最良のシナリオは、データベースに障害が発生した場合に、適切なディザスタリカバリプラン(DRP)と、自動フェイルオーバープロセスを備えた高可用性環境があることです。予期しない理由はありますか?手動フェイルオーバーを実行する必要がある場合はどうなりますか?このブログでは、データベースをフェイルオーバーする必要がある場合に従うべきいくつかの推奨事項を共有します。
変更を実行する前に、フェイルオーバープロセス後の新しい問題を回避するために、いくつかの基本的なことを確認する必要があります。
ネットワーク障害、高負荷、またはその他の問題により、障害時にスレーブノードが最新ではない可能性があるため、次のことを確認する必要があります。スレーブはすべて(またはほとんどすべて)の情報を持っています。複数のスレーブノードがある場合は、どのノードが最も高度なノードであるかを確認し、フェイルオーバーするノードを選択する必要があります。
例:MariaDBサーバーのレプリケーションステータスを確認しましょう。
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)PostgreSQLの場合、WALのステータスを確認し、フェッチされたものに適用されたものを比較する必要があるため、少し異なります。
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)フェイルオーバーを実行する前に、アプリケーション/ユーザーが現在の資格情報を使用して新しいマスターにアクセスできるかどうかを確認する必要があります。データベースユーザーを複製していない場合は、資格情報が変更されている可能性があるため、変更する前にスレーブノードで資格情報を更新する必要があります。
例:mysqlデータベースのユーザーテーブルをクエリして、MariaDB / MySQLサーバーのユーザー資格情報を確認できます:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)PostgreSQLの場合、「\ du」コマンドを使用して役割を知ることができます。また、pg_hba.conf構成ファイルをチェックして、ユーザーアクセス(資格情報ではない)を管理する必要があります。だから:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}そしてpg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trust新しいマスターにアクセスする際に発生する可能性のある問題は、クレデンシャルだけではありません。ノードが別のデータセンターにある場合、またはトラフィックをフィルタリングするローカルファイアウォールがある場合は、ノードへのアクセスが許可されているかどうか、または新しいマスターノードに到達するためのネットワークルートがあるかどうかを確認する必要があります。
例:iptables。ネットワーク167.124.57.0/24からのトラフィックを許可し、追加後に現在のルールを確認しましょう:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination例:ルート。新しいマスターノードがネットワーク10.0.0.0/24にあり、アプリケーションサーバーが192.168.100.0/24にあり、192.168.100.100を使用してリモートネットワークに到達できると仮定します。したがって、アプリケーションサーバーに対応するルートを追加します。
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0上記のすべてのポイントを確認したら、データベースをフェイルオーバーするためのアクションを実行する準備ができているはずです。
スレーブノードをプロモートすると、マスターIPアドレスが変更されるため、アプリケーションまたはクライアントアクセスで変更する必要があります。
ロードバランサーを使用することは、この問題/変更を回避するための優れた方法です。フェイルオーバープロセスの後、ロードバランサーは古いマスターをオフラインとして検出し、(構成に応じて)新しいマスターにトラフィックを送信して書き込むため、アプリケーションで何も変更する必要はありません。
>例:HAProxy構成の例を見てみましょう:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkこの場合、1つのノードがダウンしていると、HAProxyはそこにトラフィックを送信せず、使用可能なノードにのみトラフィックを送信します。
複数のスレーブノードがある場合、それらの1つを昇格させた後、新しいマスターに接続するために残りのスレーブを再構成する必要があります。ノードの数によっては、これは時間のかかる作業になる可能性があります。
すべての準備が整ったら(新しいマスターの昇格、スレーブの再構成、新しいマスターへのアプリケーションの書き込み)、新しい問題を防ぐために必要なアクションを実行することが重要です。そのため、バックアップは必須です。このステップ。ほとんどの場合、インシデントの前にバックアップポリシーを実行していたので(そうでない場合は、確実に実行する必要があります)、バックアップがまだ実行されているかどうか、または新しいトポロジで実行されるかどうかを確認する必要があります。古いマスターでバックアップを実行していたか、現在マスターであるスレーブノードを使用している可能性があるため、変更後もバックアップポリシーが機能することを確認する必要があります。
フェイルオーバープロセスを実行する場合、プロセスの前、最中、および後に監視する必要があります。これにより、問題が悪化する前に防止したり、フェイルオーバー中に予期しない問題を検出したり、その後に問題が発生したかどうかを知ることができます。たとえば、アクティブな接続の数を確認して、アプリケーションが新しいマスターにアクセスできるかどうかを監視する必要があります。
- サーバーの負荷(CPU、メモリ、ディスク)
もちろん、問題が発生した場合は、ロールバックできる必要があります。古いノードへのトラフィックをブロックし、可能な限り分離しておくことは、このための良い戦略である可能性があるため、ロールバックが必要な場合に備えて、古いノードを使用できるようにします。ロールバックが数分後の場合、トラフィックによっては、おそらくこれらの分のデータを古いマスターに挿入する必要があるため、この情報を取得して適用するために、一時マスターノードも使用可能で分離されていることを確認してください。
ClusterControlを使用したフェイルオーバープロセスの自動化
フェイルオーバーを実行するために必要なこれらすべてのタスクを確認します。おそらく、フェイルオーバーを自動化し、このすべての手作業を避けたいと思うでしょう。このために、ClusterControlが提供できるいくつかの機能を利用できます。たとえば、自動回復、バックアップ、ユーザー管理、監視など、すべて同じシステムからの機能です。
ClusterControlを使用すると、レプリケーションステータスとその遅延を確認し、資格情報を作成または変更し、ネットワークとホストのステータスを把握し、さらに多くの確認を行うことができます。
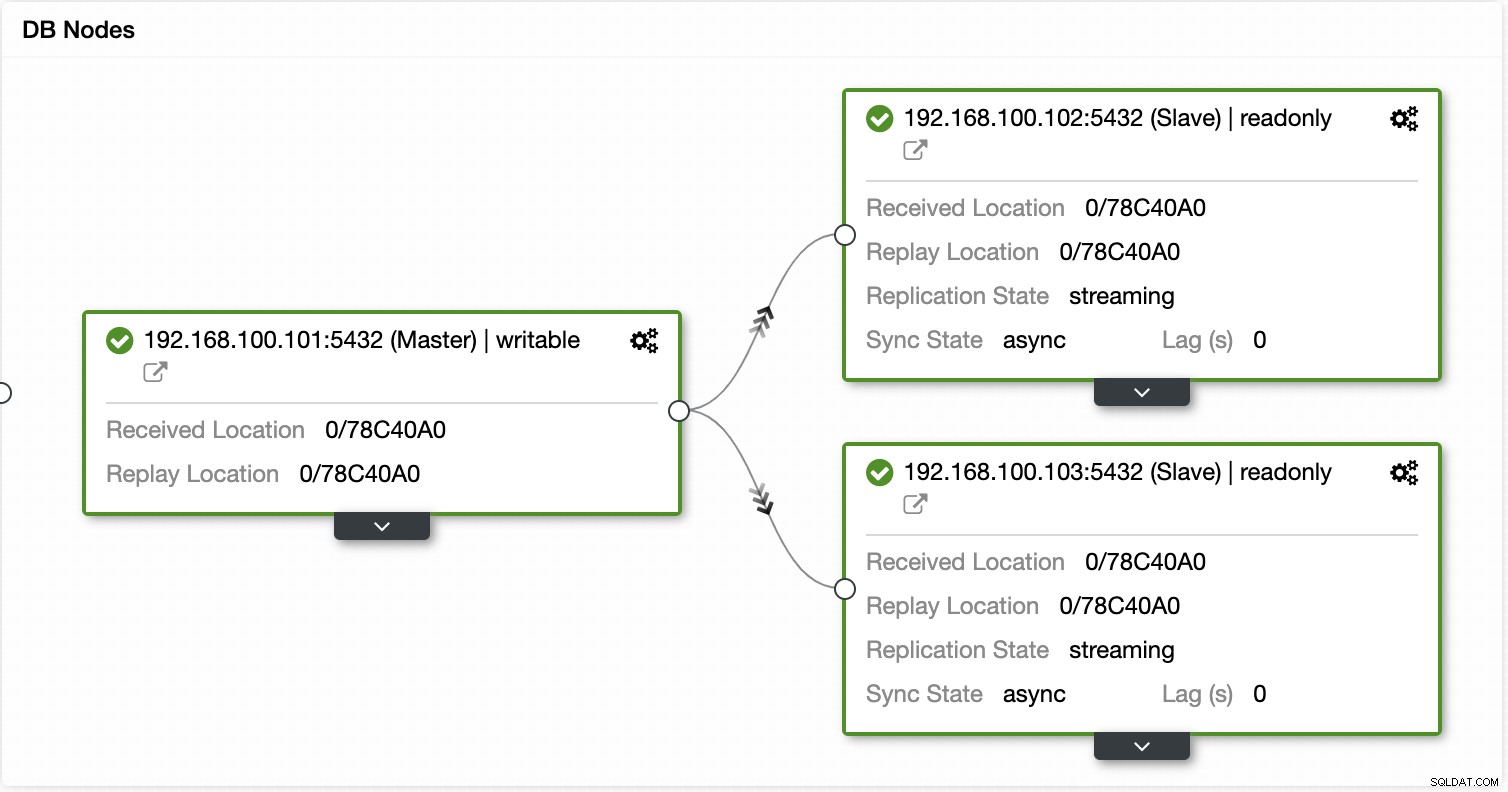
ClusterControlを使用すると、スレーブのプロモートなど、さまざまなクラスターおよびノードアクションを実行することもできます。 、データベースとサーバーの再起動、データベースノードの追加または削除、ロードバランサーノードの追加または削除、レプリケーションスレーブの再構築など。
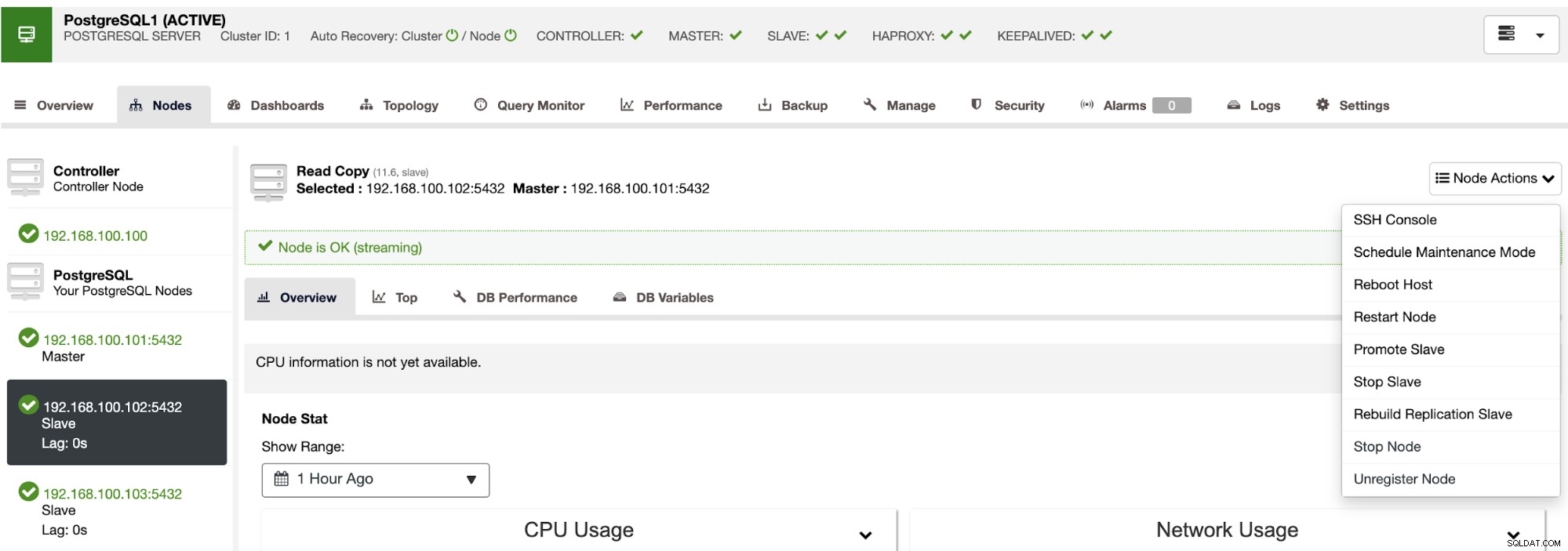
これらのアクションを使用して、必要に応じて再構築およびプロモートすることでフェイルオーバーをロールバックすることもできます前のマスター。
ClusterControlには、何が起こっているのか、または以前に何かが起こった場合でも、それを知るのに役立つ監視およびアラートサービスがあります。
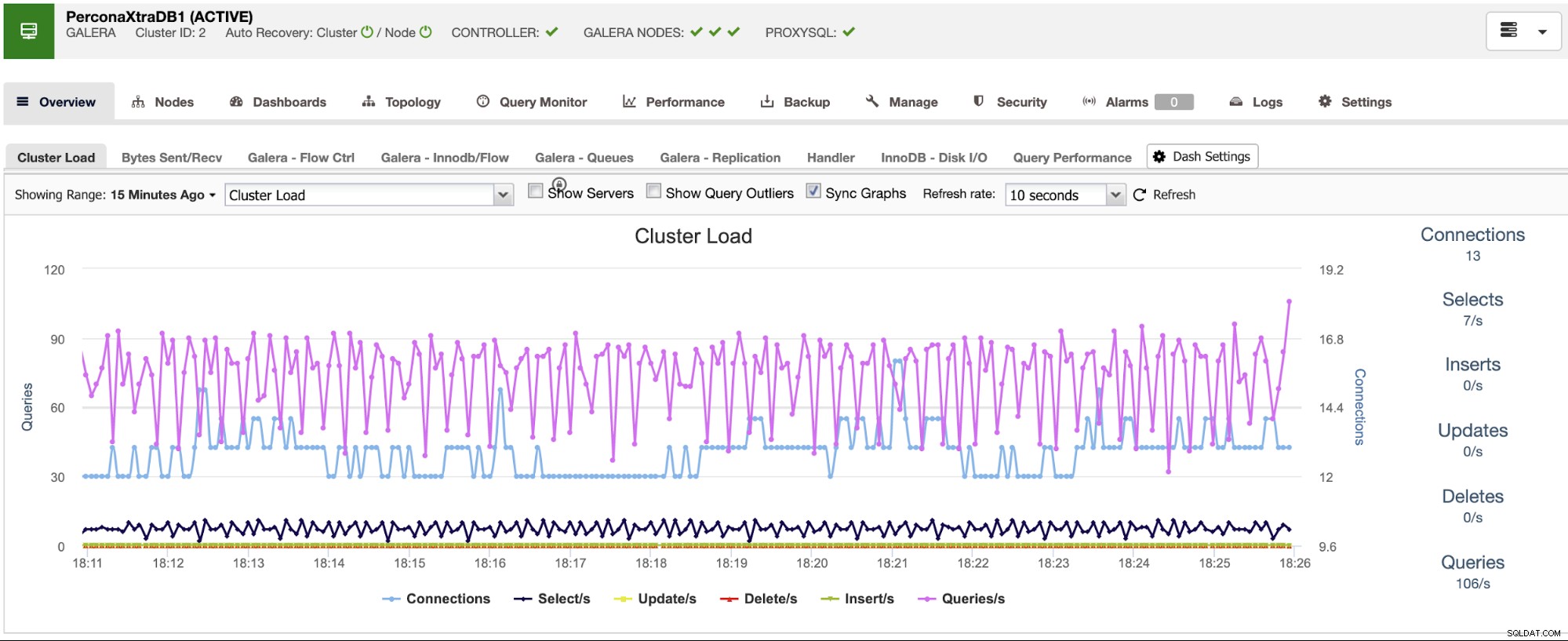
ダッシュボードセクションを使用して、よりユーザーフレンドリーなビューを表示することもできますシステムのステータスについて。
マスターデータベースに障害が発生した場合は、必要なアクションをできるだけ早く実行するために、すべての情報を用意しておく必要があります。優れたDRPを持つことは、システムを常に(またはほぼすべて)実行し続けるための鍵です。このDRPには、企業にとって許容可能なRTO(目標復旧時間)を実現するための十分に文書化されたフェイルオーバープロセスを含める必要があります。