MariaDBレプリケーションは、MariaDBで最も人気のある高可用性ソリューションの1つであり、Booking.comやGoogleなどのトップ企業によって広く使用されています。セットアップは非常に簡単ですが、ソフトウェアのアップグレード、スキーマの変更、トポロジの変更、フェイルオーバー、リカバリなど、継続的なメンテナンスには常に注意が必要なトレードオフがあります。それでも、適切なツールセットを使用すれば、トポロジを簡単に処理できるはずです。このブログ投稿では、ClusterControlを使用してMariaDBレプリケーションを効率的に監視するためのヒントをいくつか紹介します。
レプリケーションのセットアップは、いくつかの役割で構成されています。レプリケーション設定のノードは次のようになります:
- バックアップマスター-マスターの冗長性のためだけに、半同期レプリケーションを備えた読み取り専用スレーブ。
- 中間マスター-マスターから複製し、他のスレーブはこのノードから複製します。
- Binlogサーバー-データを提供せずにbinlogのみを収集/保存します。
- Slave-マスターから複製し、通常は読み取り専用として設定します。
すべての役割には独自の責任と制限があり、データベースノードを処理するときは正しいトポロジを理解する必要があります。これは、アプリケーションが常にマスターノードにのみ書き込む必要があるアプリケーションにも当てはまります。したがって、どのノードがどの役割を担っているのかを概観することが重要です。そうすれば、データベースを台無しにすることはありません。
ClusterControlでは、次のスクリーンショットに示すように、トポロジビューアでレプリケーショントポロジとその状態の概要を確認できます。
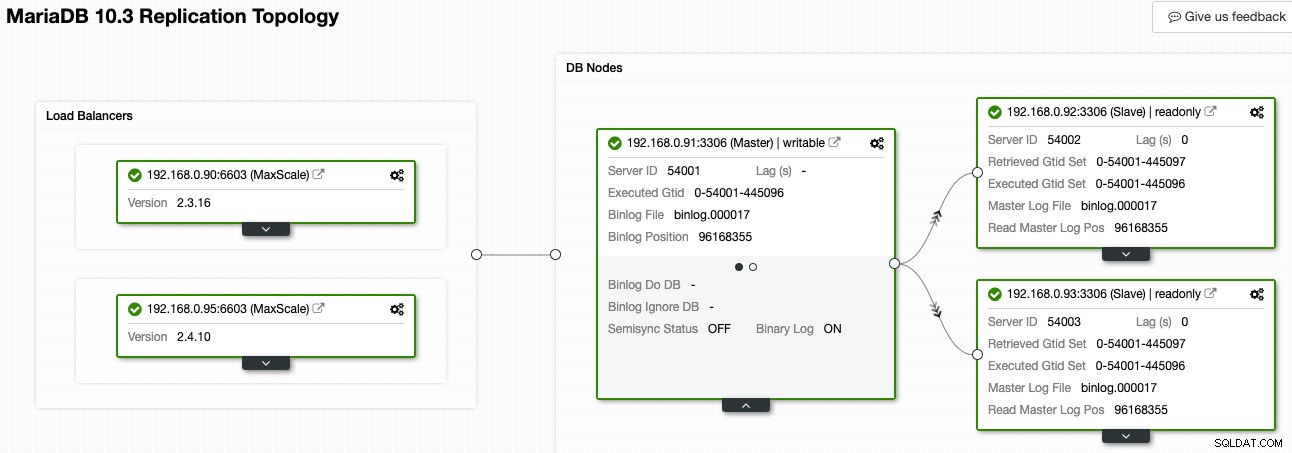
ClusterControlは、MariaDBレプリケーションを理解し、スレーブノードを指す矢印で表されているように、正しいレプリケーションデータフローを使用してトポロジを視覚化できます。レプリケーション設定では、どのノードがマスター、スレーブ、ロードバランサー(MaxScale)であるかを簡単に区別できます。緑色のボックスは、割り当てられた役割ですべての重要なサービスが期待どおりに実行されていることを示しています。
多くのノードで問題が発生している次のスクリーンショットについて考えてみます。
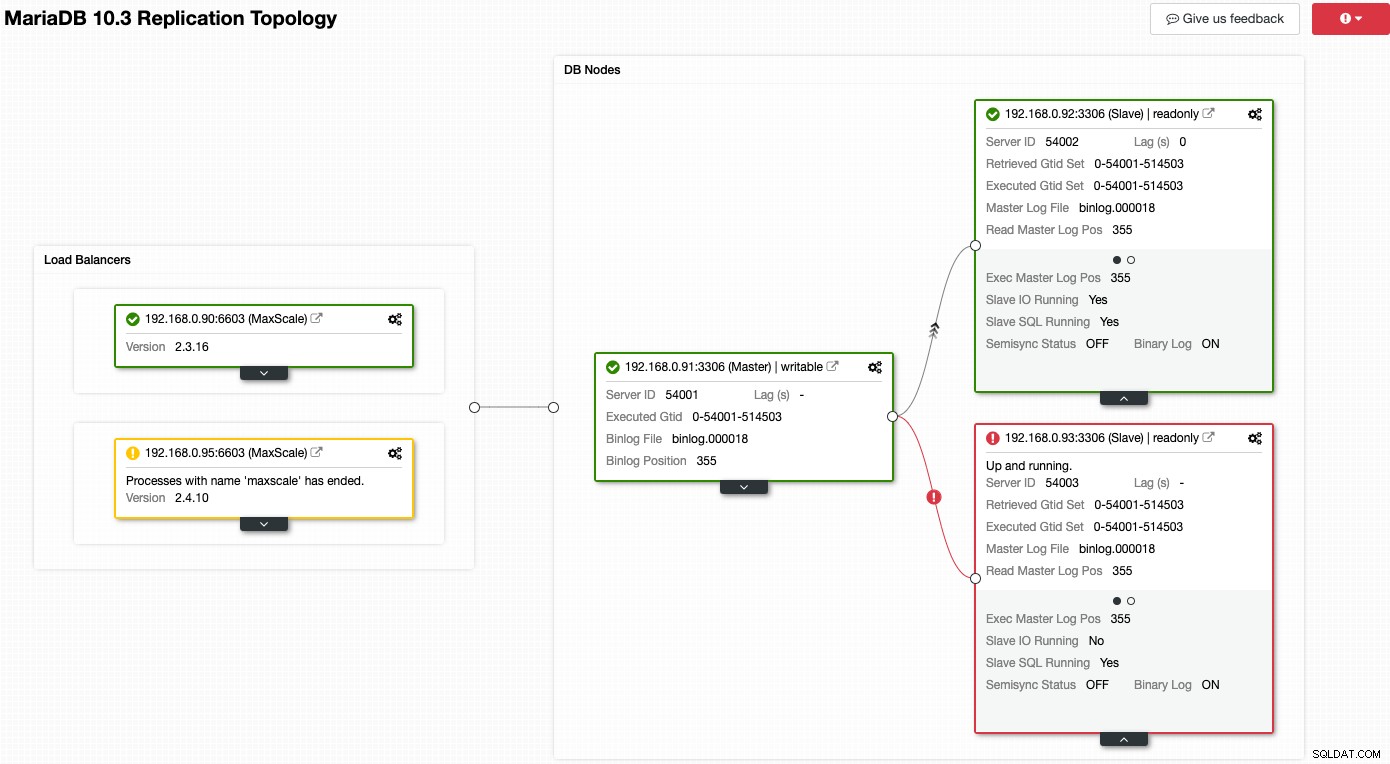
ClusterControlは、現在のトポロジの何が問題になっているのかをすぐに知らせます。スレーブの1つ(赤いボックス)は、マスターから複製する接続の問題を示すために、「SlaveIORunning」を「いいえ」と表示しています。黄色のボックスは、MaxScaleサービスが実行されていないことを示しています。また、MaxScaleのバージョンが両方のノードで同一ではないこともわかります。歯車のアイコン(すべてのボックスの右上)を直接クリックして管理タスクを実行することもできます。これにより、間違ったノードを選択するリスクが軽減されます。
これは、データレプリケーションの一貫性に依存する場合に最も重要なことです。レプリケーションラグは、スレーブがマスターで発生する更新に追いつけない場合に発生します。適用されていない変更はスレーブのリレーログに蓄積され、スレーブ上のデータベースのバージョンはマスターとはますます異なります。
ClusterControlのレプリケーションラグヒストグラムは、[概要]-> [レプリケーションラグ]にあり、ClusterControlは"SHOW SLAVE STATUS"出力からSeconds_Behind_Master値を常にサンプリングします:
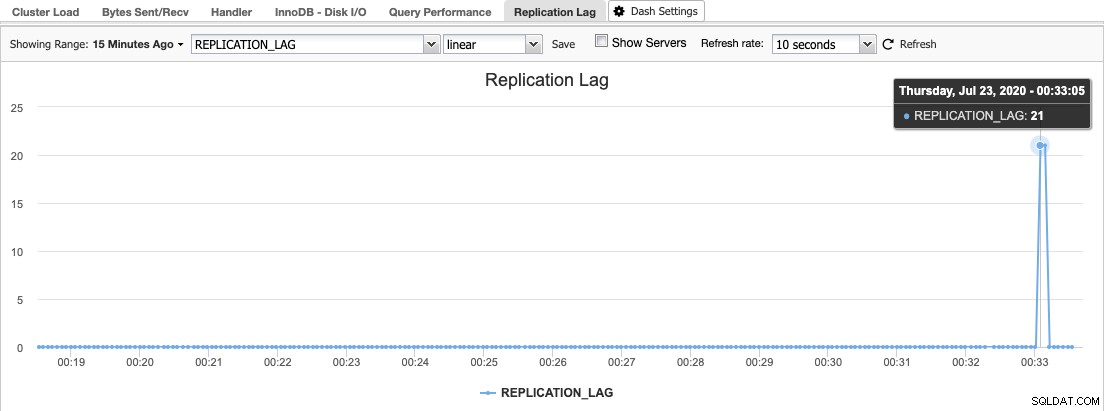
レプリケーションラグは、I/OスレッドまたはSQLスレッドのいずれかが要求に対応できない場合に発生します。 I / Oスレッドに問題がある場合は、マスターとそのスレーブ間のネットワーク接続が遅いか、問題があることを意味します。 slave_compressed_protocolを有効にしてネットワークトラフィックを圧縮したり、ネットワーク管理者に報告したりすることを検討してください。
SQLスレッドの場合、問題はおそらく、スレーブの適用に時間がかかりすぎる最適化が不十分なクエリが原因です。実行時間の長いトランザクションまたはI/Oアクティビティが多すぎる可能性があります。 ROWまたはMIXEDレプリケーション形式を使用するときにスレーブテーブルに主キーがないことも、このスレッドの遅延の一般的な原因です。テーブルのマスターバージョンとスレーブバージョンに主キーがあることを確認してください。
その他のヒントとコツについては、このブログ投稿「マルチクラウド展開でレプリケーションの遅延を減らす方法」で説明しています。
レプリケーションクラスター内のすべてのノードでかなりの量のストレージを消費する可能性があるため、バイナリログとリレーログのディスクサイズを監視することが重要です。通常、expire_logs_daysシステム変数を設定して、指定された日数が経過するとバイナリログファイルを自動的に期限切れにします(例:expire_logs_days =7)。バイナリログのサイズは、作成されたバイナリイベント(着信書き込み)の数に完全に依存し、MariaDBによってログが期限切れになる前に消費されるディスクスペースの量はほとんどわかりません。スレーブでlog_slave_updatesを有効にすると、同じサーバー上にバイナリログとリレーログの両方が存在するため、ログのサイズがほぼ2倍になることに注意してください。
ClusterControlの場合、[ClusterControl]->[設定]->[しきい値]でディスクスペース使用率のしきい値を設定して、次のように警告と重要な通知を受け取ることができます。
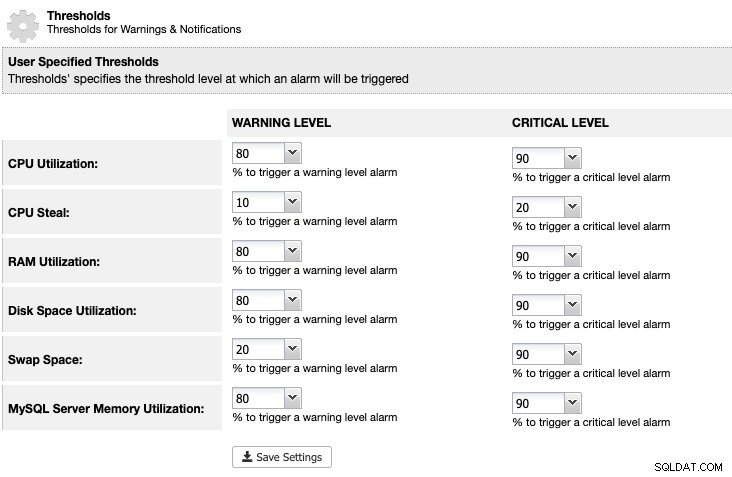
ClusterControlは、MariaDBデータの場所など、MariaDBサービスに関連するすべてのディスクスペースを監視しますディレクトリ、バイナリログディレクトリ、およびルートパーティション。しきい値に達した場合は、この記事で説明および説明されているように、PURGEBINARYLOGSコマンドを使用してバイナリログを手動でパージすることを検討してください。
ClusterControlは、データベースノードをサンプリングするための2つの監視オプション(エージェントレスまたはエージェントベース)を提供します。デフォルトはエージェントレスで、プルオンリーメカニズムでSSHを介してサンプリングが行われます。エージェントベースの監視では、Prometheusサーバーが実行されている必要があり、監視対象のすべてのノードが少なくとも3つのエクスポーターで構成されている必要があります。
- プロセスエクスポーター(ポート9011)
- ノード/システムメトリクスエクスポーター(ポート9100)
- MySQL / MariaDBエクスポーター(ポート9104)
エージェントベースの監視ダッシュボードを有効にするには、[ClusterControl]->[ダッシュボード]->[エージェントベースの監視を有効にする]に移動する必要があります。有効にすると、MariaDBレプリケーション用に構成された一連のダッシュボードが表示され、レプリケーション設定に関するより良い洞察が得られます。次のスクリーンショットは、マスターノードに表示される内容を示しています。
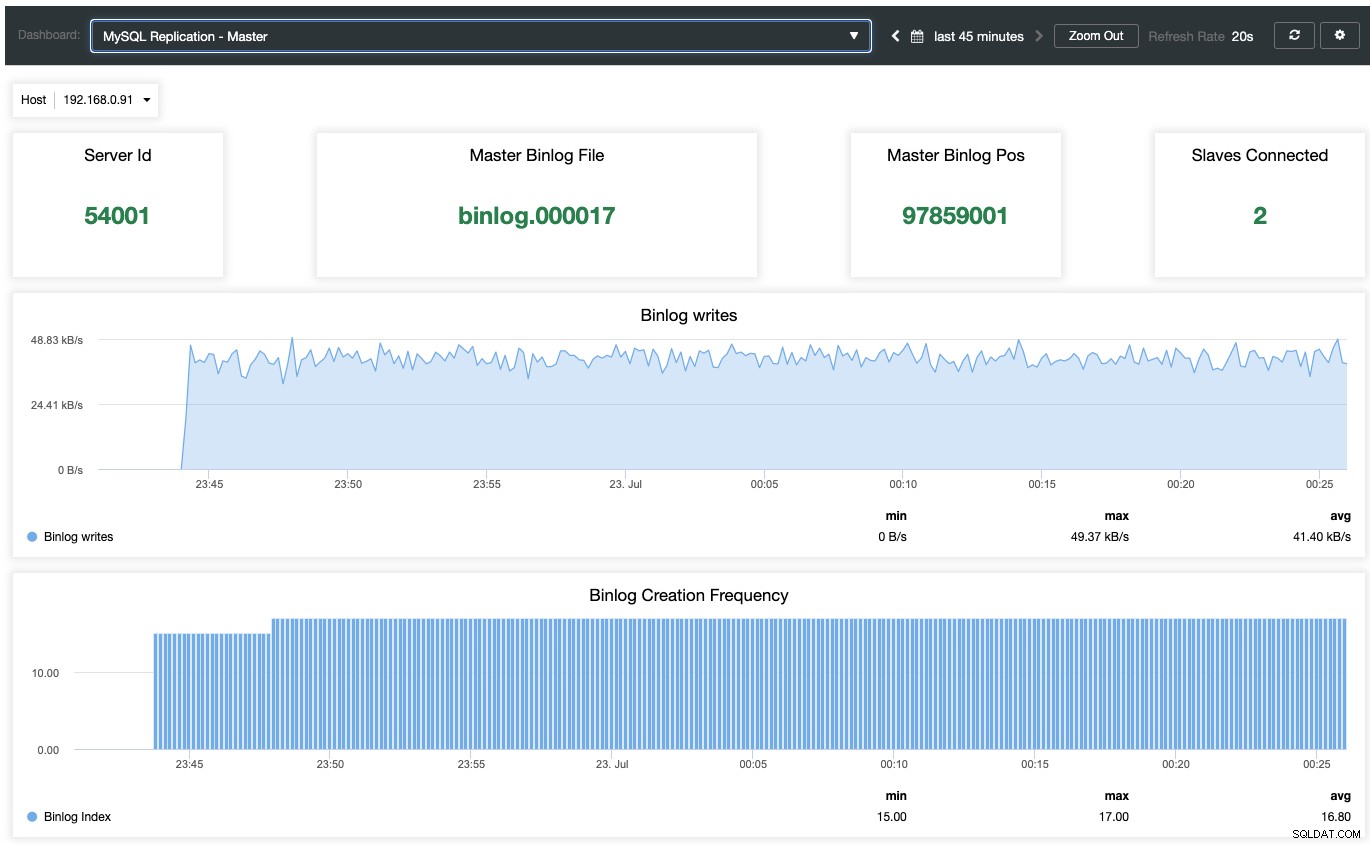
一般、キャッシュ、InnoDBメトリックなどのMariaDB標準監視ダッシュボードは別として、レプリケーションダッシュボードが表示されます。マスターノードの場合、マスターの状態、書き込みスループット、およびbinlogの作成頻度に関する多くの有用な情報を取得できます。
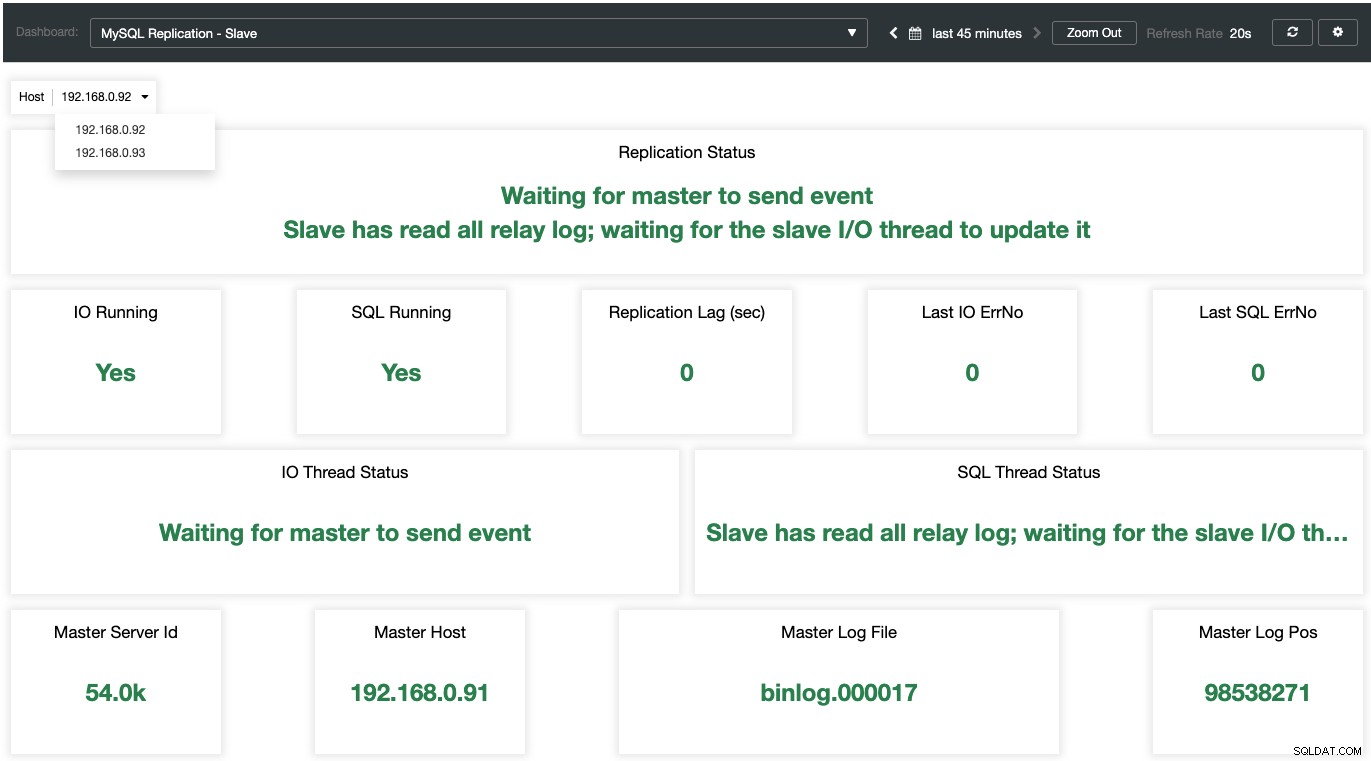
スレーブの場合、すべての重要な状態がサンプリングされ、次のスクリーンショットとして要約されます。すべてが緑色の場合、あなたは良い手にあります:
MariaDBエラーログを理解する
MariaDBは、重要なイベントをエラーログに記録します。これは、特にトポロジの変更前、変更中、変更後にサーバーで何が起こっていたかを理解するのに役立ちます。 ClusterControlは、すべてのデータベースノードからエラーログをプルすることにより、ClusterControl-> Logs->SystemLogsでエラーログの集中ビューを提供します。 「ログの更新」をクリックして、サーバーから最新のログをプルするジョブをトリガーします。
収集されたファイルは、ナビゲーションツリー構造とテキスト領域に表示され、読みやすくするために構文が強調表示されます。
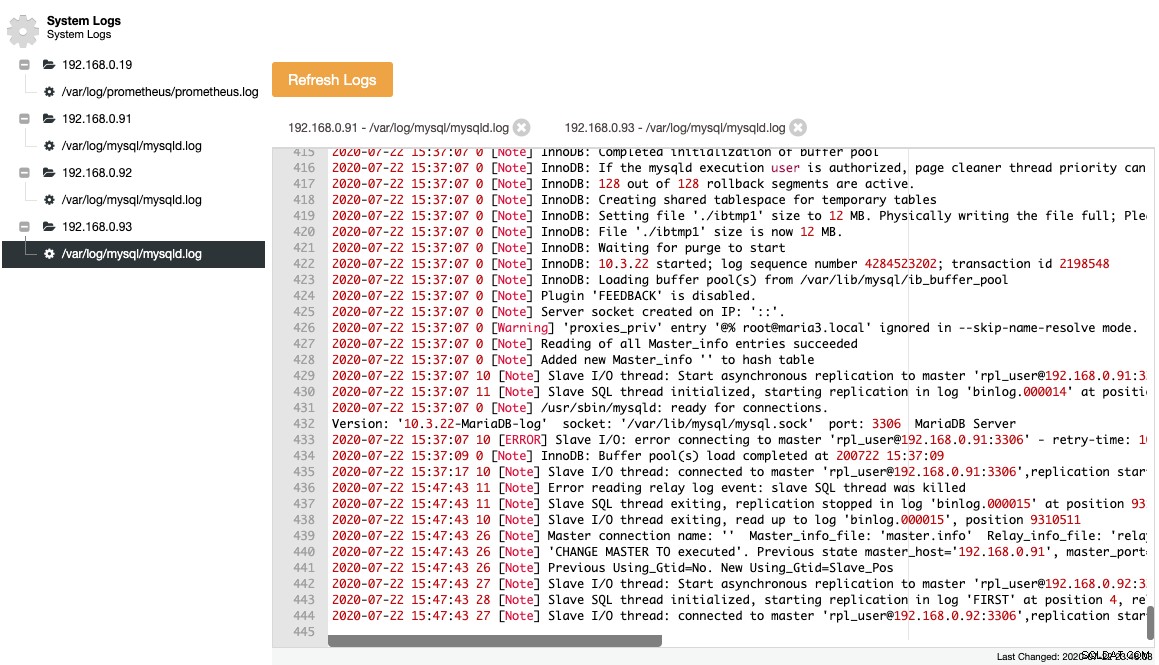
上のスクリーンショットから、イベントのシーケンスと、トポロジ変更イベント中にこのノードに何が起こったかを理解できます。上記のエラーログの最後の12行から、スレーブはマスターに接続するとエラーが発生し、最後のバイナリログファイルと位置が停止する前にログに記録されました。次に、「Previous Using_Gtid=No。NewUsing_Gtid=Slave_Pos」の行に示すように、GTID情報を使用して新しいCHANGE MASTERコマンドが実行され、レプリケーションが希望どおりに再開されます。
MariaDBアラートと通知
アラートと通知がないと、監視は不完全です。 ClusterControlによって生成されたすべてのイベントとアラームは、電子メールまたはその他のサポートされているサードパーティツールに送信できます。電子メール通知の場合、イベントのタイプをすぐに配信するか、無視するか、要約するかを構成できます(日次要約レポート):

すべての重大な重大度のイベントについて、すべてを「配信」に設定して、できるだけ早く通知を受け取るようにすることをお勧めします。 「ダイジェスト」を警告イベントに設定して、クラスターの状態と状態を十分に認識できるようにします。
ClusterControl->統合->サードパーティ通知の下の通知管理機能を使用して、好みのコミュニケーションおよびメッセージングツールをClusterControlと統合できます。 ClusterControlは、PagerDuty、VictorOps、OpsGenie、Slack、Telegram、ServiceNow、またはユーザーが登録したWebhookにアラームとイベントを送信できます。
次のスクリーンショットは、すべての重要なイベントがMariaDB10.3レプリケーションクラスター用に構成されたテレグラムチャネルにプッシュされることを示しています。

ClusterControlは、チャットボット統合もサポートしています。このブログ投稿「CCBotを使用したデータベースの自動化:ClusterControl Hubot統合」に示されているように、メッセージングツールからs9sクライアントを介してコントローラーサービスと対話できます。
ClusterControlは、データベースクラスター用のプロアクティブな監視ツールの完全なセットを提供します。ほとんどの監視機能はCommunityEditionで無料で利用できるため、ClusterControlを使用してMariaDBレプリケーション設定を監視してください。それらをお見逃しなく!