これは、PostgreSQL用のオープンソースの高可用性ツールである2ndQuadrantのrepmgrに関する2部構成のシリーズの第2回です。
最初の部分では、「監視」ノードとともに3ノードのPostgreSQL12クラスターをセットアップしました。クラスタは、プライマリノードと2つのスタンバイノードで構成されていました。クラスターとウィットネスノードは、Amazon Web Service Virtual Private Cloud(VPC)でホストされていました。以下に示すように、PostgresインスタンスをホストするEC2サーバーは、さまざまなアベイラビリティーゾーン(AZ)のサブネットに配置されました。
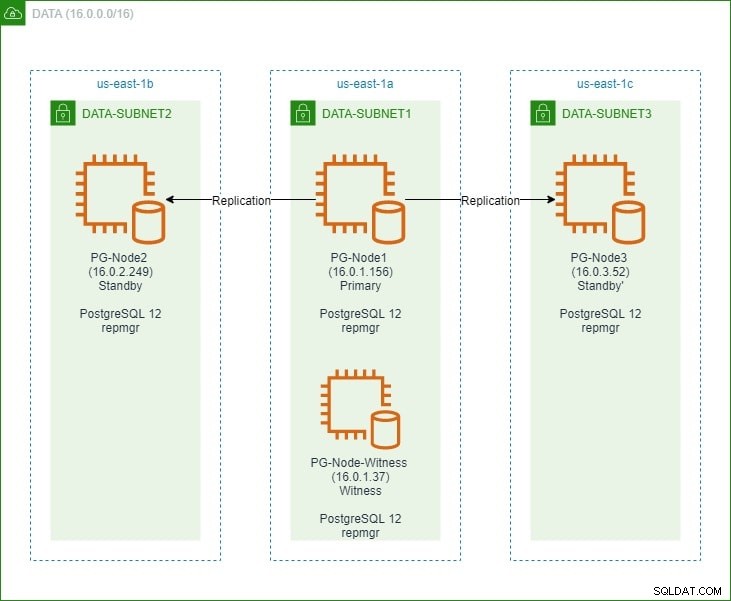
ノード名とそのIPアドレスを詳細に参照するため、ノードの詳細を示す表をもう一度示します。
| ノード名 | IPアドレス | 役割 | 実行中のアプリ |
| PG-Node1 | 16.0.1.156 | プライマリ | PostgreSQL12およびrepmgr |
| PG-Node2 | 16.0.2.249 | スタンバイ1 | PostgreSQL12およびrepmgr |
| PG-Node3 | 16.0.3.52 | スタンバイ2 | PostgreSQL12およびrepmgr |
| PG-Node-Witness | 16.0.1.37 | 証人 | PostgreSQL12およびrepmgr |
プライマリノードとスタンバイノードにrepmgrをインストールしてから、プライマリノードをrepmgrに登録しました。次に、プライマリから両方のスタンバイノードのクローンを作成し、それらを起動しました。両方のスタンバイノードもrepmgrに登録されました。 「repmgrclustershow」コマンドは、すべてが期待どおりに実行されていることを示しました。

現在の問題
repmgrを使用したストリーミングレプリケーションの設定は非常に簡単です。次に行う必要があるのは、プライマリが使用できなくなった場合でもクラスターが機能するようにすることです。これがこの記事で取り上げる内容です。
PostgreSQLレプリケーションでは、いくつかの理由でプライマリが使用できなくなる可能性があります。例:
- プライマリノードのオペレーティングシステムがクラッシュしたり、応答しなくなったりする可能性があります
- プライマリノードがネットワーク接続を失う可能性があります
- プライマリノードのPostgreSQLサービスがクラッシュ、停止、または予期せず使用できなくなる可能性があります
- プライマリノードのPostgreSQLサービスが意図的または誤って停止される可能性があります
プライマリが使用できなくなると、スタンバイはしません 自動的に主要な役割に昇格します。スタンバイは引き続き読み取り専用クエリを処理しますが、データはプライマリから受信した最後のLSNまで最新です。書き込み操作を試みると失敗します。
これを軽減する方法は2つあります。
- スタンバイは手動で プライマリロールにアップグレードされました。これは通常、計画されたフェイルオーバーまたは「スイッチオーバー」の場合です
- スタンバイは自動的に 主な役割に昇格しました。これは、レプリケーションを継続的に監視し、プライマリが使用できない場合にリカバリアクションを実行する非ネイティブツールの場合です。 repmgrはそのようなツールの1つです。
ここでは、2番目のシナリオを検討します。ただし、この状況にはいくつかの追加の課題があります:
- スタンバイが複数ある場合、ツール(またはスタンバイ)はどのスタンバイをプライマリとして昇格させるかをどのように決定しますか?クォーラムとプロモーションプロセスはどのように機能しますか?
- 複数のスタンバイの場合、1つがプライマリになった場合、他のノードはどのようにして新しいプライマリとして「フォロー」を開始しますか?
- プライマリが機能しているが、何らかの理由で一時的にネットワークから切り離されている場合はどうなりますか?スタンバイの1つがプライマリに昇格し、元のプライマリがオンラインに戻った場合、「スプリットブレイン」の状況を回避するにはどうすればよいですか?
remgrの回答:Witnessノードとrepmgrデーモン
これらの質問に答えるために、repmgrは監視ノードと呼ばれるものを使用します 。プライマリが使用できない場合–スタンバイの1つをプライマリの役割に昇格させる必要がある場合に、スタンバイがクォーラムに到達するのを支援するのは、監視ノードの仕事です。スタンバイは、プライマリノードが実際にオフラインであるか、一時的に利用できないかを判断することで、このクォーラムに到達します。監視ノードは、プライマリノードと同じデータセンター/ネットワークセグメント/サブネットに配置する必要がありますが、プライマリノードと同じ物理ホスト上で実行しないでください。
このシリーズの最初のパートでは、プライマリノードと同じアベイラビリティーゾーンとサブネットに監視ノードを展開したことを思い出してください。これにPG-Node-Witnessという名前を付け、PostgreSQL12インスタンスをインストールしました。この投稿では、そこにもrepmgrをインストールしますが、それについては後で詳しく説明します。
ソリューションの2番目のコンポーネントは、 repmgrデーモン(repmgrd)です。 クラスターのすべてのノードと監視ノードで実行されます。繰り返しになりますが、このシリーズの最初の部分ではこのデーモンを開始しませんでしたが、ここで開始します。デーモンはrepmgrパッケージの一部として提供されます。有効にすると、デーモンは通常のサービスとして実行され、クラスターの状態を継続的に監視します。プライマリがオフラインであることについてクォーラムに達すると、フェイルオーバーを開始します。 スタンバイを自動的にプロモートできるだけでなく、マルチノードクラスタ内の他のスタンバイを再開して、新しいプライマリを追跡することもできます 。
クォーラムプロセス
スタンバイがプライマリを認識できないことに気付いた場合、スタンバイは他のスタンバイと相談します。クラスタで実行されているすべてのスタンバイがクォーラムに到達し、一連のチェックを使用して新しいプライマリを選択します。
- 各スタンバイは、プライマリを最後に「見た」時間について他のスタンバイに問い合わせます。スタンバイの最後に複製されたLSNまたはプライマリとの最後の通信の時刻が、現在のノードの最後に複製されたLSNまたは最後の通信の時刻よりも新しい場合、ノードは何もせず、プライマリとの通信が復元されるのを待ちます
- どのスタンバイもプライマリを認識できない場合、監視ノードが使用可能かどうかを確認します。監視ノードにも到達できない場合、スタンバイはプライマリ側でネットワークの停止があると想定し、新しいプライマリの選択に進みません。
- 目撃者に連絡できる場合、スタンバイはプライマリがダウンしていると見なし、プライマリの選択に進みます
- 「優先」プライマリとして構成されたノードが昇格されます。各スタンバイでは、新しいプライマリに従うようにレプリケーションが再初期化されます。
自動フェイルオーバー用のクラスターの構成
次に、自動フェイルオーバー用にクラスターと監視ノードを構成します。
ステップ1:Witnessにrepmgrをインストールして構成する
前回の記事で、repmgrパッケージをインストールする方法をすでに説明しました。これは、監視ノードでも行います:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
そして:
# yum install repmgr12 -y
次に、監視ノードのpostgresql.confファイルに次の行を追加します。
listen_addresses = '*' shared_preload_libraries = 'repmgr'
また、監視ノードのpg_hba.confファイルに次の行を追加します。個々のIPアドレスを指定する代わりに、クラスターのCIDR範囲をどのように使用しているかに注意してください。
local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 16.0.0.0/16 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 16.0.0.0/16 trust
注
[ここで説明する手順は、デモンストレーションのみを目的としています。ここでの例は、ノードに外部から到達可能なIPを使用しています。したがって、listen_address =‘*’をpg_hbaの「trust」セキュリティメカニズムと一緒に使用すると、セキュリティリスクが発生するため、本番シナリオでは使用しないでください。本番システムでは、ノードはすべて1つ以上のプライベートサブネット内にあり、ジャンプホストからプライベートIPを介して到達できます。]
postgresql.confとpg_hba.confの変更が完了したら、証人にrepmgrユーザーとrepmgrデータベースを作成し、repmgrユーザーのデフォルトの検索パスを変更します。
[example@sqldat.comitness ~]$ createuser --superuser repmgr [example@sqldat.com ~]$ createdb --owner=repmgr repmgr [example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"
最後に、/ etc / repmgr / 12 /
の下にあるrepmgr.confファイルに次の行を追加します。node_id=4 node_name='PG-Node-Witness' conninfo='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2' data_directory='/var/lib/pgsql/12/data'
構成パラメーターが設定されたら、監視ノードでPostgreSQLサービスを再起動します。
# systemctl restart postgresql-12.service
監視ノードrepmgrへの接続をテストするには、プライマリノードから次のコマンドを実行します。
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
次に、postgresユーザーとして「repmgrwitness register」コマンドを実行して、監視ノードをrepmgrに登録します。 プライマリのアドレスをどのように使用しているかに注意してください 以下のコマンドの監視ノードではなく、ノード:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf witness register -h 16.0.1.156
これは、「repmgr witness register」コマンドが、監視ノードのメタデータをプライマリノードのrepmgrデータベースに追加し、必要に応じて、repmgr拡張機能をインストールし、repmgrメタデータを監視ノードにコピーすることによって監視ノードを初期化するためです。
出力は次のようになります:
INFO: connecting to witness node "PG-Node-Witness" (ID: 4) INFO: connecting to primary node NOTICE: attempting to install extension "repmgr" NOTICE: "repmgr" extension successfully installed INFO: witness registration complete NOTICE: witness node "PG-Node-Witness" (ID: 4) successfully registered
最後に、任意のノードからセットアップ全体のステータスを確認します。
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
出力は次のようになります:

ステップ2:sudoersファイルの変更
クラスターとウィットネスが実行されている状態で、クラスターの各ノードとウィットネスノードのsudoersファイルに次の行を追加します。
Defaults:postgres !requiretty postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service, /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.service
ステップ3:repmgrdパラメーターの構成
各ノードのrepmgr.confファイルにはすでに4つのパラメーターが追加されています。追加されたパラメーターは、repmgr操作に必要な基本的なパラメーターです。 repmgrデーモンと自動フェイルオーバーを有効にするには、他の多くのパラメーターを有効化/追加する必要があります。次のサブセクションでは、各パラメータと、各ノードで設定される値について説明します。
フェイルオーバー
フェイルオーバーパラメーターは、repmgrデーモンの必須パラメーターの1つです。このパラメーターは、フェイルオーバー状況が検出されたときに自動フェイルオーバーを開始する必要があるかどうかをデーモンに通知します。 「手動」または「自動」の2つの値のいずれかを持つことができます。各ノードでこれを自動に設定します:
failover='automatic'
prompt_command
これは、repmgrデーモンのもう1つの必須パラメーターです。このパラメーターは、スタンバイをプロモートするために実行する必要があるコマンドをrepmgrデーモンに指示します。このパラメーターの値は、通常、「repmgrstandbypromote」コマンドまたはコマンドを呼び出すシェルスクリプトへのパスになります。このユースケースでは、各ノードでこれを次のように設定します。
promote_command='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'
follow_command
これは、repmgrデーモンの3番目の必須パラメーターです。このパラメータは、スタンバイノードに新しいプライマリを追跡するように指示します。 repmgrデーモンは、実行時に%nプレースホルダーを新しいプライマリのノードIDに置き換えます。
follow_command='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'
優先度
優先度パラメータは、プライマリになるためのノードの適格性に重みを追加します。このパラメーターをより高い値に設定すると、ノードがプライマリノードになるための適格性が高くなります。また、ノードのこの値をゼロに設定すると、ノードがプライマリとして昇格されないようになります。
このユースケースでは、PG-Node2とPG-Node3の2つのスタンバイがあります。 PG-Node1がオフラインになったときにPG-Node2を新しいプライマリとして昇格させ、PG-Node3を新しいプライマリとしてPG-Node2に続くようにします。 2つのスタンバイノードでパラメータを次の値に設定します。
| ノード名 | パラメータ設定 |
| PG-Node2 | 優先度 =60 |
| PG-Node3 | 優先度 =40 |
monitor_interval_secs
このパラメーターは、アップストリームノードの可用性をチェックする頻度(秒数)をrepmgrデーモンに通知します。この場合、アップストリームノードはプライマリノードのみです。デフォルト値は2秒ですが、とにかく各ノードで明示的に設定します:
monitor_interval_secs=2
connection_check_type
connection_check_typeパラメーターは、repmgrデーモンがアップストリームノードに到達するために使用するプロトコルを指定します。このパラメータは3つの値を取ることができます:
- ping :repmgrはPQPing()メソッドを使用します
- 接続 :repmgrはアップストリームノードへの新しい接続を作成しようとします
- クエリ :repmgrは、既存の接続を使用してアップストリームノードでSQLクエリを実行しようとします
ここでも、このパラメーターを各ノードのpingのデフォルト値に設定します。
connection_check_type='ping'
reconnect_attemptsおよびreconnect_interval
プライマリが使用できなくなると、スタンバイノードのrepmgrデーモンはreconnect_attempts回プライマリへの再接続を試みます。このパラメーターのデフォルト値は6です。各再接続の試行の間に、reconnect_interval秒(デフォルト値は10)を待機します。デモンストレーションの目的で、短い間隔を使用し、再接続の試行回数を減らします。このパラメータはすべてのノードで設定します:
reconnect_attempts=4 reconnect_interval=8
primary_visibility_consensus
マルチノードクラスタでプライマリが使用できなくなった場合、スタンバイは相互に相談して、フェールオーバーに関するクォーラムを構築できます。これは、各スタンバイに最後にプライマリを見た時刻を尋ねることによって行われます。ノードの最後の通信が非常に最近で、ローカルノードがプライマリを確認した時間よりも遅い場合、ローカルノードはプライマリがまだ使用可能であると見なし、フェイルオーバーの決定を進めません。
このコンセンサスモデルを有効にするには、証人を含む各ノードでprimary_visibility_consensusパラメータを「true」に設定する必要があります。
primary_visibility_consensus=true
standby_disconnect_on_failover
スタンバイノードでstandby_disconnect_on_failoverパラメータが「true」に設定されている場合、repmgrデーモンは、そのWALレシーバーがプライマリから切断され、WALセグメントを受信していないことを確認します。また、フェイルオーバーの決定を行う前に、他のスタンバイノードのWALレシーバーが停止するのを待ちます。このパラメータは、各ノードで同じ値に設定する必要があります。これを「true」に設定しています。
standby_disconnect_on_failover=true
このパラメーターをtrueに設定すると、フェイルオーバーが発生したときに、すべてのスタンバイノードがプライマリからのデータの受信を停止したことを意味します。このプロセスには、5秒の遅延に加えて、フェイルオーバーの決定が行われる前にWALレシーバーが停止するのにかかる時間があります。デフォルトでは、repmgrデーモンは30秒間待機して、フェイルオーバーが発生する前に、すべての兄弟ノードがWALセグメントの受信を停止したことを確認します。
repmgrd_service_start_commandおよびrepmgrd_service_stop_command
これらの2つのパラメーターは、「repmgrdaemonstart」および「repmgrdaemonstop」コマンドを使用してrepmgrデーモンを開始および停止する方法を指定します。
基本的に、これら2つのコマンドは、サービスを開始/停止するためのオペレーティングシステムコマンドのラッパーです。 2つのパラメーター値は、これらのコマンドをOS固有のバージョンにマップします。これらのパラメータは、各ノードで次の値に設定します。
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgr12.service' repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgr12.service'
PostgreSQLサービスの開始/停止/再起動コマンド
その操作の一部として、repmgrデーモンは多くの場合PostgreSQLサービスを停止、開始、または再起動する必要があります。これがスムーズに行われるようにするには、対応するオペレーティングシステムコマンドをrepmgr.confファイルのパラメータ値として指定するのが最善です。この目的のために、各ノードに4つのパラメーターを設定します。
service_start_command='sudo /usr/bin/systemctl start postgresql-12.service' service_stop_command='sudo /usr/bin/systemctl stop postgresql-12.service' service_restart_command='sudo /usr/bin/systemctl restart postgresql-12.service' service_reload_command='sudo /usr/bin/systemctl reload postgresql-12.service'
monitoring_history
monitor_historyパラメーターを「yes」に設定すると、repmgrがクラスター監視データを確実に保存します。各ノードでこれを「はい」に設定します:
monitoring_history=yes
log_status_interval
各ノードにパラメーターを設定して、repmgrデーモンがステータスメッセージをログに記録する頻度を指定します。この場合、これを60秒ごとに設定しています:
log_status_interval=60
ステップ4:repmgrデーモンを起動する
クラスタと監視ノードにパラメータが設定されたので、コマンドのドライランを実行してrepmgrデーモンを起動します。これを最初にプライマリノードでテストし、次に2つのスタンバイノードでテストし、次に監視ノードでテストします。コマンドはpostgresユーザーとして実行する必要があります:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
出力は次のようになります。
INFO: prerequisites for starting repmgrd met DETAIL: following command would be executed: sudo /usr/bin/systemctl start repmgr12.service
次に、4つのノードすべてでデーモンを起動します。
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
各ノードの出力には、デーモンが開始したことが示されているはずです。
NOTICE: executing: "sudo /usr/bin/systemctl start repmgr12.service" NOTICE: repmgrd was successfully started
プライマリノードまたはスタンバイノードからサービスの起動イベントを確認することもできます:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_start
出力には、デーモンが接続を監視していることが示されます。
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+---------------+----+---------------------+------------------------------------------------------------------ 4 | PG-Node-Witness | repmgrd_start | t | 2020-02-05 11:37:31 | witness monitoring connection to primary node "PG-Node1" (ID: 1) 3 | PG-Node3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitoring connection to upstream node "PG-Node1" (ID: 1) 2 | PG-Node2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitoring connection to upstream node "PG-Node1" (ID: 1) 1 | PG-Node1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitoring cluster primary "PG-Node1" (ID: 1)
最後に、任意のスタンバイでsyslogからのデーモン出力を確認できます。
# cat /var/log/messages | grep repmgr | less
PG-Node3からの出力は次のとおりです。
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] connecting to database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:24 PG-Node3 systemd[1]: repmgr12.service: Can't open PID file /run/repmgr/repmgrd-12.pid (yet?) after start: No such file or directory Feb 5 11:37:24 PG-Node3 repmgrd[2014]: INFO: set_repmgrd_pid(): provided pidfile is /run/repmgr/repmgrd-12.pid Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] starting monitoring of node "PG-Node3" (ID: 3) Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] monitoring connection to upstream node "PG-Node1" (ID: 1) Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [DETAIL] last monitoring statistics update was 2 seconds ago Feb 5 11:39:26 PG-Node3 repmgrd[2014]: [2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state … …
プライマリノードでsyslogをチェックすると、異なるタイプの出力が表示されます。
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] connecting to database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] starting monitoring of node "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] monitoring cluster primary "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node-Witness" (ID: 4) is not yet attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node3" (ID: 3) is attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node2" (ID: 2) is attached Feb 5 11:37:32 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:32] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:38:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:38:14] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state Feb 5 11:39:15 PG-Node1 repmgrd[2017]: [2020-02-05 11:39:15] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state … …
ステップ5:失敗したプライマリのシミュレーション
次に、プライマリノード(PG-Node1)を停止して、障害が発生したプライマリをシミュレートします。ノードのシェルプロンプトから、次のコマンドを実行します。
# systemctl stop postgresql-12.service
フェイルオーバープロセス
プロセスが停止したら、約1〜2分待ってから、PG-Node2のsyslogファイルを確認します。以下のメッセージが表示されます。わかりやすく簡単にするために、メッセージの色分けされたグループと行間に空白を追加しました:
… Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] checking state of node 1, 2 of 4 attempts Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] checking state of node 1, 3 of 4 attempts Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of node 1, 4 of 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to reconnect to node 1 after 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] wal receiver not running Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] WAL receiver disconnected on all sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] WAL receiver disconnected on all 2 sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] local node's last receive lsn: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node3" (ID: 3) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 3 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] last receive LSN for sibling node "PG-Node3" (ID: 3) is: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has same LSN as current candidate "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has lower priority (40) than current candidate "PG-Node2" (ID: 2) (60) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node-Witness" (ID: 4) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID: 4) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 4 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promotion candidate is "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] this node is the winner, will now promote itself and inform other nodes … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promoting standby to primary Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] promoting server "PG-Node2" (ID: 2) using pg_promote() Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] STANDBY PROMOTE successful Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID: 2) was successfully promoted to primary Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] 2 followers to notify Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node3" (ID: 3) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node-Witness" (ID: 4) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] switching to primary monitoring mode Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] monitoring cluster primary "PG-Node2" (ID: 2) Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:55:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:55:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state Feb 5 11:56:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:56:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state … …
ここにはたくさんの情報がありますが、イベントがどのように展開されたかを分析してみましょう。 For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
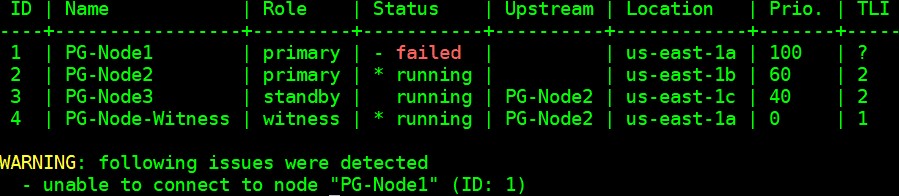
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------ 3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID: 2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID: 3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID: 4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID: 2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID: 2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID: 2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID: 4) has connected
結論
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1