前回の投稿では、SQLServerに不可欠なプロアクティブなヘルスチェックについて説明するシリーズを開始しました。ディスクスペースから始めました。この投稿では、メンテナンスタスクについて説明します。 DBAの基本的な責任の1つは、次のメンテナンスタスクが定期的に実行されるようにすることです。
- バックアップ
- 整合性チェック
- インデックスのメンテナンス
- 統計の更新
私の賭けは、これらのタスクを管理するための仕事がすでに整っているということです。また、ジョブが失敗した場合にあなたとあなたのチームに電子メールを送信するように通知が構成されていることも間違いありません。両方が当てはまる場合は、すでにメンテナンスに積極的に取り組んでいます。そして、両方を行っていない場合は、今すぐ修正する必要があります。たとえば、これを読むのをやめ、Ola Hallengrenのスクリプトをダウンロードしてスケジュールを設定し、通知を設定してください。 (インデックスの保守に固有のもう1つの代替手段は、SQL Sentry Fragmentation Managerです。)
ジョブが失敗した場合にメールで通知するように設定されているかどうかわからない場合は、次のクエリを使用してください:
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
ただし、メンテナンスについて積極的に取り組むことは、さらに一歩進んでいます。ジョブを確実に実行するだけでなく、ジョブにかかる時間を知る必要があります。 msdbのシステムテーブルを使用して、これを監視できます。
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; または、Olaのスクリプトとログ情報を使用している場合は、OlaのCommandLogテーブルにクエリを実行できます。
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
上記のスクリプトは、AdventureWorks2014データベースの各完全バックアップのバックアップ期間を示しています。データベースが大きくなるにつれて、メンテナンスタスクの期間は時間の経過とともにゆっくりと増加することが予想されます。そのため、期間の大幅な増加または予期しない減少を探しています。たとえば、平均バックアップ時間が30分未満のクライアントがありました。突然、バックアップに1時間以上かかり始めました。データベースのサイズは大幅に変更されておらず、インスタンスまたはデータベースの設定も変更されておらず、ハードウェアまたはディスクの構成も変更されていません。数週間後、バックアップ期間は30分未満に短縮されました。その1か月後、彼らは再び上昇しました。最終的に、バックアップ期間の変更をクラスターノード間のフェイルオーバーに関連付けました。 1つのノードでは、バックアップに30分もかかりませんでした。一方、彼らは1時間以上かかりました。 NICとSANファブリックの構成を少し調査したところ、問題を特定することができました。
CHECKDB操作の平均実行時間を理解することも重要です。これは、Paulが高可用性とディザスタリカバリのイマージョンイベントで話していることです。CHECKDBの実行に通常かかる時間を知っておく必要があります。これにより、破損を見つけてデータベース全体のチェックを実行した場合に、どのくらいの時間が必要かがわかります。 CHECKDBが完了するまで待ちます。上司が「問題の範囲がわかるまで、どれくらい時間がかかりますか?」と尋ねたとき。待つ必要のある最小時間の定量的な答えを提供することができます。 CHECKDBに通常よりも時間がかかる場合は、何かが見つかったことがわかります(必ずしも破損しているとは限りません。常に、チェックを終了させる必要があります)。
現在、数百のデータベースを管理している場合、すべてのデータベースまたはすべてのジョブに対して上記のクエリを実行する必要はありません。代わりに、このクエリを使用して取得できる、平均期間から一定の割合で外れるジョブを検索したい場合があります。
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; このクエリは、平均より25%長くかかったジョブを一覧表示します。クエリでは、必要な特定の情報を提供するために微調整が必要になります。期間が短い(たとえば、5分未満)ジョブは、数分余分にかかる場合に表示されますが、これは問題ではない可能性があります。それでも、このクエリは良いスタートであり、逸脱を見つける方法はたくさんあることを理解してください。各実行を前の実行と比較して、前よりも一定の割合で時間がかかったジョブを探すこともできます。
明らかに、ジョブ期間は、バックアップジョブ、整合性チェック、または断片化を削除して統計を更新するジョブなど、潜在的な問題に使用する最も論理的な識別子です。期間の最大の変動は、通常、断片化を削除して統計を更新するタスクにあることがわかりました。再編成と再構築のしきい値、およびデータの変動性に応じて、ほとんどが再編成で数日かかる場合があります。その後、突然、大きなテーブルに対していくつかのインデックスの再構築が開始され、それらの再構築によって平均期間が完全に変更されます。一部のインデックスのしきい値を変更するか、曲線因子を調整して、インデックスと断片化のレベルに応じて、再構築がより頻繁に、またはより少なくなるようにすることができます。これらの調整を行うには、各インデックスが再構築または再編成される頻度を確認する必要があります。これは、Olaのスクリプトを使用してCommandLogテーブルにログを記録している場合、または独自のソリューションをロールしてログに記録している場合にのみ実行できます。各再編成または再構築。 CommandLogテーブルを使用してこれを確認するには、最初に、どのインデックスが最も頻繁に変更されているかを確認します。
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
この出力から、どのテーブル(したがってインデックス)が最もボラティリティが高いかを確認し、再編成と再構築のしきい値を調整する必要があるか、またはフィルファクターを変更する必要があるかを判断できます。
生活を楽にする
現在、SQL Sentry Event Manager(EM)を使用している限り、独自のクエリを作成するよりも簡単なソリューションがあります。このツールは、インスタンスに設定されたすべてのエージェントジョブを監視し、カレンダービューを使用して、失敗したジョブ、キャンセルされたジョブ、または通常より長く実行されたジョブをすばやく確認できます。
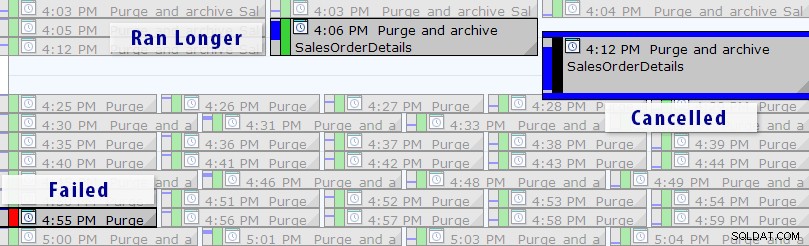 SQL Sentryイベントマネージャーのカレンダービュー(Photoshopでラベルが追加されています)
SQL Sentryイベントマネージャーのカレンダービュー(Photoshopでラベルが追加されています)
また、個々の実行にドリルダウンして、ジョブの実行にかかった時間を確認することもできます。また、期間の異常や障害状態のパターンをすばやく視覚化できる便利なランタイムグラフもあります。この場合、約15分ごとに、この特定のジョブの実行時間がほぼ400%増加したことがわかります。
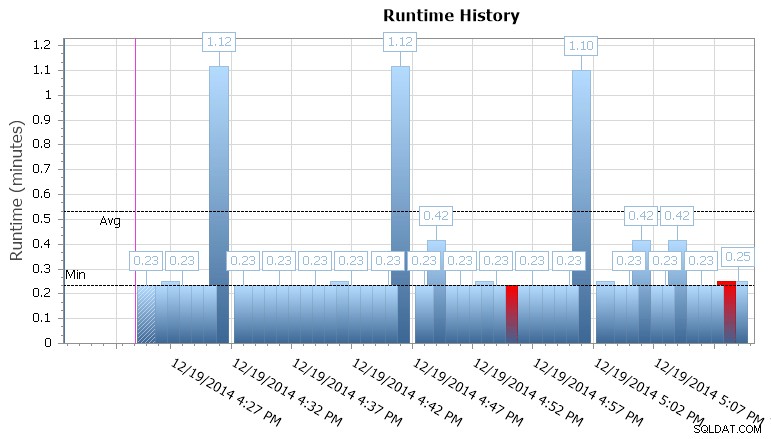 SQL SentryEventManagerランタイムグラフ
SQL SentryEventManagerランタイムグラフ
これにより、ここで同時実行の問題を引き起こしている可能性のある他のスケジュールされたジョブを調べる必要があるという手がかりが得られます。カレンダーをもう一度ズームアウトして、同じ時間に実行されている他のジョブを確認することも、これがこのデータベースに対して実行されるレポートまたはバックアップジョブであることを認識する必要がない場合もあります。
概要
ほとんどの人はすでに必要なメンテナンスジョブを実行しており、ジョブの失敗に対する通知も設定されていると思います。仕事の平均期間に慣れていない場合は、それがプロアクティブになるための次のステップです。注:職歴を保持している期間を確認する必要がある場合もあります。仕事の期間の偏差を探すときは、数週間ではなく、数か月分のデータを調べることを好みます。これらの実行時間を記憶する必要はありませんが、調査に使用する履歴を保持するのに十分なデータを保持していることを確認したら、定期的にバリエーションを探し始めます。理想的なシナリオでは、実行時間が長くなると潜在的な問題を警告できるため、実稼働環境で問題が発生する前に問題に対処できます。