クロスアプライクエリのパフォーマンスがこの単純なXMLドキュメントで非常に低く、データセットが大きくなるにつれてパフォーマンスが指数関数的に遅くなる理由は何ですか?
これは、親軸を使用してアイテムノードから属性IDを取得することです。
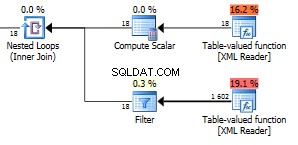
問題となるのは、クエリプランのこの部分です。

下のテーブル値関数から出てくる423行に注目してください。
3つのフィールドノードを持つアイテムノードをもう1つ追加すると、これが得られます。
732行が返されました。
最初のクエリのノードを2倍にして、合計6つのアイテムノードにした場合はどうなりますか?
最大で1602行が返されます。
上の関数の図18は、XMLのすべてのフィールドノードです。ここには6つのアイテムがあり、各アイテムに3つのフィールドがあります。これらの18個のノードは、他の関数に対して結合するネストされたループで使用されるため、1602行を返す18回の実行により、反復ごとに89行が返されます。これは、XML全体のノードの正確な数です。実は、表示されているすべてのノードより1つ多いです。どうしてか分かりません。このクエリを使用して、XML内のノードの総数を確認できます。
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
したがって、親軸..を使用するときに、SQLServerが値を取得するために使用するアルゴリズム 値関数では、最初にシュレッダーにかけているすべてのノードを検出します。最後の場合は18です。それらのノードごとに、XMLドキュメント全体を細断処理して返し、実際に必要なノードのフィルター演算子をチェックインします。親軸を使用する代わりに、1つの追加のクロスアプライを使用する必要があります。最初にアイテムを細断し、次にフィールドを細断します。
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
また、フィールドのテキスト値にアクセスする方法も変更しました。 .を使用する SQLServerがfieldへの子ノードを検索するようにします そして、それらの値を結果に連結します。子の値がないため、結果は同じですが、クエリプラン(UDX演算子)にその部分を含めないようにすることをお勧めします。
XMLインデックスを使用している場合、クエリプランには親軸の問題はありませんが、フィールド値の取得方法を変更することでメリットが得られます。