2014年が終わりに近づくにつれ、今年の初めに書き戻した「パフォーマンスの問題:最初の遭遇」に基づいて、プロアクティブなSQLServerヘルスチェックに関する一連の投稿を開始します。その投稿では、なじみのない環境でパフォーマンスの問題をトラブルシューティングするときに最初に探すものについて説明しました。この一連の投稿では、長期の顧客にチェックインするときに何を探すのかについて話したいと思います。リモートDBAサービスを提供しており、定期的なタスクの1つは、環境の毎月の「ミニ」ヘルス監査です。私たちは監視を行っており、通常、私はプロジェクトに取り組んでいるので、定期的に環境にいます。ただし、何かを見逃していないことを確認するための追加の手順として、月に1回、標準の健康監査で収集したのと同じデータを調べて、異常なものを探します。それは多くのことかもしれませんね?はい!それでは、スペースから始めましょう。
おっと、スペース?はい、スペース。心配しないでください。他のトピックに行きます。 ☺
確認事項
なぜ私はスペースから始めるのですか?これは私がよく見過ごされていることであり、データベースファイルのディスク容量が不足すると、データベースで実行できる操作が非常に制限されます。データを追加する必要がありますが、ディスクがいっぱいであるためにファイルを拡張できませんか?申し訳ありませんが、ユーザーはデータを追加できなくなりました。何らかの理由でログのバックアップを取っていないので、トランザクションログがドライブをいっぱいにしますか?申し訳ありませんが、データを変更することはできません。スペースは重要です。ディスクとファイルの空き領域を監視するジョブがありますが、監査ごとに次のことを確認し、前月の値と比較します。
- 各ログファイルのサイズ
- 各データファイルのサイズ
- 各データファイルの空き容量
- データベースファイルを使用して各ドライブの空き容量
- バックアップファイルを使用して各ドライブの空き容量を増やす
ログファイルの増加
ディスクスペースに関連して私が目にする問題の大部分は、ログファイルの増大によるものです。成長は通常、次の2つの理由のいずれかで発生します。
- データベースは完全に復旧しており、何らかの理由でトランザクションログのバックアップが作成されていません
- 誰かが単一の非常に大きなトランザクションを実行し、既存のすべてのログスペースを消費して、ファイルを強制的に拡張します
また、インデックスのメンテナンスの一環としてログファイルが大きくなるのを見てきました。再構築の場合、すべての割り当てがログに記録され、大きなインデックスの場合、大量のログが生成される可能性があります。定期的なトランザクションログのバックアップを使用しても、ログはバックアップよりも速く大きくなる可能性があります。ログを管理するには、バックアップの頻度を調整するか、インデックスの保守方法を変更する必要があります。
ログファイルが大きくなった理由を特定する必要があります。これは、追跡しない限り注意が必要な場合があります。ログファイルのサイズと使用状況をスナップショットするために1時間ごとに実行されるジョブがあります:
USE [Baselines];
GO
IF (NOT EXISTS (SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'dbo'
AND TABLE_NAME = 'SQLskills_TrackLogSpace'))
BEGIN
CREATE TABLE [dbo].[SQLskills_TrackLogSpace](
[DatabaseName] [VARCHAR](250) NULL,
[LogSizeMB] [DECIMAL](38, 0) NULL,
[LogSpaceUsed] [DECIMAL](38, 0) NULL,
[LogStatus] [TINYINT] NULL,
[CaptureDate] [DATETIME2](7) NULL
) ON [PRIMARY];
ALTER TABLE [dbo].[SQLskills_TrackLogSpace] ADD DEFAULT (SYSDATETIME()) FOR [CaptureDate];
END
CREATE TABLE #LogSpace_Temp (
DatabaseName VARCHAR(100),
LogSizeMB DECIMAL(10,2),
LogSpaceUsed DECIMAL(10,2),
LogStatus VARCHAR(1)
);
INSERT INTO #LogSpace_Temp EXEC('dbcc sqlperf(logspace)');
INSERT INTO Baselines.dbo.SQLskills_TrackLogSpace
(DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus)
SELECT DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus
FROM #LogSpace_Temp;
DROP TABLE #LogSpace_Temp; この情報を使用して、ログファイルがいつ大きくなり始めたかを判断し、ログとジョブ履歴を調べて、見つけられる追加情報を確認します。ログの増加は静的である必要があります。ログは適切なサイズに設定され、バックアップを通じて管理される必要があります(フルリカバリで実行されている場合)。ファイルを大きくする必要がある場合は、その理由を理解し、それに応じてサイズを変更する必要があります。
この問題に対処していて、ファイルの増加イベントをまだ積極的に追跡していなかった場合でも、何が起こったのかを把握できる可能性があります。自動拡張イベントはSQLServerによってキャプチャされます。 SQLSentryのAaronBertrandは、2007年にこれについてブログに書き、これらのイベントがいつ発生したかを発見する方法を示しています(デフォルトのトレースにまだ存在するのに十分最近のものである限り)。
データファイルのサイズと空き容量
データファイルは自動的に大きくなる必要がないように、事前にサイズ設定する必要があることをすでに聞いたことがあるでしょう。このガイダンスに従えば、データファイルが予期せず大きくなるというイベントを経験したことがないでしょう。ただし、データファイルを管理していない場合は、気付いているかどうかに関係なく、定期的に成長している可能性があります(特に、デフォルトの成長設定である10%と1 MBの場合)。
データファイルのサイズを事前に設定するコツがあります。データベースのサイズを大きくしすぎないようにする必要があります。たとえば、開発環境やQA環境に復元する場合、ファイルのサイズは同じであっても同じであることに注意してください。データがいっぱいではありません。ただし、成長を手動で管理する必要があります。 DBAは、新しいデータベースを使用するのに最も苦労していることがわかりました。ビジネスユーザーは、成長率と追加されるデータの量について何も知りません。そのデータベースは、環境内で少し緩い大砲です。サイズと予想される成長を把握するまで、これらのファイルに細心の注意を払う必要があります。サイズと空き領域に関する情報を提供するクエリを使用します:
SELECT
[file_id] AS [File ID],
[type] AS [File Type],
substring([physical_name],1,1) AS [Drive],
[name] AS [Logical Name],
[physical_name] AS [Physical Name],
CAST([size] as DECIMAL(38,0))/128. AS [File Size MB],
CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128. AS [Space Used MB],
(CAST([size] AS DECIMAL(38,0))/128) - (CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128.) AS [Free Space],
[max_size] AS [Max Size],
[is_percent_growth] AS [Percent Growth Enabled],
[growth] AS [Growth Rate],
SYSDATETIME() AS [Current Date]
FROM sys.database_files;> 毎月、データファイルのサイズと使用スペースを確認し、サイズを大きくする必要があるかどうかを判断します。また、成長イベントのデフォルトトレースを監視します。これにより、成長がいつ発生するかが正確にわかります。新しいデータベースを除いて、私は常にファイルの自動拡張を先取りし、手動で処理することができます。わかりました、ほとんどの場合。昨年の休暇の直前に、お客様のIT部門から、ドライブの空き容量が少ないことを通知されました(次のセクションでその考えを保持してください)。現在、通知は20%未満の無料のしきい値に基づいています。このドライブは1TBを超えていたので、ドライブを確認したところ、約150GBの空き容量がありました。まだ緊急事態ではありませんでしたが、スペースがどこに行ったのかを理解する必要がありました。
1つのデータベースのデータベースファイルをチェックすると、それらがいっぱいであることがわかりました。前月、各ファイルには50GB以上の空き容量がありました。次に、テーブルサイズを調べたところ、1つのテーブルで、過去16日間に2億7000万行を超える行が追加され、合計で100GBを超えるデータが追加されたことがわかりました。コードが変更され、新しいコードが意図したよりも多くの情報をログに記録していたことが判明しました。行を削除してファイルの空き領域を回復するジョブをすばやく設定しました(コードを修正しました)。ただし、ディスク領域を回復できませんでした。ファイルを縮小する必要があり、それはオプションではありませんでした。次に、ディスクに残っているスペースの量を判断し、それが快適な量であるかどうかを判断する必要がありました。私の快適さのレベルは、1か月に追加されるデータの量(通常の成長率)を知ることに依存しています。また、ファイルの使用状況を監視し、今月、今年、および今後2年間に必要なスペースの量を見積もることができるため、追加されるデータの量しかわかりません。
ドライブスペース
ディスクの空き領域を監視するジョブがあることは前述しました。これは、固定金額ではなく、パーセンテージに基づいています。私の一般的な経験則では、ディスクの10%未満が空いているときに通知を送信しますが、一部のドライブでは、それを高く設定する必要がある場合があります。たとえば、1 TBのドライブでは、空き容量が100GB未満になると通知が届きます。 100GBのドライブでは、空き容量が10GB未満になると通知が届きます。 20GBのドライブで…まあ、これで私がどこに行くのかわかります。そのしきい値は、問題が発生する前に警告する必要があります。ログファイルをホストするドライブに10GBしか空きがない場合、空きサイズのスペースをチェックする頻度と問題によっては、ユーザーに問題として表示される前に対応する時間がない可能性があります。です。
xp_fixeddrivesを使用して空き領域を確認するのは非常に簡単ですが、文書化されておらず、拡張ストアドプロシージャの使用は一般的に廃止されているため、これはお勧めしません。また、各ドライブの合計サイズを報告するわけではなく、データベースが使用している可能性のあるすべてのドライブタイプについて報告するわけでもありません。 SQL Server 2008R2 SP1以降を実行している限り、はるかに便利なsys.dm_os_volume_statsを使用して、少なくともデータベースファイルが存在するドライブに関する必要な情報を取得できます。
SELECT DISTINCT vs.volume_mount_point AS [Drive], vs.logical_volume_name AS [Drive Name], vs.total_bytes/1024/1024 AS [Drive Size MB], vs.available_bytes/1024/1024 AS [Drive Free Space MB] FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) AS vs ORDER BY vs.volume_mount_point;
tempdbをホストするボリュームのドライブスペースに問題がよく見られます。原因不明のtempdbの成長を伴うクライアントがいた回数のカウントを失いました。たまに数GBです。最近は200GBでした。 Tempdbはトリッキーな獣です。サイズを決定する際に従うべき公式はなく、ルーキー開発者やDBAによって引き起こされたクレイジーなイベントを処理できない空き容量の少ないドライブに配置されることがよくあります。 tempdbデータファイルのサイズを設定するには、「通常の」ビジネスサイクルでワークロードを実行して、tempdbの使用量を判断し、それに応じてサイズを変更する必要があります。
最近、ドライブのスペースが不足しないようにする方法の提案を聞きました。データのないデータベースを作成し、「取っておきたい」スペースを消費するようにファイルのサイズを設定します。次に、問題が発生した場合は、データベースとビオラを削除するだけで、再び空き領域ができます。個人的には、これは他のあらゆる種類の問題を引き起こすと思いますので、お勧めしません。ただし、ドライブに何百もの未使用のGBを表示したくないストレージ管理者がいる場合、これはドライブを「満杯」に見せるための1つの方法になります。それは、私の親友が「あなたと一緒に仕事ができない場合は、あなたの周りで仕事をします」と言うのを聞いたことを思い出させます。
バックアップ
DBAの主なタスクの1つは、データを保護することです。バックアップはそれを保護するために使用される1つの方法であり、そのため、それらのバックアップを保持するドライブはDBAの生活の不可欠な部分です。おそらく、必要に応じてすぐに復元するために、1つ以上のバックアップをオンラインで保持しています。 SLAおよびDR実行ブックは、オンラインで保持するバックアップの数を決定するのに役立ち、そのスペースを利用できるようにする必要があります。現在のバックアップが正常に完了するまで、古いバックアップも削除しないことをお勧めします。古いバックアップを削除してから現在のバックアップを実行するという罠に陥るのは簡単すぎます。しかし、現在のバックアップが失敗した場合はどうなりますか?また、圧縮を使用している場合はどうなりますか?ちょっと待ってください…圧縮バックアップはもっと小さいですよね?結局、それらはより小さくなります。しかし、.bakファイルのサイズは通常、終了サイズよりも大きくなることをご存知ですか?トレースフラグ3042を使用してこの動作を変更できますが、バックアップでは十分なスペースが必要であると考える必要があります。バックアップが100GBで、オンラインで3日間の価値を維持している場合、3日間のバックアップには300 GBが必要です。その後、次のバックアップのために十分な量(現在のデータベースサイズの2倍)が空いている可能性があります。はい、これはいつでもこのドライブに100GB以上の空き容量があることを意味します。それで大丈夫です。削除ジョブを成功させてバックアップジョブを失敗させ、3日後にバックアップがまったくないことを確認するよりも優れています(前の仕事で顧客に起こったことがあります)。
ほとんどのデータベースは時間の経過とともに大きくなります。つまり、バックアップも大きくなります。バックアップファイルのサイズを定期的に確認し、必要に応じて追加のスペースを割り当てることを忘れないでください。350GBに拡張されたデータベースに「200GBの空き」ポリシーを設定してもあまり役に立ちません。スペース要件が変更された場合は、関連するアラートも必ず変更してください。
パフォーマンスアドバイザーの使用
この投稿には、独自のプロセスを実行する必要がある場合にスペースを監視するために使用できるいくつかのクエリが含まれています。ただし、ご使用の環境にSQL Sentry Performance Advisorがある場合は、カスタム条件を使用するとこれがはるかに簡単になります。デフォルトにはいくつかの在庫条件が含まれていますが、独自に作成することもできます。
SQL Sentryクライアント内で、ナビゲーターを開き、[共有グループ(グローバル)]を右クリックして、[カスタム条件の追加]→[SQLSentry]を選択します。条件の名前と説明を入力してから、数値比較を追加し、タイプをリポジトリクエリに変更します。クエリを入力してください:
SELECT MIN(FreeSpace*100.0/Size) FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk;
EqualsをIsless未満に変更し、明示的な値を10に設定します。最後に、デフォルトの評価頻度を10秒ごとよりも頻度の低いものに変更します。 1日1回または12時間に1回は、おそらく適切な値です。空き領域を1日1回より頻繁にチェックする必要はありませんが、何度でもチェックできます。以下のスクリーンショットは、最終的な構成を示しています。
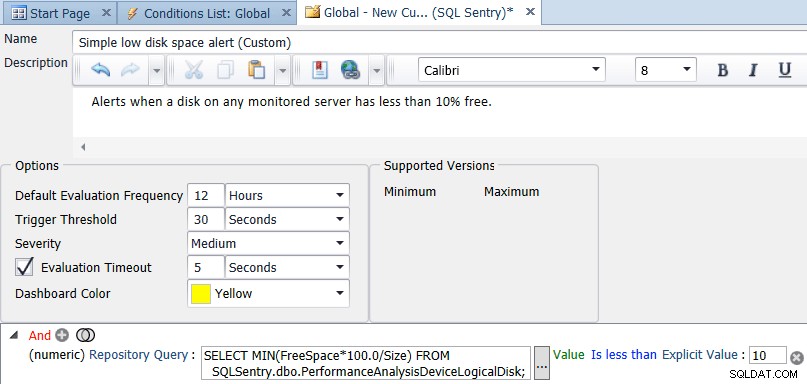
条件の[保存]をクリックすると、カスタム条件にアクションを割り当てるかどうかを尋ねられます。アラートチャネルに送信するオプションはデフォルトで選択されていますが、ジョブの実行などの他のタスクを実行したい場合があります。たとえば、古いバックアップを別の場所にコピーします(それがスペースの少ないドライブの場合)。
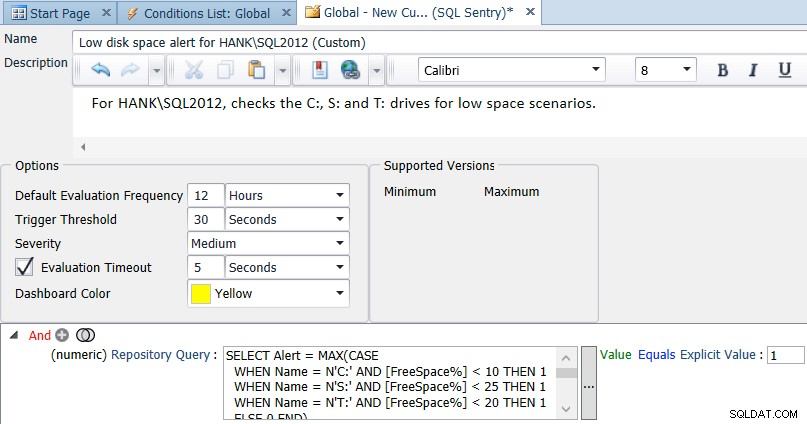
>前に述べたように、すべてのドライブのデフォルトの10%の空き領域は、環境内のすべてのドライブに適切ではない可能性があります。たとえば、さまざまなインスタンスやドライブのクエリをカスタマイズできます。
SELECT Alert = MAX(CASE WHEN Name = N'C:' AND [FreeSpace%] < 10 THEN 1 WHEN Name = N'S:' AND [FreeSpace%] < 25 THEN 1 WHEN Name = N'T:' AND [FreeSpace%] < 20 THEN 1 ELSE 0 END) FROM ( SELECT d.Name, d.FreeSpace * 100.0/d.Size AS [FreeSpace%] FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk AS d INNER JOIN SQLSentry.dbo.EventSourceConnection AS c ON d.DeviceID = c.DeviceID WHERE c.ObjectName = N'HANK\SQL2012' -- replace with your server/instance ) AS s;
環境に応じてこのクエリを変更および拡張し、それに応じて条件の比較を変更できます(基本的に、結果が1の場合はtrueと評価されます):
Performance Advisorの動作を確認したい場合は、お気軽に試用版をダウンロードしてください。
これらの条件の両方で、複数のドライブがしきい値を下回った場合でも、アラートは1回だけであることに注意してください。複雑な環境では、「キャッチオール」条件を少なくするのではなく、より具体的な条件に傾倒して、より柔軟でカスタマイズされたアラートを提供することができます。
概要
SQL Server環境には多くの重要なコンポーネントがあり、ディスク領域はプロアクティブに監視および保守する必要があるコンポーネントです。ほんの少しの計画で、これは簡単に実行でき、多くの未知数と事後対応型の問題解決を軽減します。独自のスクリプトを使用する場合でも、サードパーティのツールを使用する場合でも、データベースファイルとバックアップ用に十分な空き容量があることを確認することは、簡単に解決できる問題であり、努力する価値があります。