(仮想的に)同期レプリケーションを備えたGalera Clusterは、さまざまなタイプの環境で一般的に使用されています。新しいノードを追加してスケーリングするのは難しくありません(または、ClusterControlを使用する場合は数回クリックするだけです)。
同期レプリケーションの主な問題は、同期部分です。これにより、クラスター全体の速度が最も遅いノードと同じになることがよくあります。クラスタで実行される書き込みはすべて、すべてのノードに複製され、それらで認証される必要があります。何らかの理由でこのプロセスが遅くなると、書き込みに対応するクラスターの機能に深刻な影響を与える可能性があります。次に、フロー制御が開始されます。これは、最も遅いノードが引き続き負荷に対応できるようにするためです。これにより、実際の環境で発生する一般的なシナリオのいくつかでは非常に注意が必要です。
まず、地理的に分散したディザスタリカバリについて説明しましょう。もちろん、ワイドエリアネットワーク全体でクラスタを実行できますが、遅延の増加はクラスタのパフォーマンスに大きな影響を及ぼします。これにより、特に遅延が大きい場合の長距離では、このような設定を使用する機能が大幅に制限されます。
もう1つの非常に一般的なユースケース-メジャーバージョンアップグレードのテスト環境。可能であっても、同じクラスター内に異なるバージョンのMariaDBGaleraClusterノードを混在させることはお勧めできません。一方、より新しいバージョンへの移行には、詳細なテストが必要です。理想的には、読み取りと書き込みの両方がテストされているはずです。これを実現する1つの方法は、別のGaleraクラスターを作成してテストを実行することですが、できるだけ本番環境に近い環境でテストを実行する必要があります。プロビジョニングが完了すると、クラスターを実際のクエリでのテストに使用できますが、本番環境に近いワークロードを生成することは困難です。データが最新ではないため、本番トラフィックの一部をそのようなテストシステムに移動することはできません。
最後に、移行自体。繰り返しになりますが、前に述べたように、同じクラスター内で古いバージョンと新しいバージョンのGaleraノードを混在させることが可能であっても、それを行うのが最も安全な方法ではありません。
幸い、これら3つの問題すべての最も簡単な解決策は、個別のGaleraクラスターを非同期レプリケーションで接続することです。何がそれをそのような良い解決策にするのですか?まあ、それは非同期なので、Galeraレプリケーションに影響を与えません。フロー制御がないため、「マスター」クラスターのパフォーマンスは「スレーブ」クラスターのパフォーマンスの影響を受けません。すべての非同期レプリケーションと同様に、ラグが発生する場合がありますが、許容範囲内にある限り、完全に正常に機能します。また、最近では非同期レプリケーションを並列化して(複数のスレッドを連携させて帯域幅を増やすことができ)、レプリケーションの遅延をさらに減らすことができることにも留意する必要があります。
このブログ投稿では、MariaDBGaleraクラスター間で非同期レプリケーションをデプロイする手順について説明します。
MariaDB Galeraクラスター間で非同期レプリケーションを構成するにはどうすればよいですか?
まず、クラスターをデプロイする必要があります。この目的のために、3ノードクラスターをセットアップします。セットアップは最小限に抑えるため、アプリケーションとプロキシレイヤーの複雑さについては説明しません。プロキシレイヤーは、非同期レプリケーションを展開するタスクの処理に非常に役立つ場合があります。読み取り専用トラフィックのサブセットをテストクラスターにリダイレクトし、「メイン」クラスターが使用できない場合に、リダイレクトすることでディザスタリカバリの状況を支援します。 DRクラスターへのトラフィック。好みに応じて、HAProxy、MaxScale、ProxySQLなど、さまざまなプロキシを試すことができます。これらはすべて、このような設定で使用でき、場合によっては、トラフィックの管理に役立つプロキシもあります。
ソースクラスターの構成
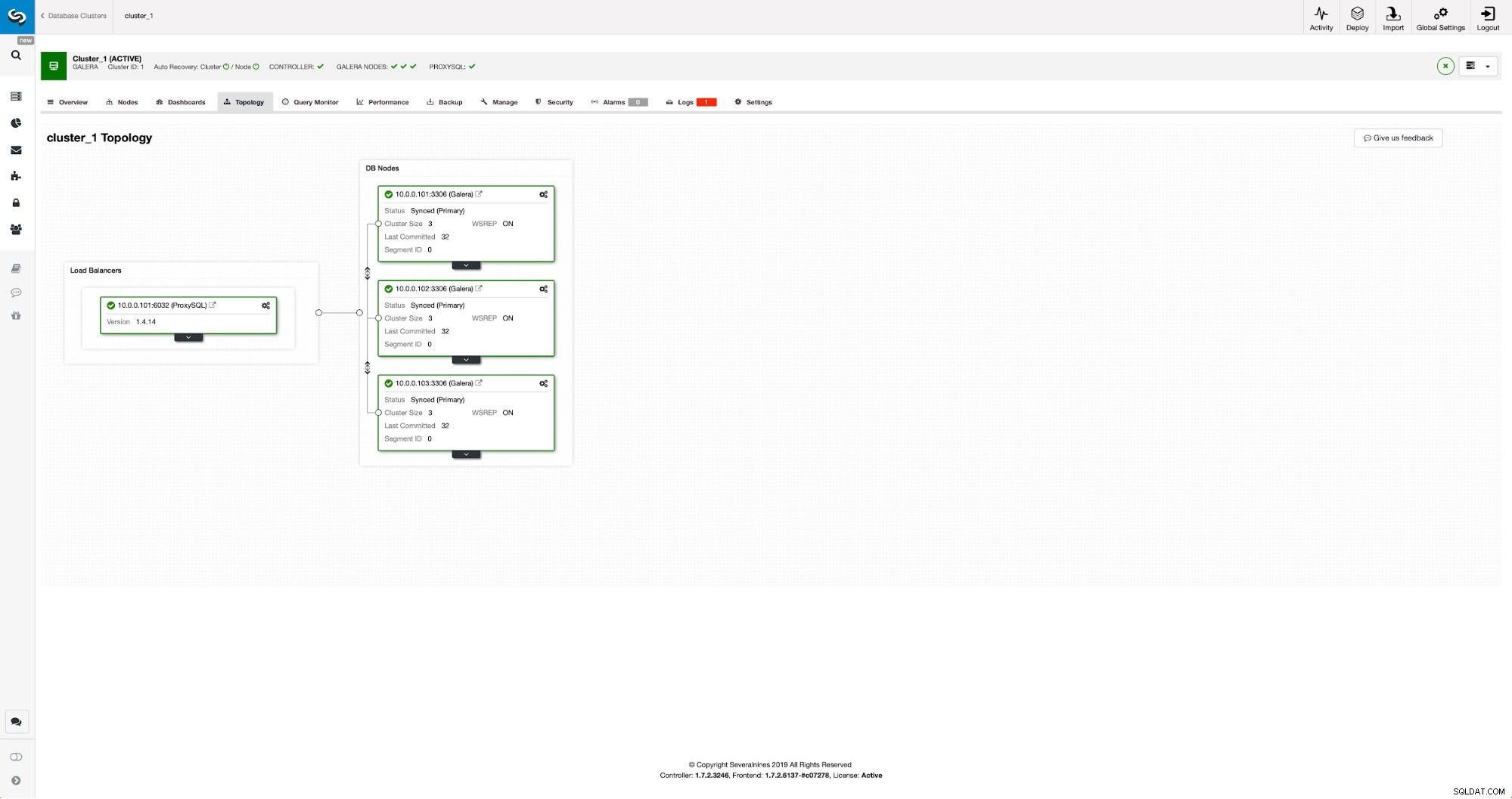
このクラスターは3つのMariaDB10.3ノードで構成されており、ProxySQLをデプロイして読み取り/書き込み分割を実行し、クラスター内のすべてのノードにトラフィックを分散します。これは本番環境グレードのデプロイメントではありません。そのため、より多くのProxySQLノードとその上にKeepalivedをデプロイする必要があります。それでも私たちの目的には十分です。非同期レプリケーションを設定するには、クラスターでバイナリログを有効にする必要があります。少なくとも1つのノードですが、binlogが有効になっている唯一のノードがダウンした場合に備えて、すべてのノードで有効にしておくことをお勧めします。クラスター内の別のノードを稼働させて、スレーブオフできるようにします。
バイナリログを有効にするときは、ある時点で古いログが削除されるように、必ずバイナリログローテーションを構成してください。 ROWバイナリログ形式を使用します。また、GTIDが構成され、使用されていることを確認する必要があります。これは、「スレーブ」クラスターを再スレーブする必要がある場合、またはマルチスレッドレプリケーションを有効にする必要がある場合に非常に便利です。これはGaleraクラスターであるため、「wsrep_gtid_domain_id」を構成し、「wsrep_gtid_mode」を有効にする必要があります。これらの設定により、Galeraクラスターからのトラフィックに対してGTIDが確実に生成されます。詳細については、ドキュメントを参照してください。これがすべて完了したら、2番目のクラスターのセットアップに進むことができます。
ターゲットクラスターのセットアップ
現在ターゲットクラスターがないことを考えると、それをデプロイすることから始めなければなりません。これらの手順については詳しく説明しません。手順については、ドキュメントをご覧ください。一般的に、プロセスはいくつかのステップで構成されています。
- MariaDBリポジトリを構成する
- MariaDB10.3パッケージをインストールします
- クラスターを形成するようにノードを構成する
最初は、1つのノードから始めます。それらすべてをセットアップしてクラスターを形成することもできますが、それらを停止して、次のステップで1つだけを使用する必要があります。その1つのノードが元のクラスターのスレーブになります。 mariabackupを使用してプロビジョニングします。次に、レプリケーションを構成します。
まず、バックアップを保存するディレクトリを作成する必要があります:
mkdir /mnt/mariabackup次に、バックアップを実行し、上記の手順で準備したディレクトリに作成します。データベースへの接続には、正しいユーザーとパスワードを使用していることを確認してください。
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/次に、バックアップファイルを2番目のクラスターの最初のノードにコピーする必要があります。そのためにscpを使用しました。rsync、netcatなど、機能するものなら何でも使用できます。
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/バックアップをコピーしたら、ログファイルを適用して準備する必要があります。
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!エラーが発生した場合は、バックアップを再実行する必要があります。すべて問題がなければ、古いデータを削除してバックアップ情報に置き換えることができます
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!また、ファイルの正しい所有者を設定する必要があります:
chown -R mysql.mysql /var/lib/mysql/レプリケーションの一貫性を維持するためにGTIDに依存するため、このバックアップで最後に適用されたGTIDを確認する必要があります。その情報は、バックアップの一部であるxtrabackup_infoファイルにあります:
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'また、スレーブノードで「log_slave_updates」とともにバイナリログが有効になっていることを確認する必要があります。理想的には、これは2番目のクラスターのすべてのノードで有効になります。「スレーブ」ノードに障害が発生し、スレーブクラスターの別のノードを使用してレプリケーションを設定する必要がある場合に備えて。
レプリケーションを設定する前に行う必要がある最後のビットは、レプリケーションの実行に使用するユーザーを作成することです。
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)必要なのはそれだけです。これで、2番目のクラスターの最初のノードであるスレーブになる予定のノードを開始できます:
galera_new_cluster開始したら、MySQL CLIに入り、数ステップ前に見つけたGITDの位置を使用して、スレーブになるように構成できます。
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)それが完了したら、最終的にレプリケーションを設定して開始できます。
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)この時点で、1つのノードで構成されるGaleraクラスターがあります。そのノードは元のクラスターのスレーブでもあります(特に、そのマスターはノード10.0.0.101です)。他のノードに参加するにはSSTを使用しますが、最初にSSTを機能させるには、SST構成が正しいことを確認する必要があります。2番目のクラスターのすべてのユーザーをソースクラスターのコンテンツに置き換えただけであることに注意してください。ここで行う必要があるのは、2番目のクラスターの「wsrep_sst_auth」構成が最初のクラスターの構成と一致することを確認することです。それが完了したら、残りのノードを1つずつ開始し、既存のノード(10.0.0.104)に参加して、SSTを介してデータを取得し、Galeraクラスターを形成する必要があります。最終的には、2つのクラスター(それぞれ3つのノード)があり、それらに非同期レプリケーションリンクがあります(この例では10.0.0.101から10.0.0.104)。次の値を確認することで、レプリケーションが機能していることを確認できます。
MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)ClusterControlを使用してMariaDBGaleraクラスター間の非同期レプリケーションを構成するにはどうすればよいですか?
このブログの時点では、ClusterControlには複数のクラスター間で非同期レプリケーションを構成する機能がないため、これを入力しながら作業を行っています。それでも、ClusterControlはこのプロセスで非常に役立ちます。ClusterControlが提供する自動化を使用して、面倒な手動手順を高速化する方法を紹介します。
前に示した内容から、これらは2つのGaleraクラスター間でレプリケーションを設定するときに実行する一般的な手順であると結論付けることができます。
- 新しいGaleraクラスターを展開する
- 古いクラスターのデータを使用して新しいクラスターをプロビジョニングする
- 新しいクラスターを構成する(SST構成、バイナリログ)
- 古いクラスターと新しいクラスター間のレプリケーションを設定します
最初の3つのポイントは、現在でもClusterControlを使用して簡単に実行できることです。その方法を紹介します。
ClusterControlを使用して新しいMariaDBガレラクラスターをデプロイしてプロビジョニングする
初期の状況も同様です。1つのクラスターが稼働しています。 2つ目を設定する必要があります。 ClusterControlの最近の機能の1つは、新しいクラスターをデプロイし、バックアップからのデータを使用してそれをプロビジョニングするオプションです。これは、テスト環境を作成するのに非常に役立ちます。また、レプリケーションセットアップ用に新しいクラスターをプロビジョニングするために使用するオプションでもあります。したがって、最初のステップは、mariabackupを使用してバックアップを作成することです。
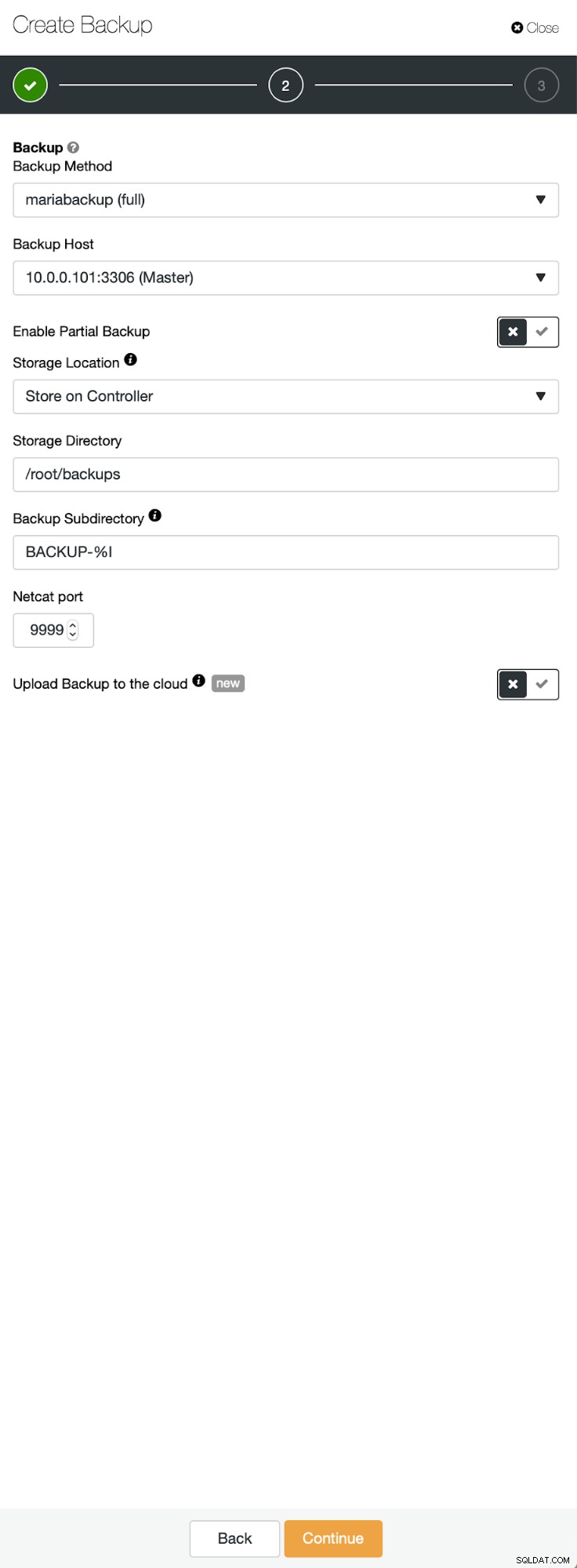
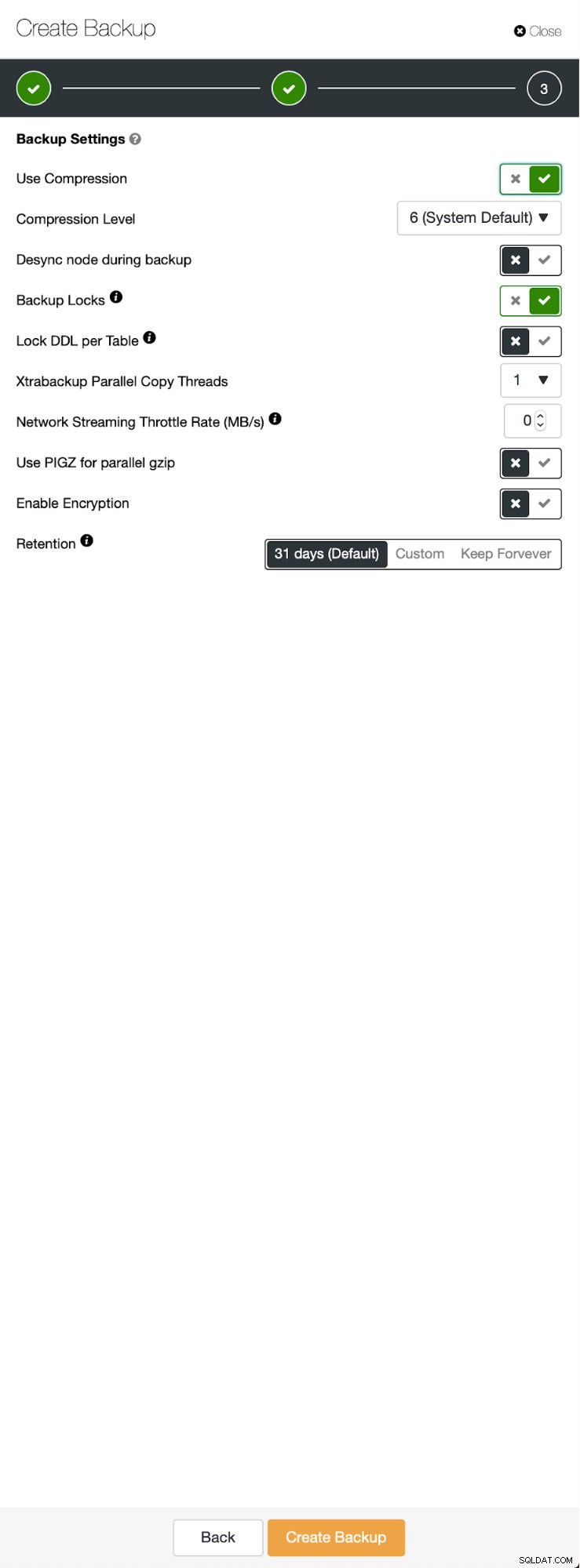
バックアップを削除するためにノードを選択した3つのステップ。このノード(10.0.0.101)がマスターになります。バイナリログを有効にする必要があります。この場合、すべてのノードでbinlogが有効になっていますが、有効になっていない場合は、ClusterControlから有効にするのは非常に簡単です。後で2番目のクラスターで有効にする手順を示します。
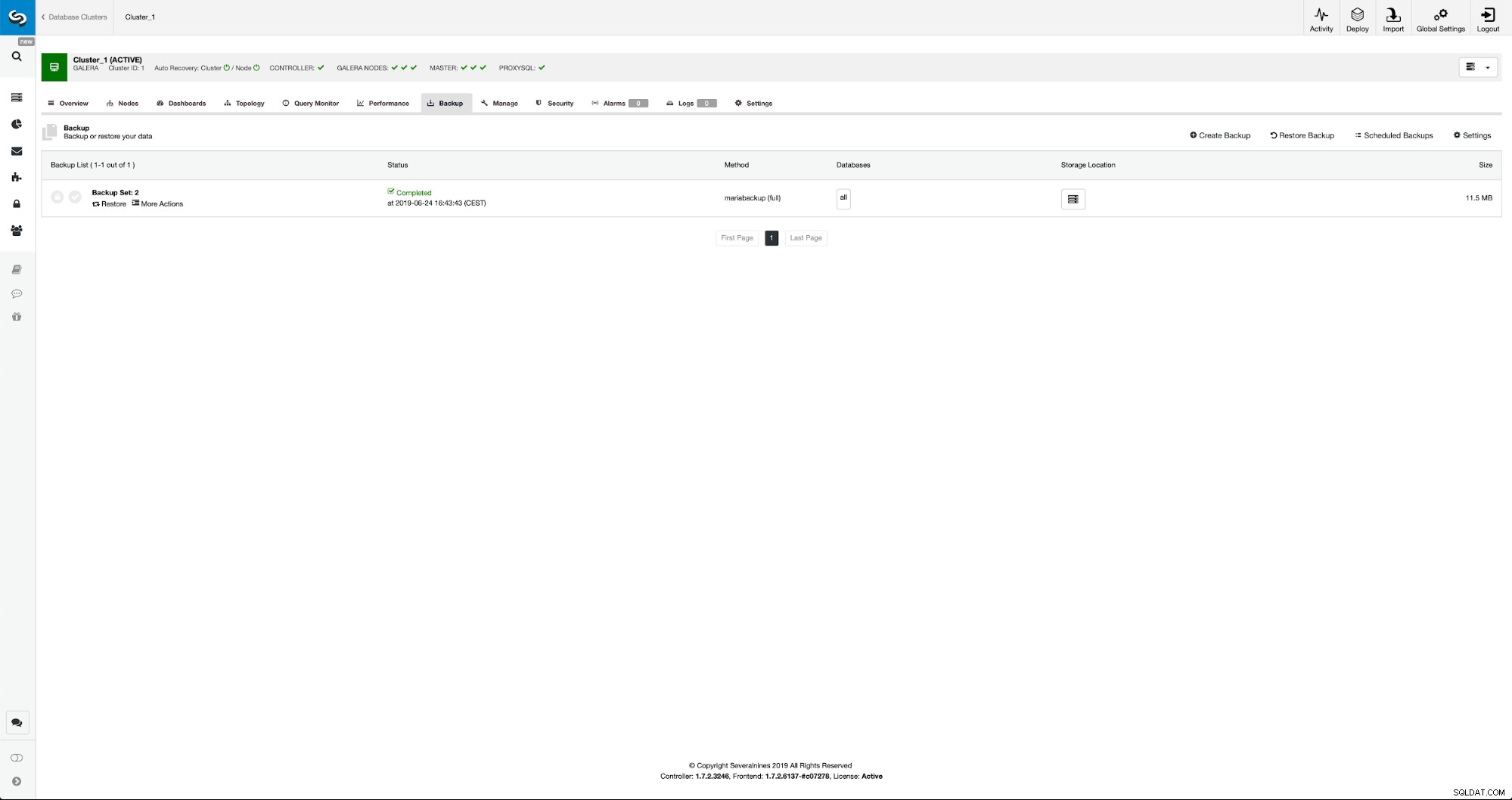
バックアップが完了すると、リストに表示されます。その後、続行して復元できます:

必要に応じて、ポイントインタイムリカバリを実行することもできますが、この場合はそれほど重要ではありません。レプリケーションが構成されると、binlogからの必要なすべてのトランザクションが新しいクラスターに適用されます。
>
次に、バックアップからクラスターを作成するオプションを選択します。これにより、別のダイアログが開きます:
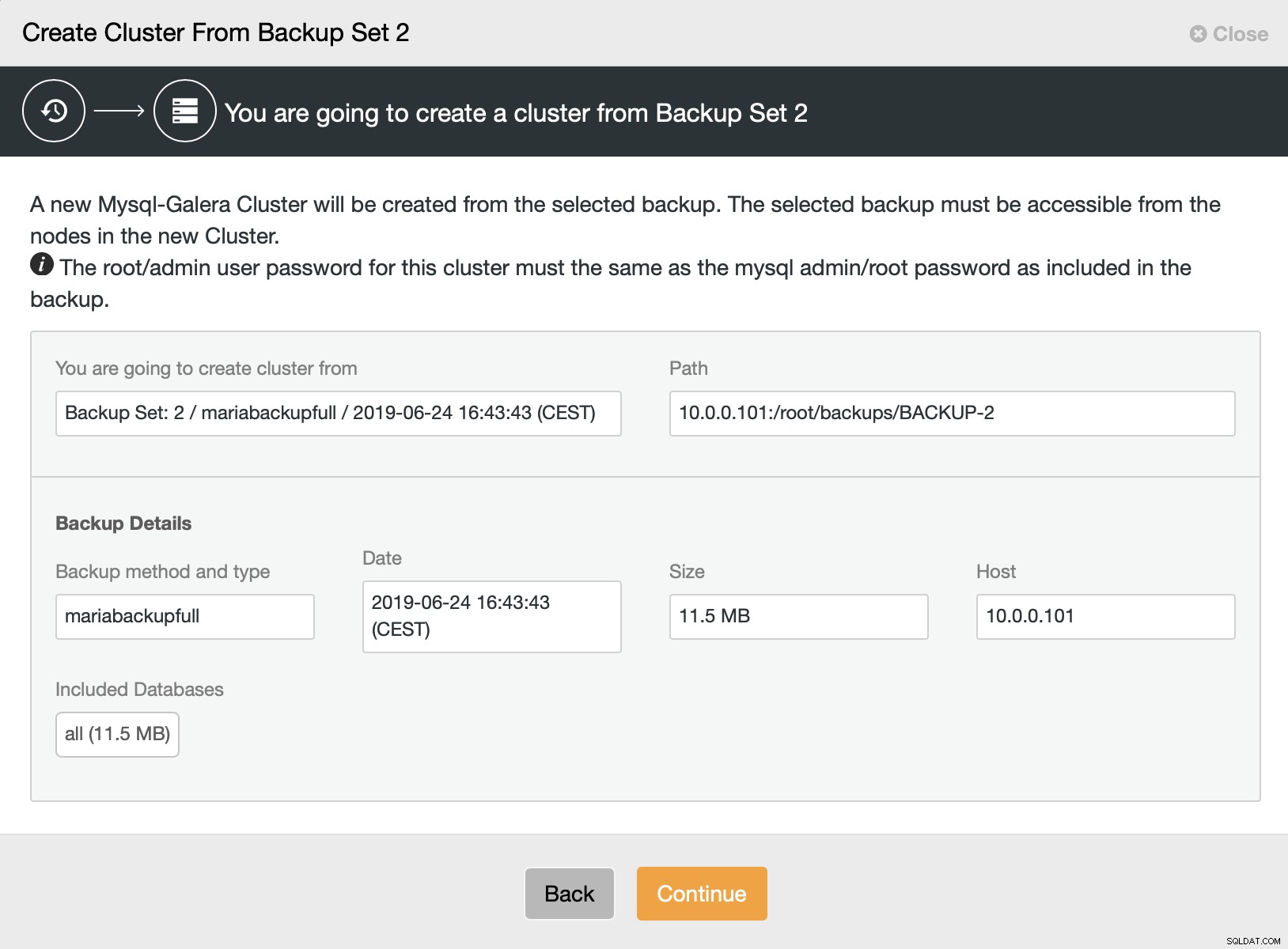
これは、使用されるバックアップ、バックアップの取得元のホスト、バックアップの作成に使用された方法、およびバックアップが正常に見えるかどうかを確認するためのメタデータの確認です。
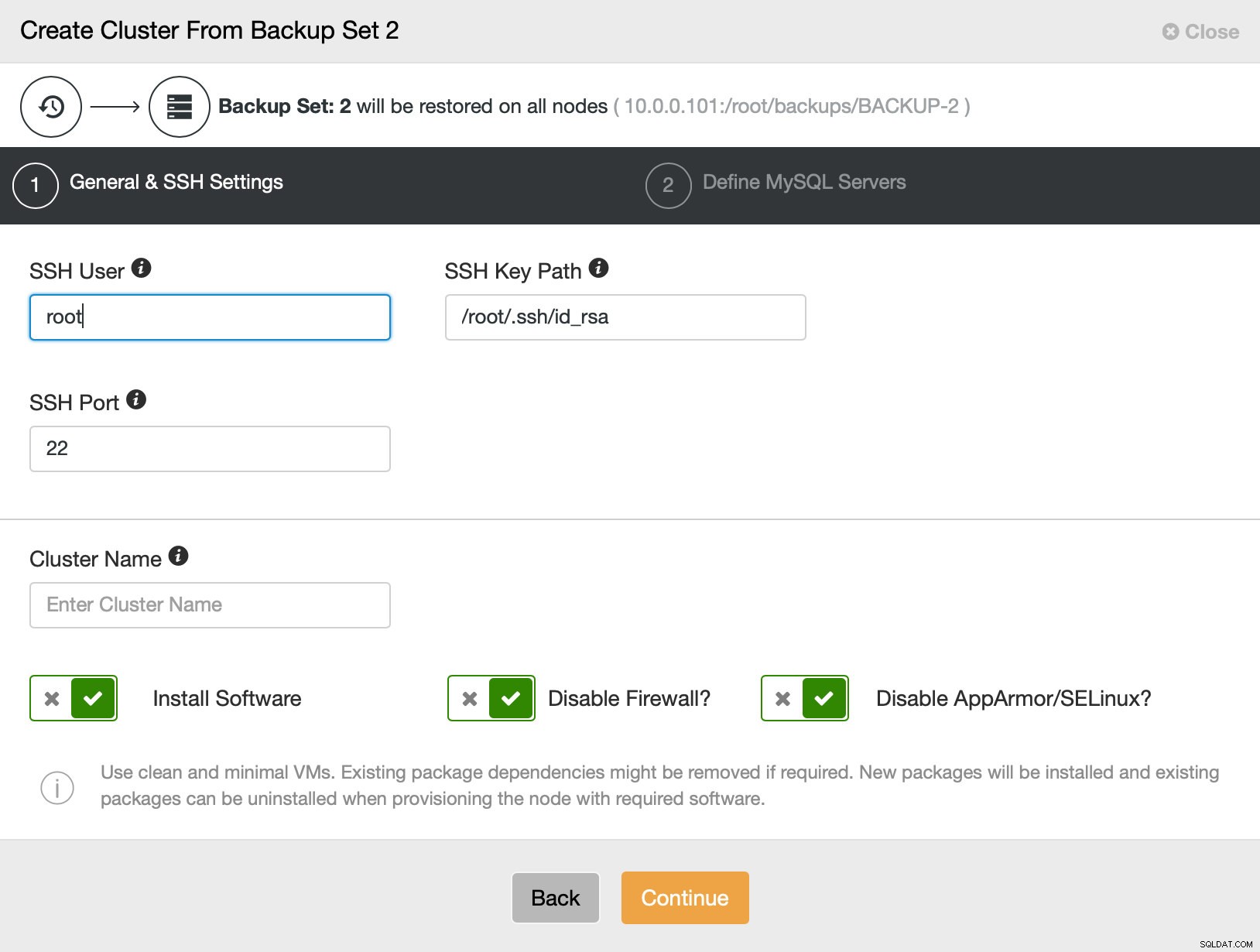
次に、基本的に通常の展開ウィザードに移動します。このウィザードでは、ClusterControlホストとノード間のSSH接続を定義して、クラスターを展開し(ClusterControlの要件)、2番目のステップで、ベンダー、バージョン、パスワード、および展開するノードを定義します。 on:
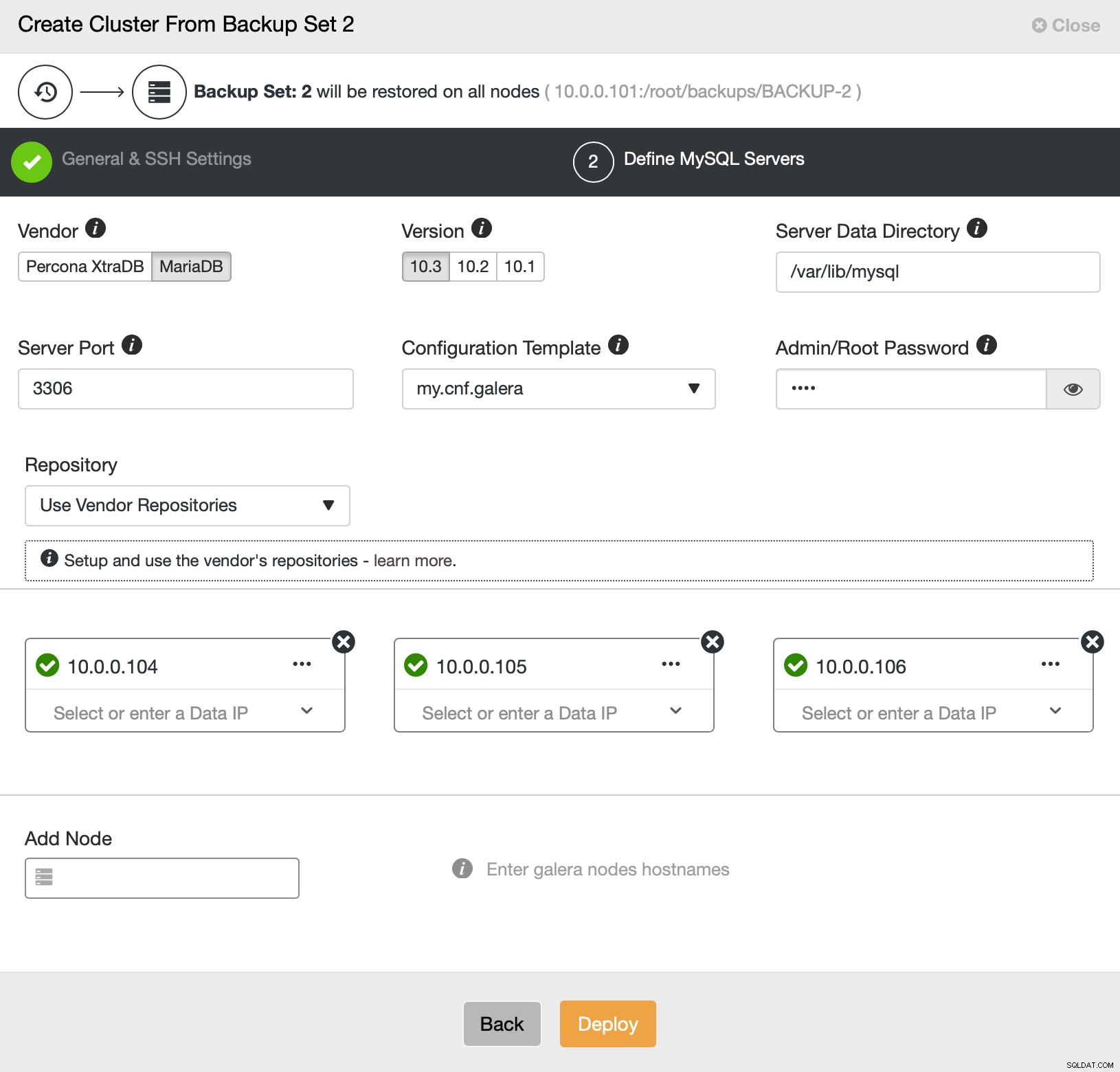
導入とプロビジョニングについては以上です。 ClusterControlは新しいクラスターをセットアップし、古いクラスターのデータを使用してそれをプロビジョニングします。
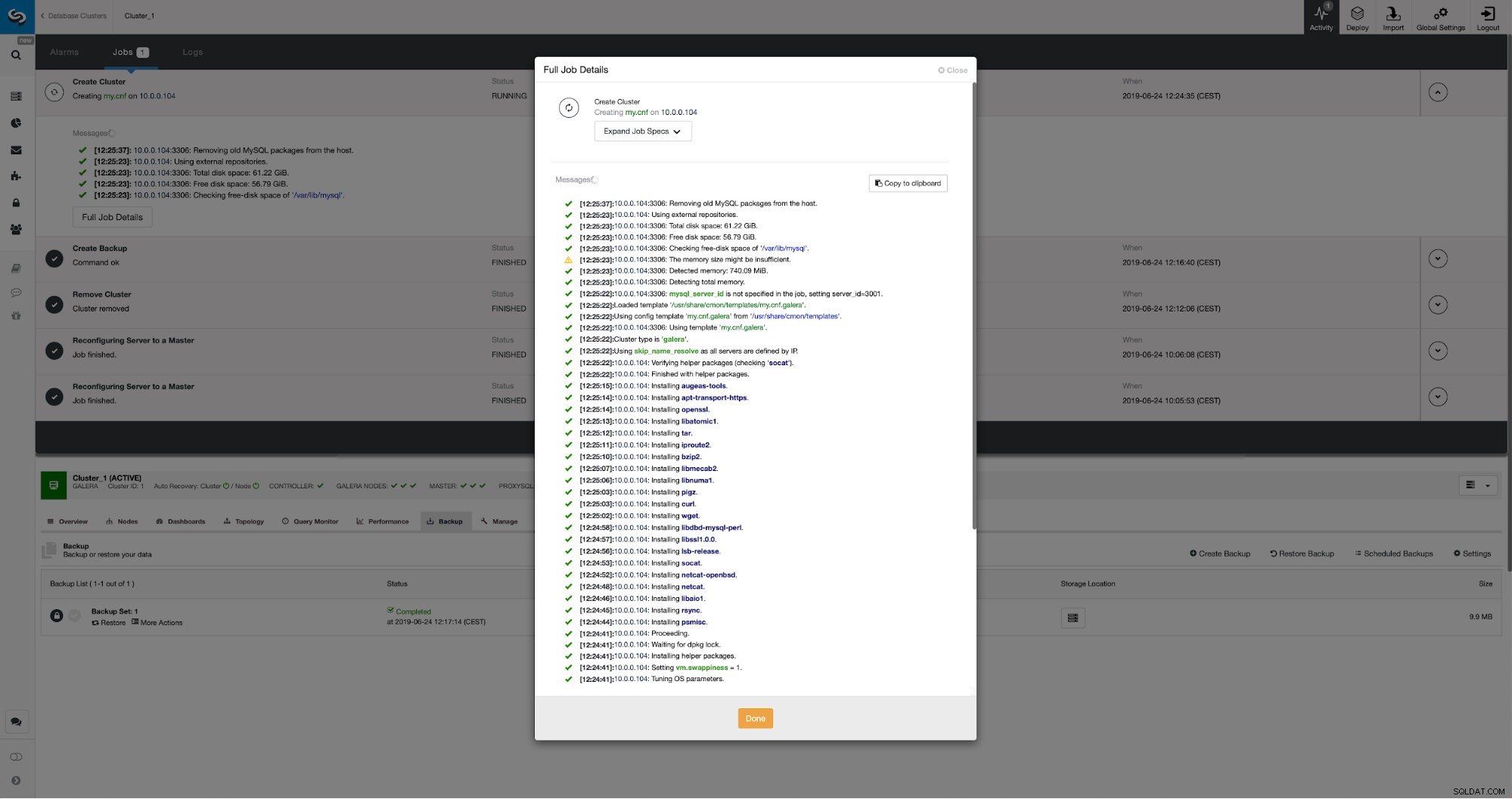
アクティビティタブで進行状況を監視できます。完了すると、2番目のクラスターがClusterControlのクラスターリストに表示されます。
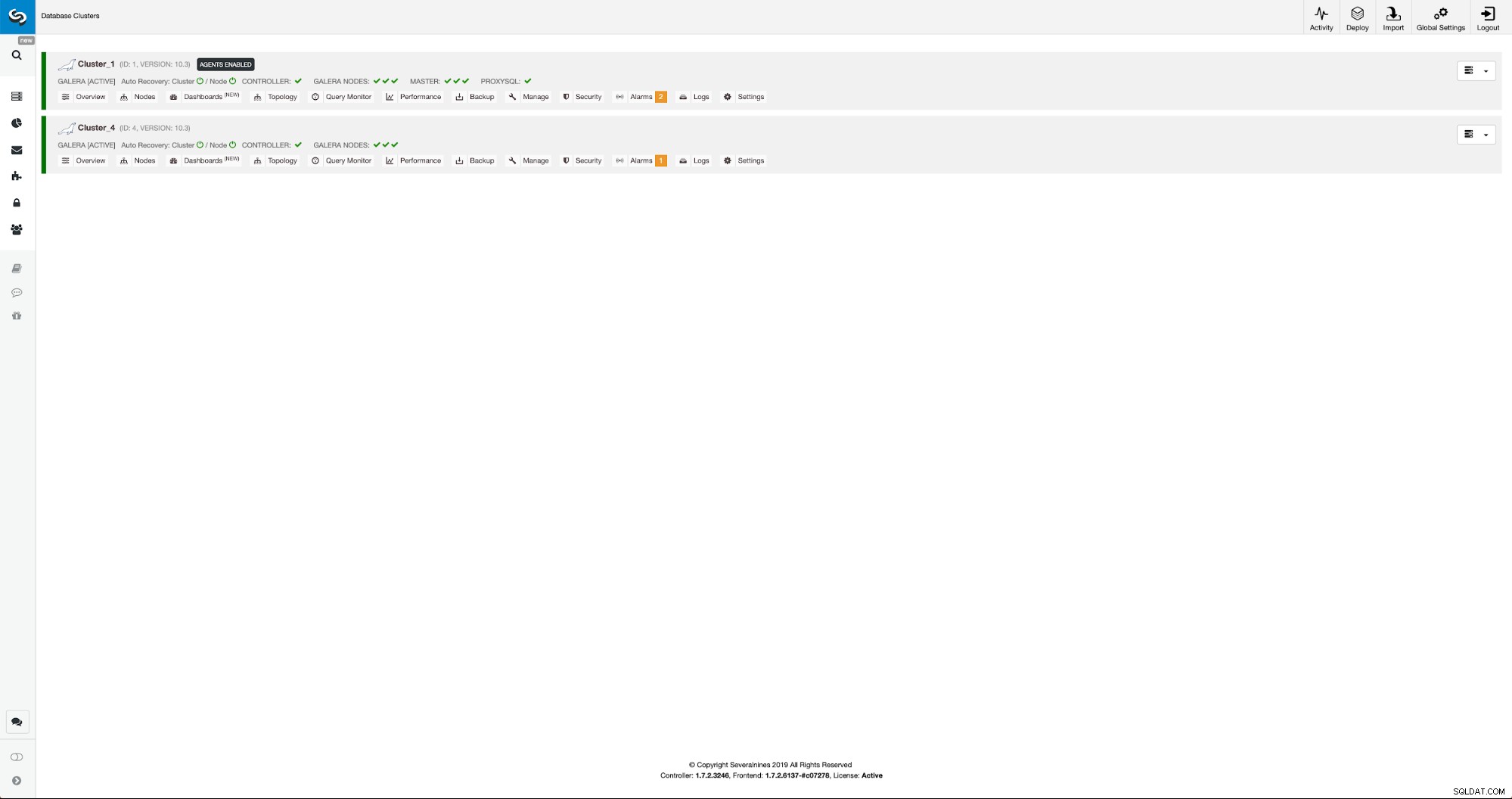
ClusterControlを使用した新しいクラスターの再構成
次に、クラスターを再構成する必要があります。バイナリログを有効にします。手動プロセスでは、wsrep_sst_auth構成を変更する必要があり、構成の[mysqldump]セクションと[xtrabackup]セクションの構成エントリも変更する必要がありました。これらの設定は、secrets-backup.cnfファイルにあります。 ClusterControlがクラスターの新しいパスワードを生成し、ファイルを正しく構成したため、今回は必要ありません。ただし、元のクラスターで「backupuser」@「127.0.0.1」ユーザーのパスワードを変更した場合は、2番目のクラスターでも構成を変更して、それを変更として反映する必要があることに注意してください。最初のクラスターは2番目のクラスターに複製されます。
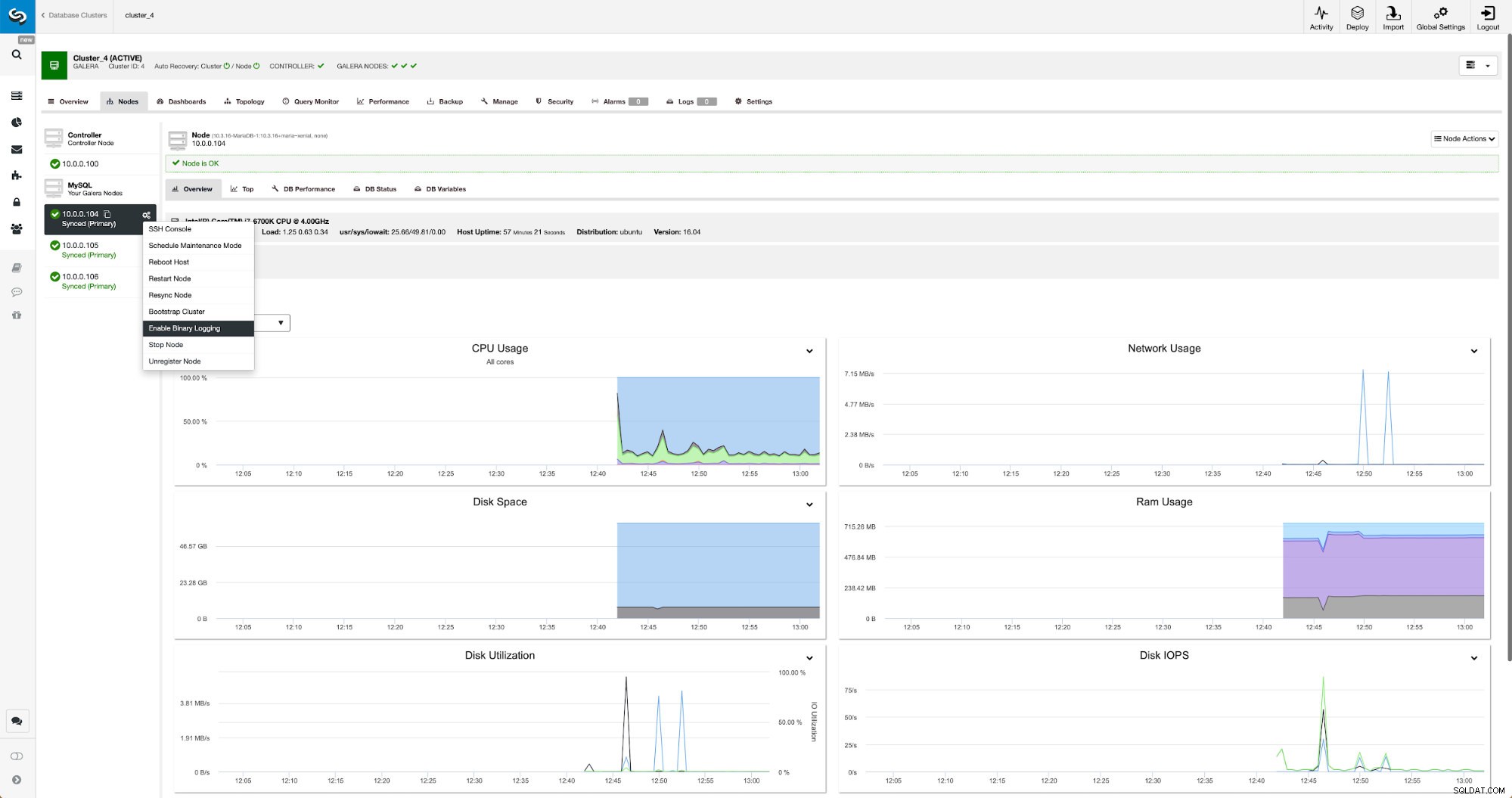
バイナリログは、[ノード]セクションから有効にできます。ノードごとに選択して、「バイナリロギングを有効にする」ジョブを実行する必要があります。ダイアログが表示されます:
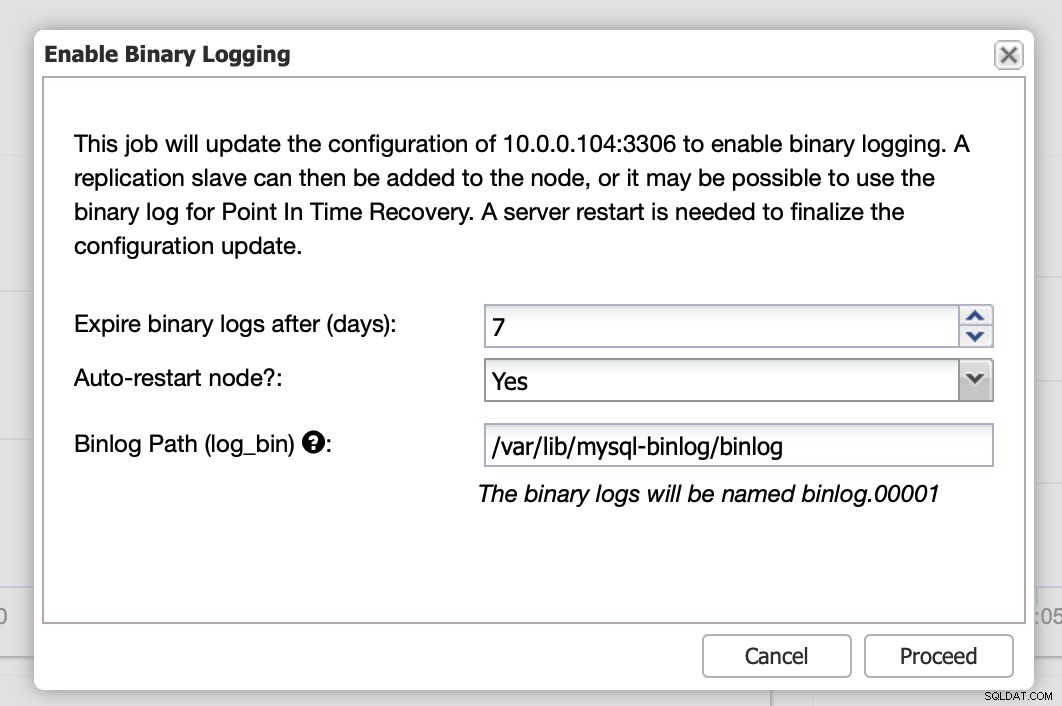
ここで、ログを保持する期間、ログを保存する場所、および変更を適用するためにClusterControlがノードを再起動する必要があるかどうかを定義できます。バイナリログ構成は動的ではなく、MariaDBを再起動してこれらの変更を適用する必要があります。
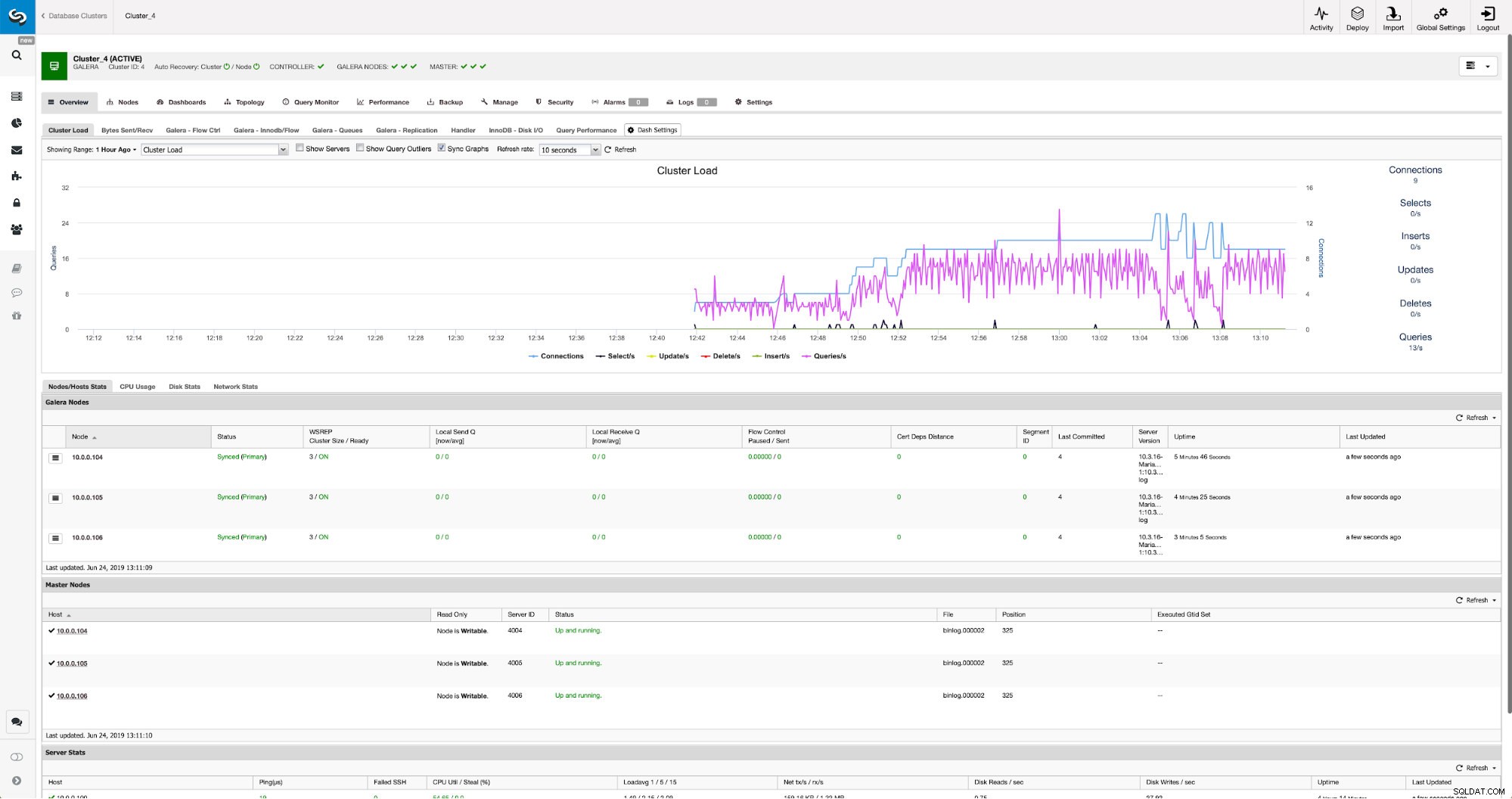
変更が完了すると、「マスター」としてマークされたすべてのノードが表示されます。これは、それらのノードでバイナリログが有効になっており、マスターとして機能できることを意味します。
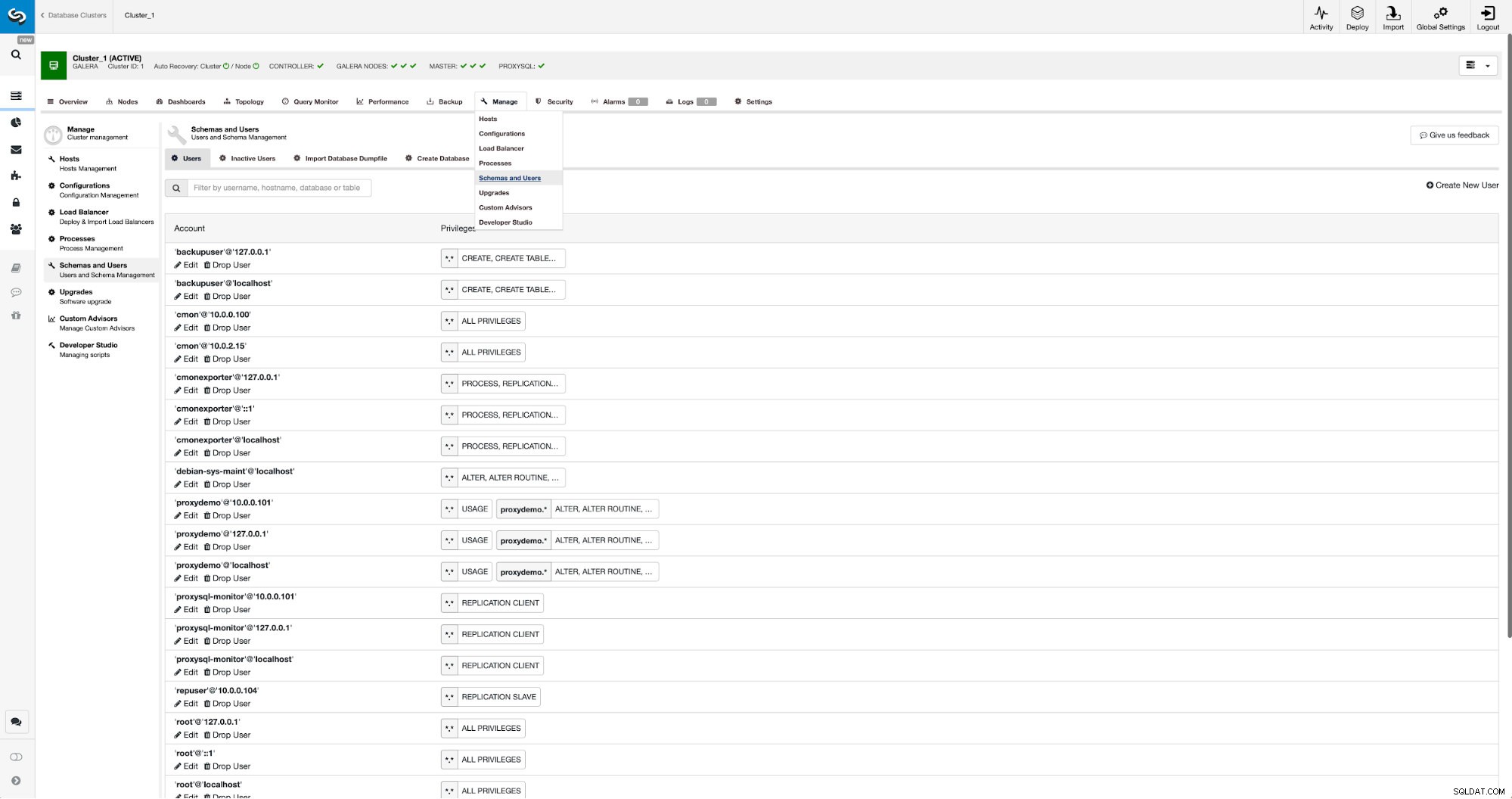
レプリケーションユーザーをまだ作成していない場合は、それを行う必要があります。最初のクラスターでは、[管理]-> [スキーマとユーザー]に移動する必要があります:
右側には、新しいユーザーを作成するオプションがあります:
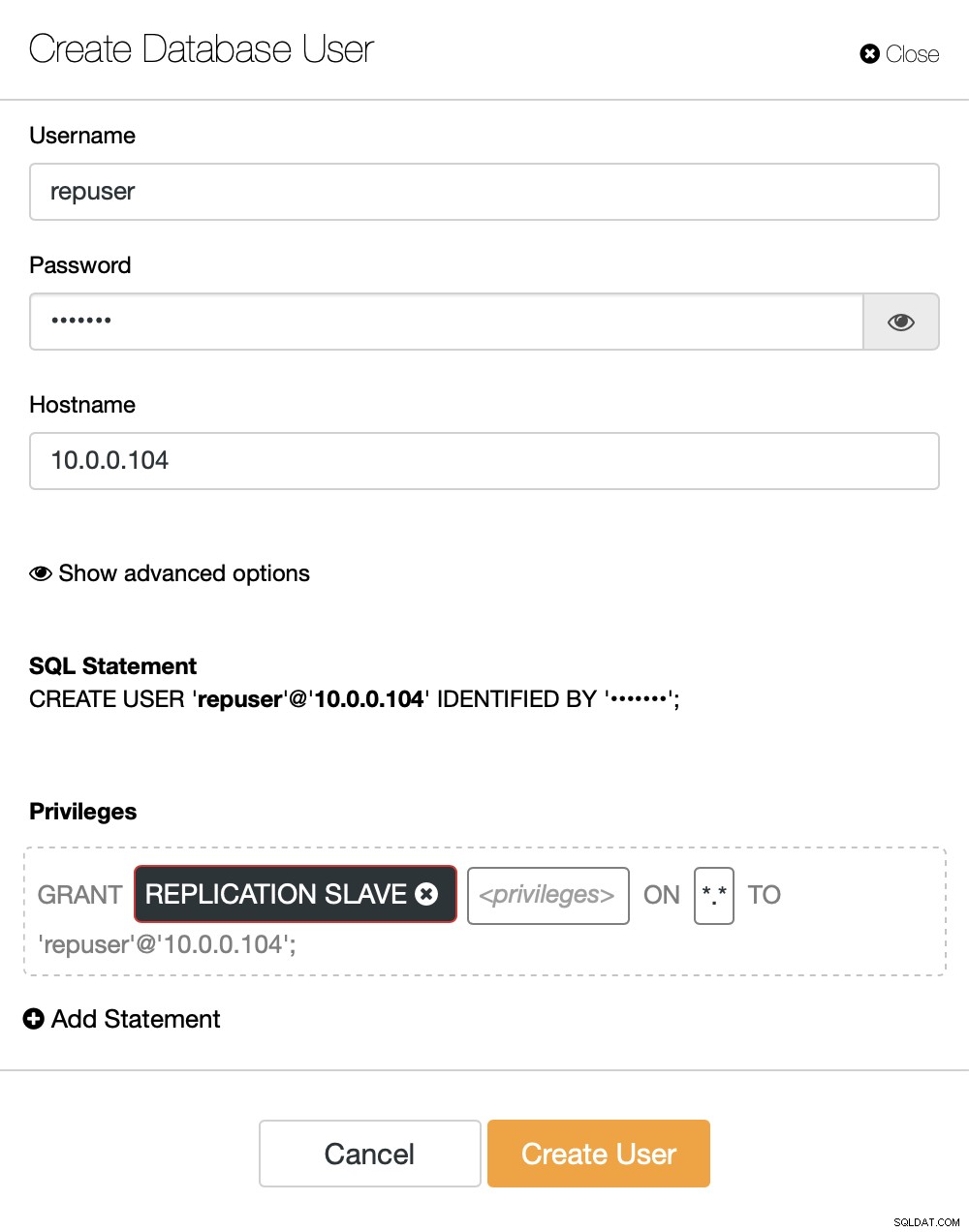
これで、レプリケーションのセットアップに必要な構成は完了です。
ClusterControlを使用したクラスター間のレプリケーションの設定
すでに述べたように、私たちはこの部分の自動化に取り組んでいます。現在、手動で行う必要があります。ご存知かもしれませんが、バックアップのGITD位置が必要であり、MySQLCLIを使用していくつかのコマンドを実行します。 GTIDデータはバックアップで利用できます。 ClusterControlは、xbstream / mbstreamを使用してバックアップを作成し、後でそれを圧縮します。バックアップは、mbstreamバイナリにアクセスできないClusterControlホストに保存されます。インストールを試みるか、バックアップファイルをそのようなバイナリが利用可能な場所にコピーすることができます:
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/それが完了したら、10.0.0.104でxtrabackup_infoファイルの内容を確認します。
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'最後に、レプリケーションを構成して開始します:
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)これがそれです-ClusterControlを使用して2つのMariaDBGaleraクラスター間で非同期レプリケーションを構成しました。ご覧のとおり、ClusterControlは、この環境をセットアップするために必要な手順の大部分を自動化することができました。