ClusterControl 1.2.11が2015年にリリースされて以来、MariaDBMaxScaleはデータベースロードバランサーとしてサポートされてきました。何年にもわたって、MaxScaleは成長し、成熟し、いくつかの豊富な機能を追加してきました。最近、MariaDB MaxScale 2.2がリリースされ、レプリケーションクラスターのフェイルオーバー管理を含むいくつかの新機能が導入されました。
MariaDB MaxScaleは、高可用性、自動フェイルオーバー、手動スイッチオーバー、および自動再結合を備えたマスター/スレーブ展開を可能にします。マスターに障害が発生した場合、MariaDBMaxScaleは最新のスレーブをマスターに自動的にプロモートできます。障害が発生したマスターが回復した場合、MariaDBMaxScaleはそれを新しいマスターのスレーブとして自動的に再構成できます。さらに、管理者は手動で切り替えを実行して、マスターをオンデマンドで変更できます。
以前のブログでは、ClusterControlを使用してMaxScaleをデプロイする方法と、DockerにMariaDBMaxScaleをデプロイする方法について説明しました。 MariaDB MaxScaleにまだ慣れていない人にとっては、MariaDBデータベースサーバー用の高度なプラグインデータベースプロキシです。 Maxscaleは、クライアントアプリケーションとデータベースサーバーの間に位置し、クライアントクエリとサーバー応答をルーティングします。また、サーバーを監視し、サーバーのステータスやレプリケーショントポロジの変更にすばやく気づきます。
Maxscaleは、ProxySQLなどの他の負荷分散テクノロジの特性の一部を共有していますが、この新しいフェイルオーバー機能(監視および自動検出メカニズムの一部)は際立っています。このブログでは、Maxscaleのこのエキサイティングな新機能について説明します。
MariaDBMaxScaleフェイルオーバーメカニズムの概要
マスター検出
別のサーバーに現在のマスターよりも多くのスレーブがある場合でも、モニターがマスターサーバーを突然変更する可能性が低くなりました。 DBAは、現在のマスターを読み取り専用に設定するか、マスターがダウンしている場合はすべてのスレーブを削除することにより、マスターの再選択を強制できます。
マルチマスター設定であっても、一度に1つのサーバーのみがマスターステータスフラグを持つことができます。マルチマスターグループ内の他のサーバーには、リレーマスターとスレーブのステータスフラグが与えられます。
新しいマスター自動選択の切り替え
switchoverコマンドは、モニターインスタンス名のみをパラメーターとして呼び出すことができるようになりました。この場合、モニターは昇格するサーバーを自動的に選択します。
レプリケーションラグの検出
レプリケーションラグの測定では、 Secondarys_Behind_Masterを読み取るだけです。 -スレーブのスレーブステータス出力のフィールド。スレーブは、スレーブが現在処理しているbinlogイベントのタイムスタンプをスレーブ自身のクロックと比較することにより、この値を計算します。スレーブに複数のスレーブ接続がある場合、最小のラグが使用されます。
ディスク容量不足の検出後の自動スイッチオーバー
最近のMariaDBサーバーのバージョンでは、モニターはバックエンドのディスクスペースをチェックし、サーバーが不足しているかどうかを検出できるようになりました。この場合、ディスク容量の少ないマスターから自動的に切り替わるようにモニターを設定できます。スレーブはメンテナンスモードに設定することもできます。ディスク容量は、プロモートする新しいマスターを選択するときに考慮される要素でもあります。
詳細については、switchover_on_low_disk_spaceおよびmaintenance_on_low_disk_spaceを参照してください。
レプリケーションリセット機能
リセット-レプリケーション monitorコマンドは、すべてのスレーブ接続とバイナリログを削除してから、レプリケーションを設定します。データは同期しているが、gtidは同期していない場合に便利です。
フェイルオーバー/スイッチオーバー/再結合でのスケジュールされたイベントの処理
イベントスケジューラスレッドによって起動されたサーバーイベントは、クラスター変更操作中に処理されるようになりました。詳細については、handle_server_eventsを参照してください。
外部マスターサポート
モニターは、クラスター内のサーバーが外部マスター(MaxScaleモニターによって監視されていないサーバー)から複製しているかどうかを検出できます。複製サーバーがクラスターマスターサーバーである場合、クラスター自体に外部マスターがあると見なされます。
フェイルオーバー/スイッチオーバーが発生した場合、新しいマスターサーバーはクラスター外部マスターサーバーから複製するように設定されます。レプリケーションのユーザー名とパスワードは、replication_userとreplication_passwordで定義されています。使用されるアドレスとポートは、古いクラスターマスターサーバーのSHOW ALLSLAVESSTATUSで表示されるものです。スイッチオーバーの場合、トポロジを維持するために、古いマスターは外部サーバーからの複製も停止します。
フェイルオーバー後、新しいマスターは外部マスターから複製しています。障害が発生した古いマスターがオンラインに戻った場合は、外部サーバーからも複製しています。状況を正常化するには、auto_rejoinをオンにするか、手動で再結合を実行します。これにより、古いマスターが現在のクラスターマスターにリダイレクトされます。
フェイルオーバーはどのように有用で適用可能ですか?
フェイルオーバーは、ダウンタイムを最小限に抑え、日常のメンテナンスを実行し、不幸な時期に発生する可能性のある悲惨で不要なメンテナンスを処理するのに役立ちます。クライアントアプリケーションをバックエンドデータベースサーバーから隔離するMaxScaleの機能により、ダウンタイムを最小限に抑えるのに役立つ貴重な機能が追加されます。
MaxScale監視プラグインは、バックエンドデータベースサーバーの状態を継続的に監視します。次に、MaxScaleのルーティングプラグインはこのステータス情報を使用して、稼働中のバックエンドデータベースサーバーにクエリを常にルーティングします。その後、クラスターの一部のサーバーがメンテナンス中または障害が発生している場合でも、バックエンドデータベースクラスターにクエリを送信できます。
MaxScaleの高い構成可能性により、クラスター構成の変更をクライアントアプリケーションに対して透過的に保つことができます。たとえば、新しいサーバーをマスタースレーブクラスターに管理上追加またはマスタースレーブクラスターから削除する必要がある場合は、maxadminCLIコンソールを使用してモニターおよびルータープラグインのサーバーリストにMaxScale構成を追加するだけです。クライアントアプリケーションはこの変更を完全に認識せず、データベースクエリをMaxScaleのリスニングポートに送信し続けます。
メンテナンス中のデータベースサーバーの設定はシンプルで簡単です。 maxctrlを使用して次のコマンドを実行するだけで、MaxScaleはこのサーバーへのクエリの送信を停止します。たとえば、
maxctrl: set server DB_785 maintenance
OK次に、サーバーの状態を次のように確認します。
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘メンテナンスモードになると、MaxScaleはサーバーへの新しいリクエストのルーティングを停止します。現在のリクエストの場合、MaxScaleはこれらのセッションを強制終了しませんが、実行を完了できるようにし、メンテナンスモード中に実行中のクエリを中断しません。また、メンテナンスモードは永続的ではないことに注意してください。ノードがメンテナンスモードのときにMaxScaleが再起動すると、MariaDBMaxScaleの新しいインスタンスはこのモードを尊重しません。ノードを使用するように複数のMariaDBMaxScaleインスタンスが構成されている場合、それらのメンテナンスモードを各MariaDBMaxScaleインスタンス内で設定する必要があります。ただし、1つのMariaDB MaxScaleインスタンス内の複数のサービスがサーバーを使用している場合は、すべてのサービスがモードの変更に注意するために、サーバーでメンテナンスモードを1回設定するだけで済みます。
メンテナンスが完了したら、次のコマンドでサーバーをクリアします。たとえば、
maxctrl: clear server DB_785 maintenance
OK通常に戻っているかどうかを確認するには、コマンド listserversを実行するだけです。 。
ClusterControlUIを介して特定の管理アクションを適用することもできます。以下のスクリーンショットの例を参照してください:
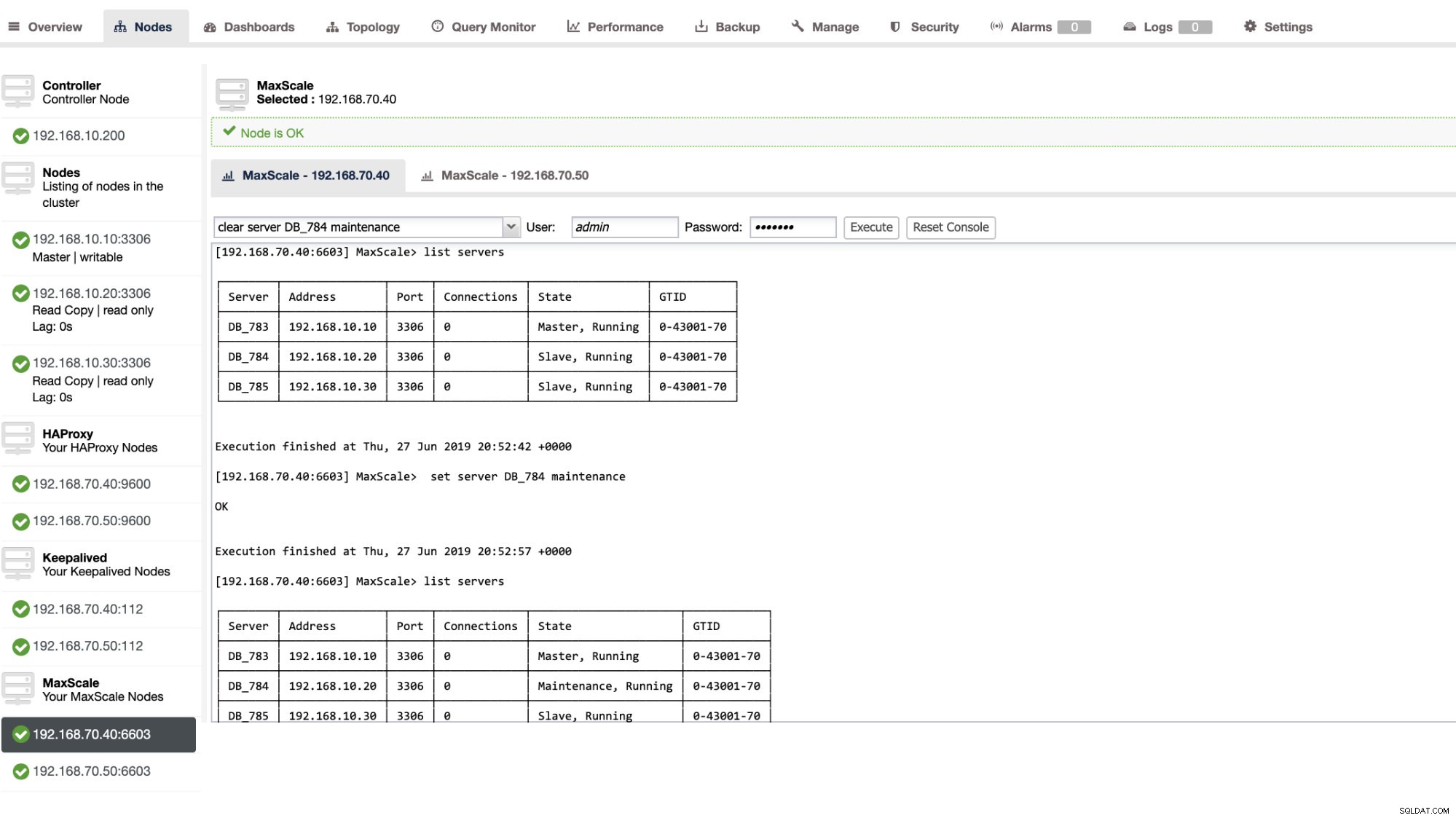
MaxScaleフェイルオーバーの実行中
自動フェイルオーバー
MariaDBのMaxScaleフェイルオーバーは非常に効率的に実行され、期待どおりにスレーブを再構成します。このテストでは、ClusterControlによって作成および管理された次の構成ファイルセットがあります。以下を参照してください:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonauto_failoverのみに注意してください およびauto_rejoin MaxScaleロードバランサーをセットアップするとClusterControlがデフォルトでこれを追加しないため、追加した変数です(ClusterControlを使用してMaxScaleをセットアップする方法については、このブログを確認してください)。構成ファイルに変更を適用したら、MariaDBMaxScaleを再起動する必要があることを忘れないでください。実行するだけです
systemctl restart maxscale行ってもいいです。
フェイルオーバーテストに進む前に、まずクラスターの状態を確認しましょう。
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘よさそうだ!
マスターノードで純粋なキラーコマンドKILL-9$(pidof mysqld)を使用してマスターを強制終了しましたが、当然のことながら、モニターはこれにすばやく気づき、フェイルオーバーをトリガーします。次のようにログを参照してください:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]それでは、クラスターの状態を見てみましょう。
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘以前はマスターであったノード192.168.10.10がダウンしています。再起動して、自動再参加がトリガーされるかどうかを確認しようとしました。ログで 2019-06-28 06:39:20.165に気づいたように ノードの状態をすばやく把握し、DBAがノードをオンにする手間をかけずに構成を自動的にセットアップします。
最後にその状態を確認すると、期待どおりに完全に機能しているように見えます。以下を参照してください:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘元マスターが修正されて回復したので、切り替えたい
以前のマスターに切り替えるのも面倒ではありません。これは、maxctrl(または以前のバージョンのMaxScaleではmaxadmin)またはClusterControl UI(前に示したように)を使用して操作できます。
以前のレプリケーションクラスターヘルスの以前の状態を参照して、192.168.10.10(現在はスレーブ)をマスター状態に戻したいと考えました。先に進む前に、使用するモニターを最初に特定する必要がある場合があります。これは、以下のコマンドで確認できます。
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘取得したら、以下のコマンドを実行して切り替えることができます。
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OK次に、クラスターの状態をもう一度確認します。
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘完璧に見えます!
ログは、それがどのように進んだか、および切り替え中の一連のアクションを詳細に示します。以下の詳細を参照してください:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]間違ったスイッチオーバーの場合、それは続行されないため、上記のログに示されているようにエラーが生成されます。だから、あなたは安全で、恐ろしい驚きはまったくありません。
MaxScaleを高可用性にする
フェイルオーバーに関しては少し話題から外れていますが、高可用性とそれがMariaDB MaxScaleフェイルオーバーとどのように関連しているかに関して、ここにいくつかの貴重なポイントを追加したいと思います。
MaxScaleを高可用性にすることは、システムがクラッシュしたり、ディスクの破損や仮想マシンの破損が発生した場合に重要な部分です。これらの状況は避けられず、これらの予期しないメンテナンスサイクルが発生した場合、自動フェイルオーバーセットアップの状態に影響を与える可能性があります。
レプリケーションクラスタータイプの環境では、これは非常に有益であり、特定のMaxScaleセットアップに強くお勧めします。これの目的は、常に1つのMaxScaleインスタンスのみがクラスターを変更できるようにすることです。キープアライブを使用してセットアップした場合、これはステータスがMASTERのインスタンスです。 MaxScale自体はその状態を認識していませんが、 maxctrl (または maxadmin 以前のバージョンでは)MaxScaleインスタンスをパッシブモードに設定できます。バージョン2.2.2の時点では、パッシブMaxScaleはアクティブMaxScaleと同様に動作しますが、フェイルオーバー、スイッチオーバー、または再結合を実行しないという違いがあります。これらのコマンドの手動バージョンでさえ、エラーで終了します。パッシブ/アクティブモードの違いは将来拡張される可能性があるため、MaxScaleでのこのような変更にご注目ください。これを行うには、次のようにします。
maxctrl: alter maxscale passive true
OK後で次のコマンドを実行して、これを確認できます。
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │キープアライブで高可用性をセットアップする方法を確認したい場合は、MariaDBからのこの投稿を確認してください。
VIP処理
さらに、MaxScaleにはVIP処理が組み込まれていないため、Keepalivedを使用して処理できます。 MASTER状態ノードに割り当てられたvirtual_ipaddressを使用するだけです。これは、MHAがmaster_failover_script変数で行うのと同じように、仮想IP管理を思い付く可能性があります。前述のように、MariaDBによるこのKeepalivedwithMaxScaleセットアップブログ投稿を確認してください。
結論
MariaDB MaxScaleは機能が豊富で、プロキシとロードバランサーであるだけでなく、大規模な組織が求めているフェイルオーバーメカニズムも提供する多くの機能を備えています。これはほぼ万能のソフトウェアですが、もちろん、特定のアプリケーションがProxySQLなどの他のロードバランサーとは対照的に必要になる可能性がある制限があります。
ClusterControlは、自動フェイルオーバーとマスター自動検出メカニズムに加えて、Maxscaleやその他の負荷分散テクノロジーを展開する機能を備えたクラスターとノードのリカバリも提供します。
これらの各ツールにはさまざまな機能がありますが、MariaDB MaxScaleはClusterControl内で十分にサポートされており、Keepalived、HAProxyと一緒に適切にデプロイできるため、日常のタスクをスピードアップできます。