
今月のT-SQL火曜日に、Steve Jones(@ way0utwest)は、私たちの最高または最悪のトリガーエクスペリエンスについて話すように依頼しました。トリガーはしばしば眉をひそめ、恐れることさえありますが、次のようないくつかの有効なユースケースがあります。
- 監査(2016 SP1より前、この機能がすべてのエディションで無料になったとき)
- 制約で簡単に実装できず、アプリケーションコードやDMLクエリ自体に依存したくない場合の、ビジネスルールとデータの整合性の適用
- データの履歴バージョンの維持(変更データキャプチャ、変更追跡、および時間テーブルの前)
- 特定の変更に応じたキューアラートまたは非同期処理
- ビューの変更を許可する(INSTEAD OFトリガーを介して)
これは完全なリストではなく、トリガーがその時点で正しい答えであった、私が経験したいくつかのシナリオの簡単な要約です。
トリガーが必要な場合、私は常に、AFTERトリガーではなく、INSTEADOFトリガーの使用を検討するのが好きです。はい、それらはもう少し前もっての作業*ですが、いくつかの非常に重要な利点があります。理論的には、少なくとも、アクション(およびそのログの結果)の発生を防ぐ可能性は、すべてを発生させてから元に戻すよりもはるかに効率的であるように思われます。
*これは、トリガー内でDMLステートメントを再度コーディングする必要があるためです。これが、トリガーの前に呼び出されない理由です。一部のシステムは、最初に実行される真のBEFOREトリガーを実装しているため、ここでは区別が重要です。 SQL Serverでは、INSTEAD OFトリガーは、それを起動させたステートメントを効果的にキャンセルします。
アカウント名を格納するための単純なテーブルがあるとしましょう。この例では、2つのテーブルを作成するので、2つの異なるトリガーと、それらがクエリ期間とログ使用量に与える影響を比較できます。概念は、ビジネスルールがあるということです。アカウント名は「不正な」名前を表す別のテーブルに存在せず、トリガーを使用してこのルールを適用します。データベースは次のとおりです:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO そしてテーブル:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
そして最後に、トリガー。簡単にするために、挿入のみを扱います。大文字と小文字のどちらも後と代わりに、いずれかの名前がルールに違反している場合は、バッチ全体を中止します。
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO ここで、パフォーマンスをテストするために、各テーブルに100,000の名前を挿入し、予測可能な失敗率を10%にします。つまり、90,000は大丈夫な名前であり、他の10,000はテストに失敗し、バッチに応じてトリガーがロールバックするか、挿入されないようにします。
まず、各バッチの前にクリーンアップを行う必要があります:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
各バッチの重要な部分を開始する前に、トランザクションログの行をカウントし、サイズと空き領域を測定します。次に、カーソルを調べて100,000行をランダムな順序で処理し、各名前を適切なテーブルに挿入しようとします。完了したら、ログの行数とサイズを再度測定し、期間を確認します。
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; 結果(各バッチの5回の実行の平均):
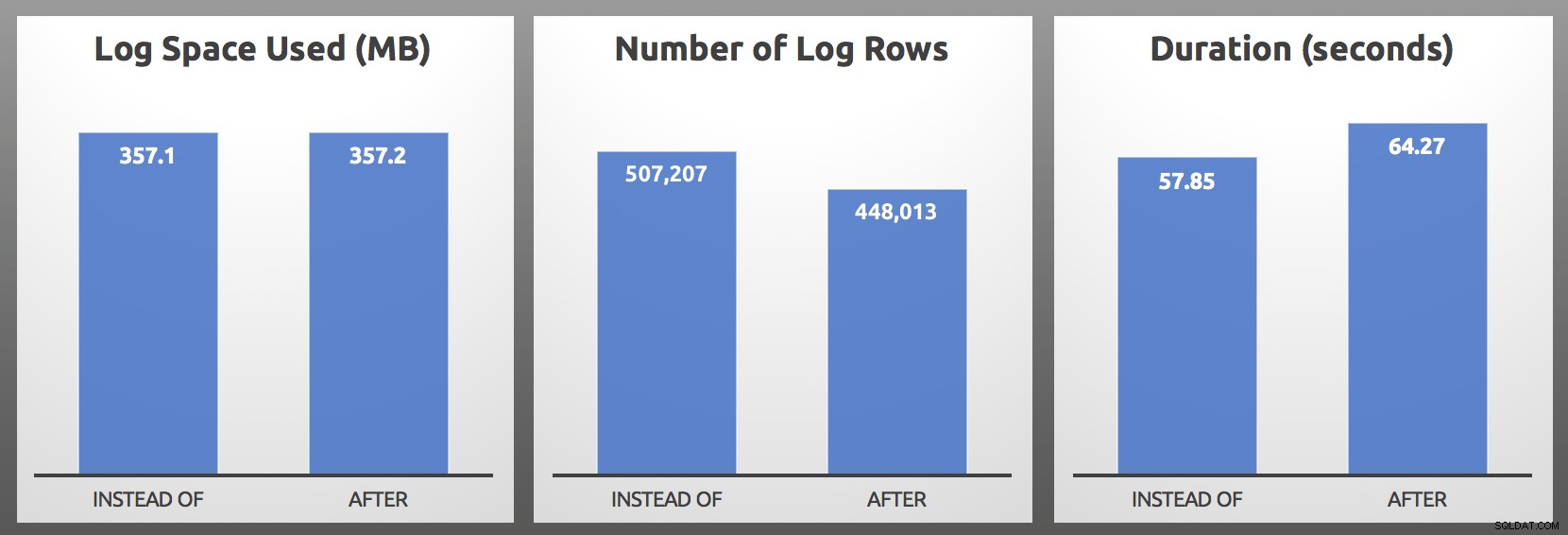 AFTER vs. INSTEAD OF:結果
AFTER vs. INSTEAD OF:結果
私のテストでは、ログの使用量はほぼ同じサイズで、INSTEAD OFトリガーによって生成されるログ行が10%以上増えました。各バッチの最後にいくつか掘り下げました:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
そして、ここに典型的な結果がありました(私は主要なデルタを強調しました):
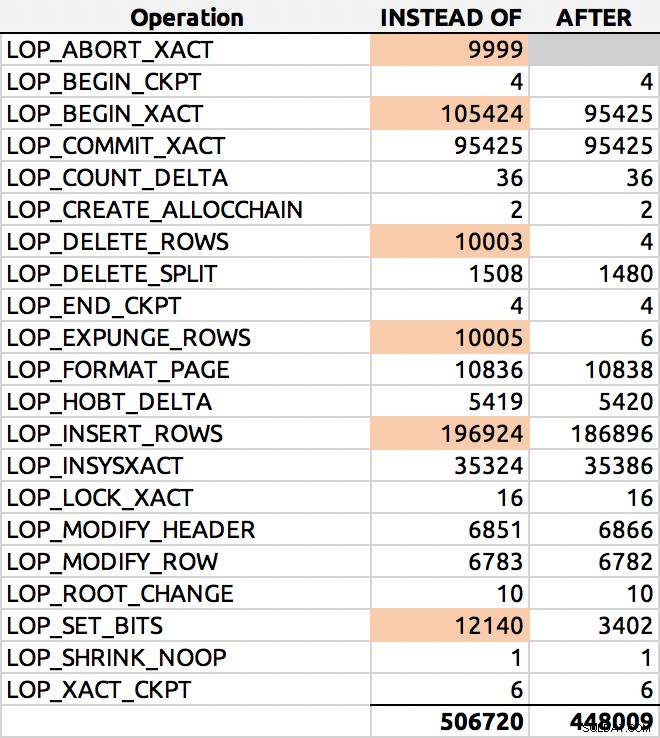
それについては、別の機会にさらに深く掘り下げます。
しかし、あなたがそれに真剣に取り組むとき…
…最も重要な指標は、ほとんどの場合、期間です。 、そして私の場合、INSTEAD OFトリガーは、すべての1つの直接テストで少なくとも5秒速く実行されました。これがすべておなじみのように聞こえる場合は、ええ、私は以前にそれについて話しましたが、当時、私はログ行でこれらの同じ症状を観察しませんでした。
これは正確なスキーマまたはワークロードではない可能性があり、ハードウェアが大きく異なる可能性があり、同時実行性が高く、失敗率がはるかに高い(または低い)可能性があることに注意してください。私のテストは、十分なメモリと非常に高速なPCIeSSDを備えた分離されたマシンで実行されました。ログが低速のドライブにある場合、ログの使用量の違いが他のメトリックを上回り、期間が大幅に変わる可能性があります。これらすべての要因(およびそれ以上!)が結果に影響を与える可能性があるため、環境でテストする必要があります。
ただし、重要なのは、INSTEADOFトリガーの方が適している可能性があるということです。さて、INSTEADOFDDLトリガーを取得できれば…