これは、SQLServerセマンティック検索専用の資料の2番目の部分です。 。前回の記事では、基本について説明しました。次に、Windowsファイルシステムに保存されているドキュメントの比較と、SQLServerのセマンティック検索との比較分析に焦点を当てます。
名前ベースのドキュメントの比較分析の実行
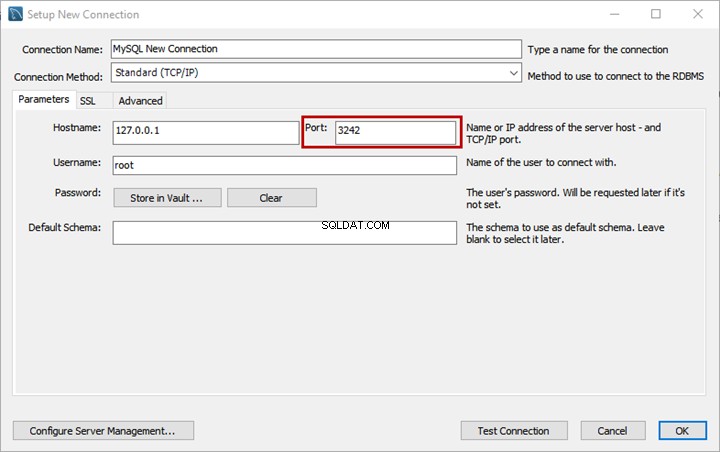
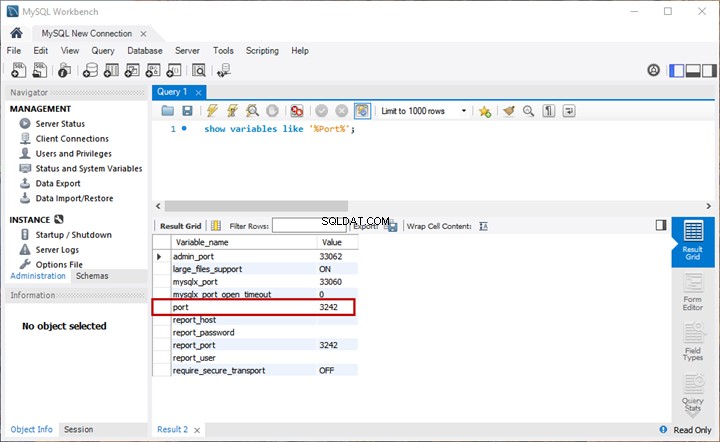
標準の命名に基づいて、ドキュメントの比較分析を実行します。この時点で、 EmployeesFilestreamSample にクエリを実行して、簡単なチェックを行いましょう。 以前に設定したデータベース:
-- View stored documents managed by File Table to check
SELECT stream_id
,[name]
,file_type
,creation_time
FROM EmployeesFilestreamSample.dbo.EmployeesDocumentStore
結果には、保存されているドキュメントが表示される必要があります:
セマンティック検索チェックリスト
すでにデータベースと、ファイルテーブルを使用したファイルシステム上の2つのサンプルMS Wordドキュメントがあります(必要に応じて、パート1を参照して知識を更新してください)。ただし、それはありません セマンティック検索シナリオのドキュメントを自動的に認定します。
セマンティック検索は、次のいずれかの方法で有効にできます。
- すでに全文検索を設定している場合 、単一のステップでセマンティック検索を有効にできます。
- セマンティック検索を直接設定できますが、全文検索も設定する必要があります。
セマンティック検索セットアップ前の全文検索テスト
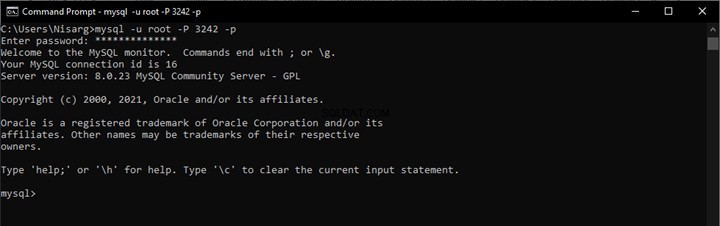
フルテキストクエリが機能する場合は、セマンティック検索を有効にするだけで済みます。これを確認するには、目的のテーブルに対してフルテキストクエリを実行します。
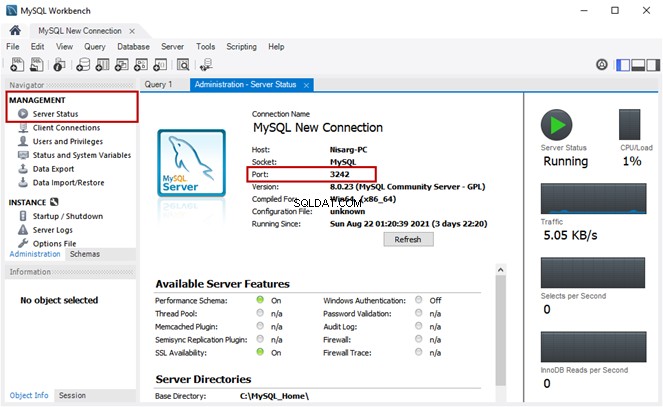
-- Searching word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
出力:
したがって、最初に全文検索の要件を満たし、次にセマンティック検索を有効にする必要があります。
使用のためのセマンティック検索の有効化
セマンティック検索を使用するには、次のポイントのうち少なくとも2つが必要です。
- 一意のインデックス
- フルテキストカタログ
- フルテキストインデックス
次のT-SQLスクリプトを実行して、一意のインデックスを作成します。
-- Create unique index required for Semantic Search
CREATE UNIQUE INDEX UQ_Stream_Id
ON EmployeesDocumentStore(stream_id)
GO
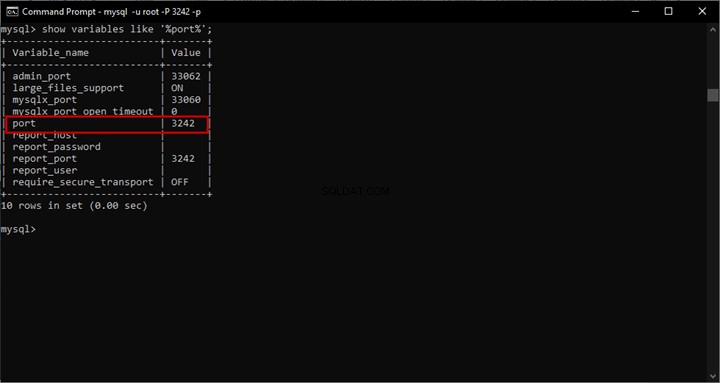
新しく作成された一意のインデックスに基づいてフルテキストカタログを作成します。次に、以下に示すようにフルテキストインデックスを作成します。
-- Getting Semantic Search ready to be used with File Table
CREATE FULLTEXT CATALOG EmployeesFileTableCatalog WITH ACCENT_SENSITIVITY = ON;
CREATE FULLTEXT INDEX ON EmployeesDocumentStore
(
name LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_type LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_stream TYPE COLUMN file_type LANGUAGE 1033 STATISTICAL_SEMANTICS
)
KEY INDEX UQ_Stream_Id
ON EmployeesFileTableCatalog WITH CHANGE_TRACKING AUTO, STOPLIST=SYSTEM;
結果:
セマンティック検索設定後の全文検索テスト
同じフルテキストクエリを実行して、 Employeeという単語を検索してみましょう。 保存されたドキュメント内:
-- Searching (after Semantic Search setup) word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
出力:
セマンティック検索の準備をしている間、フルテキストクエリがファイルテーブルに対して機能することは問題ありません。
MSWordドキュメントを追加する
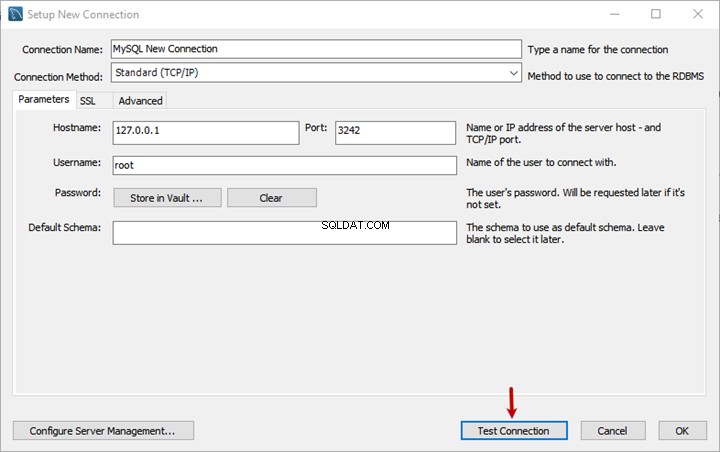
EmployeesDocumentStoreに移動します [ファイルテーブル]をクリックし、[ファイルテーブルディレクトリの探索]をクリックします :
Sadaf Contract Employeeという新しいドキュメントを作成して保存します :
次に、新しく作成したドキュメントに次のテキストを追加します。最初の行はドキュメントのタイトルである必要があります!
Sadaf契約社員(役職)
Sadafは、連絡先ベースの作業を行う非常に効率的なビジネスアナリストです。彼女はビジネス要件を完全に処理し、開発者が取り組むための技術仕様に変換することができます。彼女は非常に経験豊富なビジネスアナリストです。
Mike Permanent Employeeという別のドキュメントを追加します :
次のテキストでドキュメントを更新します:
Mike Permanent Employee(ドキュメントのタイトル)
Mikeは、Web開発を専門とする新しいプログラマーです。彼は素早い学習者であり、どんなプロジェクトにも喜んで取り組んでいます。彼は強力な問題解決スキルを持っていますが、ビジネス知識はあまりありません。問題を理解し、要件を満たすには、他の開発者やビジネスアナリストの支援が必要です。
彼は小さなプロジェクトに取り組むときは上手ですが、大きなプロジェクトや複雑なプロジェクトを与えられると苦労します。
ファイルテーブルによって管理されるWindowsファイルシステムに4つのドキュメントが保存されています。これらのドキュメントは、セマンティック検索(全文検索を含む)で使用する必要があります。
重要:サンプルとして4つのMS Wordドキュメントをフォルダーに保存しましたが、SQLServerデータベースによって数百のドキュメントが維持されている場合にセマンティック検索を使用することの重要性を想像できます。これらのドキュメントをクエリする必要があります。貴重な情報を見つけるために。
ドキュメントの標準的な命名は、このアプローチの実装を成功させるために非常に重要です。
ドキュメントの簡単なカウント
これらのドキュメントを比較し、セマンティック検索を使用して、標準の名前に基づいて相違点と類似点を定義できます。たとえば、簡単なクエリで、Windowsフォルダに保存されているドキュメントの総数を知ることができます。
-- Getting total number of stored documents
SELECT COUNT(*) AS Total_Documents FROM EmployeesDocumentStore

正社員と契約ベースの従業員の比較
今回は、セマンティック検索を使用して、組織内の正社員と契約ベースの従業員の数を比較しています。
-- Creating a summary table variable
DECLARE @Documents TABLE
(DocumentType VARCHAR(100),
DocumentsCount INT)
INSERT INTO @Documents -- Storing total number of stored documents into summary table
SELECT 'Total Documents',COUNT(*) AS Total_Documents FROM EmployeesDocumentStore
INSERT INTO @Documents -- Storing total number of permanent employees documents stored into summary table
SELECT 'Total Permanent Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Permanent'
INSERT INTO @Documents --Storing total number of permanent employees documents stored
SELECT 'Total Contract Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Contract'
SELECT DocumentType,DocumentsCount FROM @Documents
出力:
単純な(ドキュメント名ベースの)セマンティック検索クエリを実行して、キーフレーズを表示してみましょう。 とその相対スコア ドキュメントごとに:
-- Getting keyphrase and relative score for all the documents
SELECT * FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
ORDER BY score
出力:
ドキュメント名に詳細を追加しましょう。名前を次のように変更します:
- Asif正社員–経験豊富なプロジェクトマネージャー
- Mike Permanent Employee –フレッシュプログラマー
- Peter Permanent Employee –フレッシュプロジェクトマネージャー
- Sadaf契約社員–経験豊富なビジネスアナリスト
新入社員の検索(ドキュメント)
役職に基づいて新入社員に関連するドキュメントを検索します(標準の名前付け):
-- Getting document name-based scoring to find fresh employees for a new project
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName
,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) where keyphrase='fresh'
order by DocumentName desc
結果:
経験豊富な従業員の検索(ドキュメント)
今後の複雑なプロジェクトについて、経験豊富な従業員のすべての詳細をすばやく確認したいとします。次のセマンティック検索クエリを使用します:
-- Getting document name-based scoring to find all experienced employees
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='experienced' order by DocumentName
出力:
すべてのプロジェクトマネージャー(ドキュメント)の検索
最後に、すべてのプロジェクトマネージャーのドキュメントをすばやく確認する場合は、次のセマンティック検索クエリが必要です。
-- Getting document name-based scoring to find all project managers
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='Project'
結果:
ウォークスルーを実装すると、ファイルテーブルを使用して、MSWordドキュメントなどの非構造化データをWindowsフォルダに正常に保存できます。
名前ベースの分析レビュー
これまで、セマンティック検索を使用してファイルテーブルに保存されたドキュメントの名前ベースの分析を実行する方法を学習しました。ただし、次の条件を満たす必要があります。
- 標準の名前を付ける必要があります。
- 名前は分析に必要な情報を提供する必要があります。
これらの条件は、名前ベースの分析の制限でもあります。しかし、これは私たちがそれで多くを行うことができないという意味ではありません。
名前/列ベースのセマンティック検索アプローチに引き続き焦点を当てています。
ドキュメントの名前列を表示する
名前を含むDocumentsテーブルのメイン列のいくつかを見てみましょう。 列:
USE EmployeesFilestreamSample
-- View name column with the file types of the stored documents in File Table for analysis
SELECT name,file_type
FROM dbo.EmployeesDocumentStore
出力:
SEMANTICKEYPHRASETABLE機能を理解する
SQL Serverは、 SEMANTICKEYPHRASETABLEを提供します セマンティック検索でドキュメントを分析する機能。構文は次のとおりです。
SEMANTICKEYPHRASETABLE
(
table,
{ column | (column_list) | * }
[ , source_key ]
)
この関数は、ドキュメントに関連付けられたキーフレーズを提供します。それらを使用して、名前やコンテンツに基づいてドキュメントを分析できます。この場合、この機能を使用するだけでなく、適切に使用する方法を理解する必要があります。
この関数には次のデータが必要です:
- セマンティック検索分析に使用されるファイルテーブルの名前。
- セマンティック検索分析に使用される列の名前。
次に、次のデータを返します。
- Column_id –列番号
- Document_Key –ファイルテーブルドキュメントのデフォルトの主キー
- キーフレーズ –は、セマンティック検索が分析のためにインデックスを作成することを決定したフレーズです。キーフレーズを表示する列に応じて、ドキュメントの名前とコンテンツの両方に適用されます
- スコア –ドキュメントがそのキーフレーズによって最もよく認識される方法など、ドキュメントに関連付けられたキーフレーズの強度を決定します。スコアは0.0から1.0の間です。
SEMANTICKEYPHRASETABLE関数を使用したすべてのドキュメントの分析
SEMANTICKEYPHRASETABLEを使用します ファイルテーブルによって管理されるWindowsフォルダに保存されているドキュメントの名前ベースの分析のための機能。
次のT-SQLスクリプトを実行します。
USE EmployeesFilestreamSample
-- View key phrases and their score for the name column
SELECT * FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name)
order by score desc
出力:
すべてのドキュメントに添付されているすべてのキーフレーズとそのスコアのリストがあります。 column_id 3 一番上の行は名前です 桁。さらに、この列(名前)を指定して関数を呼び出しました:
document_keyを見つけることができます : 0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260次のスクリプトを実行しています(ただし、このドキュメントの名前にキーフレーズ sadafが含まれていることは明らかです。 ):
USE EmployeesFilestreamSample
-- Finding document name by its key (path_locator)
SELECT name,path_locator FROM dbo.EmployeesDocumentStore
WHERE path_locator=0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260
出力:
キーフレーズ サダフ 最高のスコアが与えられました : 1.0 。
したがって、セマンティック検索分析に十分な情報を含む標準のドキュメント命名の場合、キーフレーズ sadaf その特定のドキュメント名に最適です。
SEMANTICKEYPHRASETABLE関数を使用した特定のドキュメントの分析
名前に基づいてセマンティック検索分析を絞り込むことができます 桁。たとえば、name列を表示するだけで済みます- 特定のドキュメントのベースのキーフレーズ。 SEMANTICKEYPHRASETABLEでドキュメントキーを指定できます 機能。
まず、すべてのキーフレーズを表示するドキュメントのドキュメントキーを特定します。次のT-SQLスクリプトを実行します。
-- Find document_key of the document where the name contains Peter
SELECT name,path_locator as document_key From EmployeesDocumentStore
WHERE name like '%Peter%'
ドキュメントキーは0xFF6A92952500812FF013376870181CFA6D7C070220
それでは、ドキュメント名を定義できるすべてのキーフレーズに関するこのドキュメントを見てみましょう。
-- View all the key phrases and their score for a document related to Peter permanent employee
SELECT column_id,name,keyphrase,score FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220)
INNER JOIN dbo.EmployeesDocumentStore on path_locator=document_key
order by score desc
結果:
キーフレーズ従業員 このドキュメントで最高のスコアを取得します。列のすべての単語が、ドキュメントの意味を決定するキーフレーズであることがわかります。
SEMANTICSIMILARITYTABLE機能を理解する
この機能は、キーフレーズに基づいて1つのドキュメントを他のすべてのドキュメントと比較するのに役立ちます。この関数の構文は次のとおりです。
SEMANTICSIMILARITYTABLE
(
table,
{ column | (column_list) | * },
source_key
)
他のドキュメントと一致させるには、テーブルの名前、列、およびドキュメントキーが必要です。たとえば、キーフレーズの一致スコアが良好であれば、2つのドキュメントは類似していると言えます。
SEMANTICSIMILARITYTABLE関数を使用したドキュメントの比較
SEMANTICSIMILARITYTABLE を使用して、あるドキュメントを他のドキュメントと比較してみましょう。 機能。
すべてのプロジェクトマネージャーのドキュメントの比較
プロジェクトマネージャーに関連するすべてのドキュメントを確認する必要があります。上記の例から、ドキュメントキーであることがわかります。 指定されたドキュメントの場合は0xFF6A92952500812FF013376870181CFA6D7C070220 。したがって、このキーを使用して、プロジェクトマネージャーを含む他の一致を見つけることができます。
USE EmployeesFilestreamSample
-- View all the documents closely related to Peter project manager
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
出力:
最も密接に関連するドキュメントは、 Asif Permanent Employee – Experienced Project Manager.docx 。 どちらの従業員も常勤の労働者であり、どちらもプロジェクトマネージャーであるため、これは理にかなっています。
経験豊富なビジネスアナリストのドキュメントの比較
次に、経験豊富なビジネスアナリストに関連するドキュメントを比較します。 sそして、セマンティック検索を使用して最も近い一致を見つけます。ドキュメント名ベースの分析に限定されています:
USE EmployeesFilestreamSample
-- Finding document_key for experienced business analyst
select name,path_locator as document_key from EmployeesDocumentStore
where name like '%experienced business analyst%'
-- View all the documents closely related to experienced business analyst
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
出力:
上記の結果からわかるように、経験豊富なビジネスアナリストに関連するドキュメントに最も近いもの 経験豊富なプロジェクトマネージャーのドキュメントです どちらも経験があるからです 。それでも、スコア0.3は、これら2つのドキュメントに共通点があまりないことを示しています。
結論
おめでとう!ドキュメントをWindowsフォルダーに保存し、セマンティック検索を使用してそれらを分析する方法を正常に学習しました。また、実際に使用する関数についても説明しました。これで、新しい知識を適用して、次の演習を試すことができます
今後の資料にご期待ください!