状況によります。
まず第一に
共通テーブル式とは何ですか?
(非再帰的な)CTEは、SQLServerでインラインテーブル式としても使用できる他の構成と非常によく似た方法で処理されます。派生テーブル、ビュー、およびインラインテーブル値関数。 BOLは、CTEは「一時的な結果セットと考えることができる」と述べていますが、これは純粋に論理的な説明であることに注意してください。多くの場合、それ自体は材料化されていません。
一時テーブルとは何ですか?
これは、tempdbのデータページに格納されている行のコレクションです。データページは、部分的または全体的にメモリ内に存在する場合があります。さらに、一時テーブルにインデックスが付けられ、列の統計が含まれる場合があります。
テストデータ
CREATE TABLE T(A INT IDENTITY PRIMARY KEY, B INT , F CHAR(8000) NULL);
INSERT INTO T(B)
SELECT TOP (1000000) 0 + CAST(NEWID() AS BINARY(4))
FROM master..spt_values v1,
master..spt_values v2;
例1
WITH CTE1 AS
(
SELECT A,
ABS(B) AS Abs_B,
F
FROM T
)
SELECT *
FROM CTE1
WHERE A = 780

上記の計画には、CTE1についての言及がないことに注意してください。ベーステーブルに直接アクセスするだけで、
と同じように扱われます。SELECT A,
ABS(B) AS Abs_B,
F
FROM T
WHERE A = 780
ここでCTEを中間の一時テーブルに具体化して書き直すと、生産性が大幅に低下します。
のCTE定義の具体化
SELECT A,
ABS(B) AS Abs_B,
F
FROM T
約8GBのデータを一時テーブルにコピーする必要がありますが、それでもそこから選択するオーバーヘッドがあります。
例2
WITH CTE2
AS (SELECT *,
ROW_NUMBER() OVER (ORDER BY A) AS RN
FROM T
WHERE B % 100000 = 0)
SELECT *
FROM CTE2 T1
CROSS APPLY (SELECT TOP (1) *
FROM CTE2 T2
WHERE T2.A > T1.A
ORDER BY T2.A) CA
上記の例は、私のマシンでは約4分かかります。
ランダムに生成された1,000,000個の値のうち15行だけが述語に一致しますが、これらを見つけるために高価なテーブルスキャンが16回行われます。
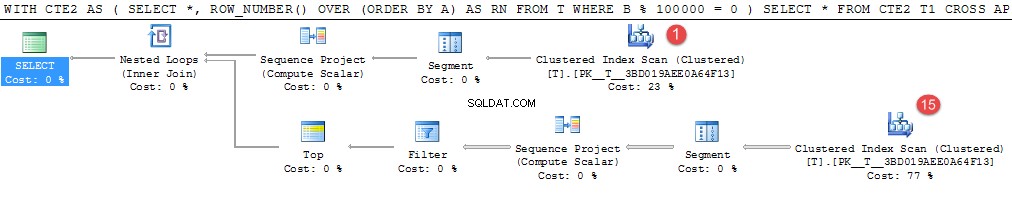
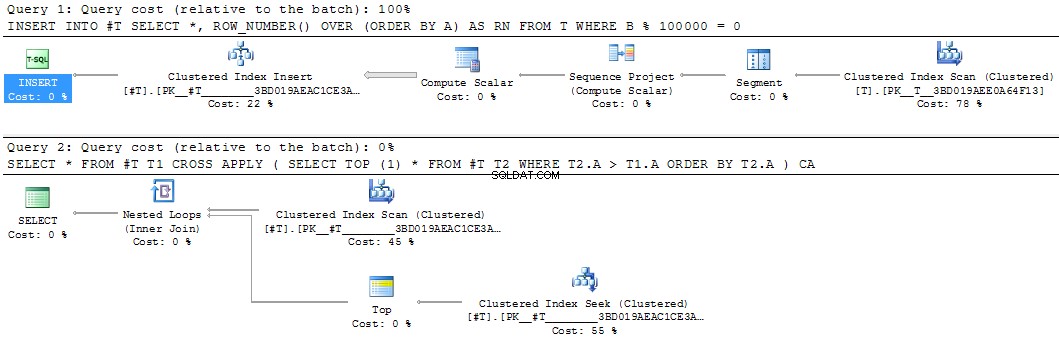
これは、中間結果を具体化するための良い候補になります。同等の一時テーブルの書き換えには25秒かかりました。
INSERT INTO #T
SELECT *,
ROW_NUMBER() OVER (ORDER BY A) AS RN
FROM T
WHERE B % 100000 = 0
SELECT *
FROM #T T1
CROSS APPLY (SELECT TOP (1) *
FROM #T T2
WHERE T2.A > T1.A
ORDER BY T2.A) CA
クエリの一部を一時テーブルに中間的にマテリアライズすると、一度だけ評価された場合でも、マテリアライズされた結果の統計を利用してクエリの残りの部分を再コンパイルできる場合に役立つことがあります。このアプローチの例は、SQLCatの記事「複雑なクエリを分解する場合」にあります。
状況によっては、SQLServerはスプールを使用して中間結果をキャッシュします。 CTEの、そしてそのサブツリーを再評価する必要を避けます。これについては、(移行された)接続項目で説明されています。CTEまたは派生テーブルの中間実体化を強制するためのヒントを提供します。ただし、これに関する統計は作成されず、スプール行の数が見積もりと大幅に異なる場合でも、進行中の実行プランがそれに応じて動的に適応することはできません(少なくとも現在のバージョンでは。適応クエリプランはで可能になる可能性があります。未来)。