親/子の設計を引き続き保持しますか、それともSQL ServerのhierarchyIDなどの新しいものを試したいですか?そうですね、2008年からhierarchyIDがSQL Serverの一部になっているので、これは本当に新しいことです。もちろん、目新しさ自体は説得力のある議論ではありません。ただし、Microsoftがこの機能を追加して、複数のレベルとの1対多の関係をより適切に表現していることに注意してください。
通常の親子関係の代わりにhierarchyIDを使用することで、どのような違いがあり、どのようなメリットが得られるのか疑問に思われるかもしれません。このオプションを検討したことがない場合は、驚くかもしれません。
真実は、このオプションがリリースされて以来、私はこのオプションを検討しなかったということです。しかし、ついにそれをやったとき、私はそれが素晴らしい革新であることに気づきました。見栄えの良いコードですが、さらに多くのコードが含まれています。この記事では、これらすべての優れた機会について説明します。
ただし、SQL ServerのhierarchyIDを使用する際の特殊性について説明する前に、その意味と範囲を明確にしましょう。
SQL Server HierarchyIDとは何ですか?
SQL ServerのhierarchyIDは、最も一般的なタイプの階層データであるツリーを表すように設計された組み込みのデータ型です。ツリー内の各アイテムはノードと呼ばれます。表形式では、hierarchyIDデータ型の列を持つ行です。
通常、テーブルデザインを使用して階層を示します。 ID列はノードを表し、別の列は親を表します。 SQL Server HierarchyIDを使用すると、データ型がhierarchyIDの列が1つだけ必要になります。
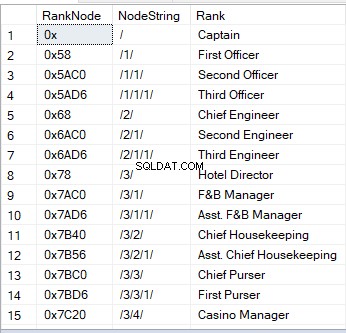
HierarchyID列を使用してテーブルをクエリすると、16進値が表示されます。これは、ノードの視覚的なイメージの1つです。別の方法は文字列です:
「/」はルートノードを表します。
「/1/」、「/ 2 /」、「/ 3 /」、または「/ n /」は子を表します–直系の子孫1からn;
「/1/1/」または「/1/2/」は「子供の子供–「孫」」です。 「/1/2/」のような文字列は、ルートの最初の子に2つの子があり、その子がルートの2つの孫であることを意味します。
外観のサンプルは次のとおりです:
他のデータ型とは異なり、hierarchyID列は組み込みのメソッドを利用できます。たとえば、 RankNodeという名前のhierarchyID列がある場合 、次の構文を使用できます:
RankNode。
SQLServerHierarchyIDメソッド
使用可能なメソッドの1つは、 IsDescendantOfです。 。現在のノードがhierarchyID値の子孫である場合は、1を返します。
以下のようなこのメソッドでコードを書くことができます:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1階層IDで使用されるその他のメソッドは次のとおりです。
- GetRoot –ツリーのルートを返す静的メソッド。
- GetDescendant –親の子ノードを返します。
- GetAncestor –指定されたノードのn番目の祖先を表すhierarchyIDを返します。
- GetLevel –ノードの深さを表す整数を返します。
- ToString –ノードの論理表現を含む文字列を返します。 ToString は、hierarchyIDから文字列型への変換が発生したときに暗黙的に呼び出されます。
- GetReparentedValue –ノードを古い親から新しい親に移動します。
- 解析– ToStringの反対として機能します 。 hierarchyIDの文字列ビューを変換します 値を16進数にします。
SQLServerHierarchyIDのインデックス作成戦略
階層IDを使用したテーブルのクエリが可能な限り高速に実行されるようにするには、列にインデックスを付ける必要があります。 2つのインデックス作成戦略があります:
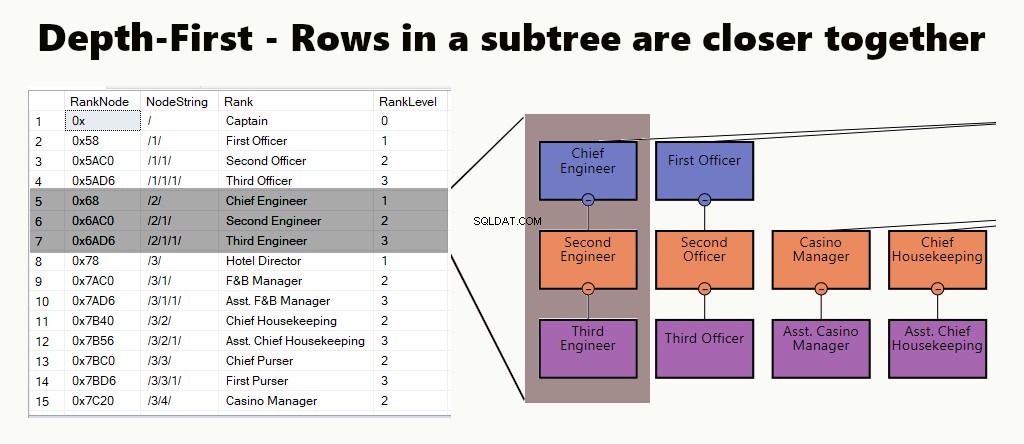
深さ優先
深さ優先インデックスでは、サブツリーの行が互いに近くなります。これは、部門、そのサブユニット、および従業員を見つけるなどのクエリに適しています。もう1つの例は、マネージャーとその従業員がより近くに保管されていることです。
テーブルでは、ノードのクラスター化インデックスを作成することにより、深さ優先インデックスを実装できます。さらに、そのように例の1つを実行します。
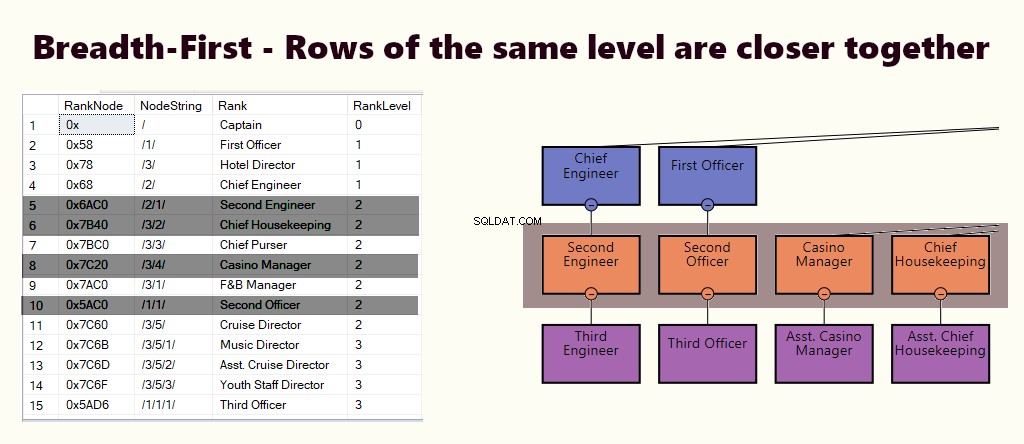
幅優先
幅優先インデックスでは、同じレベルの行が互いに接近しています。これは、マネージャーの直属の部下全員を見つけるなどのクエリに適しています。ほとんどのクエリがこれに類似している場合は、(1)レベルと(2)ノードに基づいてクラスター化されたインデックスを作成します。
深さ優先、幅優先、またはその両方が必要かどうかは、要件によって異なります。クエリタイプの重要性とテーブルで実行するDMLステートメントのバランスをとる必要があります。
SQLServerHierarchyIDの制限
残念ながら、hierarchyIDを使用してもすべての問題を解決できるわけではありません:
- SQL Serverは、親の子が何であるかを推測できません。テーブルでツリーを定義する必要があります。
- 一意性制約を使用しない場合、生成されるhierarchyID値は一意ではありません。この問題の処理は開発者の責任です。
- 親ノードと子ノードの関係は、外部キー関係のように強制されません。したがって、ノードを削除する前に、存在する子孫を照会してください。
階層の視覚化
先に進む前に、もう1つ質問を検討してください。ノード文字列を含む結果セットを見ると、階層が視覚的にわかりにくいと思いますか?
私にとって、それは私が若くならないので大きなイエスです。
このため、データベーステーブルとともにAkvelonのPowerBIと階層図を使用します。それらは、組織図で階層を表示するのに役立ちます。仕事が楽になることを願っています。
それでは、ビジネスに取り掛かりましょう。
SQLServerHierarchyIDの使用
HierarchyIDは、次のビジネスシナリオで使用できます。
- 組織構造
- フォルダ、サブフォルダ、およびファイル
- プロジェクトのタスクとサブタスク
- ウェブサイトのページとサブページ
- 国、地域、都市の地理データ
ビジネスシナリオが上記と類似していて、階層セクション全体でクエリを実行することはめったにない場合でも、hierarchyIDは必要ありません。
たとえば、組織は従業員の給与を処理します。誰かの給与を処理するためにサブツリーにアクセスする必要がありますか?全くない。ただし、マルチ商法で人のコミッションを処理する場合は、異なる場合があります。
この投稿では、クルーズ船の組織構造と指揮系統の一部を使用します。構造はここからの組織図から適応されました。下の図4でそれを見てください:

これで、問題の階層を視覚化できます。この投稿全体で以下の表を使用します:
- 船舶 –はクルーズ船のリストを表すテーブルです。
- ランク –は乗組員のランクの表です。そこで、hierarchyIDを使用して階層を確立します。
- 乗組員 –は各船の乗組員とそのランクのリストです。
各ケースのテーブル構造は次のとおりです。
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOSQLServerHierarchyIDを使用したテーブルデータの挿入
階層IDを完全に使用するための最初のタスクは、階層IDを使用してテーブルにレコードを追加することです。 桁。それを行うには2つの方法があります。
文字列の使用
階層IDを使用してデータを挿入する最も簡単な方法は、文字列を使用することです。これが実際に動作することを確認するために、いくつかのレコードをランクに追加しましょう。 テーブル。
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)上記のコードは、ランクテーブルに20レコードを追加します。
ご覧のとおり、ツリー構造は INSERTで定義されています。 上記のステートメント。文字列を使用すると簡単に識別できます。さらに、SQLServerはそれを対応する16進値に変換します。
Max()、GetAncestor()、およびGetDescendant()の使用
文字列の使用は、初期データを入力するタスクに適しています。長期的には、文字列を提供せずに挿入を処理するコードが必要です。
このタスクを実行するには、親または祖先が使用する最後のノードを取得します。これは、関数 MAX()を使用して実現します。 およびGetAncestor() 。以下のサンプルコードを参照してください:
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())上記のコードから得られたポイントは次のとおりです。
- 最初に、最後のノードとすぐ上のノードの変数が必要です。
- 最後のノードはMAX()を使用して取得できます RankNodeに対して 指定された親または直属の上司。この例では、ノード値が0x7AD6のアシスタントF&Bマネージャーです。
- 次に、重複する子が表示されないようにするには、 @ ImmediateSuperior.GetDescendant(@MaxNode、NULL)を使用します。 。 @MaxNodeの値 最後の子です。 NULLでない場合 、 GetDescendant() 次に可能なノード値を返します。
- 最後に、 GetLevel() 作成された新しいノードのレベルを返します。
データのクエリ
テーブルにレコードを追加したら、クエリを実行します。データをクエリする2つの方法が利用可能です:
直接の子孫のクエリ
マネージャーに直接報告する従業員を探すときは、次の2つのことを知っておく必要があります。
- マネージャーまたは親のノード値
- マネージャーの下の従業員のレベル
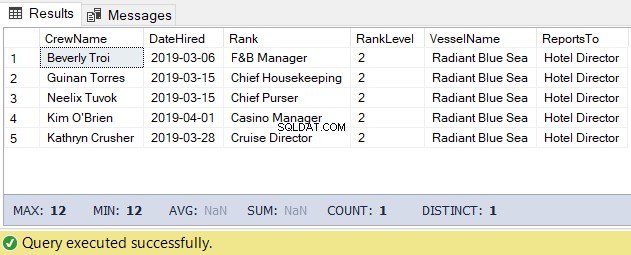
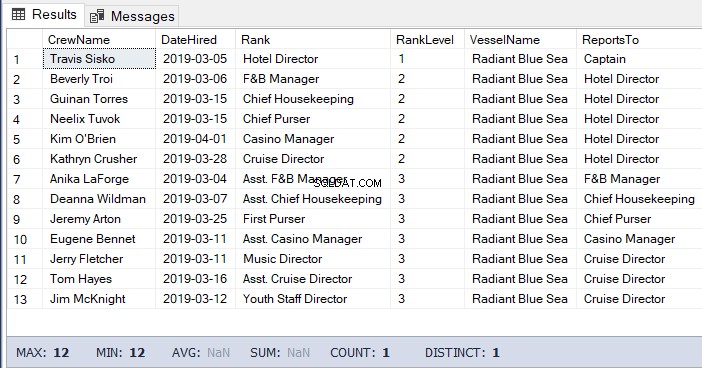
このタスクでは、以下のコードを使用できます。出力は、ホテルディレクターの下の乗組員のリストです。
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel Director上記のコードの結果は、図5のようになります。
サブツリーのクエリ
場合によっては、子と子の子を一番下までリストする必要もあります。これを行うには、親のhierarchyIDが必要です。
クエリは前のコードと似ていますが、レベルを取得する必要はありません。コード例を参照してください:
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1上記のコードの結果:
SQLServerHierarchyIDを使用したノードの移動
階層データを使用する別の標準的な操作は、子またはサブツリー全体を別の親に移動することです。ただし、先に進む前に、潜在的な問題が1つあることに注意してください。
潜在的な問題
- まず、ノードの移動にはI/Oが含まれます。階層IDまたは通常の親/子を使用する場合、ノードを移動する頻度が決定要因になる可能性があります。
- 次に、親/子デザインでノードを移動すると、1行が更新されます。同時に、hierarchyIDを持つノードを移動すると、1つ以上の行が更新されます。影響を受ける行の数は、階層レベルの深さによって異なります。重大なパフォーマンスの問題になる可能性があります。
ソリューション
この問題はデータベース設計で処理できます。
ここで使用したデザインについて考えてみましょう。
乗組員で階層を定義する代わりに 表では、ランクで定義しました テーブル。このアプローチは、従業員とは異なります。 AdventureWorksのテーブル サンプルデータベースであり、次の利点があります。
- 乗組員は船内の階級よりも頻繁に移動します。この設計により、階層内のノードの移動が減少します。その結果、上記で定義した問題を最小限に抑えることができます。
- 乗組員で複数の階層を定義する 2隻の船には2人の船長が必要なため、テーブルはより複雑です。結果は2つのルートノードです。
- 対応する乗組員と一緒にすべてのランクを表示する必要がある場合は、LEFTJOINを使用できます。 そのランクに誰も搭乗していない場合は、そのポジションの空のスロットが表示されます。
それでは、このセクションの目的に移りましょう。間違った親の下に子ノードを追加します。
これから行うことを視覚化するために、次のような階層を想像してください。黄色のノードに注意してください。

子のないノードを移動する
子ノードを移動するには、次のものが必要です。
- 移動する子ノードのhierarchyIDを定義します。
- 古い親のhierarchyIDを定義します。
- 新しい親のhierarchyIDを定義します。
- UPDATEを使用する GetReparentedValue()を使用 ノードを物理的に移動します。
子のないノードを移動することから始めます。以下の例では、CruiseStaffをCruiseDirectorの下からAsstの下に移動します。クルーズディレクター。
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
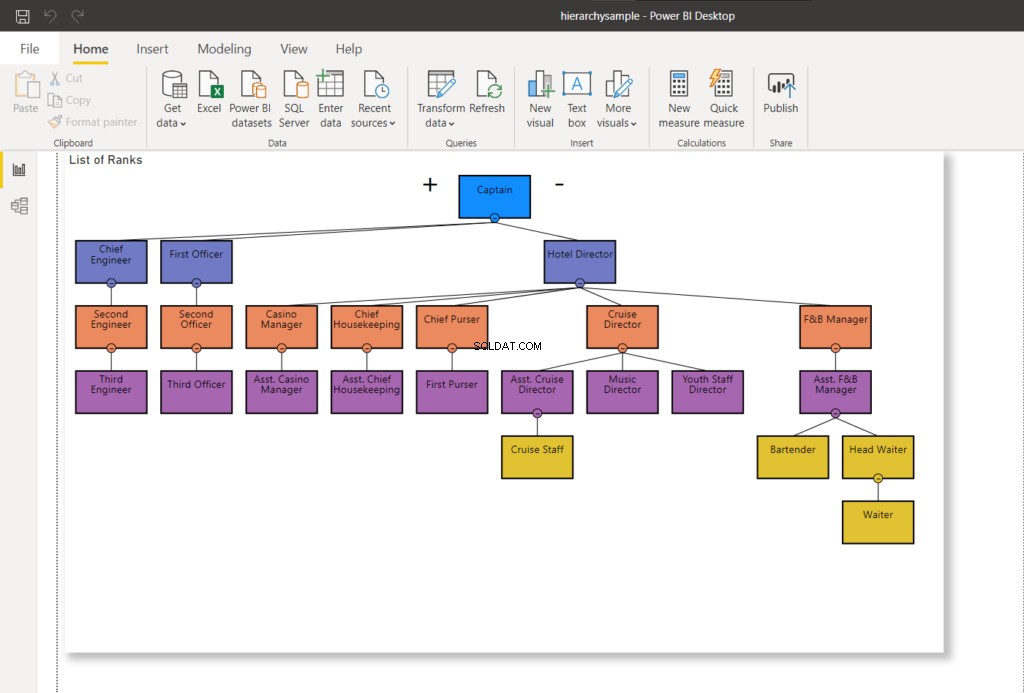
WHERE RankNode = @NodeToMoveノードが更新されると、新しい16進値がノードに使用されます。 SQLServerへのPowerBI接続を更新すると、階層チャートが次のように変更されます。
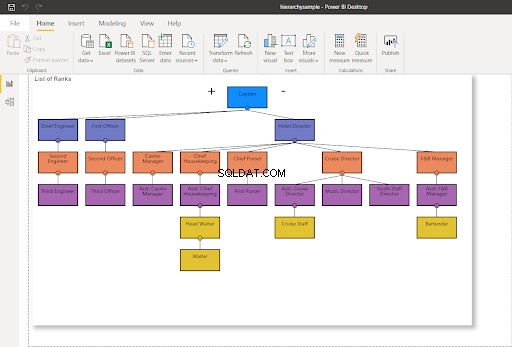
図8では、CruiseスタッフはCruise Directorに報告しなくなり、AssistantCruiseDirectorに報告するように変更されました。上記の図7と比較してください。
それでは、次の段階に進み、ヘッドウェイターをアシスタントF&Bマネージャーに移動しましょう。
子を持つノードを移動する
この部分には課題があります。
重要なのは、前のコードは子が1つでもあるノードでは機能しないということです。ノードを移動するには、1つ以上の子ノードを更新する必要があることを覚えています。
さらに、それだけではありません。新しい親に既存の子がある場合、重複するノード値にぶつかる可能性があります。
この例では、その問題に直面する必要があります:Asst。 F&BManagerにはBartender子ノードがあります。
準備?コードは次のとおりです:
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;上記のコード例では、最後のレベルでノードを子に転送する必要があるため、反復が開始されます。
実行後、ランク テーブルが更新されます。また、変更を視覚的に確認したい場合は、PowerBIレポートを更新してください。以下のような変更が表示されます:
SQLServerHierarchyIDと親/子を使用する利点
誰かに機能を使用するように説得するには、利点を知る必要があります。
したがって、このセクションでは、最初から同じテーブルを使用してステートメントを比較します。 1つはhierarchyIDを使用し、もう1つは親/子アプローチを使用します。結果セットは、両方のアプローチで同じになります。この演習では、図6の演習として期待しています。 上記。
要件が正確になったので、メリットを徹底的に調べてみましょう。
コーディングが簡単
以下のコードを参照してください:
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1このサンプルには、hierarchyID値のみが必要です。クエリを変更せずに、値を自由に変更できます。
次に、同じ結果セットを生成する親/子アプローチのステートメントを比較します。
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)どう思いますか?コードサンプルは、1つのポイントを除いてほとんど同じです。
場所 2番目のクエリの句は、別のサブツリーが必要な場合に柔軟に適応できません。
2番目のクエリを十分に一般的にすると、コードが長くなります。 Yikes!
より高速な実行
Microsoftによると、「サブツリークエリはhierarchyIDを使用すると、親/子と比較して大幅に高速になります」。それが本当かどうか見てみましょう。
以前と同じクエリを使用します。パフォーマンスに使用する重要な指標の1つは、論理読み取りです。 SET STATISTICS IOから 。これは、SQLServerが必要な結果セットを取得するために必要な8KBページの数を示します。値が大きいほど、SQL Serverがアクセスして読み取るページ数が多くなり、クエリの実行速度が低下します。 SET STATISTICS IO ONを実行します 上記の2つのクエリを再実行します。論理読み取りの低い方の値が勝者になります。
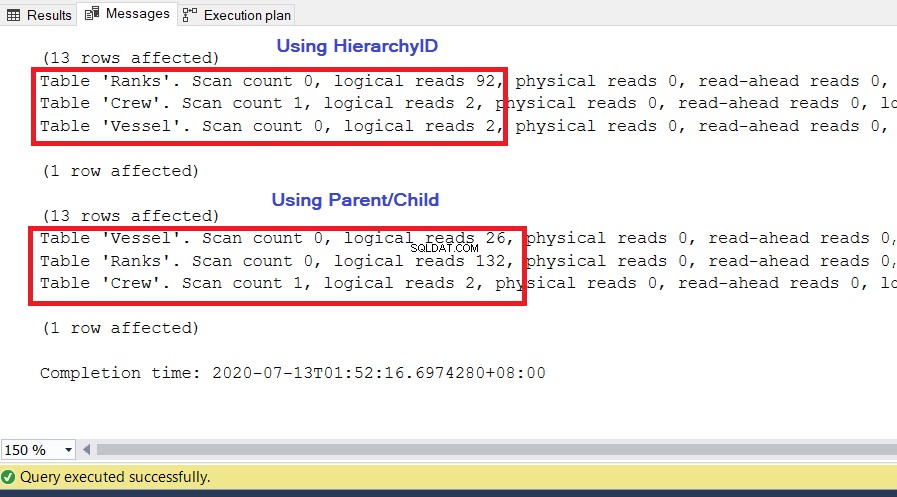
分析
図10に示すように、hierarchyIDを持つクエリのI / O統計は、対応する親/子よりも論理読み取りが低くなっています。この結果の次の点に注意してください。
- 船舶 テーブルは3つのテーブルの中で最も注目に値します。 HierarchyIDを使用すると、SQL Serverがキャッシュ(メモリ)から読み取るのに必要なページは2 * 8KB=16KBのみです。一方、親/子を使用するには、26 * 8KB =208KBのページが必要です。これは、hierarchyIDを使用する場合よりも大幅に高くなります。
- ランク 階層の定義を含むテーブルには、92 * 8KB=736KBが必要です。一方、親/子を使用するには、132 * 8KB=1056KBが必要です。
- 乗組員 テーブルには2*8KB =16KBが必要です。これは、両方のアプローチで同じです。
キロバイトのページは今のところ小さな値かもしれませんが、レコードは数個しかありません。ただし、どのサーバーでもクエリにどの程度の負担がかかるかがわかります。パフォーマンスを向上させるために、次の1つ以上のアクションを実行できます。
- 適切なインデックスを追加する
- クエリを再構築する
- 統計の更新
上記を実行し、レコードを追加せずに論理読み取りが減少した場合、パフォーマンスは向上します。論理読み取りをhierarchyIDを使用する読み取りよりも低くする限り、それは朗報です。
しかし、なぜ経過時間ではなく論理読み取りを参照するのですか?
SET STATISTICS TIME ON を使用して、両方のクエリの経過時間を確認します 小さなデータセットのミリ秒の差が少ないことがわかります。また、開発サーバーのハードウェア構成、SQL Server設定、およびワークロードが異なる場合があります。ミリ秒未満の経過時間は、クエリが期待した速度で実行されているかどうかにかかわらず、だまされる可能性があります。
さらに掘り下げる
統計IOをオンに設定 「舞台裏」で起こっていることを明らかにするものではありません。このセクションでは、実行プランを確認することで、SQLServerがこれらの数値で到達する理由を確認します。
最初のクエリの実行プランから始めましょう。
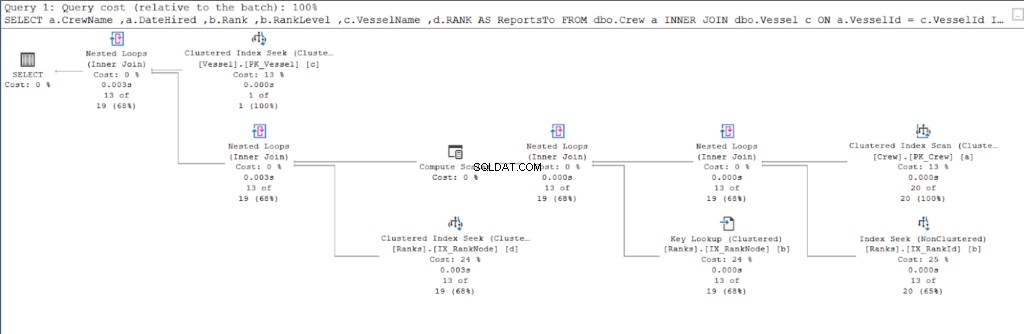
次に、2番目のクエリの実行プランを確認します。
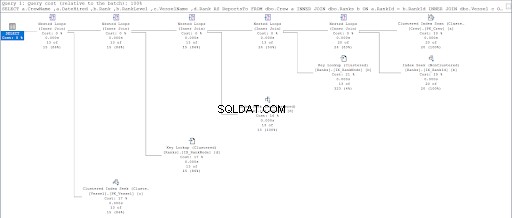
図11と図12を比較すると、親子アプローチを使用する場合、SQLServerが結果セットを生成するために追加の作業が必要であることがわかります。 場所 条項はこの合併症の原因です。
ただし、テーブルの設計に問題がある可能性もあります。両方のアプローチに同じテーブルを使用しました:ランク テーブル。そこで、ランクを複製しようとしました テーブルですが、各手順に適した異なるクラスター化インデックスを利用します。
その結果、hierarchyIDを使用すると、対応する親/子と比較して論理的な読み取りが少なくなります。最後に、Microsoftがそれを正しく主張していることを証明しました。
結論
ここで、hierarchyIDの中心的なahaモーメントは次のとおりです。
- HierarchyIDは、最も一般的なタイプの階層データであるツリーのより最適化された表現のために設計された組み込みデータタイプです。
- ツリー内の各アイテムはノードであり、hierarchyID値は16進形式または文字列形式にすることができます。
- HierarchyIDは、組織構造、プロジェクトタスク、地理データなどのデータに適用できます。
- GetAncestor など、階層データをトラバースおよび操作するためのメソッドがあります ()、 GetDescendant ()。 GetLevel ()、 GetReparentedValue ()など。
- 階層データをクエリする従来の方法は、ノードの直接の子孫を取得するか、ノードの下のサブツリーを取得することです。
- サブツリーをクエリするためのhierarchyIDの使用は、コーディングが簡単なだけではありません。また、親/子よりもパフォーマンスが優れています。
親子のデザインは決して悪くはありません、そしてこの投稿はそれを減らすことではありません。ただし、オプションを拡張して新しいアイデアを導入することは、開発者にとって常に大きなメリットです。
ここで提供した例を自分で試すことができます。効果を受け取り、階層を含む次のプロジェクトにどのように適用できるかを確認してください。
投稿とそのアイデアが気に入った場合は、好みのソーシャルメディアの共有ボタンをクリックして情報を広めることができます。