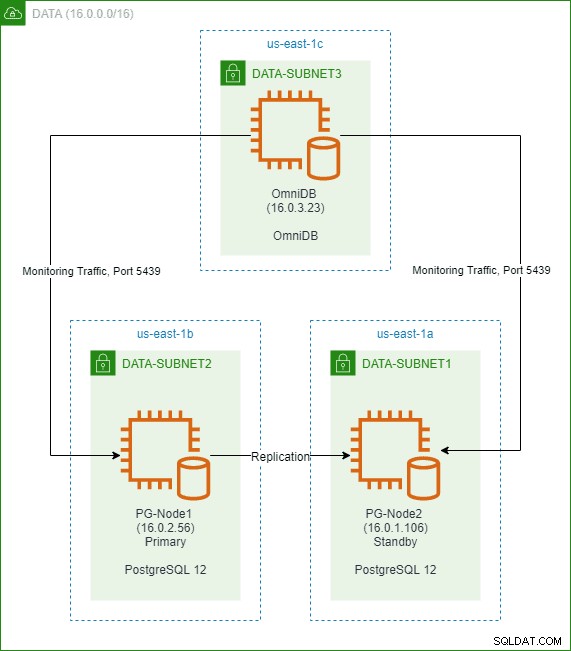
このシリーズの前回の記事では、AWSクラウドに2ノードのPostgreSQL12クラスターを作成しました。また、3番目のノードに2ndQuadrantOmniDBをインストールして構成しました。以下の画像はアーキテクチャを示しています:
OmniDBのWebベースのユーザーインターフェイスから、プライマリノードとスタンバイノードの両方に接続できます。次に、スタンバイへの複製を開始したプライマリノードに「dvdrental」というサンプルデータベースを復元しました。
シリーズのこのパートでは、OmniDBで監視ダッシュボードを作成して使用する方法を学習します。 DBAと運用チームは、データベースの状態を視覚的に検査するために、複雑なクエリではなくグラフィカルツールを好むことがよくあります。 OmniDBには、監視ダッシュボードで簡単に使用できる重要なウィジェットが多数付属しています。後で説明するように、ユーザーが独自の監視ウィジェットを作成することもできます。
パフォーマンス監視ダッシュボードの構築
OmniDBに付属しているデフォルトのダッシュボードから始めましょう。
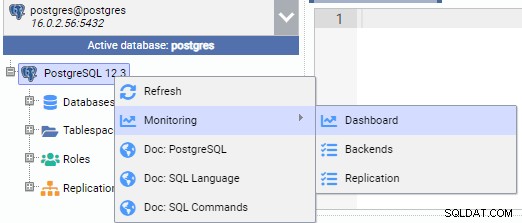
下の画像では、プライマリノード(PG-Node1)に接続されています。インスタンス名を右クリックし、ポップアップメニューから[監視]、[ダッシュボード]の順に選択します。
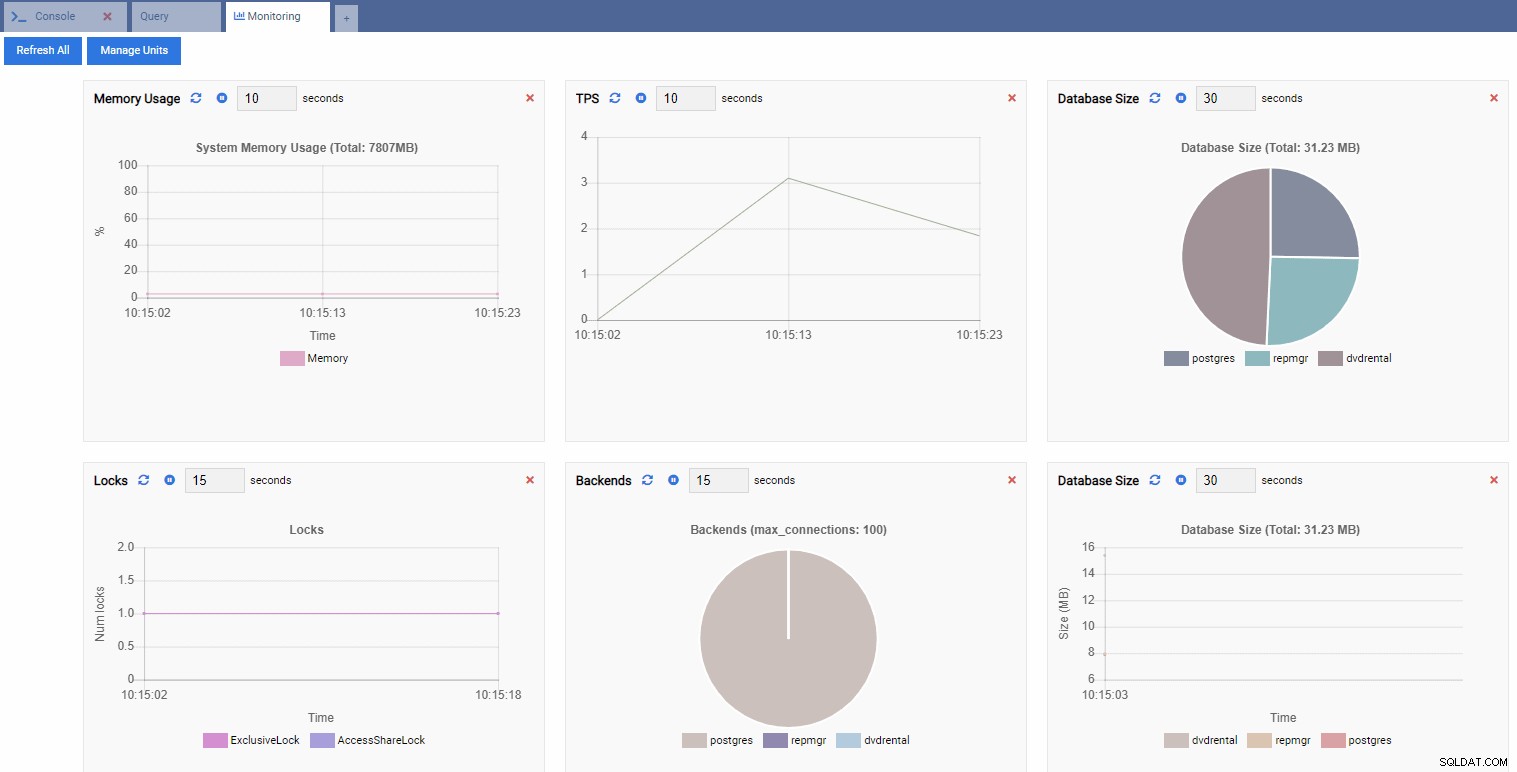
これにより、いくつかのウィジェットを含むダッシュボードが開きます。
OmniDBの用語では、ダッシュボードの長方形のウィジェットは監視ユニットと呼ばれます。 。これらの各ユニットは、接続されているPostgreSQLインスタンスからの特定のメトリックを示し、データを動的に更新します。
監視ユニットについて
OmniDBには、次の4種類の監視ユニットが付属しています。
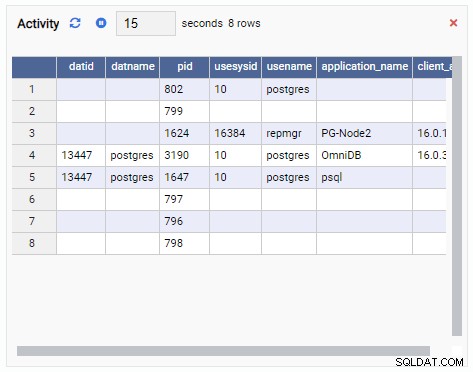
- グリッド クエリの結果を示す表形式の構造です。たとえば、これはSELECT *FROMpg_stat_replicationの出力になります。グリッドは次のようになります:
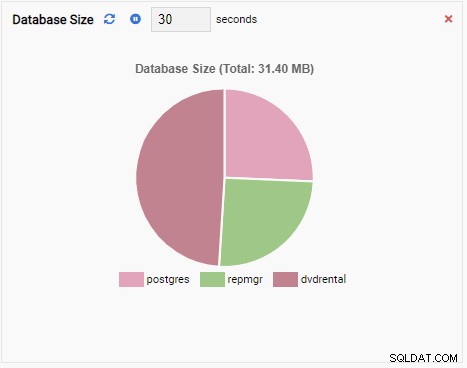
- グラフ 線や円グラフなどのグラフ形式でデータを表示します。更新すると、グラフ全体が新しい値で画面に再描画され、古い値はなくなります。これらの監視ユニットでは、メトリックの現在の値のみを確認できます。グラフの例を次に示します。
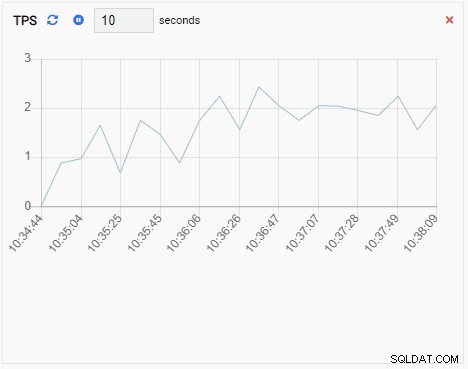
- グラフ-追加 チャートタイプの監視ユニットでもありますが、更新時に既存のシリーズに新しい値を追加する点が異なります。 Chart-Appendを使用すると、時間の経過に伴う傾向を簡単に確認できます。次に例を示します。
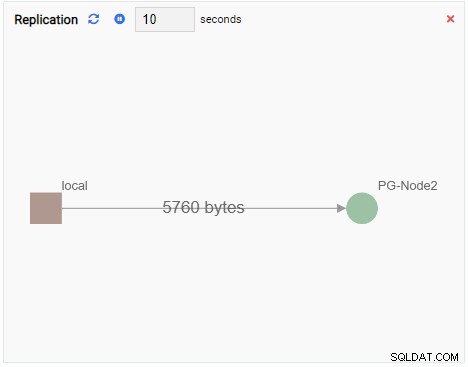
- グラフ PostgreSQLクラスターインスタンスと関連するメトリック間の関係を示します。チャート監視ユニットと同様に、グラフ監視ユニットも古い値を新しい値で更新します。次の画像は、現在のノード(PG-Node1)がPG-Node2に複製されていることを示しています。
すべての監視ユニットには、いくつかの共通の要素があります。
- 監視ユニット名
- ユニットを手動で更新するための「更新」ボタン
- 監視ユニットの更新を一時的に停止するための「一時停止」ボタン
- 現在の更新間隔を示すテキストボックス。これは変更できます
- ダッシュボードからモニタリングユニットを削除するための「閉じる」ボタン(赤い十字マーク)
- モニタリングの実際の描画領域
構築済みの監視ユニット
OmniDBには、ダッシュボードに追加できるPostgreSQL用の多数の監視ユニットが付属しています。これらのユニットにアクセスするには、ダッシュボードの上部にある[ユニットの管理]ボタンをクリックします。
これにより、「ユニットの管理」リストが開きます。
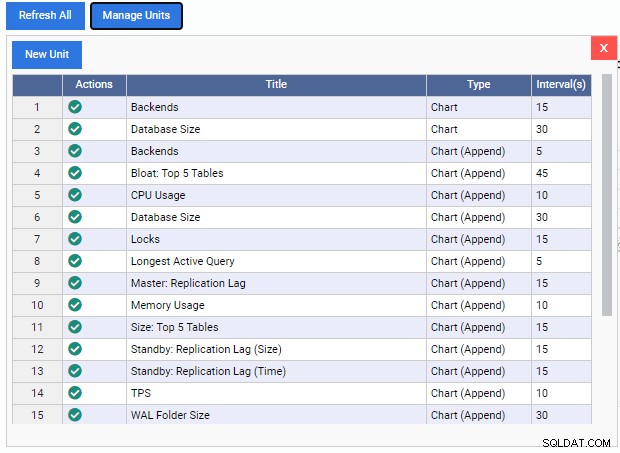
ご覧のとおり、ここには事前に構築された監視ユニットはほとんどありません。これらのモニタリングユニットのコードは、2ndQuadrantのGitHubリポジトリから無料でダウンロードできます。ここにリストされている各ユニットは、その名前、タイプ(チャート、チャート追加、グラフ、またはグリッド)、およびデフォルトのリフレッシュレートを示しています。
ダッシュボードに監視ユニットを追加するには、そのユニットの[アクション]列の下にある緑色のチェックマークをクリックするだけです。さまざまな監視ユニットを組み合わせて、必要なダッシュボードを構築できます。
下の画像では、パフォーマンス監視ダッシュボードに次のユニットを追加し、その他すべてを削除しています。
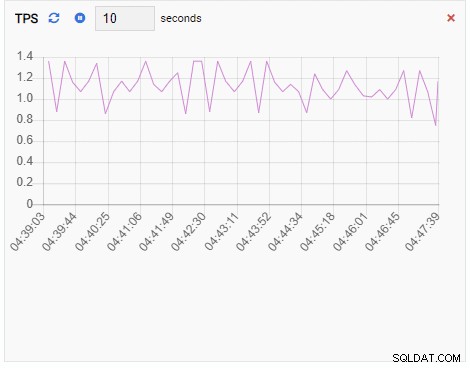
TPS(1秒あたりのトランザクション数):
ロックの数:
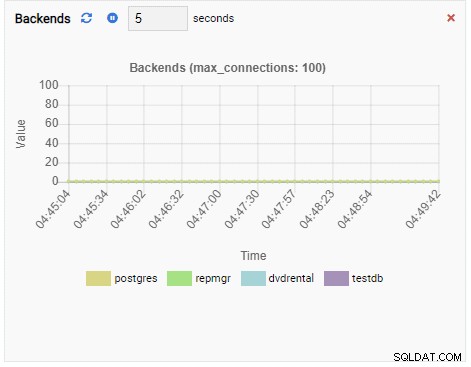
バックエンドの数:
インスタンスがアイドル状態であるため、TPS、ロック、およびバックエンドの値が最小であることがわかります。
監視ダッシュボードのテスト
次に、プライマリノード(PG-Node1)でpgbenchを実行します。 pgbenchは、PostgreSQLに付属しているシンプルなベンチマークツールです。この種の他のほとんどのツールと同様に、pgbenchは、初期化時にサンプルのOLTPシステムのスキーマとテーブルをデータベースに作成します。その後、複数のクライアント接続をエミュレートでき、それぞれがデータベース上で多数のトランザクションを実行します。この場合、PostgreSQLプライマリノードのベンチマークは行いません。 pgbenchのデータベースのみを作成し、ダッシュボードの監視ユニットがシステムの状態の変化を検出するかどうかを確認します。
まず、プライマリノードにpgbenchのデータベースを作成しています:
[example@sqldat.com〜] $ psql -h PG-Node1 -U postgres -c "CREATE DATABASE testdb"; CREATE DATABASE
次に、pgbenchの「testdb」データベースを初期化します。
[example@sqldat.com〜] $ / usr / pgsql-12 / bin / pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s20testdb古いテーブルの削除...テーブルの作成...生成データ...2000000タプルの100000(5%)完了(0.02秒経過、残り0.43秒)2000000タプルの200000(10%)完了(0.05秒経過、残り0.41秒)……2000000タプルの2000000(100%)完了(1.84秒経過、残り0.00秒)バキューム...主キーの作成...完了。
データベースが初期化されたら、実際のロードプロセスを開始します。以下のコードスニペットでは、pgbenchに、testdbデータベースに対して50の同時クライアント接続を開始するように要求しています。各接続は、そのテーブルで100000トランザクションを実行します。負荷テストは2つのスレッドで実行されます。
[example@sqldat.com〜] $ / usr / pgsql-12 / bin / pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdbstartingvacuum...end。……
OmniDBダッシュボードに戻ると、監視ユニットが非常に異なる結果を示していることがわかります。
TPSメトリックは非常に高い値を示しています。 2未満から2000を超えるまで急増しています:
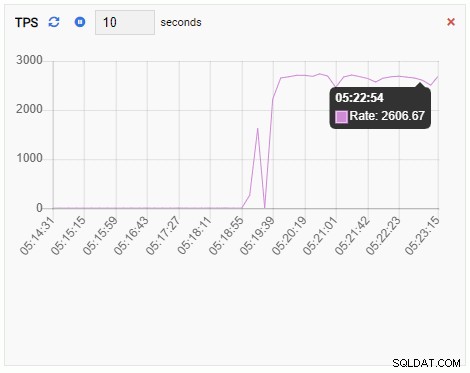
バックエンドの数が増えました。予想どおり、他のデータベースがアイドル状態のときに、testdbには50の接続があります。
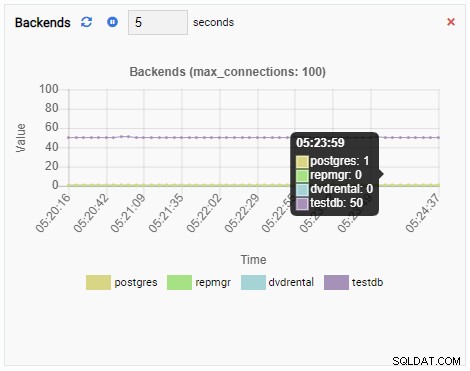
そして最後に、testdbデータベースの行排他ロックの数も多くなっています:
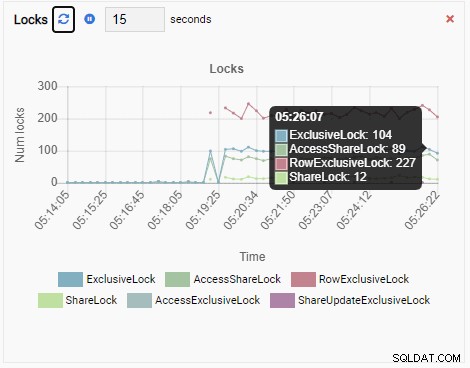
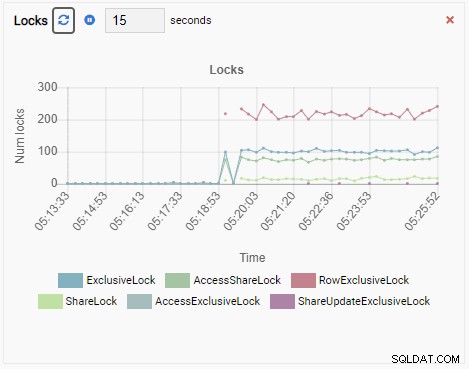
これを想像してみてください。あなたはDBAであり、PostgreSQLインスタンスのフリートを管理するためにOmniDBを使用しています。いずれかのインスタンスでパフォーマンスの低下を調査するための電話があります。
今見たようなダッシュボードを使用すると(非常に単純なものですが)、根本的な原因を簡単に見つけることができます。バックエンド、ロック、使用可能なメモリなどの数を確認して、問題の原因を確認できます。
そして、それがOmniDBが本当に役立つツールになる可能性がある場所です。
カスタム監視ユニットの作成
場合によっては、独自の監視ユニットを作成する必要があります。新しい監視ユニットを作成するには、「ユニットの管理」リストの「新しいユニット」ボタンをクリックします。これにより、コードを記述するための空のキャンバスで新しいタブが開きます:
画面の上部で、監視ユニットの名前を指定し、そのタイプを選択して、デフォルトの更新間隔を指定する必要があります。テンプレートとして既存のユニットを選択することもできます。
ヘッダーセクションの下には、2つのテキストボックスがあります。 「データスクリプト」エディタは、モニタリングユニットのデータを取得するためのコードを記述する場所です。ユニットが更新されるたびに、データスクリプトコードが実行されます。 「チャートスクリプト」エディタは、実際のユニットを描画するためのコードを記述する場所です。これは、ユニットが最初に描画されたときに実行されます。
すべてのデータスクリプトコードはPythonで記述されています。チャートタイプの監視ユニットの場合、OmniDBではチャートスクリプトをChart.jsで記述する必要があります。
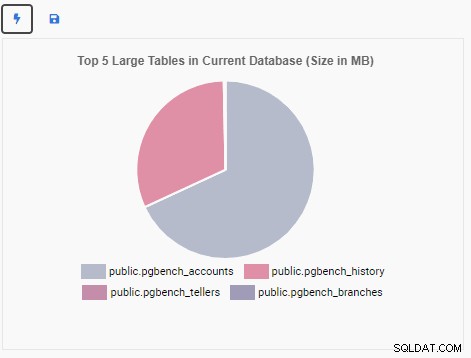
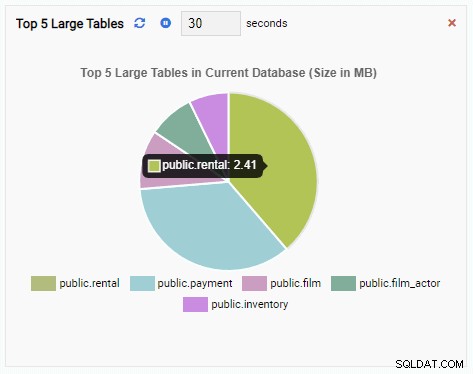
次に、現在のデータベースの上位5つの大きなテーブルを表示する監視ユニットを作成します。 OmniDBで選択されたデータベースに基づいて、監視ユニットはそのデータベース内の最大の5つのテーブルの名前を反映するように表示を変更します。
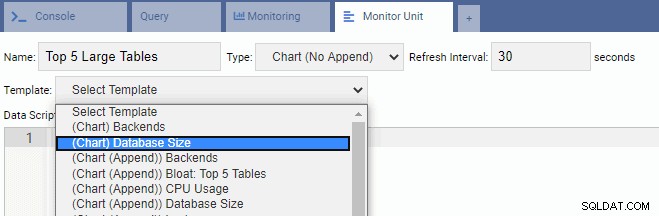
新しいユニットを作成するには、既存のテンプレートから始めて、そのコードを変更するのが最善です。これにより、時間と労力の両方を節約できます。次の画像では、監視ユニットに「上位5つの大きなテーブル」という名前を付けています。チャートタイプ(追加なし)として選択し、30秒のリフレッシュレートを提供しました。また、監視ユニットはデータベースサイズテンプレートに基づいています:
[データスクリプト]テキストボックスには、データベースサイズ監視ユニットのコードが自動的に入力されます:
from datetime import datetimefrom random import randintdatabases =connection.Query('''SELECT d.datname AS datname、round(pg_catalog.pg_database_size(d.datname)/1048576.0,2)AS size FROM pg_catalog.pg_database d datname not in('template0'、'template1')''')data =[] color =[] label =[] for db in database.Rows:data.append(db ["size"])color.append( "rgb(" + str(randint(125、225))+ "、" + str(randint(125、225))+ "、" + str(randint(125、225))+ ")")label.append (db ["datname"])total_size =connection.ExecuteScalar('''SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2)FROM pg_catalog.pg_database WHERE NOT datistemplate''')result ={"labels ":label、" datasets ":[{" data ":data、" backgroundColor ":color、" label ":"データベース1 ":" size "} "MB)"} また、グラフスクリプトのテキストボックスにもコードが入力されています:
total_size =connection.ExecuteScalar('''SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2)FROM pg_catalog.pg_database WHERE NOT datistemplate''')result ={"type": "pie" 、"data":なし、 "options":{"response":True、 "title":{"display":True、 "" text ":"データベースサイズ(合計: "+ str(total_size) }}} データスクリプトを変更して、データベースの上位5つの大きなテーブルを取得できます。以下のスクリプトでは、SQLステートメントを除く元のコードのほとんどを保持しています。
from datetime import datetimefrom random import randinttables =connection.Query('''SELECT nspname||'。'||relname AS "tablename"、round(pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2)AS " table_size "FROM pg_class C LEFT JOIN pg_namespace N ON(N.oid =C.relnamespace)WHERE nspname NOT IN('pg_catalog'、'information_schema')AND C.relkind <>'i' AND nspname!〜'^ pg_toast' BY 2 DESC LIMIT 5;''')data =[] color =[] label =[] for table in Tables.Rows:data.append(table ["table_size"])color.append( "rgb(" + str (randint(125、225))+ "、" + str(randint(125、225))+ "、" + str(randint(125、225))+ ")")label.append(table ["tablename" ])result ={"labels":label、 "datasets":[{"data ":data、" backgroundColor ":color、} pre}]
ここでは、現在のデータベース内の各テーブルとそのインデックスの合計サイズを取得しています。結果を降順で並べ替え、上位5行を選択しています。
次に、結果セットを反復処理して3つのPython配列を作成します。
最後に、配列の値に基づいてJSON文字列を作成しています。
[グラフスクリプト]テキストボックスで、元のSQLコマンドを削除するようにコードを変更しました。ここでは、チャートの表面的な側面のみを指定しています。グラフを円の種類として定義し、そのタイトルを提供しています:
result ={"type": "pie"、 "data":None、 "options":{"response":True、 "title":{"display":True、 "Top" "現在のデータベースのテーブル(サイズ(MB)) "}}}
これで、稲妻アイコンをクリックしてユニットをテストできます。これにより、プレビュー描画領域に新しい監視ユニットが表示されます:
次に、ディスクアイコンをクリックしてユニットを保存します。ユニットが保存されたことを確認するメッセージボックス:

ここで、監視ダッシュボードに戻り、新しい監視ユニットを追加します。
カスタム監視ユニットの[アクション]列の下に、さらに2つのアイコンがあることに注意してください。 1つは編集用で、もう1つはOmniDBから削除するためのものです。
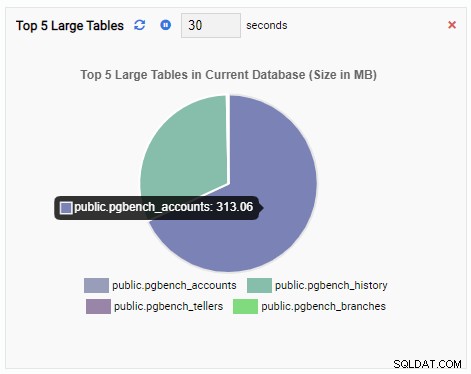
「上位5つの大きなテーブル」監視ユニットに、現在のデータベースで最大の5つのテーブルが表示されるようになりました。
ダッシュボードを閉じ、ナビゲーションペインから別のデータベースに切り替えて、ダッシュボードを再度開くと、そのデータベースのテーブルを反映するように監視ユニットが変更されていることがわかります。
最後の言葉
これで、OmniDBに関する2部構成のシリーズは終わりです。これまで見てきたように、OmniDBには、PostgreSQLDBAがパフォーマンスの追跡に役立つと思われる気の利いた監視ユニットがいくつかあります。これらのユニットを使用して、サーバーの潜在的なボトルネックを特定する方法を確認しました。また、独自のカスタムユニットを作成する方法も確認しました。読者は、特定のワークロードのパフォーマンス監視ユニットを作成してテストすることをお勧めします。 2ndQuadrantは、OmniDB MonitoringUnitGitHubリポジトリへの貢献を歓迎します。