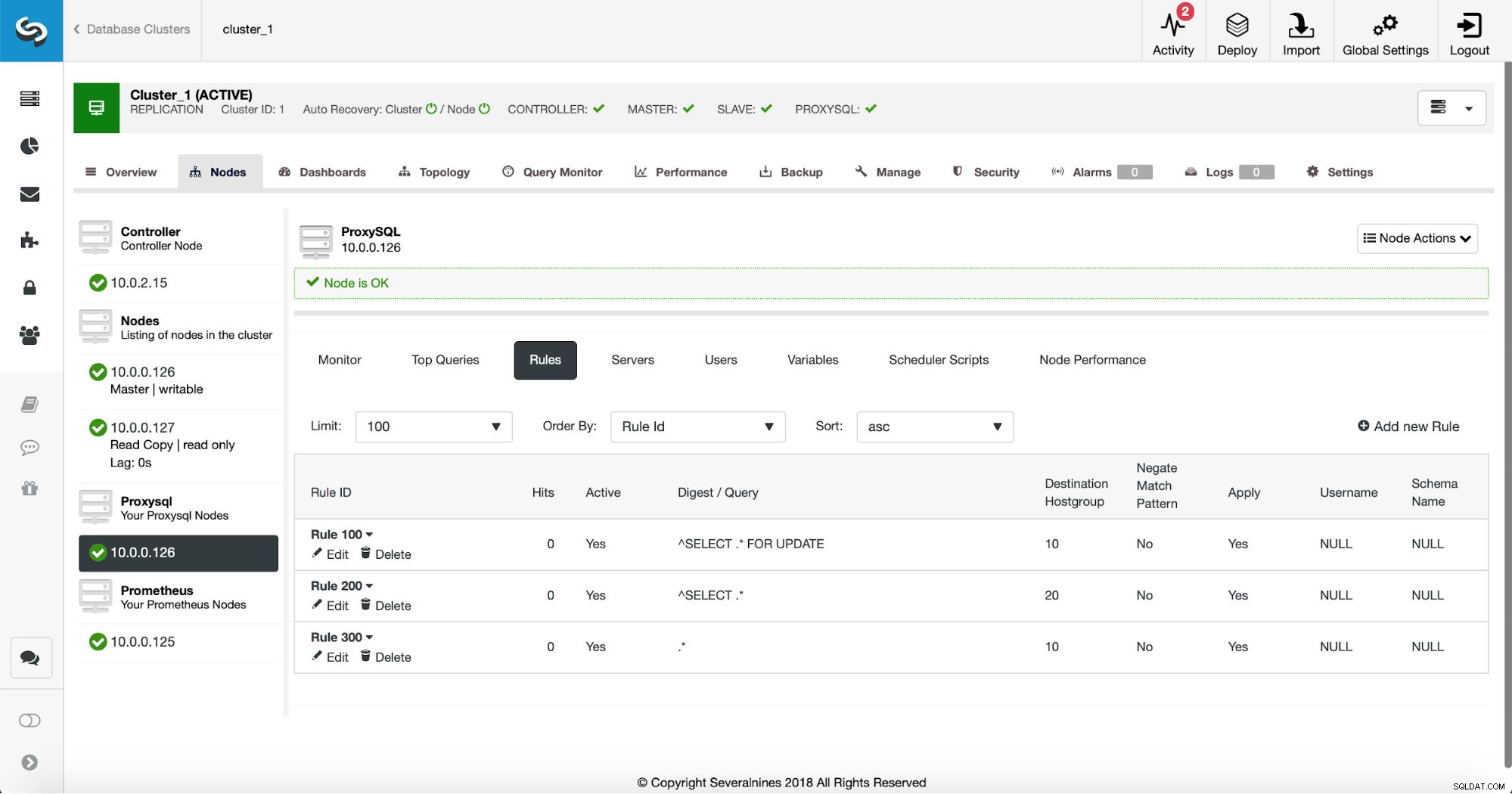
この時点で、読み取り/書き込み分割を実行するための一連のクエリルールがあります。最初のルールのIDは100です。新しいクエリルールはその前に処理する必要があるため、より低いルールIDを使用します。次のようなクエリのキャッシュを実行するクエリルールを作成しましょう:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY c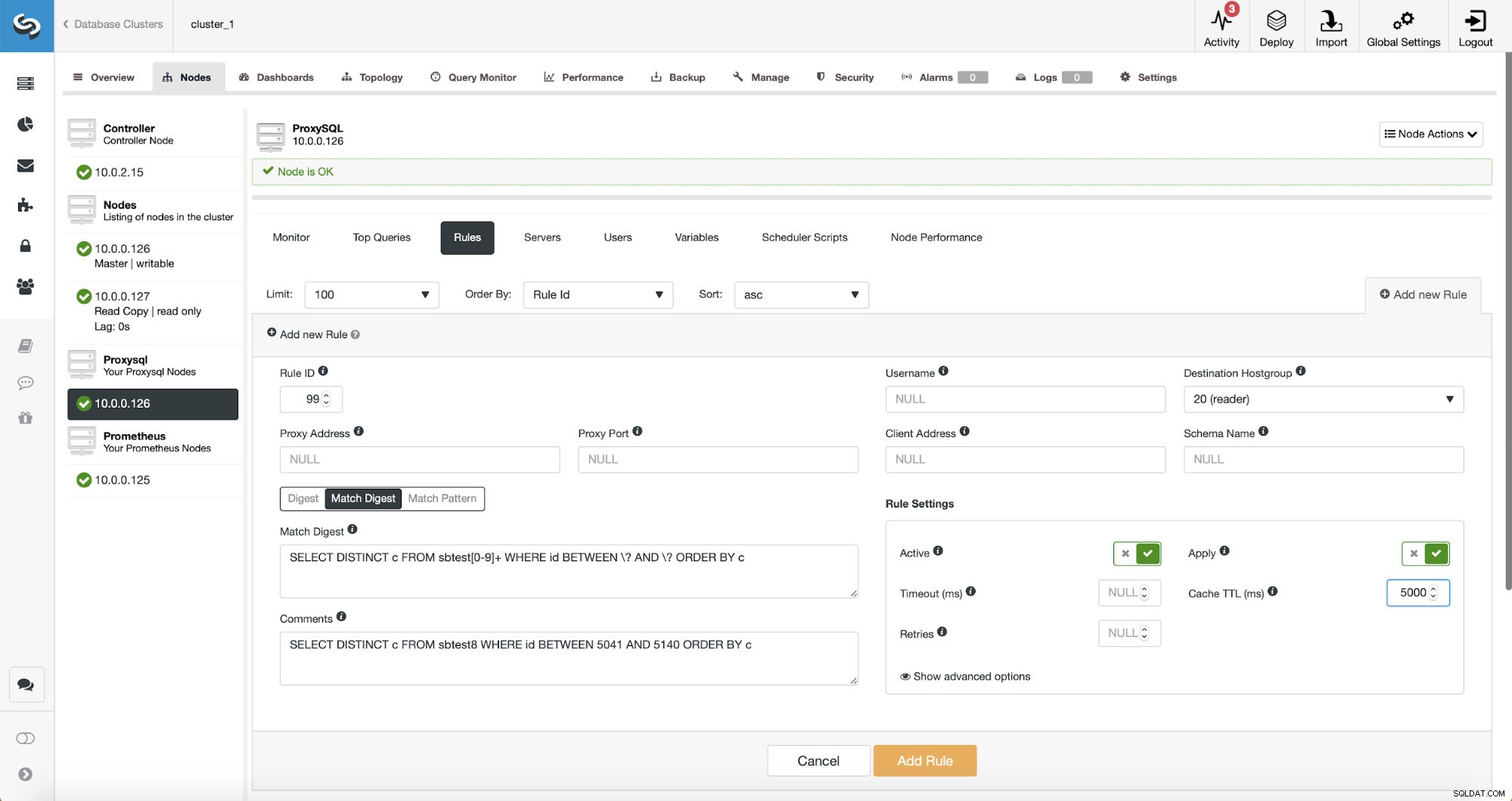
クエリを照合するには、ダイジェスト、一致ダイジェスト、一致パターンの3つの方法があります。ここでそれらについて少し話しましょう。まず、ダイジェストを一致させます。ここで、あるクエリタイプを表す一般化されたクエリ文字列に一致する正規表現を設定できます。たとえば、クエリの場合:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY c一般的な表現は次のようになります:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN ? AND ? ORDER BY cご覧のとおり、WHERE句の引数が削除されているため、このタイプのすべてのクエリは単一の文字列として表されます。このオプションは、クエリタイプ全体に一致し、さらに重要なことに、空白が削除されるため、非常に便利です。これにより、奇妙な改行、文字列の最初または最後の空白などを考慮する必要がなくなるため、正規表現を非常に簡単に記述できます。
ダイジェストは基本的に、ProxySQLがマッチダイジェストフォームに対して計算するハッシュです。
最後に、Match Patternは、クライアントから送信された完全なクエリテキストと照合します。この場合、クエリの形式は次のとおりです。
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cこれらのクエリをすべてクエリルールでカバーするため、マッチダイジェストを使用します。その特定のクエリだけをキャッシュしたい場合は、一致パターンを使用することをお勧めします。
使用する正規表現は次のとおりです。
SELECT DISTINCT c FROM sbtest[0-9]+ WHERE id BETWEEN \? AND \? ORDER BY c1つの例外を除いて、文字通り正確に一般化されたクエリ文字列を照合しています。このクエリは複数のテーブルにヒットすることがわかっているため、それらすべてに一致する正規表現を追加しました。
これが完了すると、クエリルールが有効かどうかを確認できます。
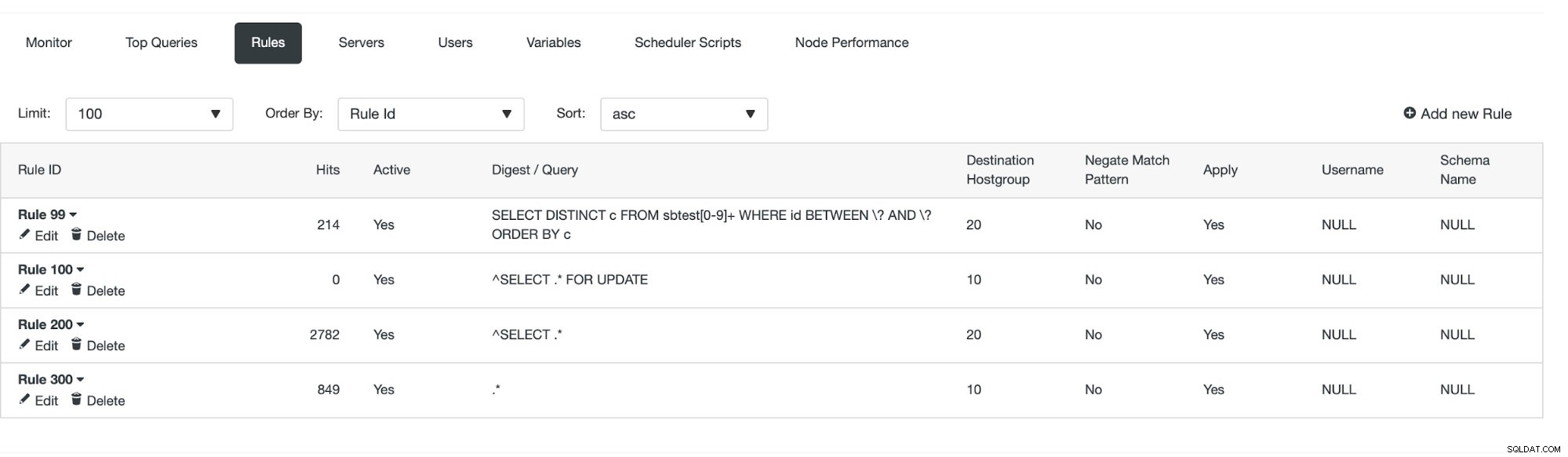
「ヒット」が増加していることがわかります。これは、クエリルールが使用されていることを意味します。次に、クエリルールを作成する別の方法を見ていきます。
ClusterControlを使用したクエリルールの作成
ProxySQLには、ルーティングしたクエリの統計を収集する便利な機能があります。実行時間、特定のクエリが実行された回数などのデータを追跡できます。このデータはClusterControlにも存在します:
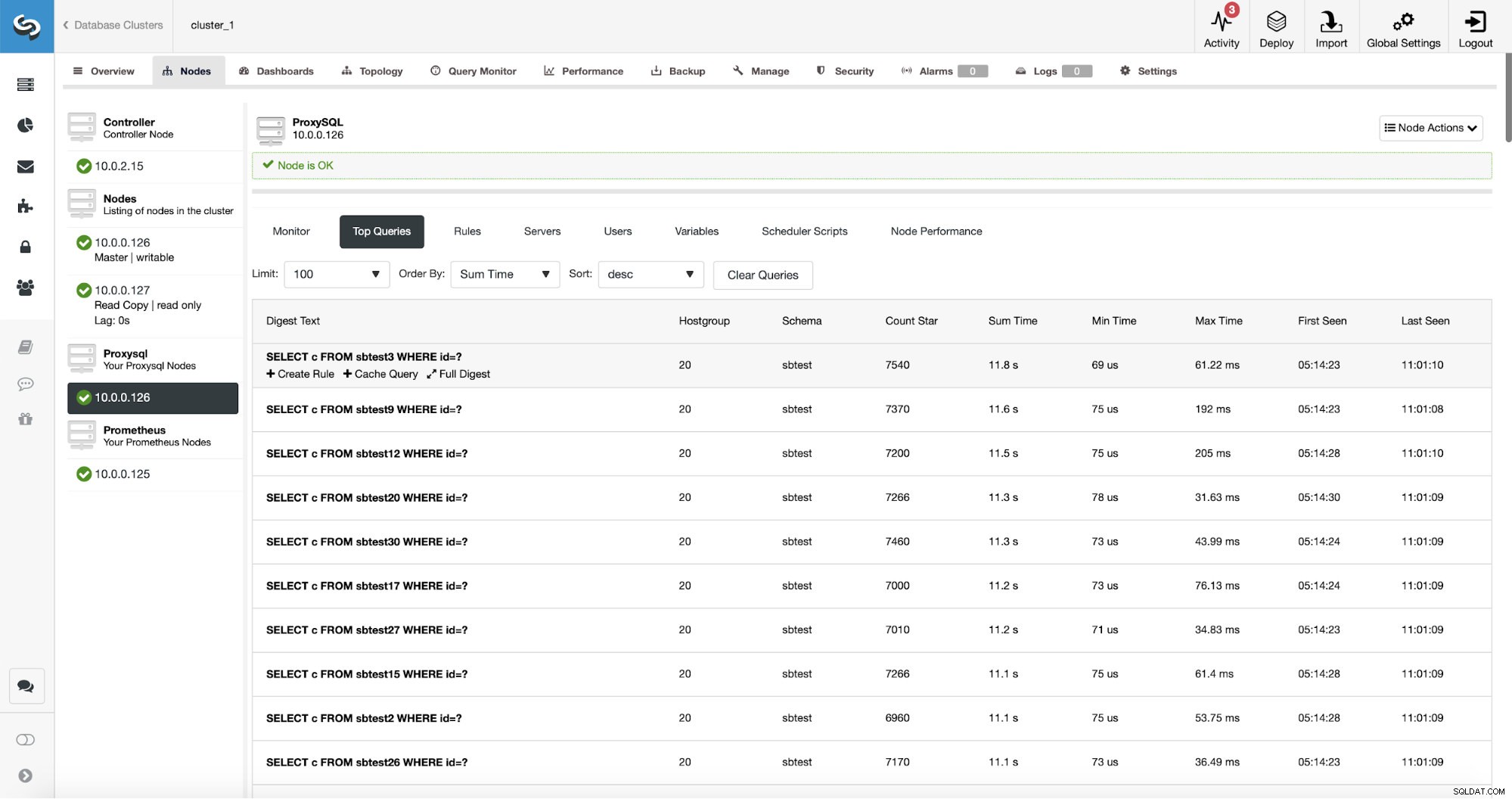
さらに良いことに、特定のクエリタイプをポイントすると、それに関連するクエリルールを作成できます。この特定のクエリタイプを簡単にキャッシュすることもできます。
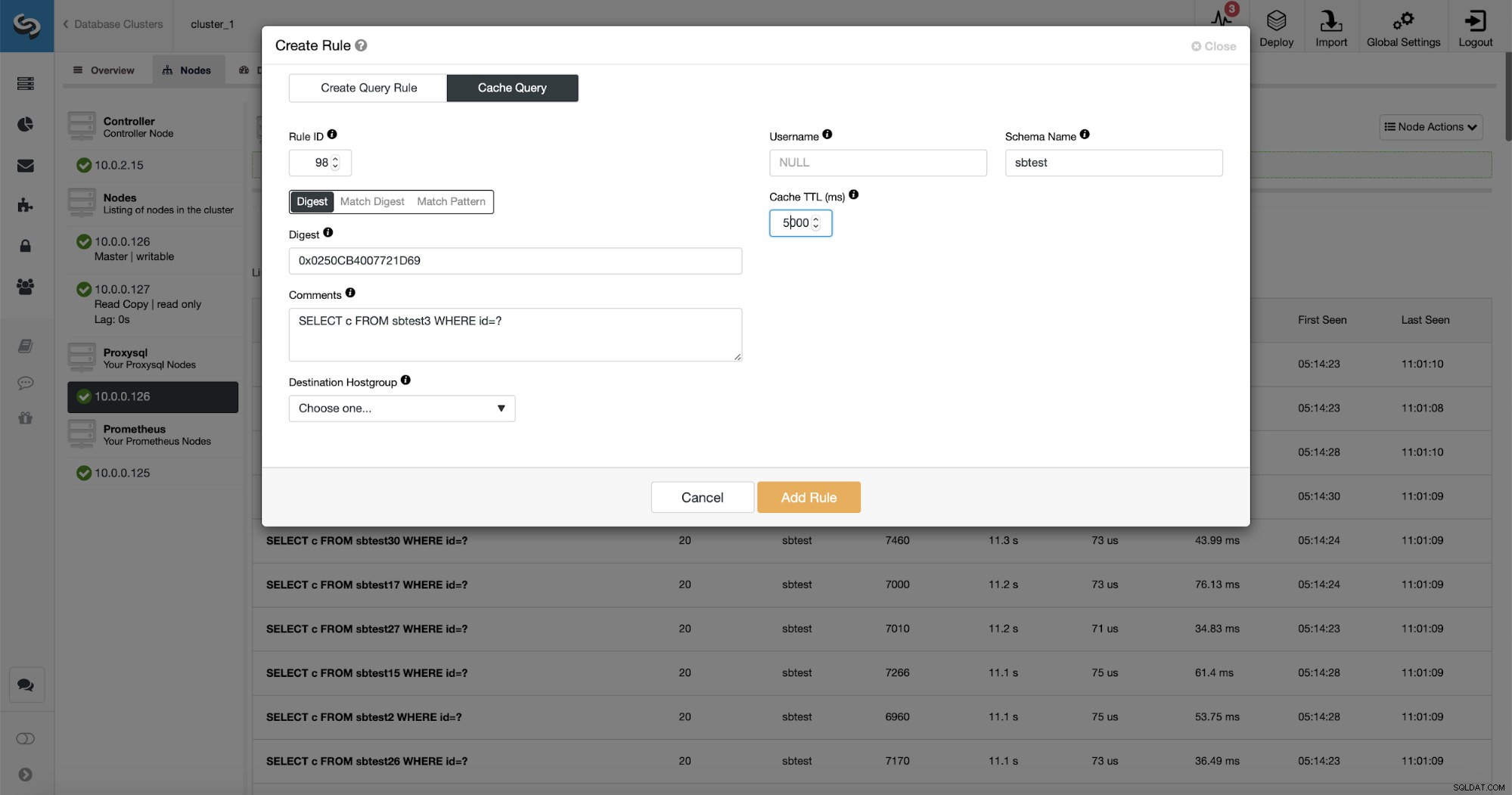
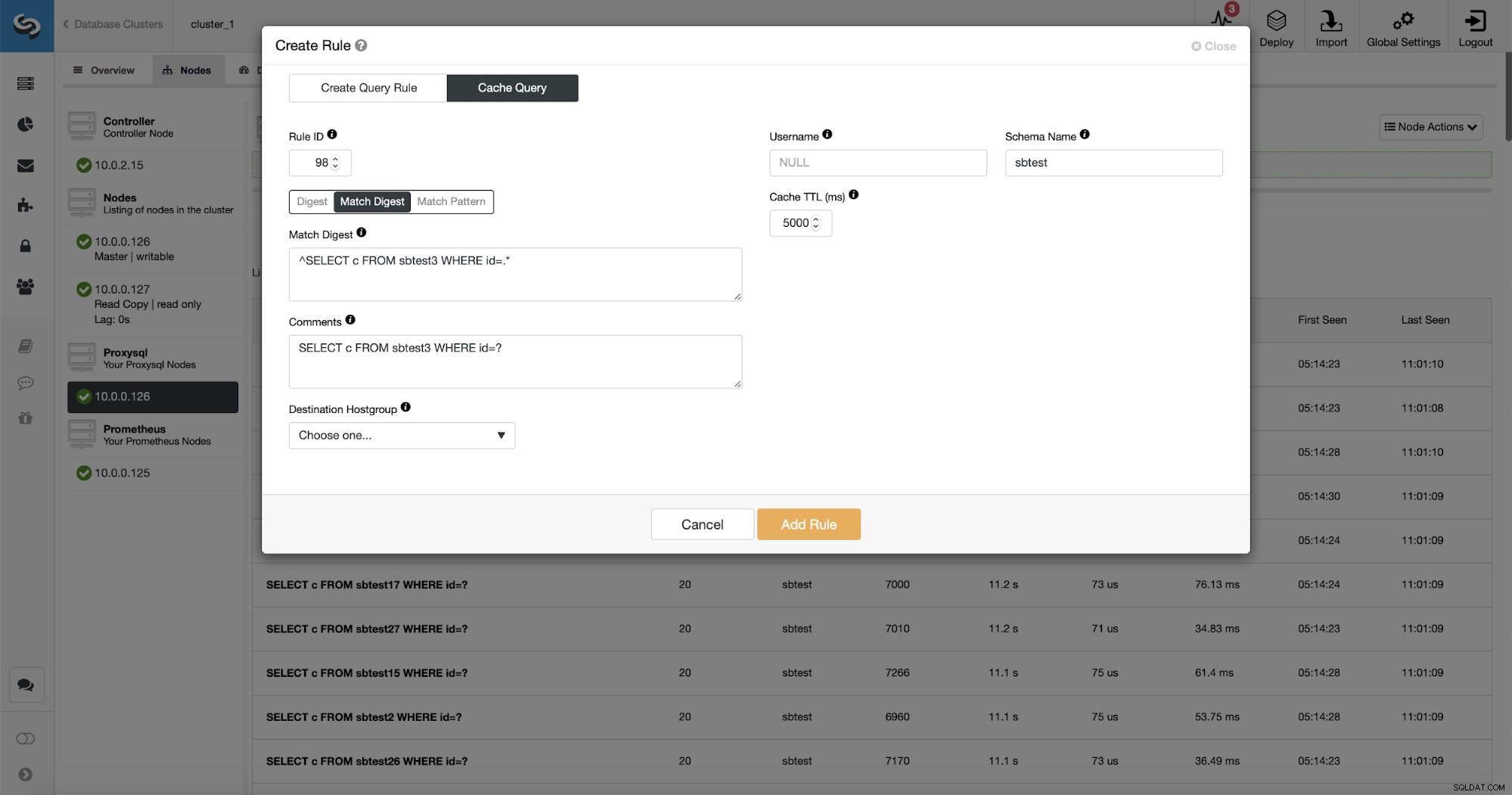
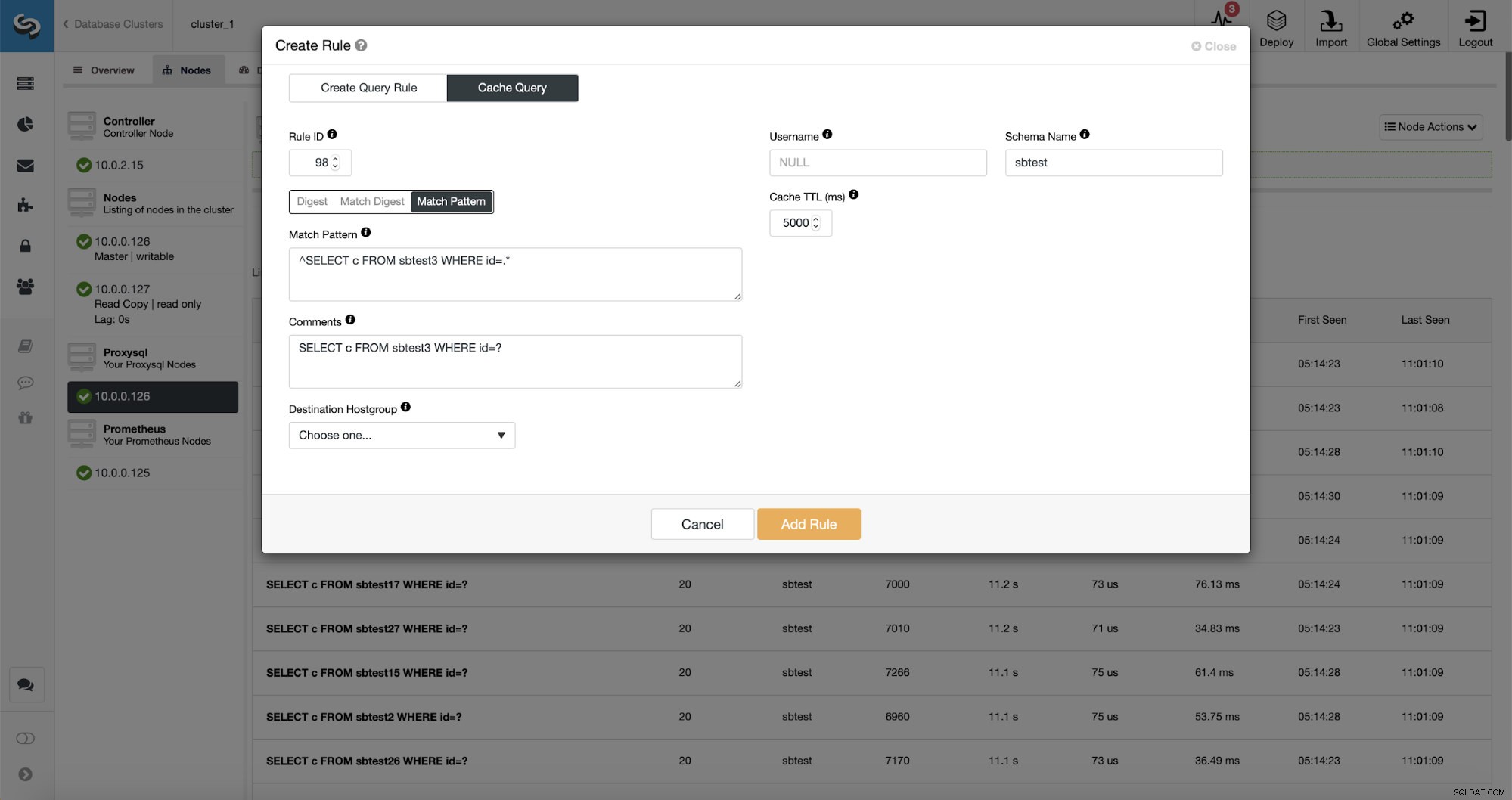
ご覧のとおり、ルールIP、キャッシュTTL、スキーマ名などのデータの一部はすでに入力されています。 ClusterControlは、使用することを決定したマッチングメカニズムに基づいてデータも入力します。特定のクエリタイプにハッシュを簡単に使用できます。正規表現を微調整する場合は、[一致ダイジェスト]または[一致パターン]を使用できます(たとえば、以前と同じように実行し、正規表現を拡張してすべてのsbtestスキーマのテーブル)。
ProxySQLでクエリキャッシュルールを簡単に作成するために必要なのはこれだけです。 ClusterControlをダウンロードして、今すぐお試しください。