リレーショナルデータベースは、さまざまなデータ型の列を使用するテーブルで組織のデータを表し、有効な値を格納できるようにします。開発者とDBAは、クエリのパフォーマンスを向上させるために、各列の適切なデータ型を理解して理解する必要があります。
この記事では、一般的なデータ型VARCHAR()とNVARCHAR()、それらの比較、およびSQLServerでのパフォーマンスレビューについて説明します。
VARCHAR [( n | 最大 )] SQL
VARCHAR データ型は非Unicodeを表します 可変長文字列データ型。文字、数字、特殊文字を保存できます。
- N 文字列のサイズをバイト単位で表します。
- VARCHARデータ型の列には、最大8000文字の非Unicode文字が格納されます。
- VARCHARデータ型は1文字あたり1バイトかかります。 Nの値を明示的に指定しない場合、1バイトのストレージが必要になります。
注: Nを混同しないでください 文字列の文字数を表す値を使用します。
次のクエリは、100バイトのデータを含むVARCHARデータ型を定義します。
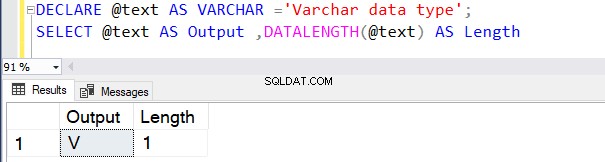
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
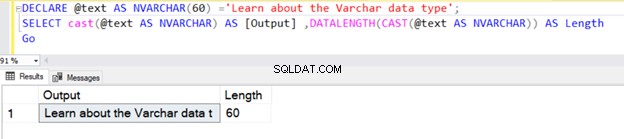
スペース文字を含む1文字あたり1バイトであるため、長さは17として返されます。
次のクエリは、 Nの値を指定せずにVARCHARデータ型を定義します 。したがって、SQL Serverは、以下に示すように、デフォルト値を1バイトと見なします。
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
CASTまたはCONVERT関数を使用してVARCHARを使用することもできます。たとえば、以下の2つの例では、長さが100バイトの変数を宣言し、後でCAST演算子を使用しました。
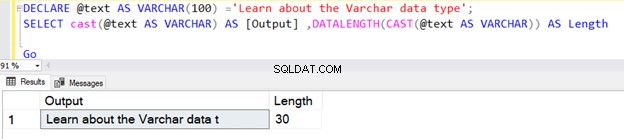
CAST演算子のVARCHARデータ型でNを指定しなかったため、最初のクエリは長さを30として返します。デフォルトの長さは30です。
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
ただし、文字列の長さが30未満の場合は、文字列の実際のサイズになります。

NVARCHAR [( n | 最大 )] SQL
NVARCHAR データ型はUnicode用です 可変長文字データ型。ここで、Nは各国語の文字セットを指し、Unicode文字列を定義するために使用されます。非Unicode文字とUnicode文字(日本語の漢字、韓国語のハングルなど)の両方を保存できます。
- N 文字列のサイズをバイト単位で表します。
- 最大4000文字のUnicodeおよび非Unicode文字を保存できます。
- VARCHARデータ型は1文字あたり2バイトかかります。 Nに値を指定しない場合、2バイトのストレージが必要です。
次のクエリは、100バイトのデータを含むVARCHARデータ型を定義します。
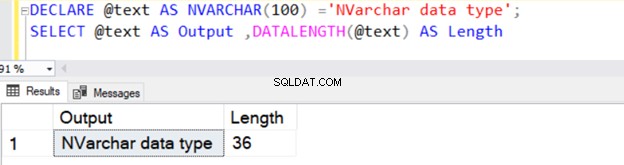
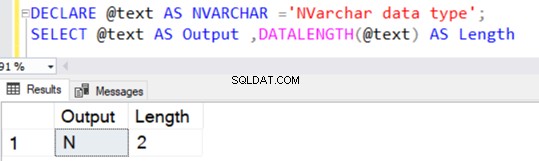
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
NVARCHARは文字ストレージごとに2バイトを使用するため、文字列の長さ36を返します。
VARCHARデータ型と同様に、NVARCHARのデフォルト値も1文字(2バイト)で、Nに明示的な値を指定していません。
Nの明示的な値なしでCASTまたはCONVERT関数を使用してNVARCHAR変換を適用する場合、デフォルト値は30文字、つまり60バイトです。
Unicode値と非Unicode値をVARCHARデータ型に格納する
eショッピングポータルからの顧客のフィードバックを記録するテーブルがあるとします。この目的のために、次のクエリを含むSQLテーブルがあります。
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
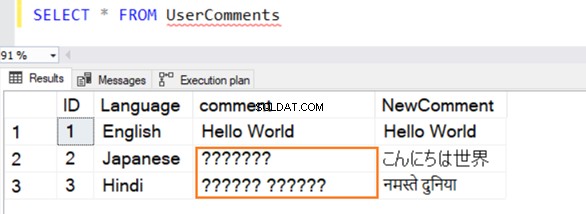
この表には、英語、日本語、ヒンディー語のサンプルレコードをいくつか挿入します。 [コメント]のデータ型 VARCHARです および[NewComment] NVARCHAR()です 。
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
クエリは正常に実行され、そこから値を選択すると次の行が表示されます。 2行目と3行目では、英語でない場合はデータを認識しません。
VARCHARおよびNVARCHARデータ型:パフォーマンスの比較
JOINまたはWHERE述部でVARCHARとNVARCHARのデータ型の使用を混在させないでください。 SQL ServerはJOINの両側で同じデータ型を必要とするため、既存のインデックスを無効にします。 SQL Serverは、不一致の場合にCONVERT_IMPLICIT()関数を使用して暗黙的な変換を実行しようとします。
SQL Serverは、データ型の優先順位を使用して、ターゲットデータ型を判別します。 NVARCHARは、VARCHARデータ型よりも優先されます。したがって、データ型の変換中に、SQLServerは既存のVARCHAR値をNVARCHARに変換します。
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
次に、データ型ごとにレコードを取得する2つのSELECTステートメントを実行しましょう。
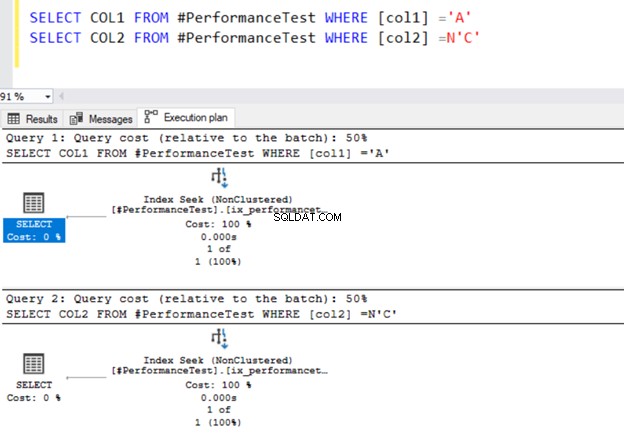
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
どちらのクエリもインデックスシーク演算子を使用します および前に定義したインデックス。
ここで、WHERE述語と比較するためにデータ型の値を切り替えます。列1にはVARCHARデータ型がありますが、N’A’を指定してNVARCHARデータ型として配置します。
同様に、col2はNVARCHARデータ型であり、VARCHARデータ型を参照する値「C」を指定します。
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'クエリの実際の実行プランでは、インデックススキャンが実行され、SELECTステートメントには警告記号があります。
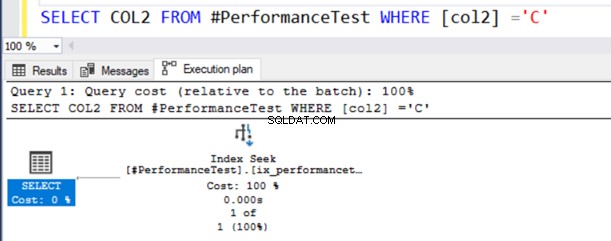
NVARCHAR()データ型はUnicode値と非Unicode値の両方を持つことができるため、このクエリは正常に機能します。
ここで、2番目のクエリはインデックススキャンを使用し、SELECT演算子で警告記号を発行します。
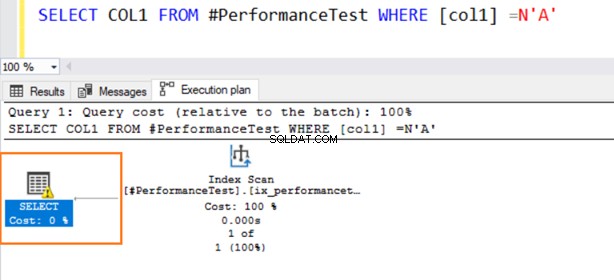
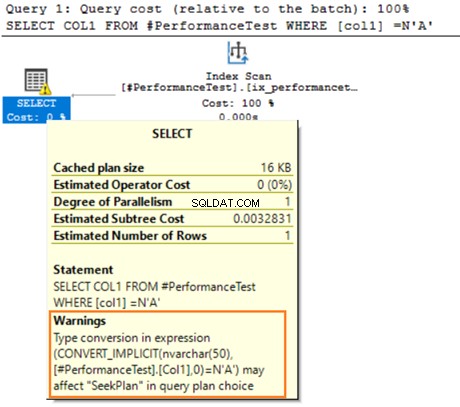
暗黙の変換に関する警告を発行するSELECTステートメントにマウスを合わせます。 SQLServerは既存のインデックスを適切に使用できませんでした。これは、VARCHARとNVARCHARの両方のデータ型でデータ並べ替えアルゴリズムが異なるためです。
テーブルに数百万の行がある場合、SQL Serverは追加の作業を行い、暗黙的にデータ変換を使用してデータを変換する必要があります。クエリのパフォーマンスに悪影響を与える可能性があります。したがって、クエリを最適化する際には、これらのデータ型を混在させたり一致させたりしないでください。
結論
データベーステーブルとその列のデータ型を適切に設計する際には、データ要件を確認する必要があります。通常、VARCHARデータ型はほとんどのデータ要件に対応します。ただし、Unicodeデータ型と非Unicodeデータ型の両方を列に格納する必要がある場合は、NVARCHARの使用を検討できます。ただし、最終的な決定を行う前に、パフォーマンスへの影響、ストレージサイズを確認する必要があります。