SQL Serverがこれを行う理由についての質問に答えると、クエリは論理的な順序でコンパイルされず、各ステートメントはそれ自体のメリットに基づいてコンパイルされるため、selectステートメントのクエリプランが生成されるときに、オプティマイザーが@val1と@Val2がそれぞれ「val1」と「val2」になることを知りません。
SQL Serverが値を認識していない場合、その変数がテーブルに表示される回数を最も正確に推測する必要があります。これにより、計画が最適化されない場合があります。私の主なポイントは、異なる値を持つ同じクエリが異なる計画を生成する可能性があるということです。この簡単な例を想像してみてください:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
ここで行ったのは、単純なテーブルを作成し、列valに値1〜10の1000行を追加することだけです。 ただし、1つは991回表示され、他の9つは1回だけ表示されます。このクエリを前提としています:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
シークにインデックスを使用するよりも、テーブル全体をスキャンする方が効率的です。次に、991ブックマークルックアップを実行して、Fillerの値を取得します。 ただし、次のクエリは1行のみです:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
インデックスシークと、Fillerの値を取得するための単一のブックマークルックアップを実行する方が効率的です。 (そして、これら2つのクエリを実行すると、これが承認されます)
シークとブックマークのルックアップのカットオフは実際には状況によって異なると確信していますが、かなり低いです。少し試行錯誤しながらサンプルテーブルを使用すると、Valが必要であることがわかりました。 オプティマイザーがインデックスシークとブックマークルックアップの全表スキャンを実行する前に、値が2の38行を持つ列:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
したがって、この例では、制限は一致する行の3.7%です。
クエリは、変数を使用しているときに一致する行数がわからないため、推測する必要があります。最も簡単な方法は、行の総数を見つけ、これを列内の個別の値の総数で割ることです。したがって、この例では、WHERE val = @Valの推定行数 は1000/10=100です。実際のアルゴリズムはこれよりも複雑ですが、たとえば、これで十分です。したがって、次の実行計画を見ると:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
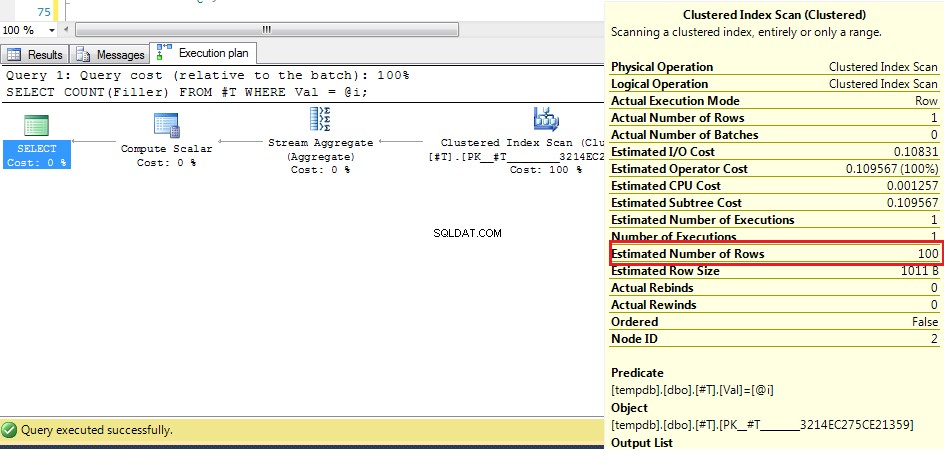
ここで(元のデータを使用して)推定行数は100ですが、実際の行数は1であることがわかります。前の手順から、オプティマイザーは38行を超えると、インデックスに対してクラスター化されたインデックススキャンを選択することがわかります。シーク。行数の最良の推測はこれよりも高いため、未知の変数の計画はクラスター化されたインデックススキャンです。
理論をさらに証明するために、1000行の数値1〜27が均等に分散されたテーブルを作成すると(したがって、推定行数は約1000/27 =37.037になります)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
次にクエリを再度実行すると、インデックスシークを含むプランが得られます:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
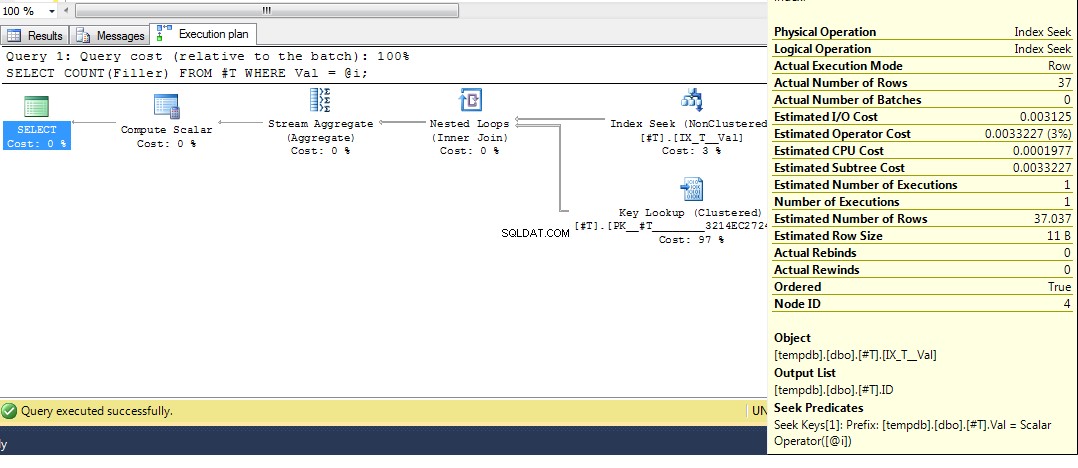
うまくいけば、それはあなたがその計画を得る理由をかなり包括的にカバーしています。次の質問は、どのように別の計画を強制するかということだと思います。答えは、クエリヒントOPTION (RECOMPILE)を使用することです。 、パラメータの値がわかっている実行時にクエリを強制的にコンパイルします。元のデータに戻す。ここで、Val = 2の最適な計画 はルックアップですが、変数を使用すると、インデックススキャンを使用したプランが生成され、次のコマンドを実行できます。
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
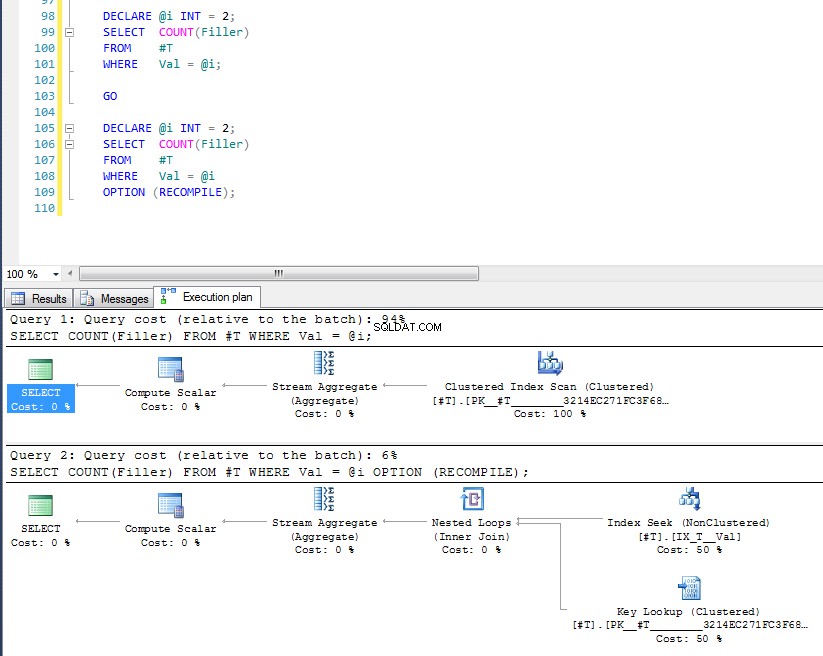
後者は実行時に変数の値をチェックしており、その特定の値に最も適切なプランが選択されているため、後者はインデックスシークとキールックアップを使用していることがわかります。 OPTION (RECOMPILE)の問題 つまり、キャッシュされたクエリプランを利用できないため、毎回クエリをコンパイルするための追加コストが発生します。