以前のブログで、クラスター間レプリケーションと呼ばれる新しいClusterControl1.7.4機能を発表しました。プライマリクラスターからDRクラスターをセットアップするプロセス全体を自動化し、その間にレプリケーションを配置します。詳細については、上記のブログエントリを参照してください。
このブログでは、既存のクラスターに対してこの新機能を構成する方法を見ていきます。このタスクでは、ClusterControlがインストールされており、それを使用してマスタークラスターがデプロイされていることを前提としています。
マスタークラスターを機能させるには、いくつかの要件があります。
- Percona XtraDB Clusterバージョン5.6.x以降、またはMariaDBGaleraClusterバージョン10.x以降。
- GTIDが有効になっています。
- バックアップクレデンシャルは、マスタークラスターとスレーブクラスターで同じである必要があります。
この新機能を使用するには、マスタークラスターを準備する必要があります。 ClusterControl側とデータベース側の両方からの構成が必要です。
ClusterControlの構成
データベースノードで、/ etc / my.cnf.d / secrets-backup.cnf(RedHatベースのOSの場合)または/ etc / mysql/secrets-backupに保存されているバックアップユーザーの資格情報を確認します.cnf(DebianベースのOSの場合)。
$ cat /etc/my.cnf.d/secrets-backup.cnf
# Security credentials for backup.
[mysqldump]
user=backupuser
password=cYj0GFBEdqdreZEl
[xtrabackup]
user=backupuser
password=cYj0GFBEdqdreZEl
[mysqld]
wsrep_sst_auth=backupuser:cYj0GFBEdqdreZElClusterControlノードで、/ etc / cmon.d / cmon_ID.cnf構成ファイル(IDはクラスターID番号)を編集し、secrets-backupに保存されているものと同じ資格情報が含まれていることを確認します。 cnf。
$ cat /etc/cmon.d/cmon_8.cnf
backup_user=backupuser
backup_user_password=cYj0GFBEdqdreZEl
basedir=/usr
cdt_path=/
cluster_id=8
...このファイルを変更するには、cmonサービスを再起動する必要があります:
$ service cmon restartデータベースレプリケーションパラメータをチェックして、GTIDとバイナリロギングが有効になっていることを確認してください。
データベースノードで、ファイル/etc/my.cnf(RedHatベースのOSの場合)または/etc/mysql/my.cnf(DebianベースのOSの場合)をチェックして、に関連する構成を確認します。レプリケーションプロセス。
Percona XtraDB:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=4002
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-log
expire_logs_days = 7MariaDBガレラクラスター:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=9000
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
relay_log = relay-log
wsrep_gtid_domain_id=9000
wsrep_gtid_mode=ON
gtid_domain_id=9000
gtid_strict_mode=ON
gtid_ignore_duplicates=ON
expire_logs_days = 7構成ファイルを確認することで、ClusterControlUIで有効になっているかどうかを確認できます。 ClusterControl-> SelectCluster->Nodesに移動します。そこに次のようなものがあるはずです:

最初のノードに追加された「マスター」の役割は、バイナリロギングを意味します有効になっています。
バイナリログを有効にしていない場合は、[ClusterControl]->[クラスター]->[ノード]->[ノードアクション]->[バイナリログを有効にする]に移動します。
次に、バイナリログの保持と保存するパスを指定する必要がありますそれ。また、ClusterControlでデータベースノードを構成した後に再起動するか、自分で再起動するかを指定する必要があります。
バイナリロギングを有効にするには、常にデータベースサービスを再起動する必要があることに注意してください。 。
ClusterControlGUIからのスレーブクラスターの作成
新しいスレーブクラスターを作成するには、ClusterControl->[クラスター]->[クラスターアクション]->[スレーブクラスターの作成]に移動します。
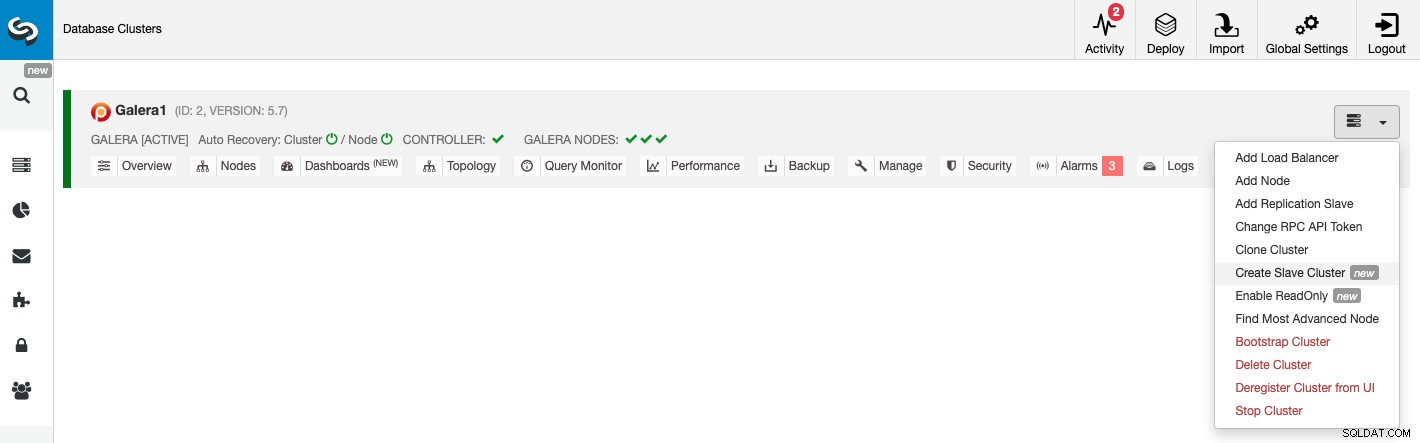
スレーブクラスターは、現在のマスタークラスターまたは既存のバックアップを使用する。
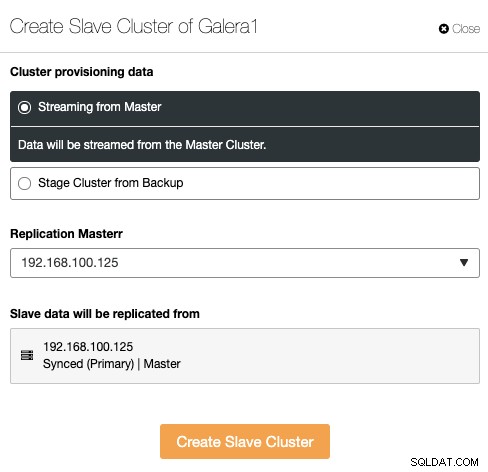
このセクションでは、現在のクラスターのマスターノードも選択する必要がありますそこからデータが複製されます。
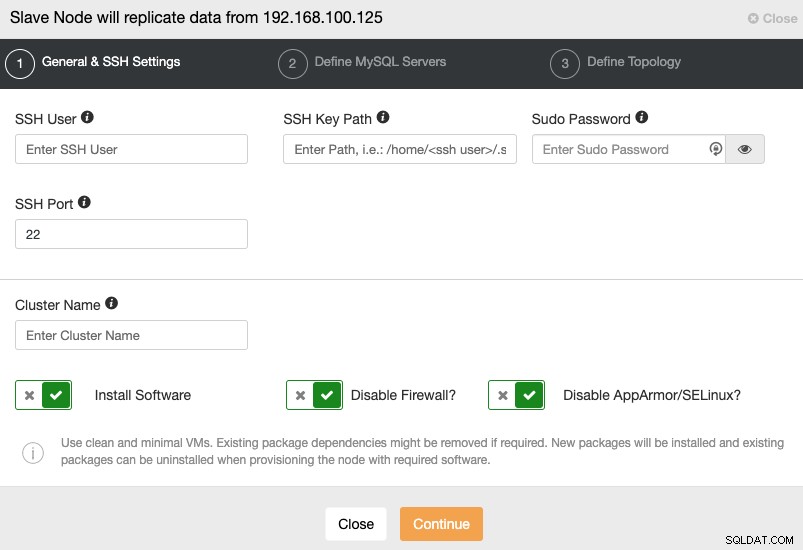
次の手順に進むときは、ユーザー、キー、またはを指定する必要がありますSSHでサーバーに接続するためのパスワードとポート。また、スレーブクラスターの名前と、ClusterControlに対応するソフトウェアと構成をインストールさせる場合も必要です。
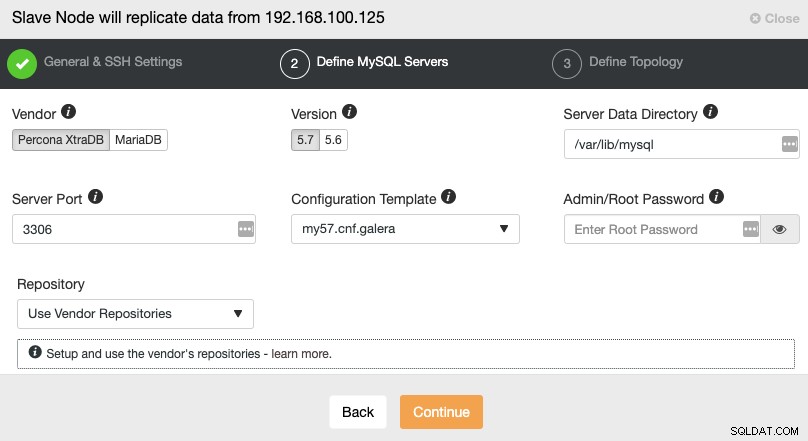
SSHアクセス情報を設定した後、データベースベンダーを定義する必要があります。バージョン、datadir、データベースポート、および管理者パスワード。マスタークラスターで使用されているものと同じベンダー/バージョンおよび資格情報を使用していることを確認してください。使用するリポジトリを指定することもできます。
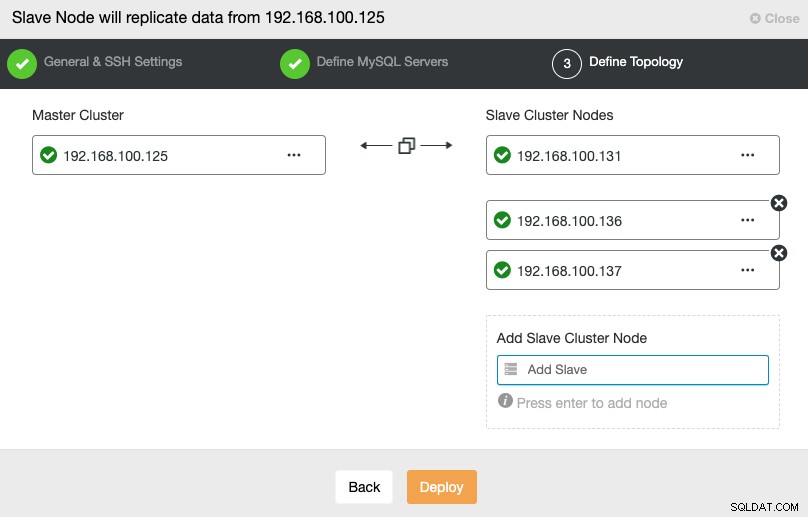
このステップでは、新しいスレーブクラスターにサーバーを追加する必要があります。このタスクでは、各データベースノードのIPアドレスまたはホスト名の両方を入力できます。
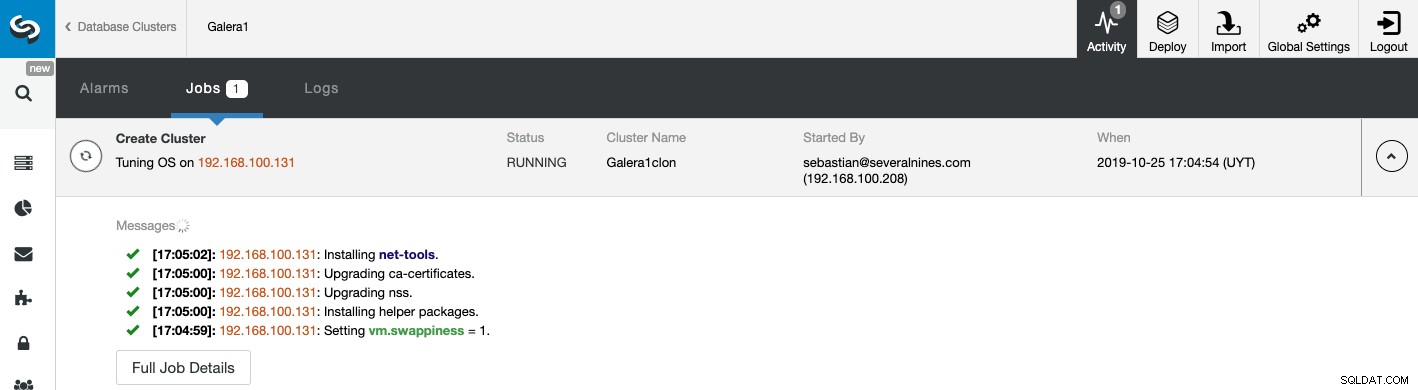
から、新しいスレーブクラスターの作成ステータスを監視できます。 ClusterControlアクティビティモニター。タスクが完了すると、ClusterControlのメイン画面にクラスターが表示されます。
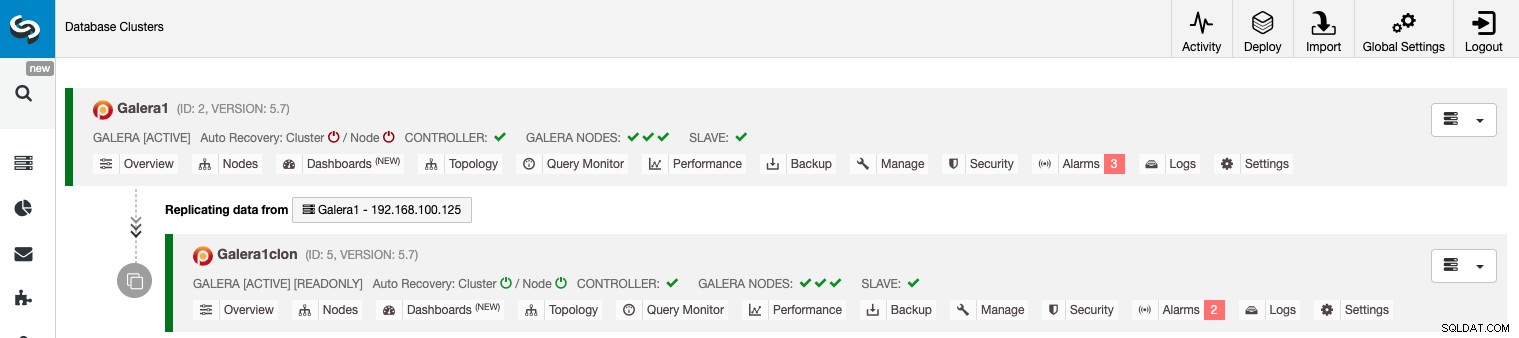
ClusterControlGUIを使用したクラスター間レプリケーションの管理
これで、クラスター間レプリケーションが稼働しました。ClusterControlを使用してこのトポロジで実行するさまざまなアクションがあります。
ご覧のとおり、デフォルトでは、スレーブクラスターは読み取り専用モードで設定されています。 ClusterControl UIからノードの読み取り専用フラグを1つずつ無効にすることは可能ですが、MySQL / MariaDBはそうではないため、アプリケーションがいずれかのクラスター上の互いに素なデータセットにのみアクセスしている場合にのみ、アクティブ-アクティブクラスタリングが推奨されることに注意してください。競合の検出または解決を提供します。
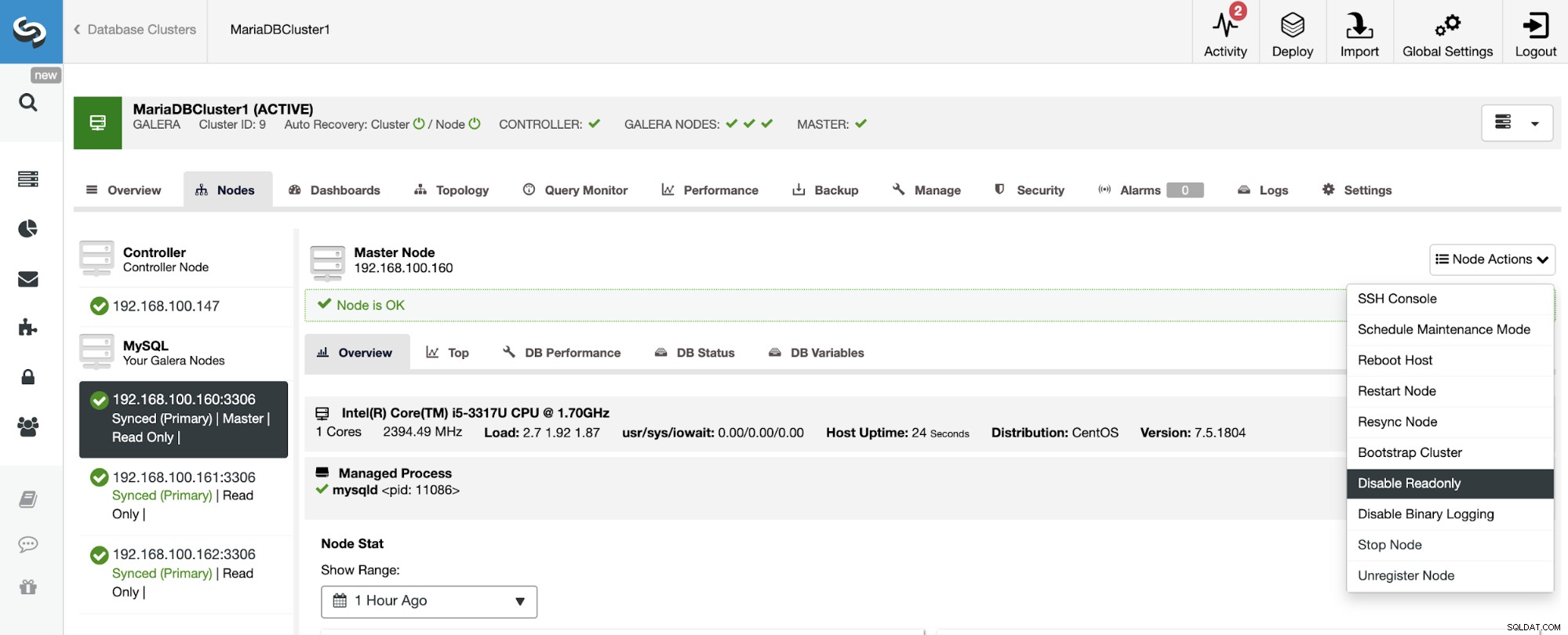
読み取り専用モードを無効にするには、ClusterControl->SelectSlaveに移動します。クラスター->ノード。このセクションでは、各ノードを選択し、[読み取り専用を無効にする]オプションを使用します。
不整合を回避するために、スレーブクラスターを再構築する場合、これは読み取り専用クラスターである必要があります。つまり、すべてのノードが読み取り専用モードである必要があります。
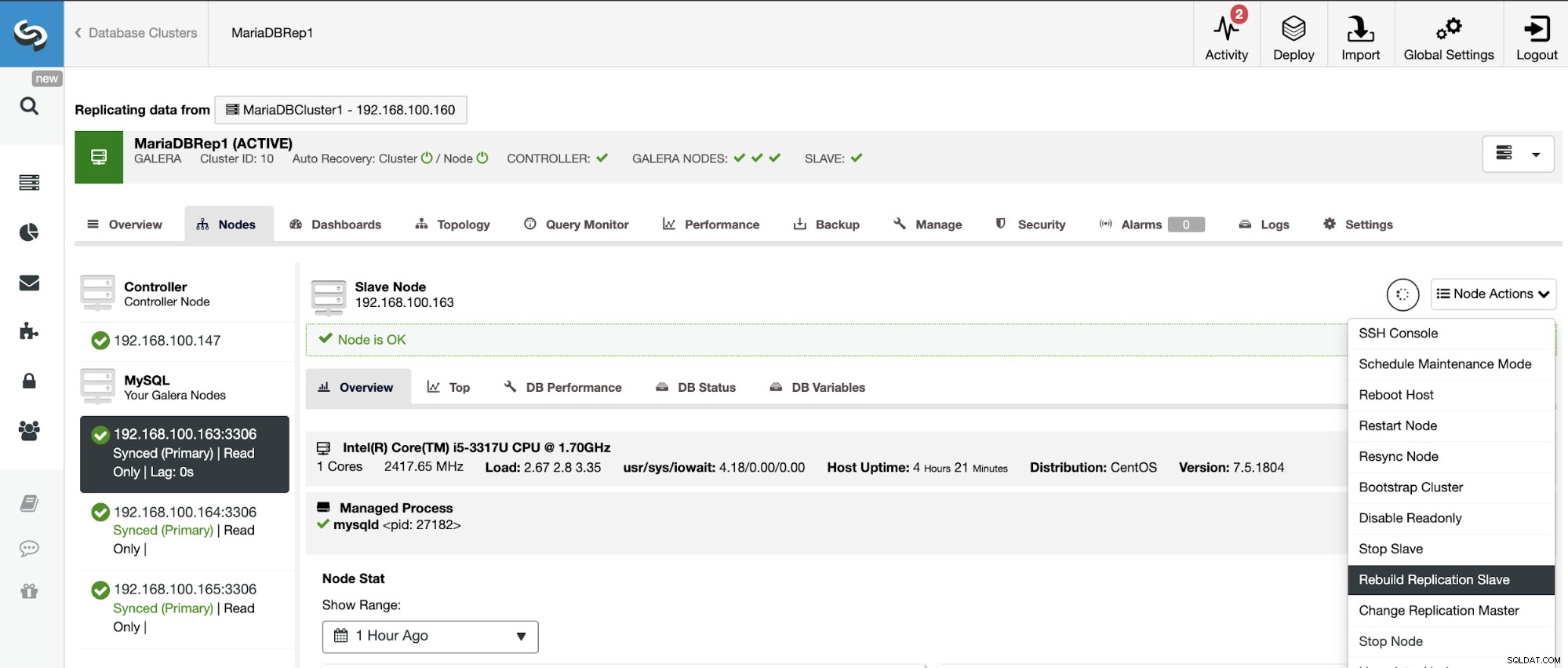
ClusterControlに移動->スレーブクラスターを選択->ノード->を選択マスタークラスターに接続されているノード->ノードアクション->レプリケーションスレーブの再構築。
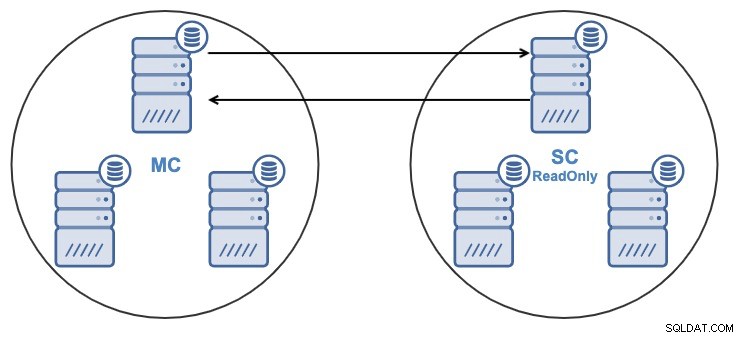
そして、何らかの理由で、マスターのレプリケーションノードを変更したい集まる。スレーブクラスターが使用するマスターノードを、マスタークラスター内の別のマスターノードに変更することができます。
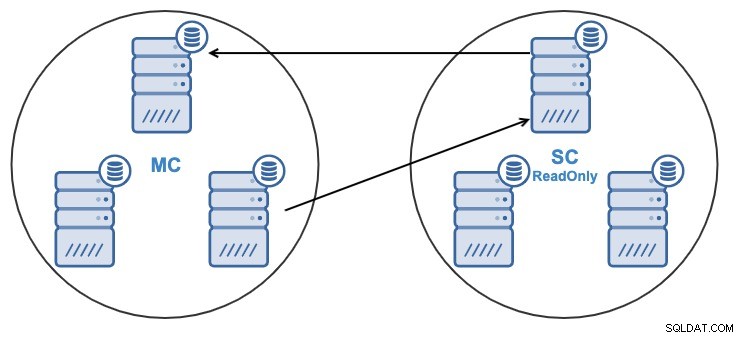
マスターノードと見なされるには、バイナリロギングが有効になっている必要があります。
ClusterControlに移動->スレーブクラスターを選択->ノード->を選択マスタークラスターに接続されているノード->ノードアクション->スレーブの停止/スレーブの開始
ClusterControlを使用すると、簡単な方法でレプリケーションスレーブを停止および開始できます。
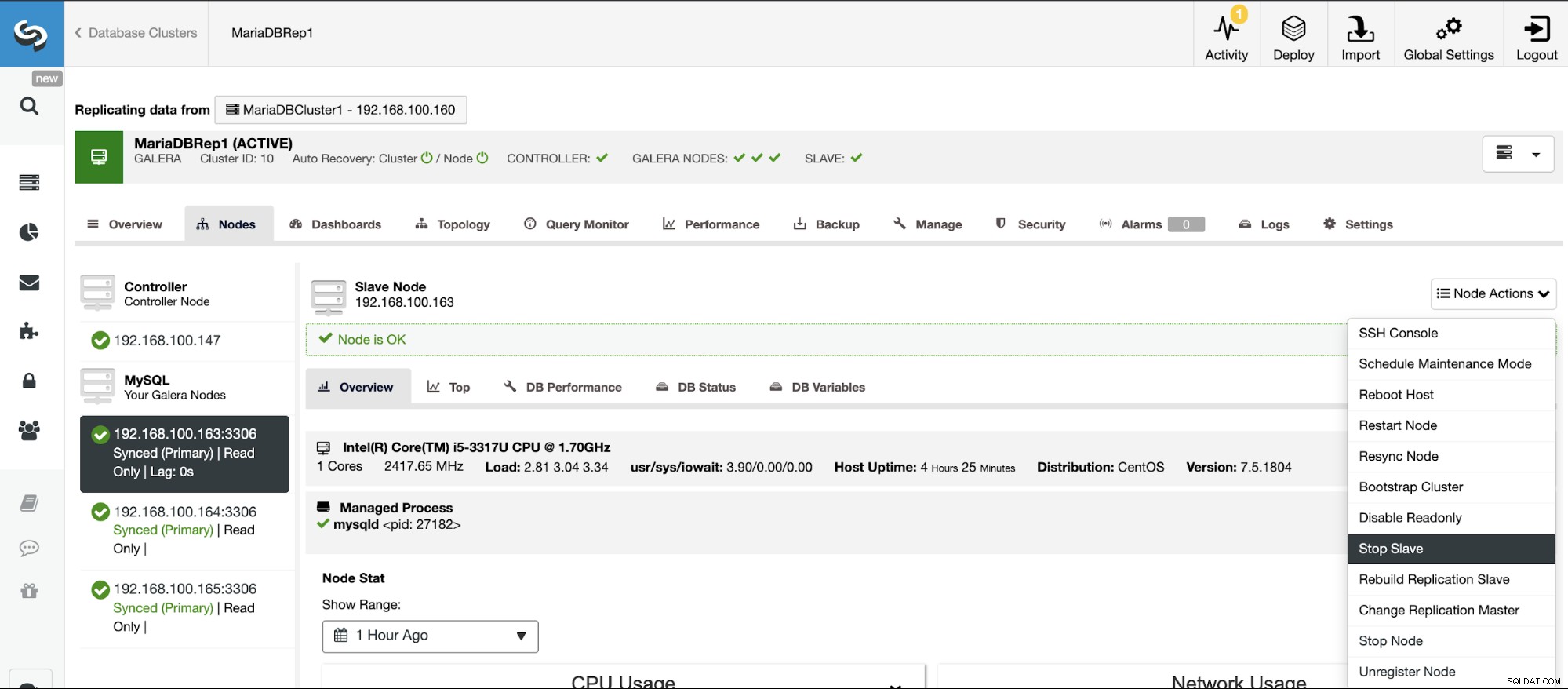
ClusterControlに移動->スレーブクラスターを選択->ノード->を選択マスタークラスターに接続されているノード->ノードアクション->スレーブの停止/スレーブの開始
このアクションを使用すると、RESETSLAVEまたはRESETSLAVEALLを使用してレプリケーションプロセスをリセットできます。これらの違いは、RESET SLAVEは、マスターホスト、ポート、クレデンシャルなどのレプリケーションパラメータを変更しないことです。この情報を削除するには、すべてのレプリケーション構成を削除するRESET SLAVE ALLを使用する必要があるため、このコマンドを使用すると、クラスター間レプリケーションリンクが破棄されます。
この機能を使用する前に、レプリケーションプロセスを停止する必要があります(前の機能を参照してください)。
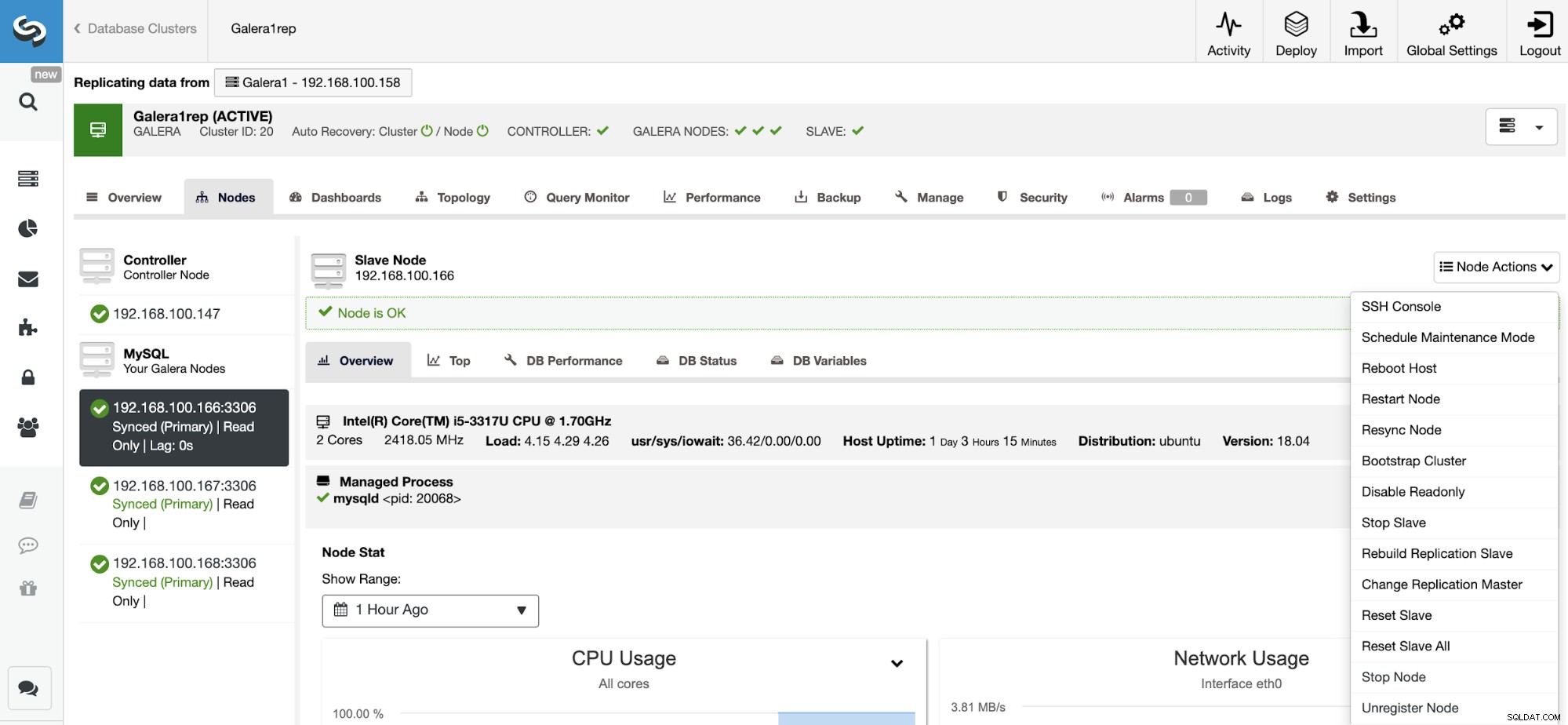
ClusterControlに移動->スレーブクラスターを選択->ノード->を選択マスタークラスターに接続されているノード->ノードアクション->スレーブのリセット/スレーブすべてのリセット
ClusterControlCLIを使用したクラスター間レプリケーションの管理
前のセクションでは、ClusterControlUIを使用してクラスター間レプリケーションを管理する方法を確認できました。それでは、コマンドラインを使用してそれを行う方法を見てみましょう。
注:このブログの冒頭で述べたように、ClusterControlがインストールされており、マスタークラスターがそれを使用してデプロイされていることを前提としています。
まず、ClusterControlCLIを使用してスレーブクラスターを作成するコマンドの例を見てみましょう。
$ s9s cluster --create --cluster-name=Galera1rep --cluster-type=galera --provider-version=10.4 --nodes="192.168.100.166;192.168.100.167;192.168.100.168" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=root --db-admin-passwd=xxxxxxxx --vendor=mariadb --remote-cluster-id=11 --logこれで、作成スレーブプロセスが実行されました。使用されている各パラメータを見てみましょう:
- クラスター:クラスターを一覧表示して操作します。
- 作成:新しいクラスターを作成してインストールします。
- Cluster-name:新しいスレーブクラスターの名前。
- Cluster-type:インストールするクラスターのタイプ。
- プロバイダーバージョン:ソフトウェアバージョン。
- ノード:スレーブクラスター内の新しいノードのリスト。
- Os-user:SSHコマンドのユーザー名。
- Os-key-file:SSH接続に使用するキーファイル。
- Db-admin:データベース管理者のユーザー名。
- Db-admin-passwd:データベース管理者のパスワード。
- Remote-cluster-id:クラスター間レプリケーションのマスタークラスターID。
- ログ:ジョブメッセージを待って監視します。
--logフラグを使用すると、ログをリアルタイムで確認できます。
Verifying job parameters.
Checking ssh/sudo on 3 hosts.
All 3 hosts are accessible by SSH.
192.168.100.166: Checking if host already exists in another cluster.
192.168.100.167: Checking if host already exists in another cluster.
192.168.100.168: Checking if host already exists in another cluster.
192.168.100.157:3306: Binary logging is enabled.
192.168.100.158:3306: Binary logging is enabled.
Creating the cluster with the following:
wsrep_cluster_address = 'gcomm://192.168.100.166,192.168.100.167,192.168.100.168'
Calling job: setupServer(192.168.100.166).
192.168.100.166: Checking OS information.
…
Caching config files.
Job finished, all the nodes have been added successfully.前に示したように、新しいクラスターで読み取り専用モードを無効にするには、各ノードで無効にすることができるので、コマンドラインから実行する方法を見てみましょう。
$ s9s node --set-read-write --nodes="192.168.100.166" --cluster-id=16 --log- ノード:ノードを処理します。
- Set-read-write:ノードを読み取り/書き込みモードに設定します。
- ノード:変更するノード。
- Cluster-id:ノードが存在するクラスターのID。
次に、次のように表示されます:
192.168.100.166:3306: Setting read_only=OFF.次のコマンドを使用して、スレーブクラスターを再構築できます。
$ s9s replication --stage --master="192.168.100.157:3306" --slave="192.168.100.166:3306" --cluster-id=19 --remote-cluster-id=11 --log- レプリケーション:データレプリケーションを監視および制御します。
- ステージ:レプリケーションスレーブをステージング/再構築します。
- マスター:マスタークラスター内のレプリケーションマスター。
- スレーブ:スレーブクラスター内のレプリケーションスレーブ。
- Cluster-id:スレーブクラスターID。
- Remote-cluster-id:マスタークラスターID。
- ログ:ジョブメッセージを待って監視します。
Rebuild replication slave 192.168.100.166:3306 from master 192.168.100.157:3306.
Remote cluster id = 11
Shutting down Galera Cluster.
192.168.100.166:3306: Stopping node.
192.168.100.166:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.166: Stopping MySQL service.
192.168.100.166: All processes stopped.
192.168.100.166:3306: Stopped node.
192.168.100.167:3306: Stopping node.
192.168.100.167:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.167: Stopping MySQL service.
192.168.100.167: All processes stopped.
…
192.168.100.157:3306: Changing master to 192.168.100.166:3306.
192.168.100.157:3306: Changed master to 192.168.100.166:3306
192.168.100.157:3306: Starting slave.
192.168.100.157:3306: Collecting replication statistics.
192.168.100.157:3306: Started slave successfully.
192.168.100.166:3306: Starting node
Writing file '192.168.100.167:/etc/mysql/my.cnf'.
Writing file '192.168.100.167:/etc/mysql/secrets-backup.cnf'.
Writing file '192.168.100.168:/etc/mysql/my.cnf'.データを複製するマスタークラスター内の別のノードを使用してトポロジを変更できるため、たとえば、次のコマンドを実行できます。
$ s9s replication --failover --master="192.168.100.161:3306" --slave="192.168.100.163:3306" --cluster-id=10 --remote-cluster-id=9 --log- レプリケーション:データレプリケーションを監視および制御します。
- フェイルオーバー:失敗した/古いマスターからマスターの役割を引き継ぎます。
- マスター:マスタークラスター内の新しいレプリケーションマスター。
- スレーブ:スレーブクラスター内のレプリケーションスレーブ。
- Cluster-id:スレーブクラスターのID。
- Remote-Cluster-id:マスタークラスターのID。
- ログ:ジョブメッセージを待って監視します。
192.168.100.161:3306 belongs to cluster id 9.
192.168.100.163:3306: Changing master to 192.168.100.161:3306
192.168.100.163:3306: My master is 192.168.100.160:3306.
192.168.100.161:3306: Sanity checking replication master '192.168.100.161:3306[cid:9]' to be used by '192.168.100.163[cid:139814070386698]'.
192.168.100.161:3306: Executing GRANT REPLICATION SLAVE ON *.* TO 'cmon_replication'@'192.168.100.163'.
Setting up link between 192.168.100.161:3306 and 192.168.100.163:3306
192.168.100.163:3306: Stopping slave.
192.168.100.163:3306: Successfully stopped slave.
192.168.100.163:3306: Setting up replication using MariaDB GTID: 192.168.100.161:3306->192.168.100.163:3306.
192.168.100.163:3306: Changing Master using master_use_gtid=slave_pos.
192.168.100.163:3306: Changing master to 192.168.100.161:3306.
192.168.100.163:3306: Changed master to 192.168.100.161:3306
192.168.100.163:3306: Starting slave.
192.168.100.163:3306: Collecting replication statistics.
192.168.100.163:3306: Started slave successfully.
192.168.100.160:3306: Flushing logs to update 'SHOW SLAVE HOSTS'次の方法で、マスタークラスターからのデータの複製を停止できます。
$ s9s replication --stop --slave="192.168.100.166:3306" --cluster-id=19 --logこれが表示されます:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Stopping slave.
192.168.100.166:3306: Successfully stopped slave.これで、もう一度開始できます:
$ s9s replication --start --slave="192.168.100.166:3306" --cluster-id=19 --logつまり、次のように表示されます:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Starting slave.
192.168.100.166:3306: Collecting replication statistics.
192.168.100.166:3306: Started slave successfully.では、使用されているパラメータを確認しましょう。
- レプリケーション:データレプリケーションを監視および制御します。
- 停止/開始:スレーブを停止/複製を開始します。
- スレーブ:レプリケーションスレーブノード。
- Cluster-id:スレーブノードが存在するクラスターのID。
- ログ:ジョブメッセージを待って監視します。
このコマンドを使用すると、RESETSLAVEまたはRESETSLAVEALLを使用してレプリケーションプロセスをリセットできます。このコマンドの詳細については、前のClusterControlUIセクションでこのコマンドの使用法を確認してください。
この機能を使用する前に、レプリケーションプロセスを停止する必要があります(前のコマンドを参照してください)。
スレーブのリセット:
$ s9s replication --reset --slave="192.168.100.166:3306" --cluster-id=19 --log192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE'.
192.168.100.166:3306: Command 'RESET SLAVE' succeeded.すべてのスレーブをリセット:
$ s9s replication --reset --force --slave="192.168.100.166:3306" --cluster-id=19 --logそして、このログは次のようになります:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
192.168.100.166:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.RESETSLAVEとRESETSLAVEALLの両方で使用されるパラメーターを見てみましょう。
- レプリケーション:データレプリケーションを監視および制御します。
- リセット:スレーブノードをリセットします。
- 強制:このフラグを使用すると、スレーブノードでRESETSLAVEALLコマンドを使用します。
- スレーブ:レプリケーションスレーブノード。
- Cluster-id:スレーブクラスターID。
- ログ:ジョブメッセージを待って監視します。
この新しいClusterControl機能を使用すると、クラスター間レプリケーションを高速に作成し、簡単で使いやすい方法で管理できます。この環境は、データベース/クラスタートポロジを改善し、ディザスタリカバリ計画、テスト環境、および概要ブログに記載されているさらに多くのオプションに役立ちます。